综述 | 三大路径,一文总览知识图谱融合预训练模型的研究进展

作者 | 梁子
编辑 | 戴一鸣
当前,预训练模型已是AI领域较为成熟的一项技术,但由于基于神经网络架构的模型本身不具有常识能力,在一些涉及逻辑推理和认知的任务上力有不逮。
近年来,知识图谱越来越受到人们的关注,知识图谱旨在提供一种复杂但灵活的知识的显式建模。许多专家认为,这种新型的知识表示对于预训练模型是一种良好的补充。本文将梳理基于知识图谱增强预训练模型的相关工作,为读者提供这一领域目前的前沿发展状况。
1 为什么要用知识图谱去增强预训练模型?
我们期望,预训练模型能够在需要特定知识或常识的任务中表现得更好。例如,在机器阅读理解中,给定一句《哈利波特》小说中的句子:“Harry Potter points his wand at Lord Voldmort.”,如果要让模型理解这句话,比如哈利波特、伏地魔之间的时空关系,模型就需要知道一些《哈利波特》中的先验知识,让模型对文本中某些实体的有更好的理解,而不仅仅是把它们当作一个称谓(指代)。
在文本生成中,如果要让模型用“河、鱼、网、捉”几个词造句,我们至少应当保证生成的句子符合正常的逻辑关系,比如“人在河里用网捉鱼”,而不是“鱼在捉网”等。这里面就涉及到一些常识。
尽管这些常识已经通过大量的文本预训练或多或少隐式存储在了模型中,但这些知识并不足以让预训练模型处理当下的任务,所以才需要进行知识的注入和增强。另一方面,得到了知识的增强之后,预训练模型可以表现得更像是领域专家,或更像是生活中插科打诨的人。比如你在和对话机器人聊天,你说:“翻译翻译,什么叫惊喜。”你是更希望它把“惊喜”翻译成英文,还是更想让它玩汤师爷的梗呢?
2 知识图谱与预训练模型结合时的常见问题
了解相关意图之后,再来看看结合需要考虑的难点。将知识图谱信息注入到预训练模型中,常见的三个问题是:
(1)结构化信息的非结构化;
(2)异构特征空间的对齐;
(3)知识噪声的解决。
第一个问题是结构化信息的非结构化。相对于自然语言文本这种非结构化的信息,知知识图谱在形式上可以看作是三元组的列表,或者是一张有向图,这样的形式蕴含着比自然语言文本更多的信息,即结构化的信息。如何将这样的信息与擅长提取非结构化文本信息的预训练模型结合起来,是开展工作的第一步。
第二个问题是空间的对齐。由于token部分的特征与知识图谱的embedding是由两种不同的方法得到的,二者所处的特征空间是不完全相同的。针对这类问题,最简单的方法是学习一个线性变换去做向量的对齐。
第三个问题是知识噪声。如果无法进行良好的融合,所融入的知识图谱信息不仅不会提升性能,反而还会降低预训练模型的效果。在embedding层面,知识信息可能会干扰注意力机制的运算,使得当前的推理与预训练模型参数之间发生矛盾;对于在输入文本上的融合,知识噪声可能会破坏原有句子的结构和表达,从而影响模型的理解和生成。
下面介绍的相关工作都是在这三个问题之上进行思考并提出的。
3 相关工作
用知识图谱增强预训练模型,有多种角度来解决这个问题。从主客关系上看,有通过知识图谱增强预训练模型,以实现更好的知识图谱构建的,也有通过知识图谱引入知识,为预训练模型在NLP本身的下游任务上提升效果的。
从知识图谱与预训练模型的增强方式来看,有通过线性变化、注意力机制等在知识实体与关系的嵌入式表达上进行知识融合的,也有直接使用实体描述,设计特定的预训练模型输入。在面向的任务上,除去GLUE等进行通用自然语言理解测试的benchmark之外,还包括近期热门的知识增强的开放领域问答、常识文本生成等等。
由于相关工作过于庞杂,本文从模型的角度入手,按照知识与预训练模型融合的方式进行分类,仅仅选取具有代表性的工作进行重点分析。粗略划分,知识融合的方法可简单分成三类:embedding层面上的融合,token层面的融合,以及知识图谱与预训练模型的共同学习。下面分别进行介绍:
3.1 隐式融合——使用embedding在模型内部融合
隐式融合是比较直接的embedding融合方法,该类方法基于一些KGE(Knowledge Graph Embedding,使用最多的是TransE)算法获得知识图谱中的实体与关系的embedding,并为这些embedding修改预训练模型结构,以便将二者进行结合。
根据将embedding与预训练模型结合的方式,可以粗略分为基于projection的结合方法和基于attention的结合方法。下面以几篇论文为例。
-
ERNIE
ERNIE算得上是该领域的较早工作,其知识融合方法可通过下图进行表达。
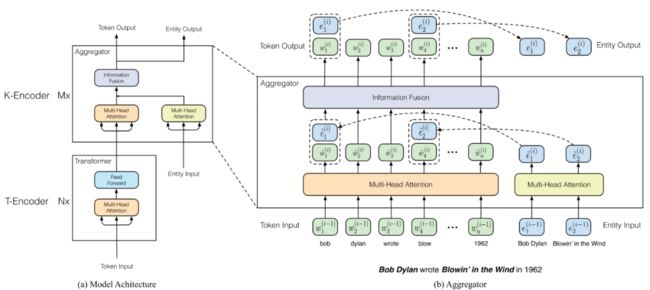
从图中可以看出,ERNIE在传统的transformer encoder(也就是图中的T-encoder,T可以理解为token或者text)的基础上,加入了一种可以进行知识融合的encoder模块(对应图中的K-encoder)。
一个K-encoder的输入除了过去常见的token input之外,还有知识的输入。ERNIE中知识主要指实体,即从待理解的输入语句中提取的一些特定的概念,这些实体可以通过实体识别、匹配等方法找到(在学术实验中多是默认为一个已有的值,后续的NLU上的工作基本继承了这一做法)。
看完输入之后,K-Encoder的输出同样也是包括两部分,即token输出和entity输出。这种设计可以实现将M个K-encoder进行拼接,从而支持进行更深度的语义融合。
那么,文本信息和实体信息是怎么进行融合的呢?前文提到,知识融合的头一个问题是特征空间的问题。所以ERNIE设计了一种projection的方式进行特征融合。
对于同一概念或实体通过文本间self-attention与实体self-attention得到的两种embedding 与,通过以下的线性变换加非线性激活函数的方式,先融合到一个新的空间,之后再映射回原有空间。
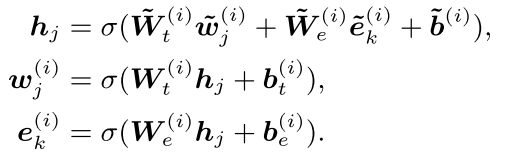
而对于输入文本中没有对应的实体的token,则不需要进行融合,仅仅用上述流程对其进行一次变换。
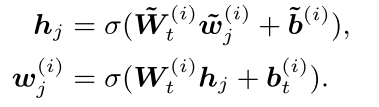
除去模型结构上的创新之外,ERNIE在MLM、NSP等典型任务的基础上,为知识增强设计了新的预训练任务。与MLM类似,该任务通过实体对齐预测的方式设计损失函数,以实现对融合过程和entity的self-attention模块参数的训练。
-
KnowBERT
这篇论文同样采用embedding融合的方式,如图:
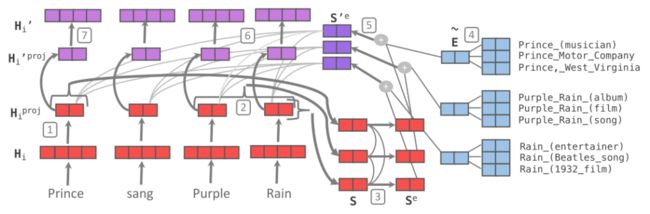
最右边的蓝色部分是实体,下部红色是融合之前的模型,紫色是融合之后的。文中一共标记了七个步骤,简化如下:
-
Projection to entity dimension (200);
-
Mention-span pooling;
-
Mention-span transform;
-
Entity embedding pooling(attention-based);
-
Entity link;
-
Fusion(recontextualization);
-
Inv-Projection;
可以看出,以上很多工作都是为融合做准备,且都是ERNIE没有考虑到的问题。如将token归并成span,这是因为有些实体其实包含多个token, token和entity不是一一对应的。这一点在中文里更为突出,而ERNIE没有考虑。
而在查询知识图谱库时,常常会出现输入一个string出现多个entity的情况,这是实际中需要考虑的问题。
除此之外,第一步和第七步的两个逆变换,其实是对ERNIE思路的一种继承。这篇论文还借用自注意力机制进行融合,具体的融合方式如下:

此处的H是projection之后的token输入,也就是纯粹的没有知识融入的文本特征,而S’e是从文本中提取出的span在融合了相关实体信息之后的表示,也就是既包含该实体的上下文信息,又包含该实体从知识图谱中获得的额外信息的表示。
KnowBERT用H作为Q,用S作为K和V,进行注意力机制的聚合。可直观理解为:长度为N的文本中的第i个token与所挖掘M个实体中的第j个实体,通过表示向量的内积计算二者的相似度,而后进行归一化形成注意力矩阵。
同传统的self-attention的方阵不同,此处的注意力矩阵是N*M的,且N一般比M大。比如在上图中,N=4,而M=3。之后,基于这样的一个权重矩阵,每个token的表示向量都通过该token对每一个entity的加权和获得。
这种方法将实体的信息更加显式地插入到了每个token里。当然,这样的结果更多是融合之后的信息,需要通过残差连接维持原有的文本输入。这篇工作的另一个问题是,中间涉及到较多的可学习模块,因此较难训练。一般该类问题都可以通过课程训练,子模块单独训练等方式缓解冷启动问题。
-
KG-BART
接下来再介绍一篇发表在AAAI2021上的论文,KG-BART。同之前的NLU任务不同,KG-BART主要是用在了文本生成上的常识文本生成(commonsense generation)任务。该任务是一种特殊的硬限制文本生成(hard-constraintNLG),特殊之处就是“常识”。而为了让生成模型具有常识,自然就需要结合知识图谱或相关文档。论文提出的方法总架构如下所示:
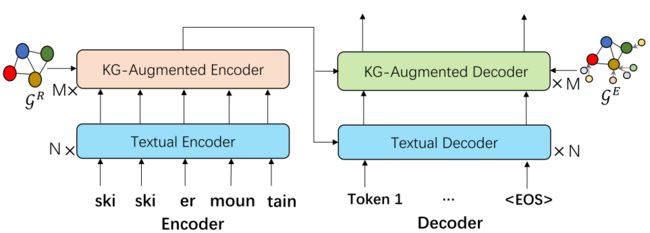
同BART一样,KG-BART也是典型的encoder-decoder结构。该结构的输入是一个BPE编码的token输入,输出为预期的句子。
知识子图在encoder和decoder上都进行了增强。encoder处的图侧重于补充常识信息(R表示reasoning),而decoder部分则主要用以辅助生成,因此是在改变输出token的分布(E表示Expanding)。下面分别对其生成方式进行简单介绍。
Encoder部分的框图如下图所示:
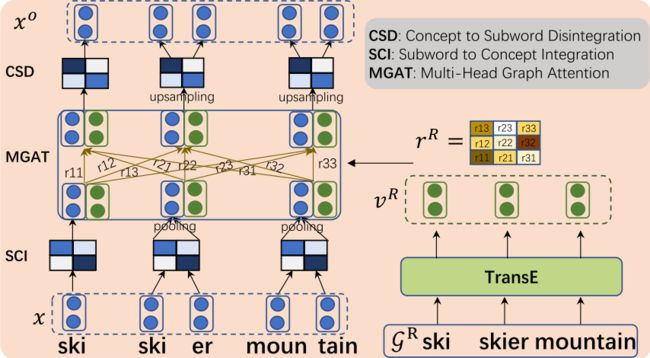
encoder中主要包含三个部分,SCI、MGAT和CSD。其中SCI和CSD类似于know BERT中的span,都是将subword整理成一个concept/entity,并将这样的一个concept再拆解到token级别的过程。论文中使用的是一维卷积加池化。
从图中可以看到,知识的融合主要包括实体v^R和关系r^R两部分,这些embedding的学习均是基于TransE进行的。对于融合过程,该工作基于GAT进行,也就是下面的三个公式:
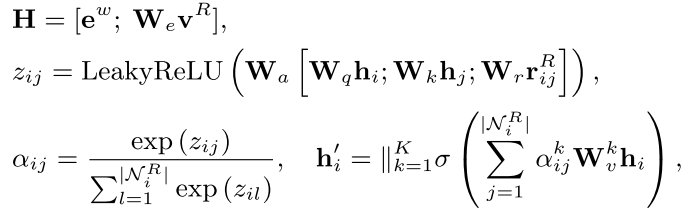
从最后一个公式可以看出,这是标准的GAT结构,即图中节点i更新之后的特征等于其邻域内所有节点的特征在经过线性变换后进行有权重的加和。
其中,每个节点的初始特征包括两部分,一部分是来自于文本的聚合之后的概念特征,另一部分是知识图谱中该概念对应的embedding在线性变换之后的结果。每个节点的特征即为这两部分的拼接值(也就是第一个公式)。而权重α则是基于目标节点i和邻居节点j的相似度进行计算的(对应第二个公式)。
不同于self-attention中使用内积近似相似度,此处使用的是加和形式的相似度,并且额外将两概念之间的关系表示也添加了进去。对于知识的图神经网络聚合,还有一些别的聚合方式。
再关注一下decoder。整体而言,decoder的融合形式同know BERT有些类似。
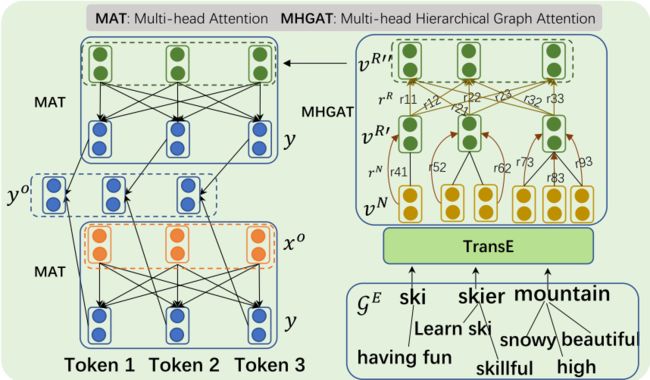
上图是decoder部分的架构图,和encoder不同的是,该图对知识图谱子图部分的处理更多一些,该工作认为进行文本生成时,需更多地考虑同当前概念相关的一些token,以更好地进行文本生成。
因此,此时的知识图谱子图(右下角)不仅仅包含了encoder输入里的概念(如ski,skier,mountain),还包括了许多新的概念,从而形成几个概念树(每个树的根节点为输入中的一个概念)。
而decoder部分先不考虑概念之间的relation,而是首先基于这样的树结构将叶子节点的信息传播到根节点,之后再进行根节点之间的传递和知识与文本信息的融合。
对于树上的GNN,论文直接使用了GAT进行特征传播,如下面的公式所示:
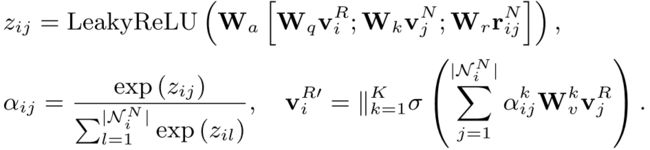
对于概念之间的信息传播,同样地一个GAT就可以解决。在此也不赘述。
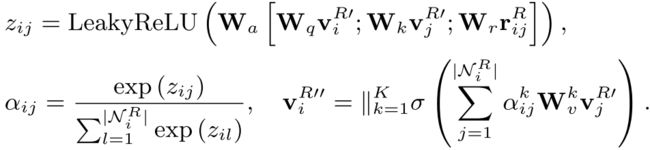
下面来看一下概念上的表示如何同文本上的概念表示进行融合。
如前所述,此处使用的是know BERT中的方法,该方法也是transformer decoder中对cross-attention的一个直接的化用。即文本输入作为Q,外部输入作为K和V,如下:
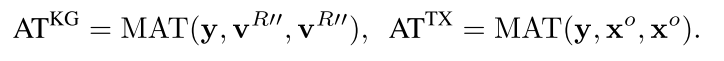
ATKG是知识图谱信息与文本信息融合的方法,ATTX则是vanilla transformer decoder中已有的部分,最终将二者进行拼接即可。
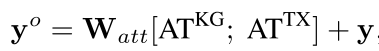
以上三篇工作均为基于embedding进行融合的典型,几乎也将embedding的结合方式总结得差不多了。当然,由于神经网络的可学习性,有时候模型结构对使用效果的影响并不是唯一的。用知识去增强预训练模型,同模型的输入、训练的任务都息息相关。面向特定的下游任务,不同的融合方式甚至也会产生不同的效果。
尽管embedding的方式比较直观,且属于典型的深度学习风格,但该类方法仍然存在以下几类问题:
-
知识的融合效果受knowledge embedding学习限制;
-
简单的变换未必能将知识空间与文本空间对齐;
-
该结构需要对预训练模型重新进行预训练,即使通用的KG+PTM预训练是可行的,针对特定领域的预训练或微调同样存在困难。
下面介绍的第二类方法将提供一些额外的思路。
3.2 显式融合——不改变模型结构的融合方式
与之前所述的基于embedding的结合相比,另一种思路更为直接:既然知识图谱本身就是借助自然语言表达的,能不能直接把实体和关系经过某些变换后,以token的形式输入到预训练模型中?这样就不需要再去为每个实体学习embedding,更不需要考虑两种特征空间的聚合。
一些相关的工作都是在这种思路的基础上进行的,这类工作大概可以分成两类:
(1)训练时的知识增强;
(2)推理时的知识增强;
下面分别对这两种类型的学习进行介绍。
-
K-BERT
较早的是K-BERT,其基于输入序列,通过查询语句中的三元组,将输入语句转化为输入树,之后,通过特殊设计BERT的输入信息编码和mask矩阵,实现推理时模型增强的目的。具体过程可通过下面的框图描述。
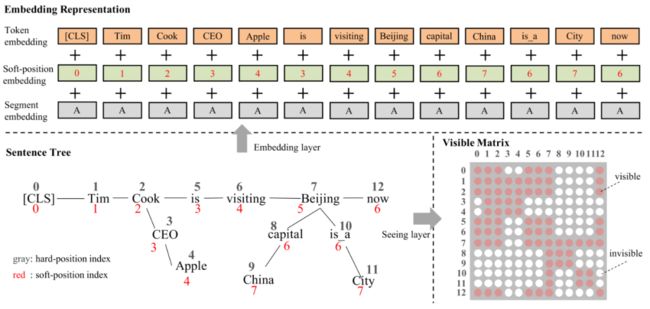
例如,对于“库克正在北京参观”这句话,在其输入到预训练模型中时,token embedding和segment embedding并没有发生变化,唯一发生改变的只是position embedding和mask matrix。
对于位置编码,图中展现了两种(红色的和白色的),通过这两种编码就可以将输入的序列一一对应为一个子图。由于硬编码已经在输入的顺序中体现,因此实际BERT输入的位置编码是描述每一条路径的软编码。
mask矩阵的意图更为简单:输入的自然语言文本是彼此可见的,每个三元组内部也是彼此可见的,但文本中的token同其他三元组是不可见的,这样也就避免了前面所说的知识噪声问题。当然,三元组上的额外信息还是可以间接传入文本中的其他token。
-
CoLAKE
如果说K-BERT意图将输入文本扩展成一棵树,CoLAKE的核心思路则是把输入文本通过知识图谱扩展成一张图。
CoLAKE基于self-attention与GNN相似性上的结论,将输入文本看作是全连接图,并在此基础上将该图通过知识图谱进行扩展。也就形成了下图所示的框图。
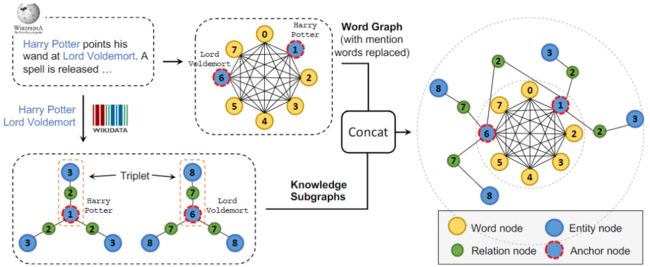
构建起这样的图之后,该图也是需要送入BERT等模型中去,因而CoLAKE面临着和K-BERT同样的设计问题。下图可以展现出其设计细节:
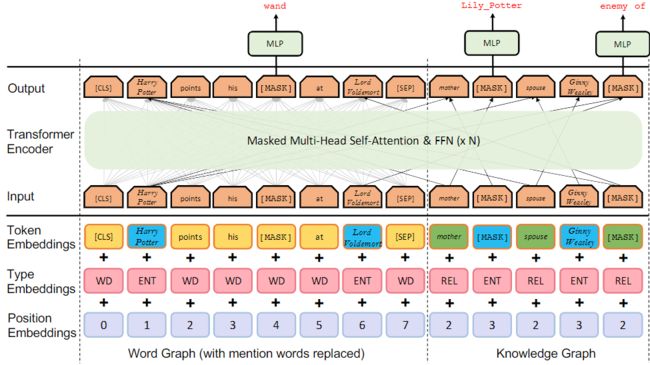
可以看出,该工作和K-BERT主要的区别有三处:
(1)segment embedding中细化了很多细节;
(2)该图的mask矩阵是基于图的拓扑关系构建,相当于是邻接矩阵,而不是根据避免知识噪声的原则构建的;
(3)该论文更为重视预训练过程,通过之前所说的扩展MLM的方法完成了对模型更好的训练。
CoLAKE的另外一个特色在于,通过这种方式得到的知识图谱中实体与关系的embedding,比transE等传统方法的效果还要好,这一点也在一些知识图谱不全的实验中得到了验证。
3.3 知识图谱与预训练模型的共同学习
除去上述两部分的工作之外,还有一类工作进行了额外的尝试。该类工作并不满足于单纯地将知识图谱增强于预训练模型,而是将知识图谱表示学习和面向知识的自然语言理解一起处理,并希望通过这种方式可以在这两个领域内都得到模型的提升。
-
KEPLER
KEPLER的基本框架如下所示:
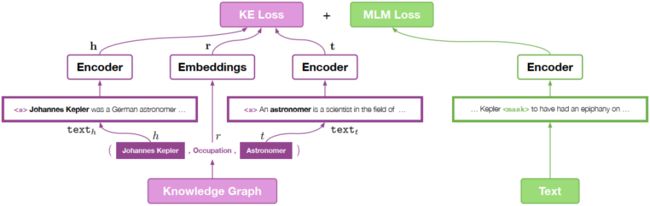
从图中可以看出,KEPLER的思想是,使用统一的一个transformer encoder实现对文本信息或实体描述信息的编码,对两个领域分别设计预训练任务,并使用这类预训练任务的联合任务对encoder进行训练。
如上图所示,提取文本信息的encoder与从头部实体与尾部实体中获取embedding的encoder是同一个,因此,通过知识图谱中的实体描述,encoder可以学习到实体信息,而通过在文本上的预训练,encoder也可以学习到文本层次上的信息,这样就完成了在训练时将知识信息融入到encoder之中。该模型的训练损失主要包括两部分,一部分是常见的MLM,另一部分则是对于Knowledge Embedding的损失,此处主要是使用负采样的损失函数,即
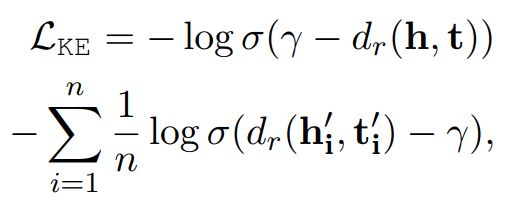
此处的h和t都是正样本,和为负样本。是同relation相关的距离函数,论文中简单使用了transE的方式,也就是加和距离:
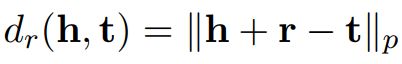
-
JAKET
JAKET将知识图谱表示学习与知识图谱增强的两个NLU任务,视为彼此可以互相促进的任务,这是该论文的最大亮点。下图展示了JAKET的整体流程。
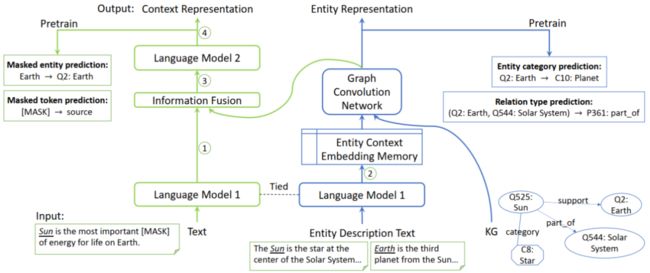
整张图中,蓝色部分主要是知识图谱表示学习的部分,而绿色的部分则是知识增强的文本理解模型。先看蓝色部分,同KEPLER类似,transformer encoder(即图中的LM1)会被用在提取实体描述的表示上,而这些描述的表示就是对应实体的表示。之后,通过适配于知识图谱的GAT,这些特征将依照知识图谱的拓扑结构得到信息传递,并连接在如实体分类、关系预测等预训练任务上。
在整个知识图谱表示学习的过程中,值得注意的两个点是:
-
同KEPLER一样,JAKET也将LM1视为共享的encoder,同时为了缓解循环依赖问题,LM2还具有额外的encoder LM2。同时,在基于KGE任务进行训练时,LM1是相对而言frozen的。
-
不同于KEPLER的是,知识图谱中实体的表示还是会被用来进行LM2的增强。
在理解清楚KGE的基本过程后,下面简单介绍一下GAT部分。同上文中介绍KG-BART里对知识图谱进行GAT的方式有所不同,此处采用的是另一个风格的GAT,具体形式如下所示:
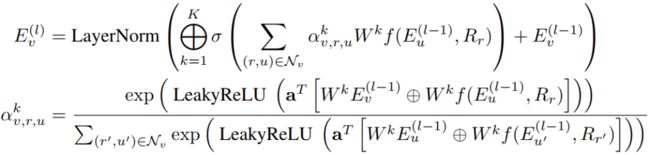
从图中可以看出,聚合方式同样还是GAT,不过有一个地方发生了变化。过去的GAT是将邻居节点的表示经过矩阵映射之后做聚合,在此处,为了适配知识图谱中的关系的特征,将聚合的对象改成了
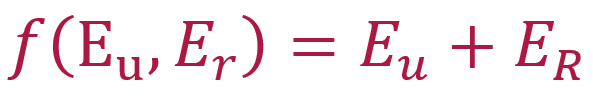
。
再来看绿色的部分,该部分首先也是通过LM1获得输入的token级别的初步特征,之后将该特征表示里实体的表示同知识图谱中获得的实体embedding进行融合,论文文中直接进行了加和。
融合之后的输入序列表示会进入到LM2中,LM2的输出被用来进行预训练模型相关的任务。同之前的工作一样,任务主要包括两个,一是通常BERT中的MLM,二是专门针对于实体的MLM。另外一个在实现中的细节是,LM1和LM2不一定是两个分离的模型,比如在论文中,二者是一个transformer encoder(论文中使用的是Roberta)的前8层和后8层。
4 总结
将知识图谱同预训练模型进行结合,目前已经出现了大量的工作。除去上述文章中所介绍的论文之外,还有将KG转化为自然语言语料融入到训练中、设置即插即用的知识图谱等其他工作。目前来看,将知识图谱与预训练模型结合,在此过程中对彼此任务都获得提升,已经成为一个趋势。另外的一个趋势是,针对于不同的下游任务,在融合方式上进行特殊的适配,毕竟目前出现了大量的需要知识图谱支撑的NLP任务。未来的工作或许会从这些角度继续深入。
参考文献
-
ERNIE:Zhang, Zhengyan, et al. "ERNIE: Enhanced language representation with informative entities." arXivpreprint arXiv:1905.07129 (2019).
-
knowBERT: Peters, Matthew E., et al."Knowledge enhanced contextual word representations." arXivpreprint arXiv:1909.04164 (2019).
-
KG-BART:Liu, Ye, et al. "KG-BART:Knowledge Graph-Augmented BART for Generative Commonsense Reasoning." arXivpreprint arXiv:2009.12677 (2020).
-
K-BERT:Washington, K., et al. KBERT.Knowledge Based Estimation of Material Release Transients. No. ESTSC-001257IBMPC00. Sandia National Labs., Albuquerque, NM(United States), 1995.
-
Co-LAKE:Sun, Tianxiang, et al."Colake: Contextualized language and knowledge embedding." arXivpreprint arXiv:2010.00309 (2020).
-
KEPLER:Wang, Xiaozhi, et al. "KEPLER:A unified model for knowledge embedding and pre-trained language representation." Transactions of the Association for ComputationalLinguistics 9 (2021): 176-194.
-
JACKET:Yu, Donghan, et al."Jaket: Joint pre-training of knowledge graph and language understanding." arXiv preprint arXiv:2010.00796 (2020).