【文献翻译CVPR2022】SoftGroup for 3D Instance Segmentation on Point Clouds
点云三维实例分割的软分组
目录
点云三维实例分割的软分组
摘要
1 简介
2 相关工作
3 方法
3.1 逐点预测网络
3.2 软分组
3.3 自上而下的精细化
3.4 多任务学习
4 实验
4.1 实验设置
4.2 基准结果
4.3 定性分析
4.4.消融实验
5 结论
References
原文链接:
https://arxiv.org/pdf/2203.01509v1.pdf
免责声明:此文献是博子为了自己学习方便从CVPR2022原文翻译而来,顺手发个CSDN。原文链接已给出;本文主要使用百度翻译和 ReadPaper网站翻译而来,其中加入了博主的一些修正和个人理解(个人理解以‘注’的形式给出,请注意区分),可能存在一些不足之处,请在评论区不吝赐教。建议与原文一起分屏对照阅读。原文目前在3D实例分割方面代表了最新进展(当前是:2022/4/4 星期一),见下图所示:

此图从ScanNet(v2) Benchmark (3D Instance Segmentation) | Papers With Code截图得到。
以下为正文:
摘要
现有的前沿的3D实例分割方法先进行语义分割,然后进行分组,在进行语义分割时进行硬预测,使得每个点都与一个单一类相关联。然而,来自硬判决的误差(注:语义误差)传播到分组中,从而导致(1)预测实例与地面真实之间的低重叠(注:欠分割)(2)大量的假阳性(注:过分割)。针对上述问题,本文提出了一种自下而上软分组、自上而下细化的3D实例分割方法--SoftGroup。SoftGroup允许每个点与多个类别相关联,以缓解由于语义预测错误而产生的问题,并通过学习将它们归类为背景来抑制假阳性实例。在不同数据集和多种评价指标上的实验结果证明了SoftGroup的有效性。它的性能在ScanNet v2隐藏测试集上显著超过了最强的先前方法的+6.2%,在S3DIS Area 5上的AP50上显著超过了6.8%。Soft-Group也很快,在ScanNet v2数据集上使用单一Titan X时,每次扫描速度为345ms。这两个数据集的源代码和经过训练的模型可在https://github.com/thangvubk/SoftGroup.git上获得。
1 简介
随着三维传感器的快速发展和大规模三维数据集的出现,三维数据的场景理解受到越来越多的关注。点云上的实例分割是一项3D感知任务,为自动驾驶、虚拟现实和机器人导航等广泛应用奠定了基础。实例分割处理点云以输出每个检测到的对象的类别和实例掩码。
最先进的方法[4,14,17]认为3D实例分割是一条自下而上的管道。它们学习逐点语义标注和中心偏移向量,然后将与实例的几何距离较小且有着相同语义标注的点进行分组。这些分组算法是在硬语义预测上执行的,其中点与单个类相关联。在许多情况下,对象是局部歧义的,输出的语义预测对不同的部分表现出不同的类别,因此使用硬语义预测进行实例分组会导致两个问题:(1)预测实例与真值(注:ground-truth)之间的重叠度低;(2)来自错误语义区域的额外的假阳性实例。图1显示了可视化示例。这里,在语义预测结果中,橱柜的某些部分被错误地预测为其他家具。当使用硬语义预测进行分组时,语义预测误差与实例预测有关。因此,预测的橱柜实例与地面真实情况的重叠度较低,而另一个家具实例是假阳性。
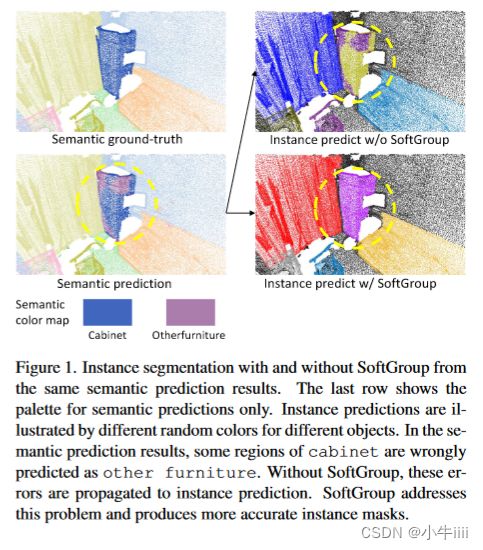
图1.来自相同的语义预测结果的使用和不使用SoftGroup的实例分割(注:语义预测结果一样,一个使用SoftGroup,另一个未使用,进行实例分割并对比结果)。最后一行显示了仅用于语义预测的调色板。实例预测由不同对象的不同随机颜色来表示。在预测结果中,部分橱柜区域被错误地预测为其他家具。如果没有SoftGroup,这些误差将传播到实例预测。SoftGroup解决了这个问题,并产生了更准确的实例掩码。
本文提出了SoftGroup来解决这些问题,通过考虑软语义分数来进行分组,而不是硬one-hot语义预测(注:one-hot独热是一种由0和1组成的二进制编码)。SoftGroup的意图如图2所示。我们的发现是,语义预测错误的对象部分对于真正的语义类仍然有合理的分数。SoftGroup依赖于分数阈值来确定对象属于哪一类,而不是参数最大值。根据软语义分数分组在正确的语义类上产生准确的实例。对于语义预测错误的实例,通过学习将其归类为背景来进行抑制。为此,我们将实例建议(注:文中出现的‘建议’、‘提案’和‘候选’等词均应考虑为proposal)视为依赖于与基本事实的最大交集(IOU)的正样本或负样本,然后构建自上而下的求精阶段来提炼正样本而抑制负样本。如图1所示,SoftGroup能够从不完美的语义预测中产生准确的实例掩码。
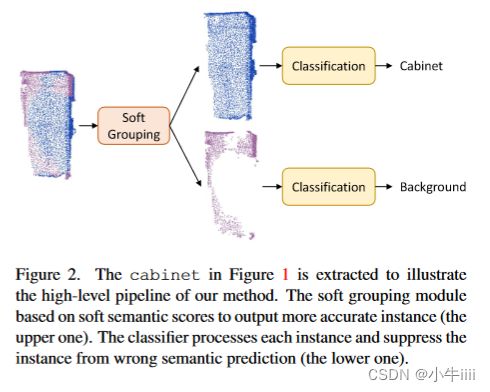
图2.提取图1中的文件柜是为了说明我们方法的高层管道。软分组模块根据软语义分数输出更准确的实例(图中上面那个分类器)。分类器处理每个实例,并从错误的语义预测(图中下面那个分类器)中抑制该实例。
SoftGroup在概念上很简单,很容易实现。在ScanNet v2[6]和S3DIS[1]基准数据集上的实验表明了该方法的有效性。尤其地是,SoftGroup在ScanNethidden测试集上的表现比以前的最先进方法高出+6.2%,在S3DIS区域5上的AP50表现出+6.8%的显著优势。SoftGroup速度很快,处理一个扫描网络场景需要345ms。总而言之,我们的贡献有三个方面:
 我们提出了SoftGroup根据软语义分数进行分组,以解决硬语义预测将错误传播到实例预测的问题。
我们提出了SoftGroup根据软语义分数进行分组,以解决硬语义预测将错误传播到实例预测的问题。
我们提出了一个自上而下的精化阶段,以纠正、细化正样本并抑制错误语义预测导致的假阳性。
我们报告了在具有不同评估指标的多个数据集上的广泛实验,显示出与现有最先进方法的显著改进。
2 相关工作
关于三维点云的深度学习。点云表示是理解三维场景的一种常用数据格式,它既简单又保留了原始的地理信息。为了处理点云,早期的方法[2,3,32,33]根据点的统计属性提取手工制作的特征。最近的深度学习方法学习从点中提取特征。点式方法,如PointNet[28,29],直接通过共享多层感知器(MLP)处理点,然后从对称函数中聚合区域和全局特征,如最大合并。基于体素的方法[5,8,21,30]将无序的点集变换成有序的稀疏体网格,然后在网格上进行三维稀疏卷积,显示了性能和速度的有效性。
基于建议的实例分割。基于提案的方法考虑一种自上而下的策略,该策略生成区域提案,然后在每个提案中分割对象。现有的基于提案的3D点云方法很大程度上受到了MASK-RCNN处理2D图像的成功的影响。为了处理点云数据的不规则性,Li等人[37]提出了GSPN,它采用综合分析的策略来生成高客观性的3D方案,并通过基于区域的PointNet进行精化。[12]提出了结合多视RGB输入和3D几何来预测边界框和实例蒙版的3DIS。Yang等人[36]提出了3D-BoNet算法,它直接输出一组包围盒,不需要生成锚点和非最大值抑制,然后通过逐点二进制分类器对目标进行分割。刘等人[19]提出GICN将每个对象的实例中心近似为一个高斯分布,并对其进行采样得到候选对象,然后产生相应的包围盒和实例掩码。
基于分组的实例分割。基于分组的方法依赖于自下而上的管道,该管道产生逐点预测(如语义图、地理度量移动或潜在特征),然后将点分组到实例中。Wang等人[34]提出了SGPN算法,对所有特征点构造特征相似度矩阵,然后将相似特征的点分组为实例。Pham et al.[25]提出了JSIS3D,它通过多值条件随机场模型融合了语义标签和实例标签,并联合优化标签以获得对象实例。拉胡德·埃塔尔[16]提出用MTML学习特征和方向嵌入,然后对嵌入的特征进行均值漂移聚类,生成根据方向特征一致性进行评分的对象段。Hanet al.[9]介绍了OccuSeg,它在对象占用信号的引导下执行基于图形的聚类,以获得更精确的分割输出。Zhang等人[38]考虑了一种概率方法,该方法将每个点表示为三元正态分布,然后通过聚类步骤获得对象实例。Jiang等人[14]提出了一种基于简单而有效的算法的点组分割算法,该算法将同一标签的附近点分组,并逐步扩展该组,从而在原始点集和偏移移动点集上分割对象。Chen等人[4]对PointGroup进行了扩展,提出了进一步吸收实例周围碎片的HAI,然后基于实例内预测对实例进行细化。Liang等人[17]使用SSTNet从预先计算的超点构造一个REE网络,然后遍历树并拆分节点以获得对象实例。
常用的基于提案的方法和基于分组的方法各有优缺点。基于提案的方法独立地处理每个对象提案,不受其他实例的干扰。基于分组的方法无需生成方案就可以处理整个场景,从而实现快速推理。然而,基于建议的方法很难生成高质量的提案,因为点只存在于对象表面;基于分组的方法高度依赖语义分割,使得语义预测中的错误传播到实例预测。(我们)提出的方法利用了两种方法的优点并解决了它们的局限性。我们的方法被构建为一个两阶段的流水线,其中自下而上阶段通过对软语义分数的分组来生成高质量的对象建议,然后自上而下阶段对每个建议进行处理以提炼正样本并抑制负样本。
3 方法
SoftGroup的整体架构如图3所示,分为两个阶段。在自下而上的分组阶段,逐点预测网络(第3.1节)将点云作为输入,并生成逐点语义标签和偏移向量。软分组模型(第3.2节)处理这些输出,以生成初步实例提案。在自上而下的细化阶段,根据提案,从主干中提取相应的特征,并用于预测类、实例掩码和掩码分数,作为最终结果。
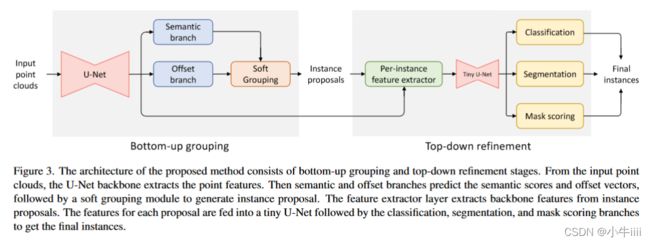
图3.提出的方法的体系结构由自下而上的分组和自上而下的精化阶段组成。U-Net骨干网从输入点云中提取点特征。然后,语义分支和偏置分支预测语义得分和偏置向量,然后由软分组模块生成实例提案。特征提取层从实例提案中提取骨干特征。每个方案的特征被馈送到一个微小的U网中,然后进行分类、分割和掩码评分分支,以获得最终实例。
3.1 逐点预测网络
逐点预测网络的输入是一组n个点,每个点都由其坐标和颜色表示。点集被体素化以将无序的点转换为有序的体网格,该有序的体网格被馈送到U-Net样式主干[31]以获得点特征。采用子流形分离卷积[8]实现了三维点云的U-Net。从点特征出发,构造两个分支输出逐点语义分数和偏移量。
语义分支。语义分支由一个两层的MLP(注:应该是两个隐含层)构造,并学习输出N个类上N个点的语义得分S={S1,...,SN}∈RN×N类。不同于已有的方法[4,14],我们直接对语义分数进行分组,而不是将语义分数转换为一个one-hot(独热编码)语义预测。
偏移分支。与语义分支并行,我们应用两层MLP(readpaper竟然翻译为两层最大似然算法,应该是错认为是MLE了)来学习偏移向量O={o1,...,on}∈RN×3,它表示从每个点到该点所属实例的几何中心的向量。基于学习到的偏移向量,我们将点移动到相应实例的中心,以更有效地执行分组。
交叉熵损失和回归损失(函数)分别用于训练语义分支和偏置分支。

其中![]() 是第i个语义标签,
是第i个语义标签, 是表示第i个点到该点(注:‘该点’亦即第i个点本身)所属实例几何中心的向量的偏移量标签(类似于[4,14,17]),
是表示第i个点到该点(注:‘该点’亦即第i个点本身)所属实例几何中心的向量的偏移量标签(类似于[4,14,17]), {pi}是指示点pi是否属于任何实例的指示函数。
{pi}是指示点pi是否属于任何实例的指示函数。
博子注(源于周志华《机器学习》主要符号表):
![]()
3.2 软分组
软分组模块接收语义得分和偏移量作为输入,生成实例提案。首先,使用偏移向量将点向对应的实例中心移位。为了使用语义分数进行分组,我们定义了分数阈值 来确定一个点属于哪个语义类,允许该点与多个类相关联。给定语义分数S∈
来确定一个点属于哪个语义类,允许该点与多个类相关联。给定语义分数S∈![]() ,我们迭代N个类,在每个类索引处,我们对具有该(w.r.t.类索引)分数高于阈值的整个场景的点子集进行切片。我们在每个点子集上遵循[4,14]的形式分组。由于每个子集中的所有点都属于同一类,我们只需遍历子集中的所有点,并在几何距离小于分组带宽b的点之间创建链接,即可获得实例提案。对于每一次迭代,对整个扫描的点子集执行分组,以确保快速推理。我们注意到现有的基于提案的方法[12,19,36]通常将边界框视为对象提案,然后在每个提案中进行分割。直观地,与实例高度重叠的边界框的中心应该靠近对象的中心,但在三维点云中生成高质量的边界框提案是具有挑战性的,因为该点只存在于对象表面上。与之相反的是,SoftGroup依赖于更准确的点级提案,并自然地继承了点云的散布特性,由于分组实例提案的质量高度依赖于语义分割的质量,因此我们定量地分析了阈值对语义预测召回率和查准率的影响。第j个类的召回率和查准率定义如下。
,我们迭代N个类,在每个类索引处,我们对具有该(w.r.t.类索引)分数高于阈值的整个场景的点子集进行切片。我们在每个点子集上遵循[4,14]的形式分组。由于每个子集中的所有点都属于同一类,我们只需遍历子集中的所有点,并在几何距离小于分组带宽b的点之间创建链接,即可获得实例提案。对于每一次迭代,对整个扫描的点子集执行分组,以确保快速推理。我们注意到现有的基于提案的方法[12,19,36]通常将边界框视为对象提案,然后在每个提案中进行分割。直观地,与实例高度重叠的边界框的中心应该靠近对象的中心,但在三维点云中生成高质量的边界框提案是具有挑战性的,因为该点只存在于对象表面上。与之相反的是,SoftGroup依赖于更准确的点级提案,并自然地继承了点云的散布特性,由于分组实例提案的质量高度依赖于语义分割的质量,因此我们定量地分析了阈值对语义预测召回率和查准率的影响。第j个类的召回率和查准率定义如下。

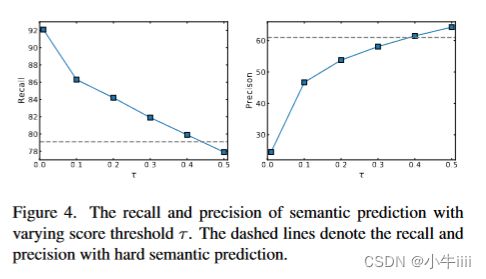
图4.不同分数阈值下语义预测的召回率和查准率,虚线表示具有硬语义预测的召回率和查准率。
图4显示了不同分数阈值与硬语义预测的召回率和查准率(所有类取平均),进行比较。在硬语义预测的情况下,召回率为79.1%,表明类上超过20%数量的点没有被预测覆盖到。当使用分数阈值时,召回率随着分数阈值的降低而增加。然而,较小的分数阈值也导致了较低的查准率。我们提出了一种自上而下的精细化阶段来缓解查准率低的问题,该精细化阶段的查准率可以解释为对象实例的前景点和背景点之间的关系。我们将阈值设置为0.2,精度接近50%,从而确保场景中的前景点和背景点之间的比例达到平衡。
3.3 自上而下的精细化
自上而下的精细化阶段对自下而上的分组阶段输出的实例提案进行分类和提炼(注:即精细化)。一个特征提取器层处理每个提案以提取其相应的骨干特征。提取的特征被送入一个微小的U-Net网络(一种具有少量层的U-Net网络),然后在随后的分支上预测分类分数、实例掩码和掩码分数。
分类分支。分类分支首先使用全局平均值池化层来聚合实例中所有点的特征,然后使用MLP来预测分类分数C={c1,...,ck}∈![]() ,其中K是实例的数量。我们直接从分类分支的输出中得到对象类别和分类置信度分数。
,其中K是实例的数量。我们直接从分类分支的输出中得到对象类别和分类置信度分数。
我们注意到现有的基于分组的方法通常是从语义预测中得到对象类别。然而,实例可能来自具有嘈杂语义预测的对象。该方法直接使用分类分支的输出作为实例类。分类分支聚合实例的所有点特征,并使用单个标签对实例进行分类,从而获得更可靠的预测。
分割分支。如第3.2节所示,实例提案同时包含前景点和背景点,我们构造了一个分割分支来预测每个提案中的实例掩码。分割分支是两层逐点MLP,其为每个实例k输出实例掩码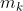 。
。
掩码评分分支。掩码评分分支与分类分支具有相同的结构。此分支输出掩码分数E={e1,...,Ek}∈![]() ,该分数估计预测掩码与真值(注:即ground truth)的IOU。将掩码得分与分类得分相乘,得到最终的置信度得分。
,该分数估计预测掩码与真值(注:即ground truth)的IOU。将掩码得分与分类得分相乘,得到最终的置信度得分。
学习目标。训练自上而下的精细化分支需要每个分支的目标标签。为此,我们遵循了已有的2D目标检测和分割方法的逻辑。我们将所有与真值实例的IOU高于50%的实例提案视为正样本,其余视为负样本。每个正样本都被分配到IOU最高的真值实例。正样本的分类目标是对应的真值实例的类别,总类数为![]() (
(![]() 个前景类和1个背景类)。分割和掩码评分分支只在正样本上训练,正样本的掩码目标是配对的真值实例的掩码。掩码评分的目标是预测的掩码和真值掩码之间的IoU。这些分支的训练损失是交叉熵、二元交叉熵和
个前景类和1个背景类)。分割和掩码评分分支只在正样本上训练,正样本的掩码目标是配对的真值实例的掩码。掩码评分的目标是预测的掩码和真值掩码之间的IoU。这些分支的训练损失是交叉熵、二元交叉熵和![]() 回归损失的组合,如下[10,13]。
回归损失的组合,如下[10,13]。

这里,c∗、m∗、r∗分别为分类、分割和掩码评分目标。K为提案总数,{}表示该提案是否为正面样本。
3.4 多任务学习
整个网络可以用端到端的方式使用多任务损失(函数)进行训练。

其中,![]() 和
和![]() 是在第3.1节中定义的语义损失和偏置损失(函数),而
是在第3.1节中定义的语义损失和偏置损失(函数),而![]() 、
、 和
和![]() 是在第3.3节中定义的分类、分割和掩码评分损失(函数)。
是在第3.3节中定义的分类、分割和掩码评分损失(函数)。
4 实验
4.1 实验设置
数据集。实验是在标准基准ScanNet v2[6]和S3DIS[1]数据集上进行的。ScanNet数据集包含1613次扫描,分别分为1201次、312次和100次扫描的训练集、验证集(注:亦称校验集)和测试集。实例分割在18个对象类上进行了评估。按照现有的方法,基准测试结果将在隐藏的测试分集上报告。消融研究在验证集上进行。
S3DIS数据集包含6个区域的3D扫描,总共有271个场景。该数据集由13个类别组成,用于实例分割评估。在现有方法的基础上,使用两种设置来评价实例分割结果:在Area 5进行测试和6重交叉验证。
评估指标。评价指标是标准平均精度(注:精度即查准率)。其中,AP50和AP25分别表示IOU阈值为50%和25%的分数。同样,AP表示IOU阈值为50%到95%、步长为5%的平均分数。此外,还使用平均实例覆盖率(mCov)、平均加权实例覆盖率(mWCov)、平均查准率(mPrec)和平均召回率(mRec)来评估S3DIS。
实施详情。实现细节遵循现有方法[4,14]。该模型使用PyTorch深度学习框架[24]实现,并使用Adam优化器进行了120k次迭代[15]的训练。批大小被设置为4。学习率被初始化为0.001,并通过余弦退火法[20]进行调整。体素大小和分组带宽b分别被设置为0.02m和0.04m。软分组分数阈值被设置为0.2。在训练时,场景被随机裁剪,最大点数为250K。对于点密度较高的S3DIS,在裁剪前对场景按1/4的比例进行随机下采样。在推断时,场景被分成四个部分,然后输入到模型中,然后将四个部分的输出合并得到最终结果。
我们注意到,现有高性能方法的源代码和经过训练的模型仅在ScanNet v2上公开提供。在这项工作中,将发布ScanNet v2和S3DIS上的源代码和训练模型,以支持结果的重现性。
4.2 基准结果

表1.根据AP50分数在ScanNet v2隐藏测试集上的3D实例分割结果。提出的SoftGroup获得了最高的平均AP50,远远超过了之前最强的方法。报告的结果来自2021年11月13日的ScanNet数据集 上的Benchmark。
ScanNet v2。表1显示了SoftGroup在ScanNet v2基准的隐藏测试集上使用的最新方法的结果。我们提交我们的模型并从服务器报告结果。所提出的SoftGroup达到了最高的平均AP50%,达到了76.1%,以6.2%的显著差距超过了以前最强的方法。
S3DIS。表2总结了在S3DIS数据集的Area 5和6倍交叉验证的结果。在Area 5和交叉验证的评估中,与现有方法相比,所提出的SoftGroup获得了更高的整体性能。值得注意的是,在Area 5评估中,SoftGroup的AP/AP50达到51.6/66.1(%),与第二好的相比提高了8.9/6.8(%)。在ScanNet v2和S3DIS数据集上的最新性能表明了该方法的泛化优势。
(表2、表3和表4在同一张图中,如下图所示:)
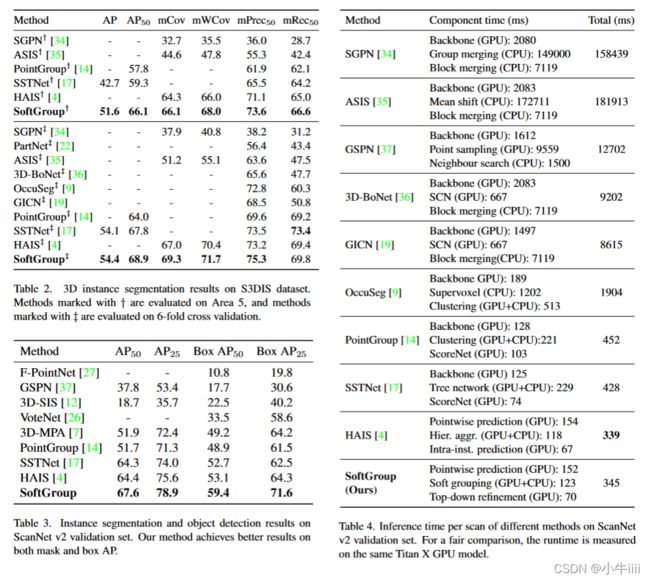
表2.基于S3DIS数据集的3D实例分割结果。使用†标记的方法在Area 5上进行评估,而使用‡标记的方法在6倍交叉验证上进行评估。
表3.ScanNet v2验证集上的实例分割和对象检测结果。我们的方法在掩码和盒的AP上都取得了更好的结果。
表4.不同方法在ScanNetv2验证集上的每次扫描推断时间,为了进行公平的比较,运行时是在相同的Titan X GPU型号上测量的。
分割和检测结果。我们进一步报告了在ScanNet v2验证集上的实例分割和目标检测结果。为了获得目标检测结果,我们按照[7]中的方法从预测点掩模(注:或称掩码)中提取紧凑的轴对称的边界框。表3报告了实例分割和目标检测结果。与次优方法相比,我们的方法在AP50、AP25、盒AP50和盒AP25上分别获得了3.2、3.3、6.3和7.3(%)的提升。
运行时间分析。表4报告了ScanNet v2验证集上不同方法的每次扫描运行时间。为了进行公平比较,报告的运行时间是在相同的Titan X GPU型号上测量的。我们的方法每次扫描的推理时间是345ms,比最快的模型多6ms。对于分量时间,逐点预测网络、软分组算法和自上而下求精的延迟分别为152ms、132ms和70ms。结果表明,该方法在保持计算效率的同时,达到了较高的精度。
4.3 定性分析
图5显示了Scan-Net v2数据集的可视化示例。如果没有SoftGroup,语义预测错误会传播到实例分割预测(用虚线框突出显示)。相比之下,SoftGroup有效地纠正了语义预测错误,从而生成了更准确的实例掩码。
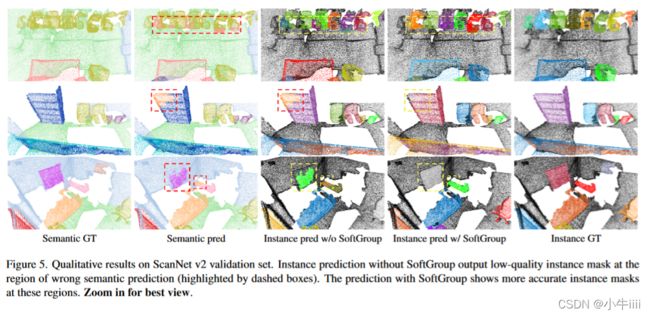
图5.ScanNet v2验证集的定性结果。没有SoftGroup的实例预测会在错误的语义预测区域(用虚线框突出显示)输出低质量的实例掩码。预测显示有SoftGroup的区域的实例掩码更准确。放大以获得最佳视图。
4.4.消融实验
(表5、表6、表7和表8在同一张图中,如下图所示:)
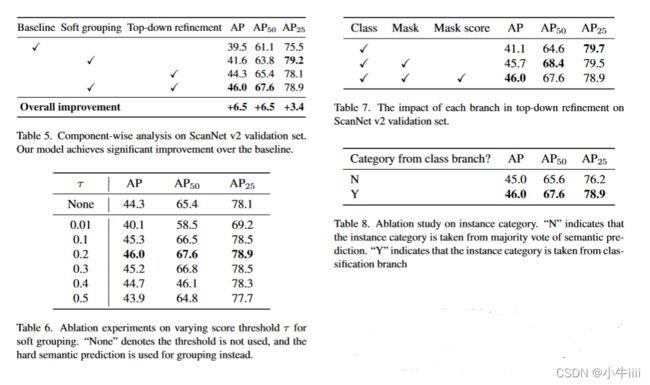
表5.在ScanNet v2验证集上的组件分析。我们的模型在基线上取得了显著的改进。
表6.软分组在不同阈值上的消融实验。“无”表示不使用阈值,而是使用硬语义预测进行分组。
表7.自上而下细化中的每个分支对ScanNet v2验证集的影响。
表8.实例类别的烧蚀研究。“N”表示实例范畴取自语义预测的多数票。Y表示该实例类别取自分类分支
组件方面的分析。我们给出了忽略不同组件时SoftGroup的实验结果,所考虑的基线是一个硬分组的模型,输出实例的置信度得分通过评分网分支[14,17]进行排序。表5显示了消融结果。基准线在AP/AP50/AP25上达到了39.5/61.1/75.5(%)。无论是采用软分组还是采用自上而下的精化,都能获得显著的改善。将这两个组件组合在一起,可获得最佳的AP/AP50/AP25的总体性能,为46.0/67.6/78.9(%),显著高出基线6.5/6.5/3.4(%)。
软分组的得分阈值。表6显示了软分组的不同分数阈值下的实验结果。基线是为“None”,表示阈值被停用,硬预测标签用于分组。基线达到AP/AP50/AP25为44.3/65.4/78.1(%)。当过高或过低时,性能甚至比基线更差。当为0.2时,性能最好,这证实了我们在第3.2节的分析,其中正负样本的数量是平衡的。
自上而下的完善。我们在表7中进一步提供了自上而下细化的消融结果。仅使用分类分支,我们的方法实现了41.1/64.6/79.7%的AP/AP50/AP25。当依次应用掩码分支和掩码评分分支时,在IoU阈值较高的区域,它的表现往往会有所改善。。将所有分支合并后,性能AP/AP50/AP25为46.0/67.6/78.9(%)。
分类分支中的实例类别。表8报告了获取对象类别的不同方案的结果。结果表明,从语义预测推导出对象类别,得到的AP/AP50/AP25为45.0/65.6/76.2(%)。该方法直接使用分类分支的输出作为实例类。分类分支聚合实例的所有点特征,并使用单个标签对实例进行分类,从而获得更可靠的预测。结果表明,直接使用分类输出作为对象类别,可以将AP/AP50/AP25提高到46.0/67.6/78.9(%)。
5 结论
我们提出了分割三维点云的一种简单有效的方法--SoftGroup。SoftGroup对软语义分数进行分组,以解决局部不确定对象的硬分组问题。从分组阶段获得的实例提案被分配给正样本或负样本。然后,构建一个自上而下的精细化阶段,以提炼正样本,抑制负样本。在不同数据集上的扩展实验表明,我们的方法在隐藏的ScanNet v2测试集上的性能比现有的最先进方法高出+6.2%,在S3DIS Area 5的AP50上有+6.8%的显著优势。SoftGroup也很快,处理ScanNet场景需要345ms。
References
[1] Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, IoannisBrilakis, Martin Fischer, and Silvio Savarese. 3d semanticparsing of large-scale indoor spaces. In CVPR, 2016. 2, 5
[2] Mathieu Aubry, Ulrich Schlickewei, and Daniel Cremers.The wave kernel signature: A quantum mechanical approachto shape analysis. In ICCV workshops, 2011. 2
[3] Michael M Bronstein and Iasonas Kokkinos. Scale-invariantheat kernel signatures for non-rigid shape recognition. InCVPR, 2010. 2
[4] Shaoyu Chen, Jiemin Fang, Qian Zhang, Wenyu Liu, andXinggang Wang. Hierarchical aggregation for 3d instancesegmentation. In ICCV, 2021. 1, 3, 4, 5, 6, 7
[5] Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4dspatio-temporal convnets: Minkowski convolutional neuralnetworks. In CVPR, 2019. 2
[6] Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal-ber, Thomas Funkhouser, and Matthias Nießner. Scannet:Richly-annotated 3d reconstructions of indoor scenes. InCVPR, 2017. 2, 5
[7] Francis Engelmann, Martin Bokeloh, Alireza Fathi, BastianLeibe, and Matthias Nießner. 3d-mpa: Multi-proposal ag-gregation for 3d semantic instance segmentation. In CVPR,2020. 6, 7
[8] Benjamin Graham, Martin Engelcke, and Laurens VanDer Maaten. 3d semantic segmentation with submanifoldsparse convolutional networks. In CVPR, 2018. 2, 3
[9] Lei Han, Tian Zheng, Lan Xu, and Lu Fang. Occuseg:Occupancy-aware 3d instance segmentation. In CVPR, 2020.2, 6, 7
[10] Kaiming He, Georgia Gkioxari, Piotr Doll ́ar, and Ross Gir-shick. Mask r-cnn. In ICCV, 2017. 5
[11] Tong He, Chunhua Shen, and Anton van den Hengel.Dyco3d: Robust instance segmentation of 3d point cloudsthrough dynamic convolution. In CVPR, 2021. 6
[12] Ji Hou, Angela Dai, and Matthias Nießner. 3d-sis: 3d seman-tic instance segmentation of rgb-d scans. In CVPR, 2019. 2,4, 6, 7
[13] Zhaojin Huang, Lichao Huang, Yongchao Gong, ChangHuang, and Xinggang Wang. Mask scoring r-cnn. In CVPR,2019. 5
[14] Li Jiang, Hengshuang Zhao, Shaoshuai Shi, Shu Liu, Chi-Wing Fu, and Jiaya Jia. Pointgroup: Dual-set point groupingfor 3d instance segmentation. In CVPR, 2020. 1, 3, 4, 5, 6,7, 8
[15] Diederik P Kingma and Jimmy Ba. Adam: A method forstochastic optimization. In ICVLR, 2015. 5
[16] Jean Lahoud, Bernard Ghanem, Marc Pollefeys, and Mar-tin R Oswald. 3d instance segmentation via multi-task metriclearning. In ICCV, 2019. 2, 6
[17] Zhihao Liang, Zhihao Li, Songcen Xu, Mingkui Tan, andKui Jia. Instance segmentation in 3d scenes using semanticsuperpoint tree networks. In ICCV, 2021. 1, 3, 4, 6, 7, 8
[18] Chen Liu and Yasutaka Furukawa. Masc: Multi-scale affin-ity with sparse convolution for 3d instance segmentation.arXiv:1902.04478, 2019. 6
[19] Shih-Hung Liu, Shang-Yi Yu, Shao-Chi Wu, Hwann-TzongChen, and Tyng-Luh Liu. Learning gaussian instance seg-mentation in point clouds. arXiv:2007.09860, 2020. 2, 4, 6,7
[20] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradientdescent with warm restarts. In ICVLR, 2017. 5
[21] Daniel Maturana and Sebastian Scherer. Voxnet: A 3d con-volutional neural network for real-time object recognition. InIROS, 2015. 2
[22] Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, SubarnaTripathi, Leonidas J Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level3d object understanding. In CVPR, 2019. 7
[23] Gaku Narita, Takashi Seno, Tomoya Ishikawa, and YohsukeKaji. Panopticfusion: Online volumetric semantic mappingat the level of stuff and things. arXiv:1903.01177, 2019. 6
[24] Adam Paszke, Sam Gross, Soumith Chintala, GregoryChanan, Edward Yang, Zachary DeVito, Zeming Lin, Al-ban Desmaison, Luca Antiga, and Adam Lerer. Automaticdifferentiation in pytorch. In NIPS-W, 2017. 5
[25] Quang-Hieu Pham, Thanh Nguyen, Binh-Son Hua, GemmaRoig, and Sai-Kit Yeung. Jsis3d: joint semantic-instancesegmentation of 3d point clouds with multi-task pointwisenetworks and multi-value conditional random fields. InCVPR, 2019. 2
[26] Charles R Qi, Or Litany, Kaiming He, and Leonidas JGuibas. Deep hough voting for 3d object detection in pointclouds. In CVPR, 2019. 7
[27] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas JGuibas. Frustum pointnets for 3d object detection from rgb-ddata. In CVPR, 2018. 7
[28] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas.Pointnet: Deep learning on point sets for 3d classificationand segmentation. In CVPR, 2017. 2
[29] Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Point-net++: Deep hierarchical feature learning on point sets in ametric space. arXiv:1706.02413, 2017. 2
[30] Gernot Riegler, Ali Osman Ulusoy, and Andreas Geiger.Octnet: Learning deep 3d representations at high resolutions.In CVPR, 2017. 2
[31] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmen-tation. In International Conference on Medical image com-puting and computer-assisted intervention, 2015. 3
[32] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fastpoint feature histograms (fpfh) for 3d registration. In ICVRA,2009. 2
[33] Radu Bogdan Rusu, Nico Blodow, Zoltan Csaba Marton, andMichael Beetz. Aligning point cloud views using persistentfeature histograms. In IROS, 2008. 2[
34] Weiyue Wang, Ronald Yu, Qiangui Huang, and Ulrich Neu-mann. Sgpn: Similarity group proposal network for 3d pointcloud instance segmentation. In CVPR, 2018. 2, 6, 7
[35] Xinlong Wang, Shu Liu, Xiaoyong Shen, Chunhua Shen, andJiaya Jia. Associatively segmenting instances and semanticsin point clouds. In CVPR, 2019. 7
[36] Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, SenWang, Andrew Markham, and Niki Trigoni. Learning ob-ject bounding boxes for 3d instance segmentation on pointclouds. In NeurIPS, 2019. 2, 4, 6, 7
[37] Li Yi, Wang Zhao, He Wang, Minhyuk Sung, and Leonidas JGuibas. Gspn: Generative shape proposal network for 3dinstance segmentation in point cloud. In CVPR, 2019. 2, 6,7
38] Biao Zhang and Peter Wonka. Point cloud instance segmen-tation using probabilistic embeddings. In CVPR, 2021. 3
[39] Biao Zhang and Peter Wonka. Point cloud instance segmen-tation using probabilistic embeddings. 2021. 6