FPN论文解读 和 代码详解
FPN论文解读 和 代码详解
论文地址:[Feature Pyramid Networks for Object Detection](1612.03144v2.pdf (arxiv.org))
代码地址:[Detectron/FPN](Detectron/FPN.py at 8170b25b425967f8f1c7d715bea3c5b8d9536cd8 · facebookresearch/Detectron · GitHub)
整篇论文看下来,代码读下来,我对损失函数以及训练定义还是没有特别清楚,如果结尾所说那样,模型是否能够训练成功,效果好不好,我也表示很不理解。
如果有比较清楚的欢迎和我进行探讨
论文解读
简介 关键词摘要
Feature pyramids存在的问题是计算成本太高,内存占用太多.FPN的改进在于只增加了边缘计算成本。
FPN的于是速度6fps/s,没有具体指明哪一类GPU。
Feature pyramids 常用在机器学习中,用来识别人工归纳的特征,图(a)。现在的特征往往通过深度学习网络提取出来的,图(b)。后来在深度学习网络中,来归纳和形成图像金字塔,如图c。特征金子塔如图d。
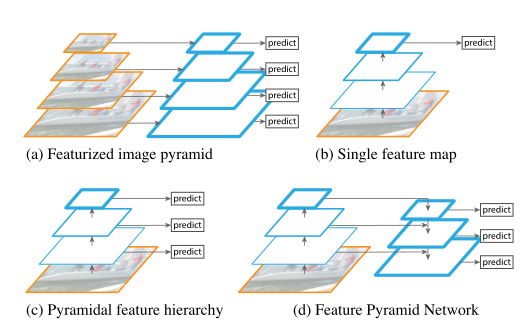
总结,特征金子塔不是新兴的技术,利用卷积神经网络生成的特征金字塔也不是。卷积神经网络的加入替代了原有的特征提取部分。相对于手工提取特征,卷积神经网路和深度神经网络提取特征表现出了良好的语义性,卷积神经网络的特征。但在多尺度目标识别上面,特征金子塔的识别的准确率是明显高过单纯使用卷积神经网络。在原始的Feature pyramids上,不同的层是通过对图像的适量的缩放形成的。但在包含卷积神经网络的架构里面,不同的层是卷积神经网络不同深度的层。
FPN的优势每一层都含有吩咐的语言信息,并且能够较快的从一种尺度图片上面建立。这里原本是将其与Faster R-CNN检测器相结合来进行测试,Faster R-CNN是Fast R-CNN的改进,继承了Roi pooling层,能够将不同尺度的待选锚框,特征向量长度统一化,这个对深度学习,和特征金字塔网络比较重要。

相关工作,研究现状
研究现状就不带大家过,这里只是例举出来。感兴趣自己找相关论文看看。
- Hand-engineered features and early neural networks. SIFT,HOG,DPM
- Deep ConvNet object detectors. OverFeat,RCNN,SPPnet
- Methods using multiple layers FCN,ION,HyperNet,ParseNet,ION
其实这些论文除了比较经典的我也没读过多少,只需要读最近的论文就可以了。如果确实针对某一方面改进可以去看看。
Feature pyramid Networks 特征金字塔网络
FPN网络的架构图:

FPN包含两种路径分别是自底向上,和自顶向下两种方式
自底向上的路径
自底向上的路径主要是特征提取网络主干网络 backbone。因为在这个backbone中有许多层的输出大小是一致的,对于这些输出大小一致的层,我们把它们归为一个阶段,对于一个阶段里面的层,因为输出大小一致,语义包含的信息也差不多。每个阶段,只选取最后一层的输出结果作为特征金字塔的一层。
特别的对于ResNet,我们针对每一个residual block的结果作为特征金子塔的一层。则我们拥有 C 2 , C 3 , C 4 , C 5 {C_2, C_3, C_4, C_5} C2,C3,C4,C5分别代表图像金字塔的四层,对应的步长分别为 {4, 8, 16, 32}。原始图片包含信息太多不利于处理没有选为图像金字塔的一层。
自顶向下的路径和旁路连接
自顶向下的连接是通过upsampling来进行连接的。通过对特征图的放大,因为最后的特征图有非常大的语气信息。横向连接的优势是,自底向上的特征映射较低的语义级别,被二次采样的更少,更容易激活本地化。具体连接方式,见上图的网络架构。
注意到,在自底向上的提取过程中,步长的缩放是成倍的,通过unsampling,每一次侧边连接的时候,两个特征图的大小是一致的,直接可以通过元素加成组合在一起。
在最顶层 C 5 C_5 C5的是采用 C o n v 1 x 1 Conv_{_1x_1} Conv1x1来生成top-down最上面的那一层,针对于每一个已经meraged map使用 C o n v 3 x 3 Conv_{_3x_3} Conv3x3生成最后的特征图
总结
上面已经介绍了FPN的核心内容,但文中没有介绍每一层的predict预测器是如何训练的,损失函数的定义。FPN的每一层包含不同尺度语义信息和输入信息后,并且这些特征网络,提取层都可以进行共用和复用,没有改变原有的backbone的训练方式,训练消耗资源增加较小。
应用
应用中例举了几种常见的目标检测模型和FPN的结合,在适配中针对模型进行了一定的修改,直接上结果图吧

代码详解
官方代码的实现是FPN加上ResNet 实现
# ---------------------------------------------------------------------------- #
# FPN with ResNet
# ---------------------------------------------------------------------------- #
def add_fpn_ResNet50_conv5_body(model):
return add_fpn_onto_conv_body(
model, ResNet.add_ResNet50_conv5_body, fpn_level_info_ResNet50_conv5
)
def add_fpn_ResNet50_conv5_P2only_body(model):
return add_fpn_onto_conv_body(
model,
ResNet.add_ResNet50_conv5_body,
fpn_level_info_ResNet50_conv5,
P2only=True
)
def add_fpn_ResNet101_conv5_body(model):
return add_fpn_onto_conv_body(
model, ResNet.add_ResNet101_conv5_body, fpn_level_info_ResNet101_conv5
)
def add_fpn_ResNet101_conv5_P2only_body(model):
return add_fpn_onto_conv_body(
model,
ResNet.add_ResNet101_conv5_body,
fpn_level_info_ResNet101_conv5,
P2only=True
)
def add_fpn_ResNet152_conv5_body(model):
return add_fpn_onto_conv_body(
model, ResNet.add_ResNet152_conv5_body, fpn_level_info_ResNet152_conv5
)
def add_fpn_ResNet152_conv5_P2only_body(model):
return add_fpn_onto_conv_body(
model,
ResNet.add_ResNet152_conv5_body,
fpn_level_info_ResNet152_conv5,
P2only=True
)
上面代码分别在几个常见的ResNet中添加了FPN的模型
# 增加FPN的函数
def add_fpn(model, fpn_level_info):
"""Add FPN connections based on the model described in the FPN paper."""
# FPN levels are built starting from the highest/coarest level of the
# backbone (usually "conv5"). First we build down, recursively constructing
# lower/finer resolution FPN levels. Then we build up, constructing levels
# that are even higher/coarser than the starting level.
fpn_dim = cfg.FPN.DIM
min_level, max_level = get_min_max_levels()
# Count the number of backbone stages that we will generate FPN levels for
# starting from the coarest backbone stage (usually the "conv5"-like level)
# E.g., if the backbone level info defines stages 4 stages: "conv5",
# "conv4", ... "conv2" and min_level=2, then we end up with 4 - (2 - 2) = 4
# backbone stages to add FPN to.
num_backbone_stages = (
len(fpn_level_info.blobs) - (min_level - LOWEST_BACKBONE_LVL)
)
lateral_input_blobs = fpn_level_info.blobs[:num_backbone_stages]
output_blobs = [
'fpn_inner_{}'.format(s)
for s in fpn_level_info.blobs[:num_backbone_stages]
]
fpn_dim_lateral = fpn_level_info.dims
xavier_fill = ('XavierFill', {})
# For the coarsest backbone level: 1x1 conv only seeds recursion
if cfg.FPN.USE_GN:
# use GroupNorm
c = model.ConvGN(
lateral_input_blobs[0],
output_blobs[0], # note: this is a prefix
dim_in=fpn_dim_lateral[0],
dim_out=fpn_dim,
group_gn=get_group_gn(fpn_dim),
kernel=1,
pad=0,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
output_blobs[0] = c # rename it
else:
model.Conv(
lateral_input_blobs[0],
output_blobs[0],
dim_in=fpn_dim_lateral[0],
dim_out=fpn_dim,
kernel=1,
pad=0,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
#
# Step 1: recursively build down starting from the coarsest backbone level
#
# 构建自顶向下的模型
# For other levels add top-down and lateral connections
for i in range(num_backbone_stages - 1):
add_topdown_lateral_module(
model,
output_blobs[i], # top-down blob
lateral_input_blobs[i + 1], # lateral blob
output_blobs[i + 1], # next output blob
fpn_dim, # output dimension
fpn_dim_lateral[i + 1] # lateral input dimension
)
# 构建3x3的卷积层
# Post-hoc scale-specific 3x3 convs
blobs_fpn = []
spatial_scales = []
for i in range(num_backbone_stages):
if cfg.FPN.USE_GN:
# use GroupNorm
fpn_blob = model.ConvGN(
output_blobs[i],
'fpn_{}'.format(fpn_level_info.blobs[i]),
dim_in=fpn_dim,
dim_out=fpn_dim,
group_gn=get_group_gn(fpn_dim),
kernel=3,
pad=1,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
else:
fpn_blob = model.Conv(
output_blobs[i],
'fpn_{}'.format(fpn_level_info.blobs[i]),
dim_in=fpn_dim,
dim_out=fpn_dim,
kernel=3,
pad=1,
stride=1,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
blobs_fpn += [fpn_blob]
spatial_scales += [fpn_level_info.spatial_scales[i]]
#
# Step 2: build up starting from the coarsest backbone level
#
# Check if we need the P6 feature map
if not cfg.FPN.EXTRA_CONV_LEVELS and max_level == HIGHEST_BACKBONE_LVL + 1:
# Original FPN P6 level implementation from our CVPR'17 FPN paper
P6_blob_in = blobs_fpn[0]
P6_name = P6_blob_in + '_subsampled_2x'
# Use max pooling to simulate stride 2 subsampling
P6_blob = model.MaxPool(P6_blob_in, P6_name, kernel=1, pad=0, stride=2)
blobs_fpn.insert(0, P6_blob)
spatial_scales.insert(0, spatial_scales[0] * 0.5)
# Coarser FPN levels introduced for RetinaNet
if cfg.FPN.EXTRA_CONV_LEVELS and max_level > HIGHEST_BACKBONE_LVL:
fpn_blob = fpn_level_info.blobs[0]
dim_in = fpn_level_info.dims[0]
for i in range(HIGHEST_BACKBONE_LVL + 1, max_level + 1):
fpn_blob_in = fpn_blob
if i > HIGHEST_BACKBONE_LVL + 1:
fpn_blob_in = model.Relu(fpn_blob, fpn_blob + '_relu')
fpn_blob = model.Conv(
fpn_blob_in,
'fpn_' + str(i),
dim_in=dim_in,
dim_out=fpn_dim,
kernel=3,
pad=1,
stride=2,
weight_init=xavier_fill,
bias_init=const_fill(0.0)
)
dim_in = fpn_dim
blobs_fpn.insert(0, fpn_blob)
spatial_scales.insert(0, spatial_scales[0] * 0.5)
return blobs_fpn, fpn_dim, spatial_scales
可以从代码中看出,在ResNet本体中已经构建了自顶向下的过程
在ResNet中添加FPN的模型就是,构建自顶向下的过程
首先是计算最顶上的那个块,因为最顶上的块没有从上往下的输入,只能通过ResNet 加上 1x1 的卷积得以实现 GN 是GroupNormal 批量归一化,对使用批量归一化的模型单独进行处理
第二部是通过递归构建出不同的FPN的模块,因为FPN的模块是相互关联的需要确定参数,构建完成FPN模块后,在添加3x3的卷积层,将每一层的结果作为输出结果
重点来了 fpn的损失函数
def add_fpn_rpn_losses(model):
"""Add RPN on FPN specific losses."""
loss_gradients = {}
for lvl in range(cfg.FPN.RPN_MIN_LEVEL, cfg.FPN.RPN_MAX_LEVEL + 1):
slvl = str(lvl)
# Spatially narrow the full-sized RPN label arrays to match the feature map
# shape
model.net.SpatialNarrowAs(
['rpn_labels_int32_wide_fpn' + slvl, 'rpn_cls_logits_fpn' + slvl],
'rpn_labels_int32_fpn' + slvl
)
for key in ('targets', 'inside_weights', 'outside_weights'):
model.net.SpatialNarrowAs(
[
'rpn_bbox_' + key + '_wide_fpn' + slvl,
'rpn_bbox_pred_fpn' + slvl
],
'rpn_bbox_' + key + '_fpn' + slvl
)
loss_rpn_cls_fpn = model.net.SigmoidCrossEntropyLoss(
['rpn_cls_logits_fpn' + slvl, 'rpn_labels_int32_fpn' + slvl],
'loss_rpn_cls_fpn' + slvl,
normalize=0,
scale=(
model.GetLossScale() / cfg.TRAIN.RPN_BATCH_SIZE_PER_IM /
cfg.TRAIN.IMS_PER_BATCH
)
)
# Normalization by (1) RPN_BATCH_SIZE_PER_IM and (2) IMS_PER_BATCH is
# handled by (1) setting bbox outside weights and (2) SmoothL1Loss
# normalizes by IMS_PER_BATCH
loss_rpn_bbox_fpn = model.net.SmoothL1Loss(
[
'rpn_bbox_pred_fpn' + slvl, 'rpn_bbox_targets_fpn' + slvl,
'rpn_bbox_inside_weights_fpn' + slvl,
'rpn_bbox_outside_weights_fpn' + slvl
],
'loss_rpn_bbox_fpn' + slvl,
beta=1. / 9.,
scale=model.GetLossScale(),
)
loss_gradients.update(
blob_utils.
get_loss_gradients(model, [loss_rpn_cls_fpn, loss_rpn_bbox_fpn])
)
model.AddLosses(['loss_rpn_cls_fpn' + slvl, 'loss_rpn_bbox_fpn' + slvl])
return loss_gradients
这个是RPN + FPN的损失函数
首先
for lvl in range(cfg.FPN.RPN_MIN_LEVEL, cfg.FPN.RPN_MAX_LEVEL + 1):
这个和Losses表明 FPN的损失函数不是单一,基本上FPN每一层predict都会计算一个losses这个是相互独立的
其中 分类函数采用的是交叉熵损失函数
而 Bbox采用的是SmoothL1loss函数
分别计算 loss gradient
if model.train:
loss_gradients = {}
for lg in head_loss_gradients.values():
if lg is not None:
loss_gradients.update(lg)
return loss_gradients
训练函数,没有看到比较独特的处理流程,可能是从min_level的输出到max_level 进行依次训练。
在FPN中来进行训练,因为FPN金子塔顶是最高层,也就是粗糙层,最大层。塔底是精细层。训练是从精细层来优化参数。