【ICC】Inception-Based Crowd Counting — Being Fastwhile Remaining Accurate解读
论文名称:Inception-Based Crowd Counting -- Being Fast while Remaining Accurate
论文地址:https://arxiv.org/abs/2210.09796
简单概括:这篇文章是为了解决CNN在实时估计(视频计数)计算量比较大的问题,引入了Inception-V3来解决这个问题。
1.摘要
复杂的CNN被用来解决头部多尺度问题,但是CNN复杂度高,导致实时估计不切实际。所以我们提出用 Inception-V3来解决复杂度高这个问题。我们的方法(ICC)使用inception前五层,并用一个contextual module(来自CAN这篇论文)来提取不同尺度的信息。
2.介绍
人群计数在现实中有不少应用。1. 来自监控视频的视频被分解成帧放入人群计数模型预测人数。2.公交公司计数站台人数,动态调整发车时间。
但是目前的方法有一些问题。
1.backbone降低了推理速度。使用最多的VGG采用标准卷积,处理720P图片需要数千亿算术操作。而Inception-V3多采用1x1和空间可分离卷积,大大减少开销。
2.缺少适当的预训练模型。UCF CC 50,ShanghaiTech (A and B) 和 UCF-QNRF是几个流行的人数计数数据集。大多数人公开的是这几个的权重。尽管SHB是监控视角,但是他只有拥挤场景的。其他三个数据集是随机视角并且更拥挤。所以这些数据集并不能代表现实生活中监控场景。Crowd Surveillanc数据集(来自Perspective-guided convolution networks for crowd counting
)就很合适,既有稀疏又有拥挤场景的监控视角数据集。这个数据集比较适合训练模型。
简言之,这篇文章的贡献:
1.利用Inception-V3提出一个极小的的人群计数模型。
2.准备开源一个Crowd Surveillance的预训练权重。
3.方法
先公式化了一下问题。假设X是RGB图片,Y是对应的二进制密度图,p(X)是X的分布。L是loss函数,F(,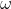 )是用w参数化的函数。对于一般的人群计数算法和给定损失函数L来说,数学目标是拟合函数F来最小化代价。如下公式所示:
)是用w参数化的函数。对于一般的人群计数算法和给定损失函数L来说,数学目标是拟合函数F来最小化代价。如下公式所示:

最小值记为CF

现实生活中X的分布不可见,X和Y可以获得(图片和他的二进制密度图),这不可避免导致过拟合。数据一般被划分成train集和test集。train集优化在train集的代价函数,如下

在test集上计算最小值CF

因为这篇文章是要做实时估计,所以F被限制在一个特定的范围内F(花体)。最终目的就是求F在特定范围内

3.1网络模型

1)The Encoding Front End
首先是前12个block来自预训练的Inception-V3,Feature1是第二个maxpooling的输出,和CAN中庸VGG提取的base feature很像,区别就是Feature1是浅层的输出,容纳更丰富的信息。第三个Inception-A block的输出作为Feature2。为了减少参数,第一个Inception-C block后截断Inception-V3,Inception-C block输出作为Feature3。
2)Contextual Information Extraction
有两种策略来提取信息。
a.来自CAN的contextual module
CAN没看过的可以看我这篇解读。[CAN] [CVPR2019]:Context-Aware Crowd Counting论文+代码解读_行走的人参的博客-CSDN博客_context-aware
利用1x1,2x2,3x3,6x6的卷积来提取信息。这篇文章是把Feature1作为这四个卷积的输入,并且由于使用了1x1的卷积可以保留大量细节。并且这样得到特征是context-aware,因为可以准确的预测大小头。
b.使用来自front end的Inception blocks
这些block中有bottleneck架构可以学习稀疏和非稀疏的特征。并且这些块在深层,在Feature2和Feature3 提取过程中,上下文信息被反复融合。由于Feature2和Feature2已经包含上下文信息,因此不需要对它们进行进一步处理,所有这些上特征最终都会沿着channel维度进行组合。
简言之,Feature2和Feature2从front end拿过来就没处理。直接用了。
3)The Decoding Back End
1x1后面跟一个3x3。1x1用来降维,最后输出一个密度图。比较简单没什么东西。最后的密度图是原来的1/8,因为用了stride=2的下采样操作。可以利用插值上采样到原图大小。
4)Loss
用的DM-COUNT的loss,本文特别指出optimal transport cost是p到q的传输最小成本。这涉及一个优化问题。这篇文章说他用Sinkhorn Knopp矩阵缩放算法(分别对每行或列求和,再对每个数除以其和,重复该过程以达到缩放的目的。)实现。并且可以直接调用python POT这个包实现。
最终loss如下公式所示: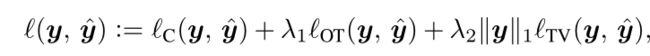
4.实验
复杂度下降挺多,就是精度比较一般了。

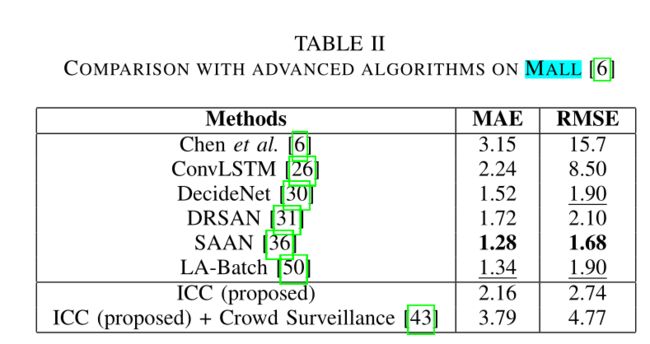
消融就做了一个实验:两个东西都有用,看起来是contextal modelu更有用些。这篇文章消融太少了,我估计还会在补充的把。