【MAFNet】 A Multi-Attention Fusion Networkfor RGB-T Crowd Counting解读
论文:https://arxiv.org/abs/2208.06761
二作是Junyu Gao,github上awesome-crowd-counting千星的作者。推荐一下他的github:GitHub - gjy3035/Awesome-Crowd-Counting: Awesome Crowd Counting
平常我就在这里面找crowd counting的论文看。
本文主要是通过利用热图像信息作为额外信息来解决人群计数中单RGB图像在低光照和相似背景表现不佳的问题。
1.摘要
RGB-T人群计数任务是利用热图像作为RBG图像的补充信息,来解决单RGB图像在低光照和相似背景表现不佳的问题。当前方法不能编码RBG-T图像对的跨模态上下文语义信息。因此,提出双流RGB-T人群计数网络MultiAttention Fusion Network (MAFNet),利用自注意力机制从RGB中获得长依赖上下文信息和学习热模态。在Encoder中,Multi-Attention Fusion (MAF)嵌入到两个模态特定分支的不同阶段,来进行全局跨模态融合。Multi-modal Multi-scale Aggregation (MMA) 回归头充分利用跨模态的多尺度和上下文信息,生成人群密度图。
2.介绍
当前人群计数方法主要用RGB图像,但是RGB容易受光照的影响,在低光照和相似背景下效果不佳。热图像不受光照影响,可以穿透烟雾。可以把热图像作为补充信息来学习。
如图,低光下人看不见,但是热图可以清晰看见人的轮廓。 热图分辨率低,并且存在热交叉导致的不同目标混淆问题。RBG图像分辨率高,语义信息丰富,可以弥补热图缺点。所以这启发我们研究RGB-T跨模态融合问题。目前主流RGB-T用的是纯CNN,不能捕获长依赖上下文信息。

采用Transformer中自注意力来学习跨模态全局信息。本文提出一个双分支网络MAFNet,用两个VGG19学习模态特定表征;MAF)模块捕获跨模态多层级全局信息。另外,由于下采样会损失一些关键信息,我们提出MMA回归头来冲分利用跨模态的多尺度信息生成高质量密度图。
3.方法

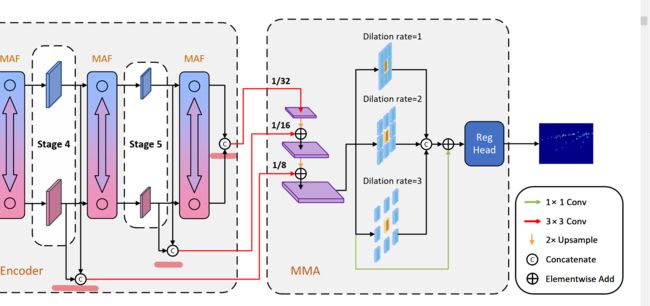
网络如图所示:RBG和热图同时喂到去除全连接层的VGG19中。 VGG19五个阶段,每个阶段最后一层有一个stride为2的max pooling层来下采样。如果两种模态之间的大规模特征信息交互是在浅层阶段进行的,融合效果可能会受到成对RGB-T数据的未特征对齐的影响。因此MAF模块嵌入在深层,以融合具有小尺度但高级语义信息的特征。特征提取阶段max pooling的平移不变性缓解了特征没有对齐的问题。
从第三阶段开始,特征先经过backbone再放入MAF模块,最终MAF模块的输出是输入图像的1/8、1/16、1/32,对应通道数256, 512, 512。
3.1Multi-Attention Fusion Module
MAF其实很简单,就是一个标准的self-attention(不懂的先去看transformer)+一个跨域的self-attention。
拿到特征先打成patch,在IMA中是对同一模态作self-attention。比如说对于来自RGB的特征,我仅对来自RGB的特征作self-attention。
CMA就是对跨模态作self-attention,原先我的Q都是来自RGB的特征,但是在CMA中我的Q来自另外一个模态。比如说我RGB的Q变成了来自热图的Q,这样热图就能够学习RGB的全局信息,而RGB学习了热图的全局信息。从而达到了学习不同模态全局信息的目的。

IMA的token和CMA出来的token做乘法,通过MLP和reshape还原回特征形式。
3.2 Multi-Modal Multi-Scale Aggregation Regression Head
下采样会导致信息丢失,本文提了一个回归头解决这个问题。从MAF中出来的成对特征先concat然后经过一个3x3卷积聚合信息。不同尺寸信息上采样到相同尺度并相加,然后放入有着不同空洞率的四分支结构,三个分支分别是3x3,空洞率为1,2,3的卷积,还有一个分支是1x1的跳跃连接。(这里的做法和CCtrans是一样的),得到的结果concat并与原来的特征残差相加。最后喂到3x3和1x1中生成密度图。
总的来看,这个模块没有什么新意。和cctrans一样,唯一区别是她融合的两个模态的特征。
4.Loss
MSE loss

5.实验

总的来看跨模态self-attention(CMA)比不跨的一般self-attention(IMA)更好,和基线相比每个模块都有用。三个模块相比,感觉还是CMA的用处比较大。
和其他方法相比,如下图:没有MMA效果就比他列出的好。

还有一个位置消融比较有意思,发现位置信息有和没有都差不多,作者认为原因是MAF模块的跳跃连接引入了卷积的归纳偏置,提供了位置信息。
还有一个消融是比较MAF模块的个数,可以看出越多越好,当3个MAF最好,4个开始性能下降。因为浅层的时候特征不能对齐,所以他这边nums增加是从深层往浅层增加的方式,这样也算把在什么位置插入也做了消融实验把。
depth表示MAF堆叠个数,可以看出2,2,2这个选择比较好,因为MAE(GAME(0)) 和 RMSE这两个指标比较重要。
6.结论
这篇文章MMA模块的思路我在cctrans看见过,跨模态的self-attention感觉也在什么其他地方看见过。不过这篇文章实验做的挺多的,解释的也比较详细。代码尚为开源。