深入理解 Batch-Normalization 前向传播 forward /反向传播 backward 以及 代码实现
深入理解 Batch-Normalization
BN 能显著提升神经网络模型的训练速度(论文),自2015年被推出以来,已经成为神经网络模型的标准层。
现代深度学习框架(如 TF、Pytorch 等)均内置了 BN 层,使得我们在搭建网络轻而易举。但这也间接造成很多人对于 BN 的理解只停留在 概念 层面,而没有深入公式,详细推导其行为 (前向传播+反向传播)。
本文的主旨则是从数学公式层面,详细推导 BN,并通过代码手动实现BN 层。
一、BN 的 前向传播
让我们从原论文中最出名的一张图开始吧:

(图1: BN 的前向传播)
BN的前向传播过程分别在不同阶段的行为可以概述如下:
训练阶段:
- 对每个批次的输入 x,[ ‼️重要:在batch 方向上‼️],计算 均值 μ B {\mu}_B μB 和 方差 σ B 2 {\sigma}^2_B σB2:
- μ B = 1 m ∑ i m x i {\mu}_B = \frac{1}{m} \sum_i^m{x_i} μB=m1∑imxi
- σ B 2 = 1 m ∑ i m ( x i − μ B ) 2 {\sigma}^2_B = \frac{1}{m} \sum_i^m{{(x_i - {\mu}_B)}^2} σB2=m1∑im(xi−μB)2
- 利用 μ B {\mu}_B μB 和 σ B 2 {\sigma}^2_B σB2 对输入 x 进行标准化:
- x i ^ = x i − μ B σ B 2 + ϵ \hat{x_i} = \frac{x_i - \mu_B}{\sqrt{{\sigma}^2_B + \epsilon}} xi^=σB2+ϵxi−μB
- 引入可学习参数 γ \gamma γ 和 β \beta β, 对标准化后的 x i ^ \hat{x_i} xi^ 进行 缩放 和 平移,作为 BN 层的最终输出值:
- y i = γ x i ^ + β y_i=\gamma\hat{x_i}+\beta yi=γxi^+β
注意:
训练过程 中会以指数平均的方式计算整个训练集的 平均均值(running mean) 和 平均方差(running_var),这两个值将在 测试阶段 代替 μ B {\mu}_B μB 和 σ B 2 {\sigma}^2_B σB2 对 x 进行归一化:
- r u n n i n g _ m e a n = m o m e n t u m ∗ r u n n i n g _ m e a n + ( 1 − m o m e n t u m ) ∗ μ B running\_mean=momentum * running\_mean + (1-momentum)*\mu_B running_mean=momentum∗running_mean+(1−momentum)∗μB
- r u n n i n g _ v a r = m o m e n u t m ∗ r u n n i n g _ v a r + ( 1 − m o m e n t u m ) ∗ σ B 2 running\_var=momenutm * running\_var + (1-momentum)*\sigma^2_B running_var=momenutm∗running_var+(1−momentum)∗σB2
测试阶段
在这个阶段的计算流程大体与训练阶段相同,但不会计算 μ B {\mu}_B μB 和 σ B 2 {\sigma}^2_B σB2,而是分别以 running_mean 和 running_var 代替。
说明:
- 对于 Linear 层,设 x 的维度为 [N, D];那么上面那些公式中的值都是什么维度?
- μ B {\mu}_B μB 和 σ B 2 {\sigma}^2_B σB2: [D]
- x i ^ \hat{x_i} xi^ 和 y i y_i yi: [N,D]
- running_mean 和 running_var: [D]
- γ \gamma γ 和 β \beta β: [D]
- 如果是Conv 层,设 x 的维度为 [N, C, H, W]; 那么上面那些公式中的值都是什么维度?
- 这种情况要特别注意⚠️,对于卷基层,BN 计算均值和方差将会考虑 H 和 W 的维度,在 Pytorch 中称为 BatchNorm2D,如下图所示:

(图2: BatchNorm2D)
- 这种情况要特别注意⚠️,对于卷基层,BN 计算均值和方差将会考虑 H 和 W 的维度,在 Pytorch 中称为 BatchNorm2D,如下图所示:
二、BN 的 反向传播
反向传播的要点是找到 Loss 对当前节点中所有参数的梯度以及对节点的输入张量 x 的梯度,即 ∂ L ∂ γ \frac{\partial L}{\partial \gamma} ∂γ∂L、 ∂ L ∂ β \frac{\partial L}{\partial \beta} ∂β∂L 以及 ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L。
由 链式法则可知,这些梯度均等于 上游梯度 * 局部梯度:
- ∂ L ∂ γ = ∂ L ∂ o u t ∗ ∂ o u t ∂ γ \frac {\partial L}{\partial \gamma}=\frac {\partial L}{\partial out}*\frac {\partial out}{\partial \gamma} ∂γ∂L=∂out∂L∗∂γ∂out
- ∂ L ∂ β = ∂ L ∂ o u t ∗ ∂ o u t ∂ β \frac {\partial L}{\partial \beta}=\frac {\partial L}{\partial out}*\frac {\partial out}{\partial \beta} ∂β∂L=∂out∂L∗∂β∂out
- ∂ L ∂ x = ∂ L ∂ o u t ∗ ∂ o u t ∂ x \frac {\partial L}{\partial x}=\frac {\partial L}{\partial out}*\frac {\partial out}{\partial x} ∂x∂L=∂out∂L∗∂x∂out
注意:在这些公式中,上游梯度( ∂ L ∂ o u t \frac {\partial L}{\partial out} ∂out∂L) 是已知的,因此我们只需要求 局部梯度 即可。
方法一:根据计算图求梯度
思路:
为了求得 局部梯度,我们可以把 BN 中每一个计算步骤均绘制成计算图,然后按照计算图反向传播,那么问题就迎刃而解了。
这种方法实现起来特别简单,因为每个步骤的计算公式都是独立的,此时计算局部梯度几乎是轻而易举的事,只需要牢记 链式法则(YYDS),那么SO EASY!!!
这部分网上有一篇特别棒的文章,非常清晰的讲解了这种方法,搭配了Numpy代码讲解,强烈建议阅读!! 具体的步骤我就不赘述了,这里只给出我按照种方式实现的 Pytorch 版本。
注: 代码段来源于 密西根大学的计算机视觉课程: EECS 498-007 / 598-005
Deep Learning for Computer Vision 的 Assignment-3 作业.
def backward(dout, cache):
xhat, gamma, xmu, ivar, sqrtvar = cache
N = dout.shape[0]
# Step9:
dbeta = torch.sum(dout, dim=0)
dgammaxhat = dout
# Step8:
dgamma = torch.sum(dgammaxhat * xhat, dim=0)
dxhat = dgammaxhat * gamma
# Step7:
divar = torch.sum(dxhat * xmu, dim=0)
dxmu = dxhat * ivar
# Step6:
dsqrtvar = divar * (-1. / sqrtvar ** 2)
# Step5:
dvar = dsqrtvar * (0.5 / sqrtvar)
# Step4:
dsq = dvar * (1. / N)
# Step3:
dxmu += dsq * 2. * xmu
# Step2:
dmu = -1. * torch.sum(dxmu, dim=0)
dx = dxmu
# Step1:
dx += dmu * (1. / N)
return dx, dgamma, dbeta
我不会解释这种方法,因为文章中把该解释的都解释了。但我想说的是这种方法不是最优的,因为每一步计算都明确给出了梯度。
事实上,我们可以做的更聪明些,把很多没必要的计算进行“融合”,就像我们计算 sigmoid 的梯度不会精确到每一步计算一样,而是直接写出梯度。下一小节讲重点介绍这种方法。
方法二: BN 的梯度计算 - Analitical Solution
最好的方式是我们首先在纸上计算好梯度,然后直接应用公式得出结果!!
这部分在网上也有几篇博客,推荐大家看下,不过在我尝试了几次后,我发现根据他们的结果我的程序无法得出正确结果!!
- Deriving the Gradient for the Backward Pass of Batch Normalization
- Back Propagation in Batch Normalization Layer
这促使我自己推导公式,下面是完整的步骤。
首先,让我们来回顾一下 BN 中符号,了解中间变量,这可以使我们不会在众多的计算中迷失方向:
- μ \mu μ : 等同于上文中的 μ B \mu_B μB,表示当前batch的均值(或期望);
- v v v: 等同于上文中的 σ B 2 \sigma^2_B σB2,表示当前batch的方差;
- σ \sigma σ: 等同于上文中的 σ 2 + ϵ \sqrt {\sigma^2 + \epsilon} σ2+ϵ,表示当前batch的标准差;
- γ \gamma γ 和 β \beta β: 缩放 和 平移 参数;
- y y y: 等同于上文中的 x ^ \hat{x} x^,表示标准化后的中间张量;
- z z z: BN 的输出张量。
其次,我们再看看 BN 的简要版计算图,这将帮助我们知道哪些变量会对梯度有贡献:
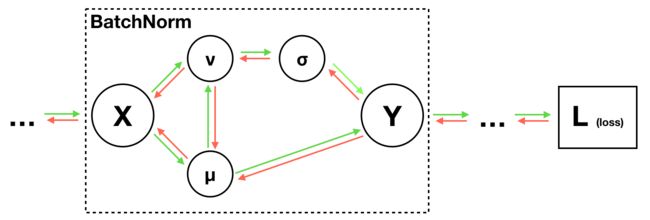
(图3: BN简要计算图)
计算公式如下:
- 1⃣️ μ = 1 N ∑ j = 1 N x j \mu=\frac{1}{N}\sum_{j=1}^N x_j μ=N1∑j=1Nxj
- 2⃣️ v = 1 N ∑ j = 1 N ( x j − μ ) 2 v=\frac{1}{N}\sum_{j=1}^N (x_j-\mu)^2 v=N1∑j=1N(xj−μ)2 ,
- 3⃣️ σ = v + ϵ \sigma=\sqrt{v+\epsilon} σ=v+ϵ
- 4⃣️ y i = x i − μ σ y_i=\frac{x_i-\mu}{\sigma} yi=σxi−μ
- 5⃣️ z i = γ ∗ y i + β z_i=\gamma*y_i+\beta zi=γ∗yi+β
我们的目的是要计算:
- ∂ L ∂ γ \frac {\partial L}{\partial \gamma} ∂γ∂L、 ∂ L ∂ β \frac {\partial L}{\partial \beta} ∂β∂L、 ∂ L ∂ x \frac {\partial L}{\partial x} ∂x∂L
1. ∂ L ∂ γ \frac {\partial L}{\partial \gamma} ∂γ∂L 的计算
由 链式法则 可知: ∂ L ∂ γ = ∂ L ∂ z ∗ ∂ z ∂ γ \frac {\partial L}{\partial \gamma}=\frac {\partial L}{\partial z}*\frac {\partial z}{\partial \gamma} ∂γ∂L=∂z∂L∗∂γ∂z
注意:
- 上式中 z 是矩阵,直接计算矩阵的梯度比较难,那么我们不妨先对某一个单独的输入 x i x_i xi计算梯度,然后应用到整个矩阵。
- 不要忘了, ∂ L ∂ z \frac {\partial L}{\partial z} ∂z∂L 是 上游梯度,在当前节点这是已知值,我们只需要计算 局部梯度。
对于某一个单独的输入 z i z_i zi,我们计算梯度: ∂ z i ∂ γ = y i \frac {\partial z_i}{\partial \gamma}= y_i ∂γ∂zi=yi
显然所有 ∂ z i ∂ γ \frac {\partial z_i}{\partial \gamma} ∂γ∂zi 都会对 ∂ L ∂ γ \frac {\partial L}{\partial \gamma} ∂γ∂L 有贡献,因此不难得出结论1⃣️:
- 1⃣️ ∂ L ∂ γ = ∑ j = 1 N ∂ L ∂ z j ∗ y j \frac {\partial L}{\partial \gamma}=\sum_{j=1}^N\frac {\partial L}{\partial z_j}*y_j ∂γ∂L=∑j=1N∂zj∂L∗yj
2. ∂ L ∂ β \frac {\partial L}{\partial \beta} ∂β∂L 的计算
同 ∂ L ∂ γ \frac {\partial L}{\partial \gamma} ∂γ∂L 计算原理相同,我们很容易就能得出结论2⃣️:
- 2⃣️ ∂ L ∂ β = ∑ j = 1 N ∂ L ∂ z j ∗ 1 = ∑ j = 1 N ∂ L ∂ z j \frac {\partial L}{\partial \beta}=\sum_{j=1}^N\frac {\partial L}{\partial z_j} * 1 =\sum_{j=1}^N\frac {\partial L}{\partial z_j} ∂β∂L=∑j=1N∂zj∂L∗1=∑j=1N∂zj∂L
3. ∂ L ∂ x \frac {\partial L}{\partial x} ∂x∂L 的计算
这部分最难,中间变量众多,我们得非常小心。查看计算图可知,x 对三个变量有直接贡献: μ \mu μ、 v v v 和 Y Y Y 。
其中 X -> Y Y Y 这条连接在图3中没有画出来,但我们从公式4⃣️知道,这确实存在!由此可知:
- ∂ L ∂ x i = ∂ L ∂ y i ∗ ∂ y i ∂ x i + ∂ L ∂ v ∗ ∂ v ∂ x i + ∂ L ∂ u ∗ ∂ u ∂ x i \frac {\partial L}{\partial x_i} = \frac {\partial L}{\partial y_i}*\frac {\partial y_i}{\partial x_i}+\frac {\partial L}{\partial v}*\frac {\partial v}{\partial x_i}+\frac {\partial L}{\partial u}*\frac {\partial u}{\partial x_i} ∂xi∂L=∂yi∂L∗∂xi∂yi+∂v∂L∗∂xi∂v+∂u∂L∗∂xi∂u
我们一项一项来。
第一项: ∂ L ∂ y i ∗ ∂ y i ∂ x i \frac {\partial L}{\partial y_i}*\frac {\partial y_i}{\partial x_i} ∂yi∂L∗∂xi∂yi:
- ∂ L ∂ y i \frac {\partial L}{\partial y_i} ∂yi∂L:
由于 y i y_i yi 只对 z i z_i zi 有贡献,因此: ∂ L ∂ y i = ∂ L ∂ z i ∗ ∂ z i ∂ y i = ∂ L ∂ z i ∗ γ \frac {\partial L}{\partial y_i}=\frac {\partial L}{\partial z_i}*\frac {\partial z_i}{\partial y_i}=\frac {\partial L}{\partial z_i}*\gamma ∂yi∂L=∂zi∂L∗∂yi∂zi=∂zi∂L∗γ - ∂ y i ∂ x i \frac {\partial y_i}{\partial x_i} ∂xi∂yi:
这一项是指 x i x_i xi 对 y i y_i yi 的直接贡献,由公式4⃣️可知: ∂ y i ∂ x i = 1 σ \frac {\partial y_i}{\partial x_i}=\frac{1}{\sigma} ∂xi∂yi=σ1
综上可得: ∂ L ∂ y i ∗ ∂ y i ∂ x i = ∂ L ∂ y i ∗ 1 σ \frac {\partial L}{\partial y_i}*\frac {\partial y_i}{\partial x_i}=\frac {\partial L}{\partial y_i}*\frac{1}{\sigma} ∂yi∂L∗∂xi∂yi=∂yi∂L∗σ1
第二项: ∂ L ∂ v ∗ ∂ v ∂ x i \frac {\partial L}{\partial v}*\frac {\partial v}{\partial x_i} ∂v∂L∗∂xi∂v
- ∂ v ∂ x i \frac {\partial v}{\partial x_i} ∂xi∂v:
- 由公式2⃣️, ∂ v ∂ x i = 1 N ∗ 2 ∗ ( x i − μ ) \frac {\partial v}{\partial x_i}=\frac{1}{N}*2*(x_i-\mu) ∂xi∂v=N1∗2∗(xi−μ)
- ∂ L ∂ v = ∑ j = 1 N ∂ L ∂ y j ∂ y j ∂ v = ∑ j = 1 N ∂ L ∂ y j ∂ y j ∂ σ ∂ σ ∂ v \frac {\partial L}{\partial v}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_j}{\partial v}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_j}{\partial \sigma}\frac {\partial \sigma}{\partial v} ∂v∂L=∑j=1N∂yj∂L∂v∂yj=∑j=1N∂yj∂L∂σ∂yj∂v∂σ
- 由公式3⃣️, ∂ σ ∂ v = 1 2 σ \frac {\partial \sigma}{\partial v}=\frac{1}{2\sigma} ∂v∂σ=2σ1
- 由公式4⃣️, ∂ y j ∂ σ = − x j − μ σ 2 \frac {\partial y_j}{\partial \sigma}=-\frac{x_j-\mu}{\sigma^2} ∂σ∂yj=−σ2xj−μ
综上可得:
- ∂ L ∂ v ∗ ∂ v ∂ x i = ∑ j = 1 N ∂ L ∂ y j − ( x j − μ ) σ 2 1 2 σ ∗ 2 ( x i − μ ) N \frac {\partial L}{\partial v}*\frac {\partial v}{\partial x_i}=\sum_{j=1}^N\frac{\partial L}{\partial y_j}\frac{-(x_j-\mu)}{\sigma^2}\frac{1}{2\sigma}*\frac{2(x_i-\mu)}{N} ∂v∂L∗∂xi∂v=∑j=1N∂yj∂Lσ2−(xj−μ)2σ1∗N2(xi−μ)
- 注意到 x j − μ σ = y j \frac{x_j-\mu}{\sigma}=y_j σxj−μ=yj,则上式化简为:
- ∂ L ∂ v ∂ v ∂ x i = x i − μ σ − 1 σ N ∑ j = 1 N ∂ L ∂ y j x j − μ σ = y i σ − 1 N ∑ j = 1 N ∂ L ∂ y j y j \frac {\partial L}{\partial v}\frac {\partial v}{\partial x_i}=\frac{x_i-\mu}{\sigma}\frac{-1}{\sigma N}\sum_{j=1}^N\frac{\partial L}{\partial y_j}\frac{x_j-\mu}{\sigma}=\frac{y_i}{\sigma}\frac{-1}{N}\sum_{j=1}^N\frac{\partial L}{\partial y_j}y_j ∂v∂L∂xi∂v=σxi−μσN−1∑j=1N∂yj∂Lσxj−μ=σyiN−1∑j=1N∂yj∂Lyj
第三项: ∂ L ∂ u ∗ ∂ u ∂ x i \frac {\partial L}{\partial u}*\frac {\partial u}{\partial x_i} ∂u∂L∗∂xi∂u
- ∂ u ∂ x i = 1 N \frac {\partial u}{\partial x_i}=\frac{1}{N} ∂xi∂u=N1
- ∂ L ∂ u \frac {\partial L}{\partial u} ∂u∂L:
- 因为 v v v 是 μ \mu μ的函数,因此:
∂ L ∂ u = ∑ j = 1 N ∂ L ∂ y j ∂ y i ∂ u + ∑ j = 1 N ∂ L ∂ y j ∂ y j ∂ v ∂ v ∂ u \frac {\partial L}{\partial u}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_i}{\partial u} + \sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_j}{\partial v}\frac {\partial v}{\partial u} ∂u∂L=∑j=1N∂yj∂L∂u∂yi+∑j=1N∂yj∂L∂v∂yj∂u∂v - 由于 ∂ v ∂ u = 1 N ∑ j = 1 N ( x j − μ ) ( − 2 ) = 0 \frac {\partial v}{\partial u}=\frac{1}{N}\sum_{j=1}^N(x_j-\mu)(-2)=0 ∂u∂v=N1∑j=1N(xj−μ)(−2)=0, 因此上式第二项为 0。
- 由公式4⃣️, ∂ y j ∂ u = − 1 σ \frac {\partial y_j}{\partial u}=\frac{-1}{\sigma} ∂u∂yj=σ−1
- 因此, ∂ L ∂ u = ∑ j = 1 N ∂ L ∂ y j ∂ y j ∂ u = ∑ j = 1 N ∂ L ∂ y j − 1 σ \frac {\partial L}{\partial u}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_j}{\partial u}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac{-1}{\sigma} ∂u∂L=∑j=1N∂yj∂L∂u∂yj=∑j=1N∂yj∂Lσ−1
- 因为 v v v 是 μ \mu μ的函数,因此:
综上可得: ∂ L ∂ u ∗ ∂ u ∂ x i = ∑ j = 1 N ∂ L ∂ y j ∂ y i ∂ u ∂ u ∂ x i = − 1 N σ ∑ j = 1 N ∂ L ∂ y j \frac {\partial L}{\partial u}*\frac {\partial u}{\partial x_i}=\sum_{j=1}^N\frac {\partial L}{\partial y_j}\frac {\partial y_i}{\partial u}\frac {\partial u}{\partial x_i}=\frac{-1}{N\sigma}\sum_{j=1}^N\frac {\partial L}{\partial y_j} ∂u∂L∗∂xi∂u=∑j=1N∂yj∂L∂u∂yi∂xi∂u=Nσ−1∑j=1N∂yj∂L
综合所有上述三项结果,最终:
∂ L ∂ x i = 1 σ ∂ L ∂ y i − y i N σ ∑ j = 1 N ∂ L ∂ y j y j − 1 σ 1 N ∑ j = 1 N ∂ L ∂ y j \frac{\partial L}{\partial x_i}=\frac{1}{\sigma}\frac{\partial L}{\partial y_i} -\frac{y_i}{N\sigma}\sum_{j=1}^N\frac{\partial L}{\partial y_j}y_j-\frac{1}{\sigma}\frac{1}{N}\sum_{j=1}^N\frac{\partial L}{\partial y_j} ∂xi∂L=σ1∂yi∂L−Nσyi∑j=1N∂yj∂Lyj−σ1N1∑j=1N∂yj∂L
稍作整理:
∂ L ∂ x i = 1 σ ( ∂ L ∂ y i − 1 N ∑ j = 1 N ∂ L ∂ y j − y i N ∑ j = 1 N ∂ L ∂ y j y j ) \frac{\partial L}{\partial x_i}=\frac{1}{\sigma}(\frac{\partial L}{\partial y_i}-\frac{1}{N}\sum_{j=1}^N\frac{\partial L}{\partial y_j} - \frac{y_i}{N}\sum_{j=1}^N\frac{\partial L}{\partial y_j}y_j) ∂xi∂L=σ1(∂yi∂L−N1∑j=1N∂yj∂L−Nyi∑j=1N∂yj∂Lyj)
向量化结果:
∂ L ∂ X = 1 σ ( ∂ L ∂ Y − E [ ∂ L ∂ Y ] − Y ∗ E [ ∂ L ∂ Y ∗ Y ] ) \frac{\partial L}{\partial X}=\frac{1}{\sigma}(\frac{\partial L}{\partial Y}-E[\frac{\partial L}{\partial Y}] - Y*E[\frac{\partial L}{\partial Y}*Y]) ∂X∂L=σ1(∂Y∂L−E[∂Y∂L]−Y∗E[∂Y∂L∗Y])
使用 Pytorch 编写代码如下:
def backward(dout, cache):
xhat, gamma, ivar = cache
dbeta = torch.sum(dout, dim=0)
dgamma = torch.sum(dout * xhat, dim=0)
dy = dout * gamma
dx = ivar * (dy - torch.mean(dy, dim=0) - xhat * torch.mean(dy * xhat, dim=0))
结语
最后让我们测试下两种计算方法的结果,并看看计算速度的对比:
from convolutional_networks import BatchNorm
reset_seed(0)
N, D = 128, 2048
x = 5 * torch.randn(N, D, dtype=torch.float64, device='cuda') + 12
gamma = torch.randn(D, dtype=torch.float64, device='cuda')
beta = torch.randn(D, dtype=torch.float64, device='cuda')
dout = torch.randn(N, D, dtype=torch.float64, device='cuda')
bn_param = {'mode': 'train'}
out, cache = BatchNorm.forward(x, gamma, beta, bn_param)
t1 = time.time()
dx1, dgamma1, dbeta1 = BatchNorm.backward(dout, cache)
t2 = time.time()
dx2, dgamma2, dbeta2 = BatchNorm.backward_alt(dout, cache)
t3 = time.time()
print('dx difference: ', eecs598.grad.rel_error(dx1, dx2))
print('dgamma difference: ', eecs598.grad.rel_error(dgamma1, dgamma2))
print('dbeta difference: ', eecs598.grad.rel_error(dbeta1, dbeta2))
print('speedup: %.2fx' % ((t2 - t1) / (t3 - t2)))
代码运行结果如下:
dx difference: 1.1126357877489443e-16
dgamma difference: 0.0
dbeta difference: 0.0
speedup: 1.58x
由此可见,我们通过公式计算得到的梯度与通过计算图反向传播得到的梯度没有差别,但前者的计算速度是后者的 1.58 倍。