cv学习笔记(2)神经网络分类问题之鸢尾花数据集
cv学习笔记(2)神经网络分类问题之鸢尾花数据集
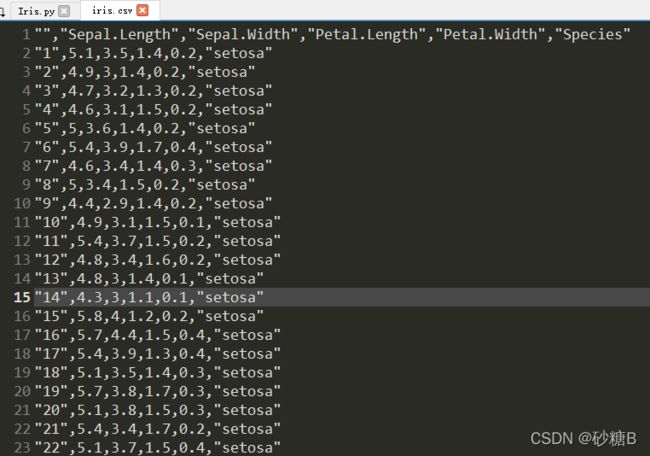
鸢尾花数据集
根据鸢尾花的花瓣、花萼的长度和宽度来判断这是什么鸢尾花。这是统计学的经典问题。
该数据集有150个数据,根据这个数据集,训练一个人工神经网络,然后就可以根据给定的花瓣和花萼来判断这是哪一种鸢尾花。
建立网络结构
使用一个串型结构。第一个层是从输入层到隐含层,设置7个节点,输入4个数据,指定激活函数是双曲正切函数(tanh);第二层是输出层,是3个类别,激活函数是softmax。最后进行编译这个模型,使用mean_squared_error作为损失函数,用sgd优化,用准确度衡量模型的好坏。
#define a network
def baseline_model():
model = Sequential()
model.add(Dense(7, input_dim=4, activation='tanh')) #从输入层到隐含层
model.add(Dense(3, activation='softmax')) #输出层
model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['accuracy']) #mean_square_error是均方差, sgd是随机梯度下降, 衡量模型的好坏,用准确度来衡量
return model
读取数据
使用pandas读取csv文件的数据,将输入保存为X,输出保存为Y,由于Y是字符串的形式,所以要将Y进行编码。
#load data
df = pd.read_csv('iris.csv')
X = df.values[:, 1:5].astype(float)
Y = df.values[:, 5]
encoder = LabelEncoder()
Y_encoded = encoder.fit_transform(Y) #把y从字符串变成数字
Y_onehot = np_utils.to_categorical(Y_encoded) #将向量转化为独热编码的形式
评估
根据模型进行训练,总共进行20次训练,一次输入1组数据,输出也为1组数据。使用交叉验证的方法进行评估。
estimator = KerasClassifier(build_fn=baseline_model, epochs=20, batch_size=1, verbose=1) #用交叉验证,根据模型进行训练,测验它的准确率, epochs表示训练多少次, batch_size表示批处理, verbose表示训练时输出的信息
#evalute
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
result = cross_val_score(estimator, X, Y_onehot, cv=kfold) #cv表示交叉验证的方法, X,Y表示输入数据
print("Accuray of cross validation, mean %.2f, std %.2f" % (result.mean(), result.std())) #均值和方差
完整代码
# -*- coding: utf-8 -*-
import numpy as np #矩阵运算
import pandas as pd #数据分析,文件读取
from keras.models import Sequential #串型模型
from keras.layers import Dense #每一层的每一个都跟前面一层和后面的节点都有一个连接,密度很高
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils
from sklearn.model_selection import cross_val_score #验证准确度的得分
from sklearn.model_selection import KFold#把给定的数据集分为k个小的数据集,k-1个训练,1个测试,重复k次
from sklearn.preprocessing import LabelEncoder #预处理,将字符串转为数字
from keras.models import model_from_json #将训练好的模型存为json格式的文件
#reproducibility
seed = 13 #使每次产生的随机种子都一样
np.random.seed(seed)
#load data
df = pd.read_csv('iris.csv')
X = df.values[:, 1:5].astype(float)
Y = df.values[:, 5]
encoder = LabelEncoder()
Y_encoded = encoder.fit_transform(Y) #把y从字符串变成数字
Y_onehot = np_utils.to_categorical(Y_encoded) #将向量转化为独热编码的形式
#define a network
def baseline_model():
model = Sequential()
model.add(Dense(7, input_dim=4, activation='tanh')) #从输入层到隐含层
model.add(Dense(3, activation='softmax')) #输出层
model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['accuracy']) #mean_square_error是均方差, sgd是随机梯度下降, 衡量模型的好坏,用准确度来衡量
return model
estimator = KerasClassifier(build_fn=baseline_model, epochs=20, batch_size=1, verbose=1) #用交叉验证,根据模型进行训练,测验它的准确率, epochs表示训练多少次, batch_size表示批处理, verbose表示训练时输出的信息
#evalute
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
result = cross_val_score(estimator, X, Y_onehot, cv=kfold) #cv表示交叉验证的方法, X,Y表示输入数据
print("Accuray of cross validation, mean %.2f, std %.2f" % (result.mean(), result.std())) #均值和方差
#save model
estimator.fit(X, Y_onehot) #训练模型
model_json = estimator.model.to_json() #模型转化为json
with open("model.json", "w") as json_file:
json_file.write(model_json)
estimator.model.save_weights("model.h5")
print("save model to dissl")
#load model and use for prediction
json_file = open("model.json", "r")
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights("model.h5")
print("loaded model from disk")
predicted = loaded_model.predict(X)
print("predicted probability:" + str(predicted))
predicted_label = loaded_model.predict_classes(X)
print("predicted label:" + str(predicted_label))
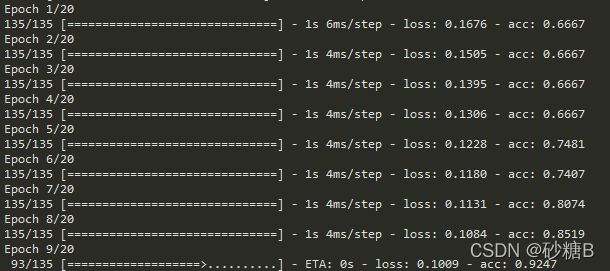
输出
训练时,可以看到损失值逐渐变小,精确度再变大。
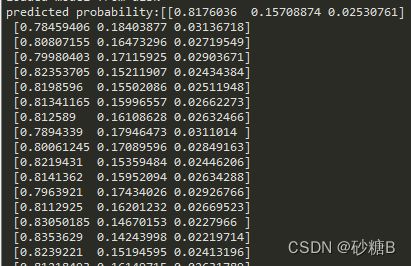
测试数据,三种鸢尾花的概率。

总结
参考链接: https://www.bilibili.com/video/BV1WJ411B7nL。