引航计划 人工智能 实训 个人笔记
学习思维导图
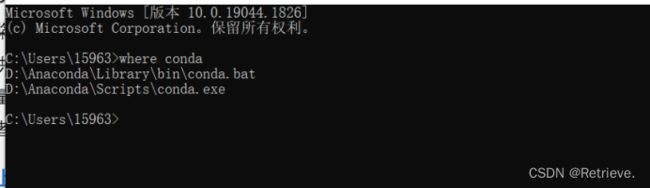
Anaconda安装及环境配置
官网下载anaconda
![]()

添加清华源加快torch下载速度
pip3 install torch torchvision torchaudio -i Simple Index
下载vscode并配置

下载python拓展

下载markdown拓展
设置python interpreter(解释器)路径为D:\Anaconda\envs\torch_1_12\python.exe
测试vscode

清华镜像下载anaconda linux Anaconda3-2022.05-Linux-x86_64.sh
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
激活环境
![]()
进入unet_torch所在的文件夹
![]()
![]()
-b batch size
-e epoch
-l learning rate
-s scale
-c catetory (类别数)
![]()
python predict.py - m D:\小车\1_segmentation\unet_torch\checkpoints\0720\checkpoint_epoch1.pth -i D:\小车\1_segmentation\unet_torch\test\train_43.jpg -v -n -s 1
-v 可视化
-n 保存

中科曙光环境配置(前边的anaconda安装以及pytorch安装详情请查看中科曙光环境配置.DOCX..\..\8.9\中科曙光环境配置.docx)
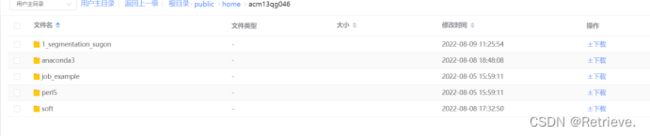
将1_segmentation_sugon 上传到用户主目录
更改submit文件
Activate 后改为自己的环境名称
home后改为自己的用户名
命令行输入
salloc -p kshdtest -N 1 --gres=dcu:4 --cpus-per-task=18
向曙光申请资源
输入 ssh + 自己申请到的用户名(服务器名)登录到该服务器
登录成功后激活自己的torch_1_12环境
通过cd进入submit所在的文件夹下
输入./submit.sh
8.8/ 模型训练和预测
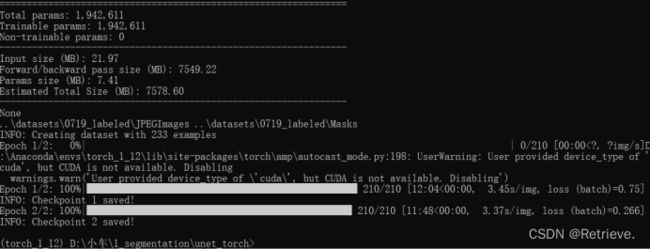
1.训练模型
Python train.py + 相应参数设置
-> 训练结果保存在checkpoints
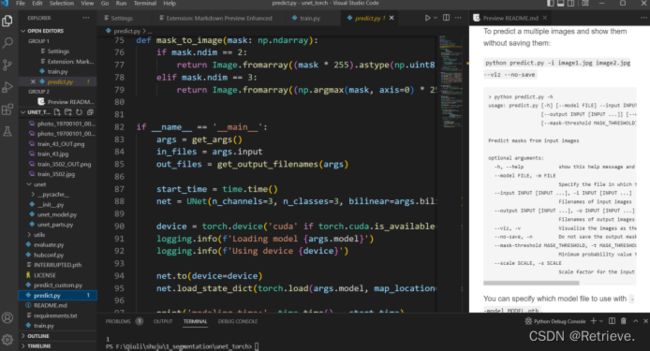
2.预测模型
Python predict.py + -m checkpoints 路径 +图片路径+设置相关参数
->出现一页预测的图片
模型 保存在VSCode页面文件夹下checkpoints 0720中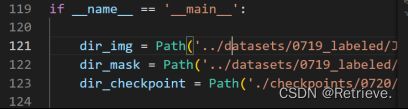
\转义字符 \\=/ ../回退一级文件夹 ./当前文件夹找文件 …/错误
预测数据
预测:python predict_custom.py -i .\test\photo_19700101_000737.jpg -n -v -m ./checkpoints/0720/checkpoint_epoch1.pth -s 0.5
补包: pip install matplotlib six
解决resize问题(版本不一样,接口不匹配):
pip uninstall torchvision 卸载
pip install torchvision==0.13.0 重新装
预测参数: -m:指定存储模型的文件
-i -v:可视化处理图像
–t:考虑掩码像素白色的最小概率值
–s:修改图像大小
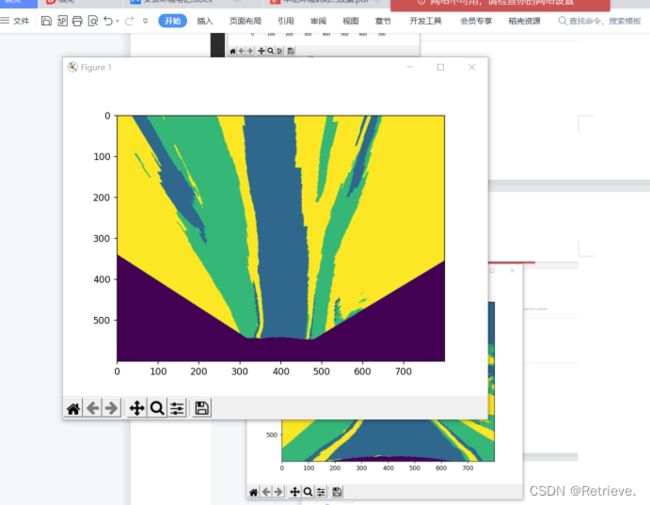
预测![]()
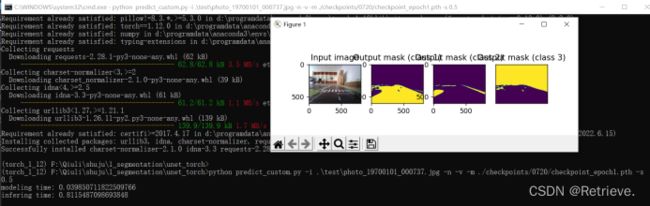
**训练自己的数据
注意:团队中标签颜色名称都应该一致;删掉时:标签+原图;生成灰度图Marks文件。
a)导入自己的数据0808_labeled
b)创建Masks空文件 ,保存掩码标签(灰度图像)
c)打开mask_开头文件。重新配环境Python解释器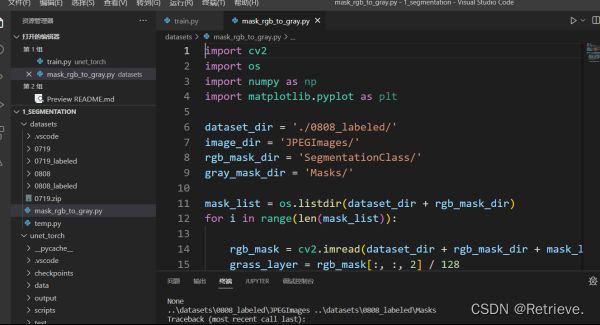
d)安装openCV:pip install opencv-python==3.4.2.17
e)Temp.py打开一张标签图片查看RGB值
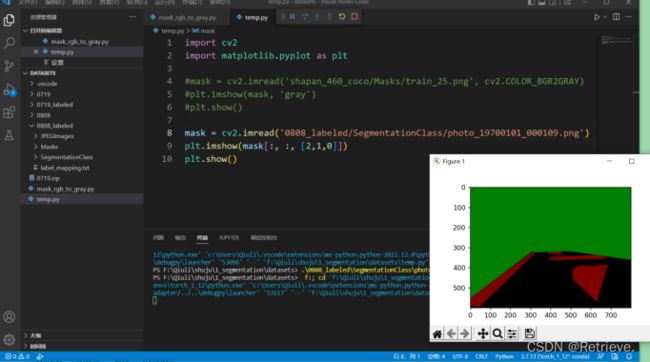
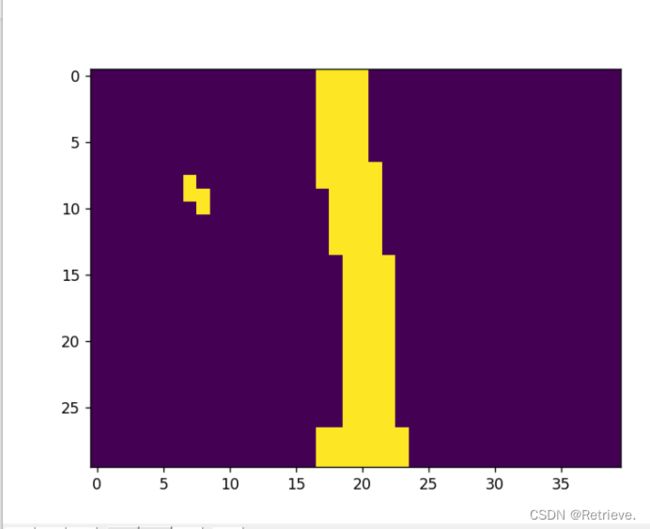
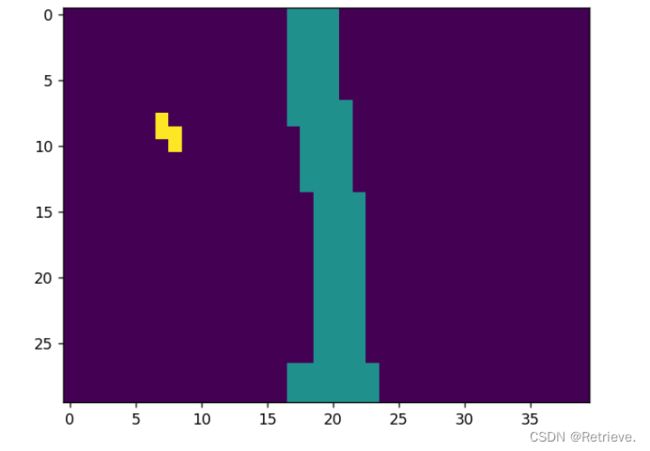
f)生成灰度图像保存在Masks文件中,图像为(0,0,0):道路;(1,1,1):草;(2,2,2):背景。
注意:Python读取RGB时是BGR方式读取(红0绿1蓝2)
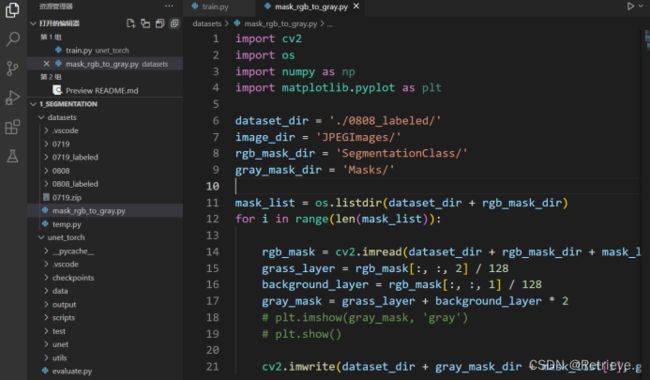
g)合并所有人Masks用于训练。
8.9/ 鸟瞰图的制作以及相机的成像原理
鸟瞰图 -> 1去畸变 -> 2视角转换
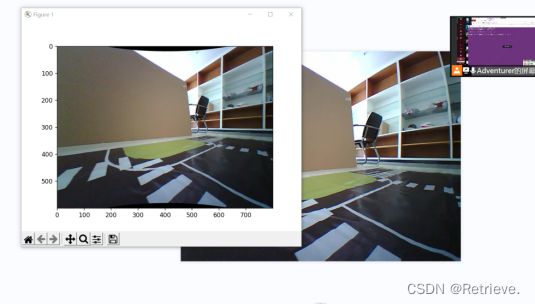
猫眼摄像有图像扭曲(直线扭曲等)、近大远小(远处的相同长度的斑马线显得更短)
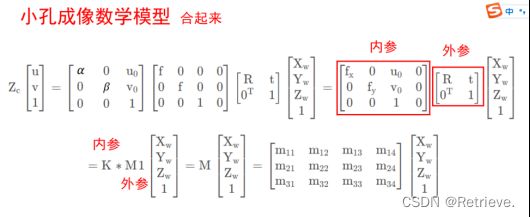
相机的成像原理
小孔成像

无人驾驶代码下载3_birdview 文件
使用VScode打开文件夹
运行第一个python文件

37张图片,14张标定图片,图片大小DIM=(800,600)
Rms误差 K 相机内参 D(distortion)畸变参数
取消第73、74行代码注释,注意缩进
再次运行第一个python文件 查看角点识别标记情况
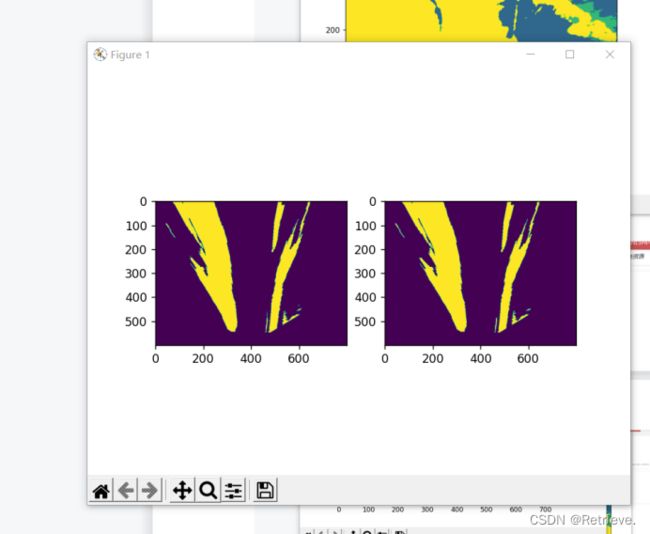
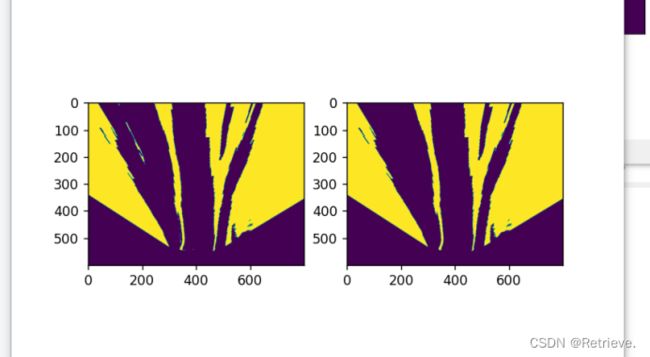
运行第二个python文件,与未校正前的图片比较,查看畸形矫正后的图片效果
常见几何变换 : 平移、旋转
刚体变换/欧几里得变换
相似变换
仿射变换
透视变换
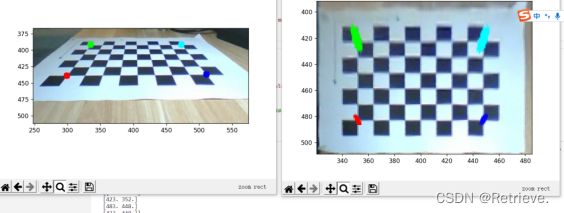
标记四组点,第二张图的四个点由人工标注
作透视变换
环境问题: cv2 下载opencv-python==3.4.2.17(4.有些功能收费,不可用)
8.9/ 中科曙光环境配置
Anaconda官网下载Lixux版本的包
在用户主目录新建soft和 anaconda3文件夹
在soft目录下新建Anaconda3文件夹,将在anaconda官网上下载的Linux文件上传
进入命令行
cd -> soft
cd ->Anaconda3
bash Anaconda3-2020.07-Linux-x86_64.sh –u
安装完毕执行source ~/.bashrc
Which conda
如果没有,配置环境 -> nano ~/.bashrc
export PATH=/public/home/username/soft/Anaconda3/bin:$PATH
测试:
Python3
Exit()
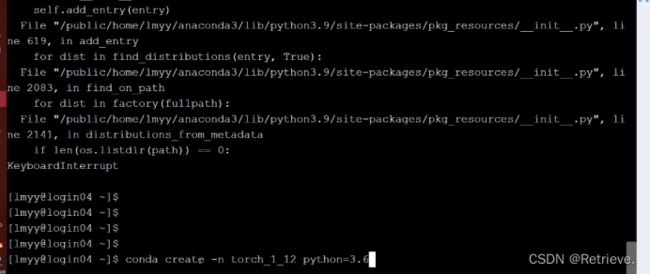
Pytorch安装 -> conda create - n torch_1_12 python=3.6
Conda activate torch_1_12
Pip install /public/software/apps/DeepLearning/whl/rocm-4.0.1/torch-1.9.0+rocm4.0.1-cp36-cp36m-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/

![]()
下载后上传到

然后cd ->soft cd->Anaconda3
pip install torchvision-0.10.0a0-cp36-cp36m-linux_x86_64.whl

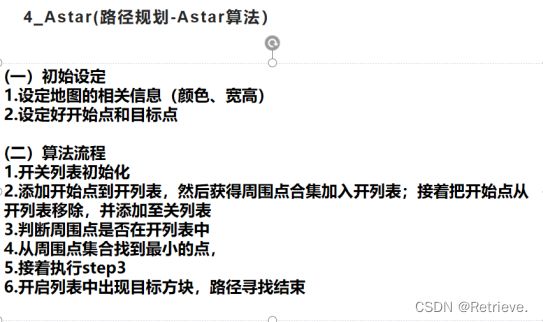
8.10/ A*算法
A*算法:
网址:https://www.redblobgames.com/pathfinding/a-star/introduction.html
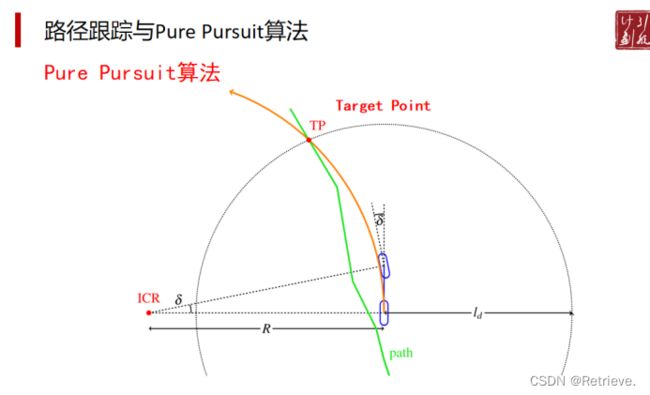
路径跟踪与Pure Pursuit算法
https://thomasfermi.github.io/Algorithms-for-Automated-Driving/Control/BicycleModel.html
Pure Pursuit — Algorithms for Automated Driving
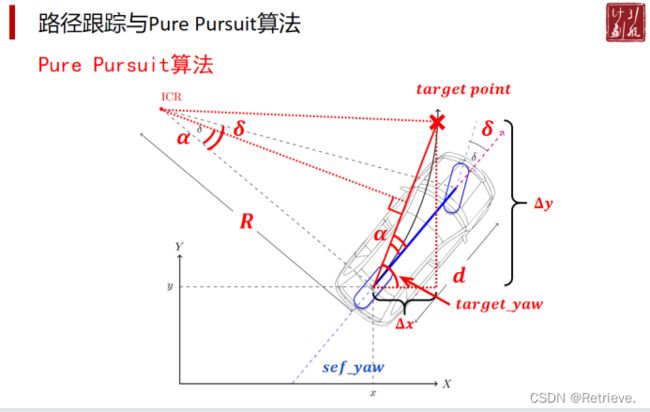
原理 阿克曼转向几何
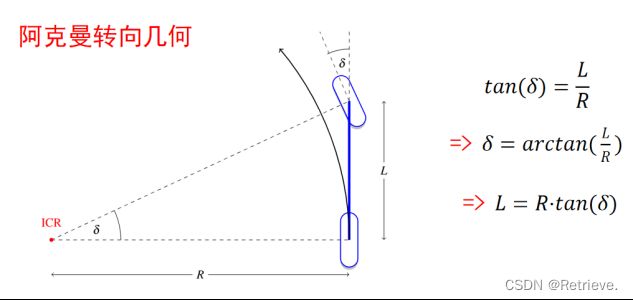
前左轮和前右轮协同转动
瞬时旋转中心重合 要使两个轮子的带动的轴不一样长,以保证切线在一点相交
求角α
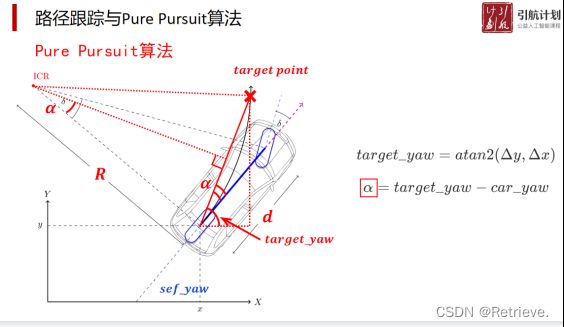
求R的长度
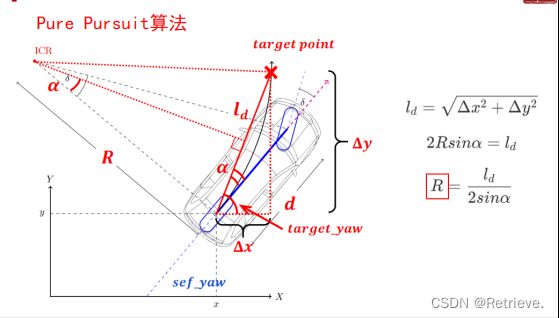
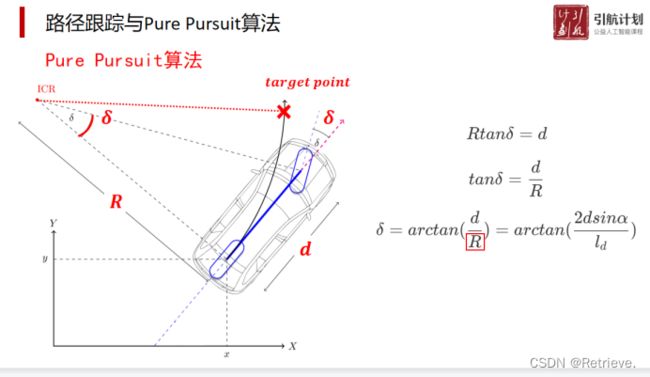
根据R求角δ
8.10/ 具体代码解析
路径规划 ->A*



3_mask_to_path.py代码 局部追踪
根据图像分割结果
- 分割结果转鸟瞰图
- 去畸变148-169 cv2.fisheye.intUndistorRectifyMap 、 cv2.remap
- 转鸟瞰174-183 读取透视变换矩阵np.loadtxt 、 cv2.warpPerspective 执行透视变换
- 可行驶区域可视化 190-263
cv2.getStructuringElement将图片返回成指定形状(椭圆)和尺寸结构
morphology.remove_small_objects去除grass和background的面积小于60/4000的连通区域
cv2.erode和cv2.dilate函数对图片进行腐蚀和膨胀
- 补全车前盲区
相机视野焦点所在位置为车头中点,小车行驶原点为后车轮中点位置,因此需要加上车身长度进行补全
- 选取终点 281-312
cv2.circle选定车辆局部区域候选半径(如80cm)
可行驶区域与候选半径范围进行交集,利用random函数随机生成最后目标点
- 路径规划 318-351
利用astar算法进行小车与目标点之间的路径规划
- 路径平滑
全局路径规划算法计算完路径后,其结果是一串用来表示经过的路径点的坐标,但该路径通常有“锯齿“形状,不符合实际需求,因此进行平滑处理。
6_multi_steps-4-photo 综合
(一)将图像分割训练及预测的代码封装为库seg进行调用
(二)运行主程序
1.主程序中构建Unet网络
2.用unet_predict函数预测最终的路径图
3.剩余步骤同3_mask-to-path
6_multi_steps-5-photo 综合
(一)将图像分割的训练及预测模型封装至seg库进行调用
(二)将拍照追踪(4_photo_to_path)的代码封装至path-plan.utils中进行调用
(三)运行主程序(同4)
1.道路分割
2.相机标定
3.路径规划 find_path
4.路径平滑 smooth
6_multi_steps-6-pursuit
(一)将图像分割的训练及预测模型封装至seg库进行调用
(二)将拍照追踪(4.photo_to_path)的代码封装至path-plan.utils中进行调用
(三)将路径追踪的pursuit算法代码封装至pure-pursuit.utils库中进行调用
(四)运行主程序
1.同5_photo-to-path-final
2.用pure-pursuit进行路径跟踪
8.11/ 7和9寻迹行驶
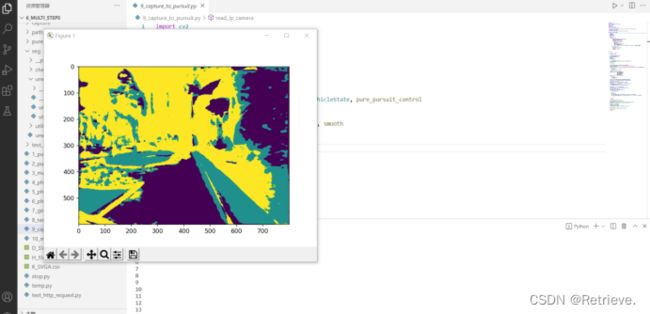
运行9_capture_to_pursuit.py
如果报图片大小错误
进入D:\小车\6_multi_steps\6_multi_steps\seg\unet\unet_model.py修改n=8为n=4
Python控制摄像头和小车
更改IP_Camera.info 中的wifi为自己的小车wifi和密码
将电脑或手机连接小车wifi(好像同一时间只能连一个)

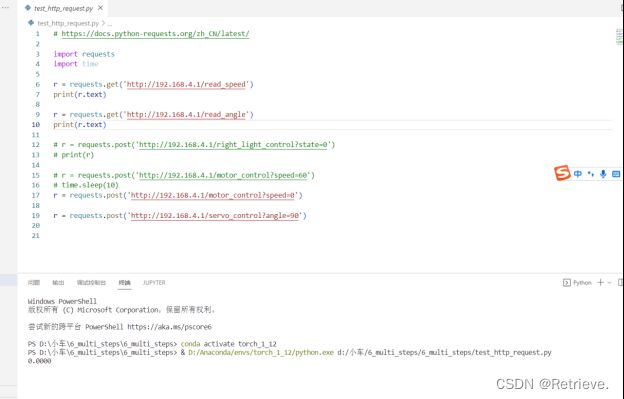
8_test_ip_camera_thread.py
控制摄像头
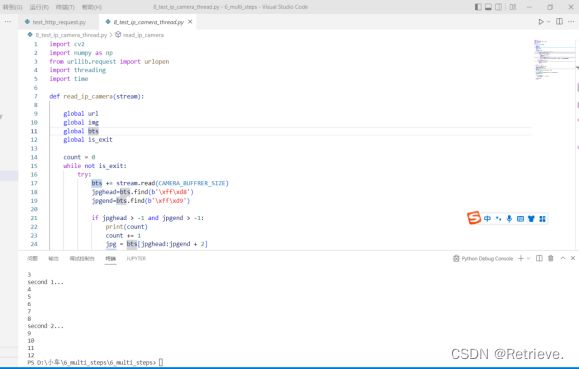
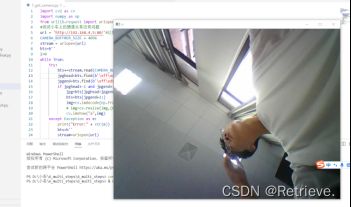
test_http_request.py
文件
r = requests.get('http://192.168.4.1/read_speed')
print(r.text)
读取当前小车速度并输出0.000
r = requests.get('http://192.168.4.1/read_angle')
print(r.text)
读取当前小车角度并输出 -0.24
r = requests.post('http://192.168.4.1/motor_control?speed=128')
控制小车速度
r = requests.post('http://192.168.4.1/servo_control?angle=0')
控制小车角度
传感器安装
测速传感器
蓝色:OUT -接码盘右
紫色:VCC -接码盘右VCC
白色:GND -接码盘右 GND
测角度传感器
紫色 VCC -3.3V
橙色 GND -GND
黄色 SCL clock -SCL
绿色 SDA 加速度 -SDA
蓝色 INT 触发 接G05


小车速度设置为60时
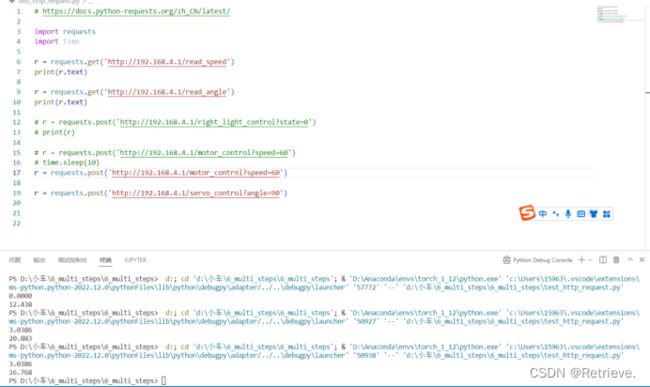
角度为180度时
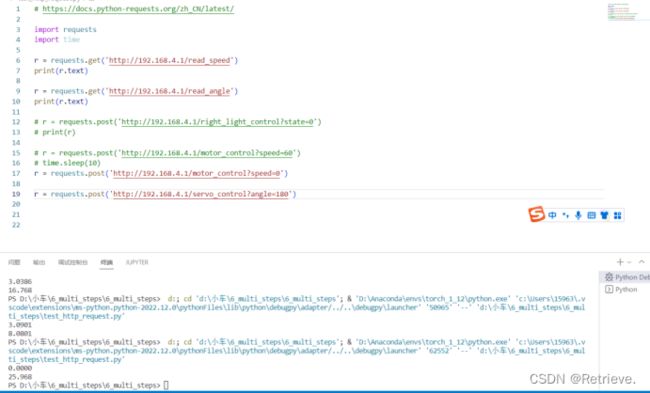
速度为255时
![]()
8.12总结

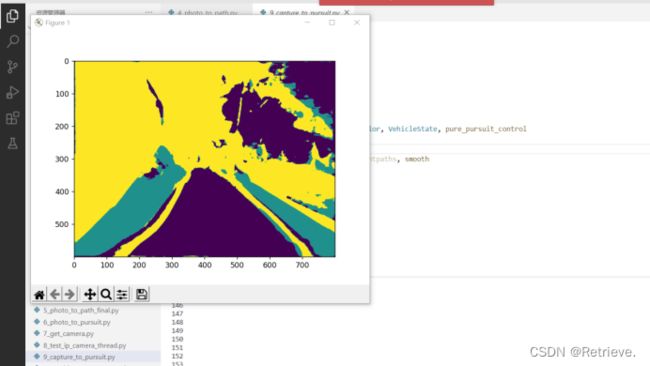
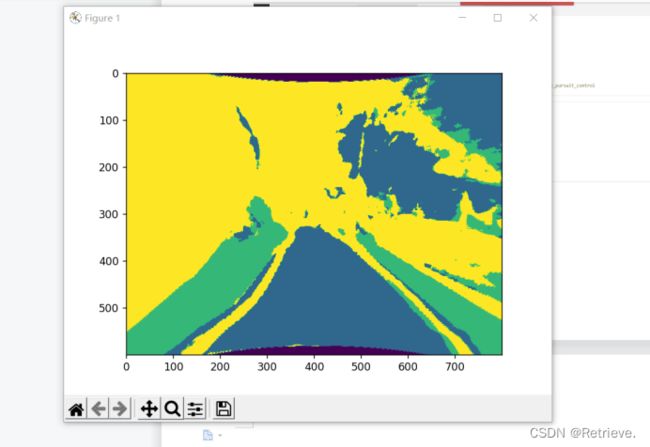
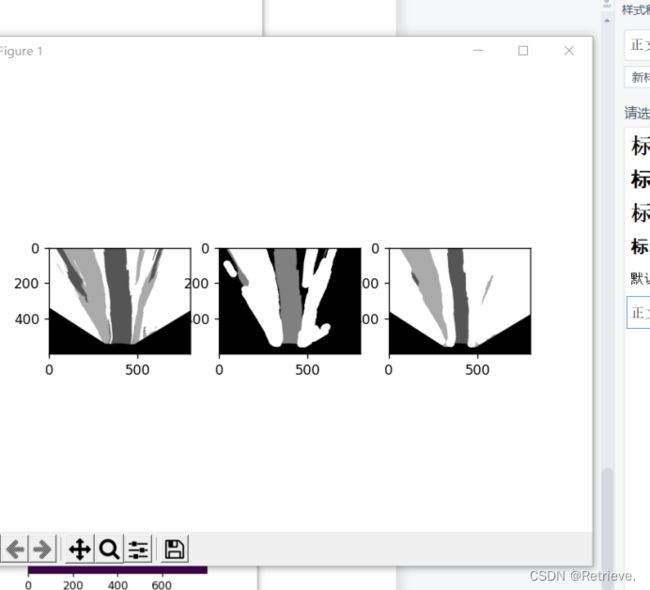
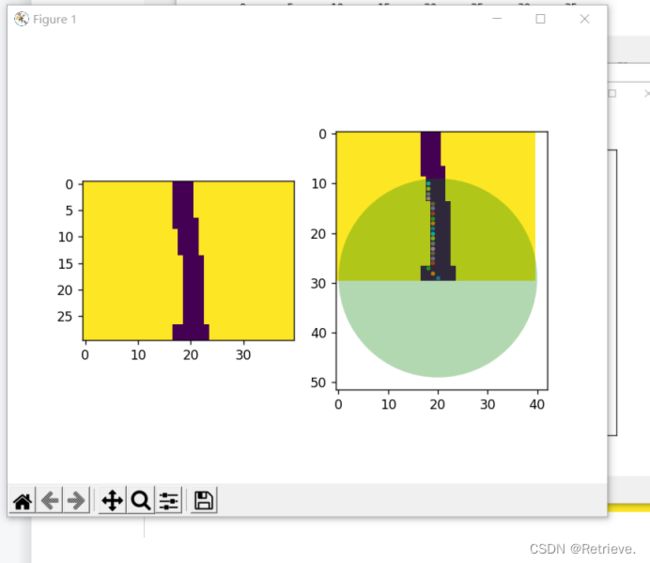
训练自己的数据集时,在使用导出的数据集的时候,需要转灰度图片,这时候mask_rgb_to_gray并不能直接使用,除了需要更改路径为自己数据集的路径外,还需要确保输出的***mask路面是0,绿化带是1,背景是2
注意不要随意把分享的导出的数据集放在一起,如果标注不同很容易出现3 out of bound 报错,建议把大的数据集放在一起在easydata上进行多人标注
进行完这一步之后
就可以使用6_和7_final中的python文件测试小车行驶情况了
其中 6_文件中的3_birdview展示的是如何转化为鸟瞰图(去畸变+转视角)
4/5/6为利用A*算法和pursuit算法计算路径,5/6为4的简单封装
6可以简单测试对小车的控制和小车寻迹行驶情况
7、8是对小车摄像头可用性的检测
9.10就是整合以上步骤,通过控制小车摄像头拍照、语义分割、转换鸟瞰图、利用算法寻迹、
控制小车寻迹行驶
经过整合一百多张图片的数据集后,小车能够简单的行驶一条直线道路后左转,但是由于数据太少,以及传感器并不太灵敏,实际拟合情况并不是很好
注:本地训练自己的数据集或曙光训练自己的数据集步骤请具体参照anaconda安装及环境配置.DOCX..\8.8\安装anaconda配置环境
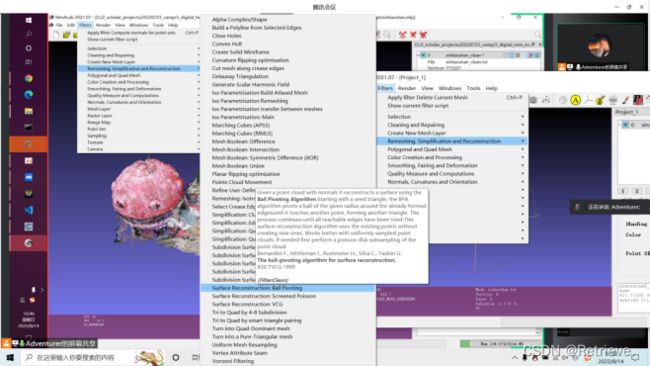
//8.13/14 智慧城市与三维重建部分
下载MVS
用VScode打开
配置好python解释器后运行
发现缺少cv2
进入cmd anaconda torch_1_12环境
pip install opencv-contrib-python==3.4.2.17
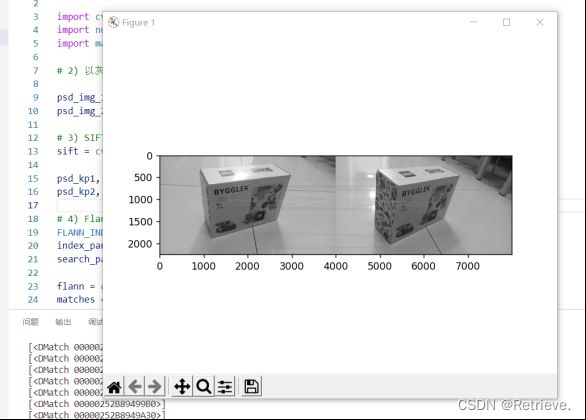
查看关键点匹配情况
下载COLMAP-3.7-windows-no-cuda
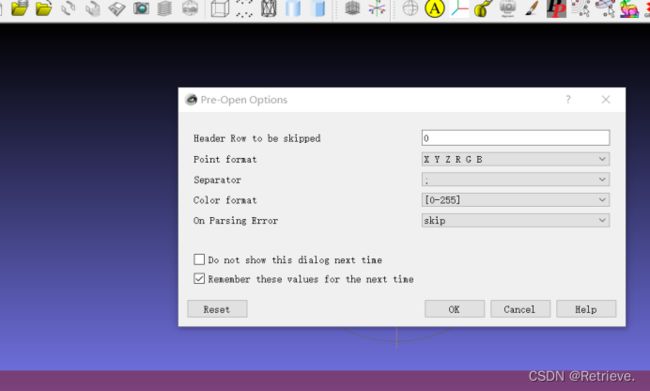
和xinhaoshan
点击COLMAP.bat
如果页面太大显示不下可以调整电脑分辨率
在选择工作区目录的时候一定要记得使用全英文目录
选择好后点击Run运行
然后等待
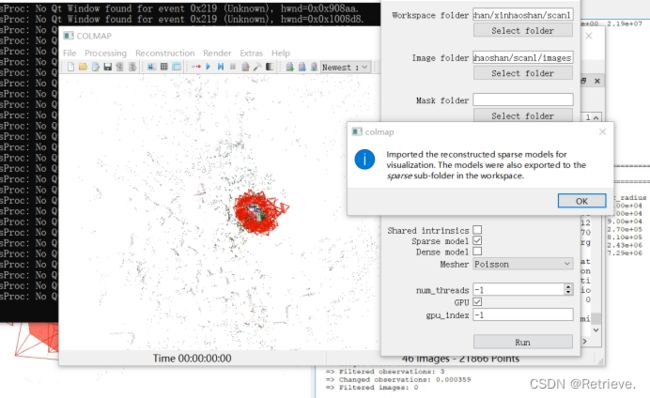
可以放大后双击红色的凌锥(摄像头)
查看具体信息
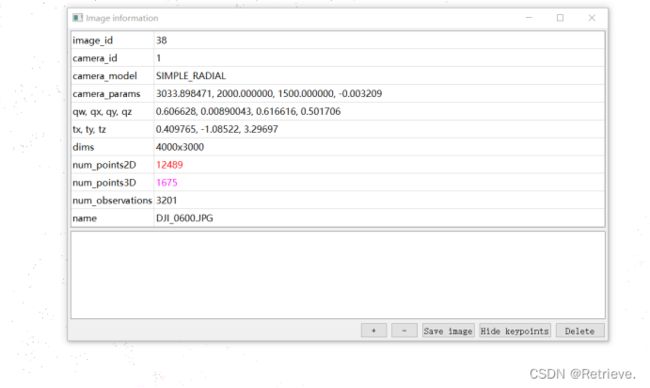
训练完后保存
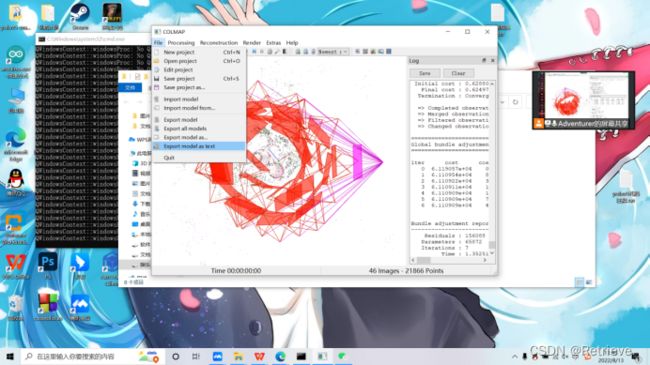
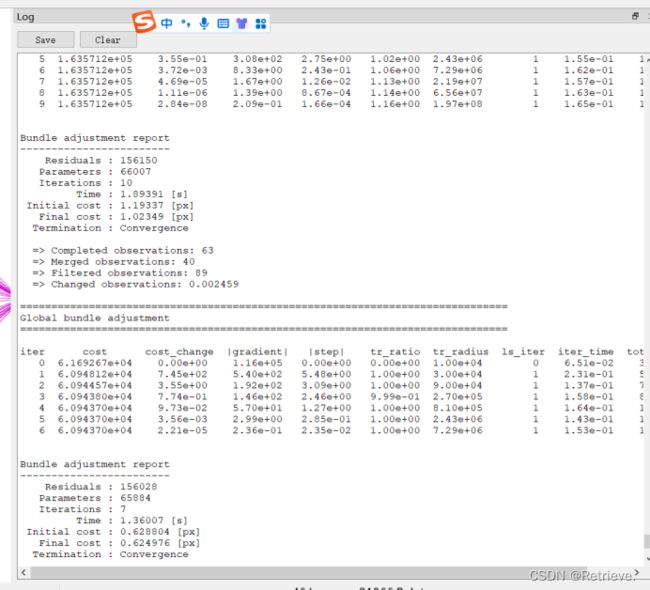
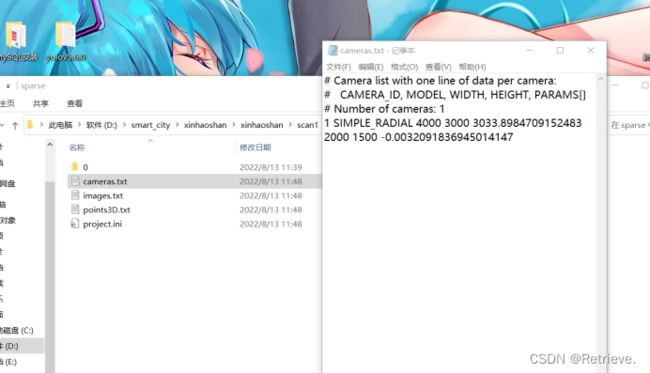
可以直接点击cameras.txt查看对于相机的预测情况
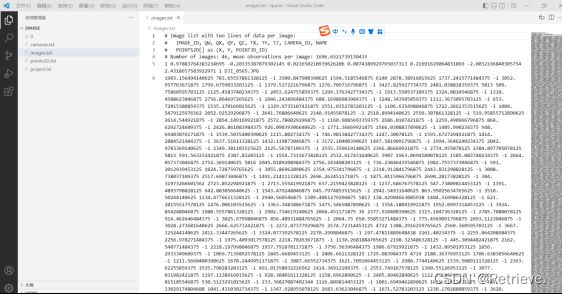
下午内容:
1.排序
下载AA-RMVSNet-sdu
进入中科曙光
在命令行申请资源后新开一个命令行
激活torch_1_12环境
安装包
pip install plyfile
pip install opencv-python==3.4.2.17 numpy (按需加清华源)
打开E-FILE
新建文件夹experiments和dataset
将AA-RMVSNet-sdu文件夹上传到experiments
将上午训练好的xinhaoshan上传到datasets
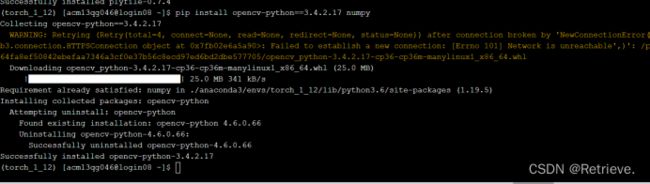
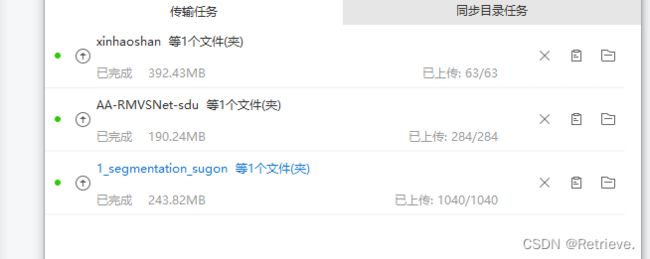
上传成功后
在命令行激活自己的环境torch_1_12
然后进入xinhaoshan/scan1新建文件夹original_images
将images的内容移动进original_images
python ./experiments/AA-RMVSNet-sdu/sfm/colmap2mvsnet.py --dense_folder /public/home/acm13qg046/datasets/xinhaoshan/scan1/ --interval_scale 0.4 --max_d 512



2.推断
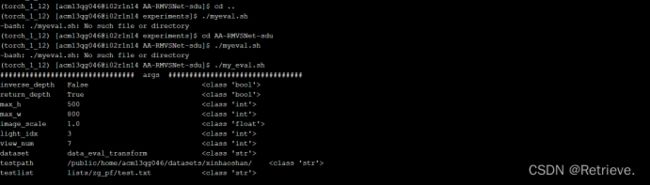
依次跑my_eval和my_fusion文件(AA-RMVSNet-sdu)
**记得更改路径为自己的用户名和环境名

可以阅读log文件,与自己终端的结果相比对
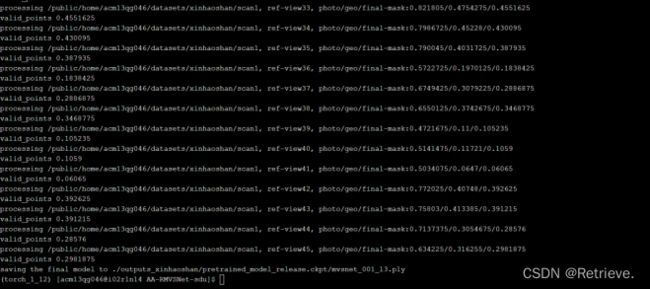
- 预测
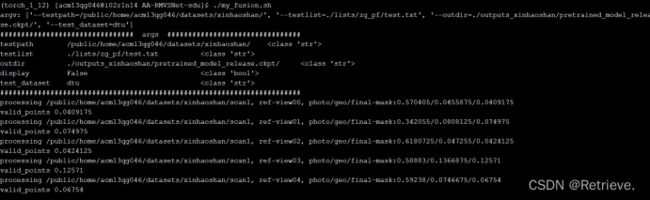
查看中科曙光昨天运行的相关文件结果是否正确
在本地用vsvode打开AA-NMVSNet-sdu
运行view_pfm.py
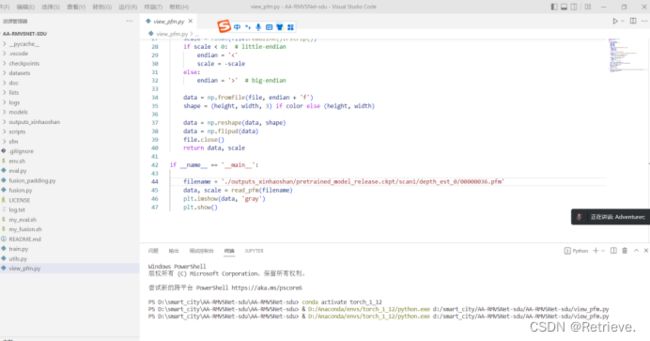
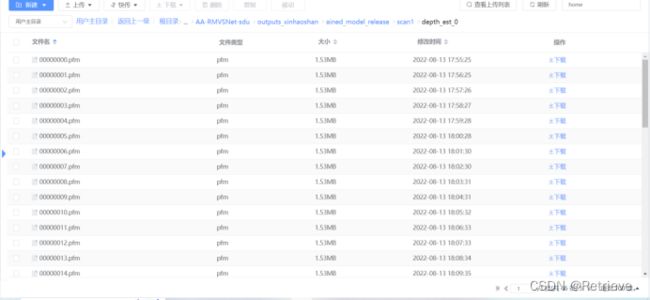
去曙光文件中寻找对应图片与本地的py文件产生的深度图片对比

排列中参数

每个像素的加权平均输出结果
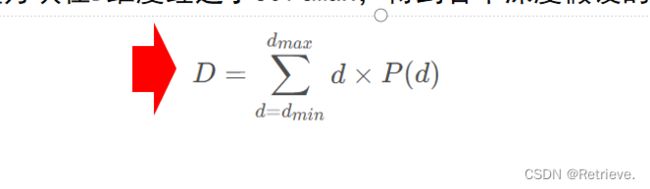
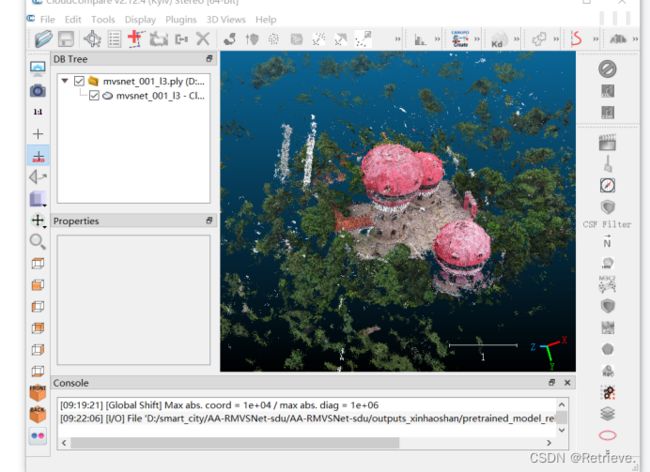
点云软件下载
下载CloudCompareStereo_v2.12.4_setup_x64.exe和MeshLab2021.07-windows.exe
安装
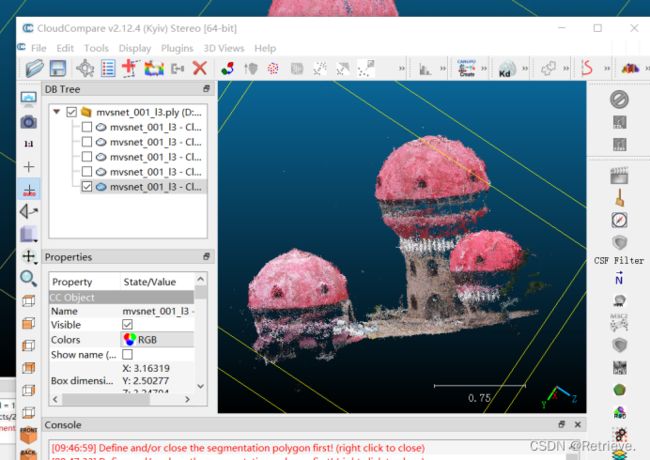
打开cloudcompare软件 ,将本地的AA-RMVSNet-sdu/outputs_xinhaoshan/pretrained_model_release.ckpt/mvsnet_001_12.ply拖到其中,直接Apply

通过鼠标右键(移动),左键(方向旋转)找到xinhaoshan
选定
选定后进行segment
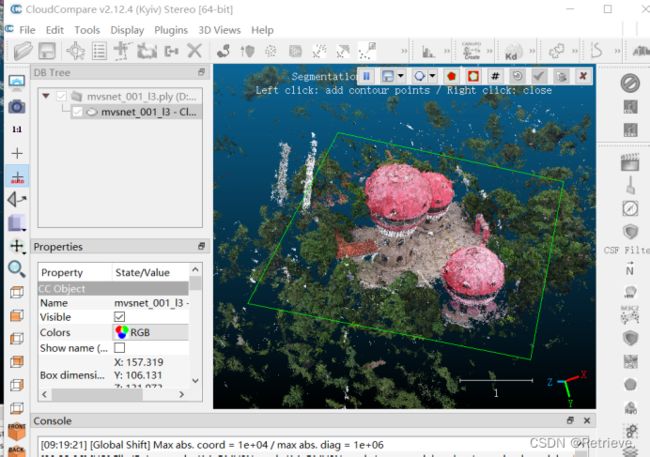
左边保留框内的,右边保留框外的
||用来决定拖动地图还是选取