目标检测 | AP-Loss:提高单阶段目标检测性能的分类损失,超越Focal loss
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

论文地址:https://arxiv.org/pdf/1904.06373v3.pdf
代码地址:https://github.com/cccorn/AP-loss
动机
单阶段目标检测器是通过同时优化分类损失和定位损失来训练的。由于anchor的数量很多,存在前景目标和背景目标不平衡的问题。
为了解决单阶段目标检测的这种问题,很多不同的方法引入了新的分类损失,如 balanced loss、Focal loss 和 tailored training 方法(Online Hard Example Mining (OHEM))等。这些 losses 对每个 anchor box 都分别独立建模,在分类损失中,其尝试对前景样本和背景样本重新赋权值,来适应样本不平衡的情况,这些方法没有考虑不同 samples 之间的联系。设计的平衡权重是手工选取的超参数,并不能很好的适应于不同类型的数据集。
本文认为,分类任务和检测任务之间的鸿沟阻碍了单阶段目标检测器的性能提升,本文并未从分类损失函数的修正上着手,而是直接使用排序方法(ranking)来代替分类损失。其中,关联的 ranking loss 显式地对关系建模,并且对正样本和负样本的比例不敏感。
同时,提出了一种新的框架来缓和上述不平衡问题,即使用排序方法来代替分类任务,并且使用 Average-Precision loss(AP-loss)来完成排序问题。

因为 AP-loss 是不可微且非凸的,AP-loss 不能直接被优化,故本文使用一种新的优化方法,可以将感知学习过程的误差驱动的更新机制和深度网络中的反向传播机制进行巧妙的结合。
概况简介
1、用于目标检测的 AP loss:
AP 被当做评价指标,但由于其不可微和非凸性,难以用作优化函数,本文的方法有四个特点:
1)本文方法可以被用于任何可微线性或可微非线性模型,如神经网络,其他的那些方法仅仅可以在线性 SVM 模型中起作用。
2)本文方法直接优化 AP- loss,会导致 loss 出现 gap
3)本文方法不是近似的梯度,且不受目标函数非凸性的影响
4)本文方法可以端到端的训练检测器
2、感知学习方法:
本文优化准则的核心是“误差驱动更新”,是感知学习方法的泛化版本,有助于克服不可微目标函数的困难。当训练数据是线性可分的时,该方法能够保证在有限次数内收敛。
具体方法
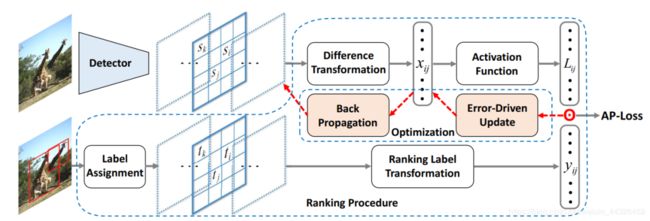
Average Precision Loss(AP Loss)对每个预测框进行排序,用排序后的序号来设计loss,核心思想在于鼓励正样本预测框的得分在负样本得分序列中尽可能靠前。启发自AUC Loss,后者用AUC的排序序号来设计loss,直接对AUC进行优化,而目标检测通常以mAP为指标,因此作者指出直接对AP进行优化能有更好的效果。
Bounding Box的设置方式跟传统的设置方式有些不同。比如有K个分类,
传统上是为每个Bounding Box预测一个分类(,0表示背景)以及得分向量
论文则是把Bounding Box复制K次,分别用于某一个分类(-1表示忽略,不纳入AP Loss的计算)的预测,以及得分

(左:一个label,属于分类k; 右:K个label,第k个为1)
AP Loss的具体设计(与GTBox的IoU超过阈值为正样本,否则为负样本):
1、计算所有预测框两两之间的得分差值
![]()
2、计算每个预测框的归一化排序(在所有预测框中的排序)
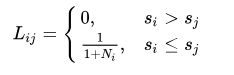
其中,是得分大于等于的所有预测框数量(包括正负样本);
显然,就是第个预测框在所有预测框中的排序序号,而就是第个预测框的得分在所有负样本框中的一个排位(归一化的序号,序号越小则得分越高);
也可以展开成关于的数学描述,

其中,为阶跃函数,
3、计算AP Loss

其中,是正样本预测框的数量;也可以写成,

最终,待优化的目标函数为:

其中,θ 是权值,激活函数 L(⋅) 是不可微的,故需要一种新的参数更新方法,而非传统的梯度下降法。
4、显然是不可导,所以需要定义近似的更新规则
![]()
其中,是真实值。
当时,,因为目标是让正样本预测框的得分比所有负样本预测框都高;
当时,,因为它不对AP Loss产生贡献;
因此,可以简化成
![]()
此时我们有期望更新:△x,之后,需要寻找模型权重 △θ 的更新方式。使用点乘来测量连续移动的大小,且用基于 L2−norm 的惩罚方法来调整权重变化(△θ)。
![]()
得分 si 的梯度gi可以通过反向传播差值来获得:

训练方法细节
1、minibatch training
minibatch 训练有助于优化方法规避 “score-shift” 情况。

AP-loss 可以从一个 batch 中获得,也可以从具有多个 anchor 的单个图像中获得。
假设一个极端情况:我们的检测器可以同时预测 I1和I2的完美ranking,但是 I1的最低得分都比 I2的最高得分高,这就是两个图像的 “score-shift”,所以当单独计算每个图像的 AP-loss 时,会出现检测效果较差的情况。
计算一个 mini-batch 的所有图像的得分可以避免上述情况,所以 mini-batch 训练是保证好的收敛性和准确性的重要前提。
2、分段阶跃函数:
训练初期,得分 si 之间非常接近(即几乎所有的 H(x)输入都接近于0),所以,输入的一个微小的改变将会带来一个大的输出改变,会改变更新过程。
为了避免该问题,我们使用下面的分段阶跃函数来代替 H(x) 函数:

不同 δ 情况下的分段阶跃函数如图所示。

1)当 δ 为 +0 时,该分段函数是最初的阶跃函数,注意,f(⋅) 仅仅在输入接近于0的时候与 H(⋅)不同。
2)另外一个单调且对称的平滑函数同样有效,且仅仅在输入接近于0的时候与 H(⋅)不同。
3)δ 的选择和 CNN 优化过程中的权值衰减有有着很大的联系。
4)δ决定了正样本和负样本的决策边界的宽度,小的 δ 得到较窄的决策边界,会导致权值相应减小。
3、差分AP:常用的评估
实验
相比于Focal Loss有比较明显的提升,而且不需要调整任何超参:

在RetinaNet上使用不同分类损失的实验结果


参考:
[1]https://blog.csdn.net/jiaoyangwm/article/details/91479594
[2]https://www.yuque.com/yahei/hey-yahei/objects_detection#zoJwH
扫描上方微信号,进入学习群。
目标检测、图像分割、自动驾驶、机器人、面试经验。
福利满满,名额已不多…