论文学习-Segmenter: Transformer for Semantic Segmentation
目录
- 一、Segmenter: Transformer for Semantic Segmentation
-
- Abstract
- 1. Introduction
- 2. Related work
- 3. Our approach: Segmenter
-
- 3.1. Encoder
- 3.2. Decoder
- 4. Experimental results
-
- 4.1. Datasets and metrics
- 4.2. Implementation details
一、Segmenter: Transformer for Semantic Segmentation
Abstract
图像分割在单个图像块的水平上往往是模糊的,需要上下文信息来达到标签的共识。本文介绍了一种用于语义分割的transformer模型。与基于卷积的方法相比,我们的方法允许已经在第一层和整个网络中对全局上下文进行建模。我们建立了最近的视觉转换器(ViT),并将其扩展到语义分割。为此,我们依赖于与图像块对应的输出嵌入,并通过点向线性解码器或mask transfomer解码器从这些嵌入中获得类标签。我们利用预先训练过的模型来进行图像分类,并表明我们可以在可用于语义分割的中等大小的数据集上对它们进行微调。线性解码器已经允许获得良好的结果,但性能可以通过mask transfomer生成类掩模进一步提高。我们进行了广泛的消融研究,以显示不同参数的影响,特别是对于大模型和小贴片尺寸的性能更好。Segmenter在语义分割方面取得了良好的效果。它在ADE20K和Pascal上下文数据集上都优于先进技术,在城市景观上具有竞争力。
1. Introduction
语义分割是一个具有挑战性的计算机视觉问题,具有广泛的应用范围,包括自动驾驶、机器人技术、增强现实、图像编辑、医学成像等。语义分割的目标是将每个图像像素分配给与底层对象相对应的类别标签,并为目标任务提供高级图像表示,例如检测人和衣服的边界。近年来,图像分割仍然是一个具有挑战性的问题,因为丰富的类内变化,上下文变化和模糊性源自遮挡和低图像分辨率。
最近的语义分割方法通常依赖于卷积编码器-解码器架构,其中编码器生成低分辨率的图像特征,将解码器的上采样特征生成到具有过像素类分数的分割地图。最先进的方法部署了全卷积网络(FCN),并在具有挑战性的分割基准测试上取得了令人印象深刻的结果。这些方法依赖于可学习的堆叠卷积,可以捕获语义丰富的信息,并在计算机视觉中非常成功。,然而,卷积的局部性限制了对图像中全局信息的访问。同时,这些信息对于分割尤为重要,因为局部块的标记往往依赖于全局图像的上下文。为了解决这个问题,DeepLab方法引入了具有扩展卷积和空间金字塔池的特征聚合。这允许扩大卷积网络的接受域,并获得多尺度的特征。
根据NLP的进展,一些分割方法探索了基于通道或空间注意力机制和点级注意力机制的替代聚合方案,以更好地捕获上下文信息。然而,这种方法仍然依赖于卷积主干,因此偏向于局部交互。广泛使用特殊的层来纠正这种偏差表明了卷积架构的局限性。
为了克服这些限制,我们将语义分割问题表述为一个序列到序列的问题,并使用transformer架构利用模型的每个阶段的上下文信息。通过设计,transformer可以捕获场景元素之间的全局交互,见图1。然而,全局交互的模型是以二次代价进行的,这使得这种方法在应用于原始图像像素时非常昂贵。根据最近对Vision Transformer (ViT) 的研究工作,我们将图像分割成块,并将线性块嵌入作为transformer编码器的输入标签。由编码器产生的上下文化的标记序列,然后被一个transformer解码器上采样到每像素的类的概率。对于解码,我们考虑块嵌入到类的概率的简单点线性映射或基于transformer的解码方案,其中可学习的类嵌入与块标签联合处理以生成类掩码。我们通过消融模型正则化、模型大小、输入补丁大小及其在精度和性能之间的权衡,对用于分割的变压器进行了广泛的研究。
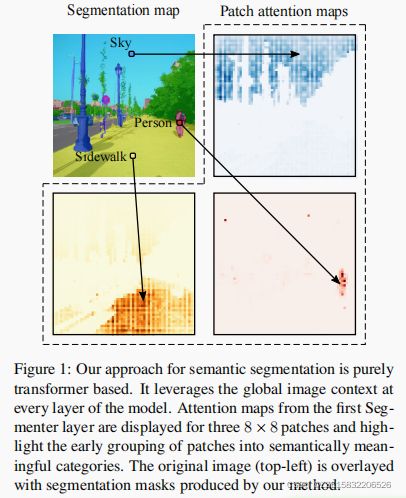
总之,我们的工作提供了以下四项贡献:
- 我们提出了一种基于Vision Transformer (ViT)的新的语义分割方法,该方法不使用卷积,通过设计捕获上下文信息,并且优于基于FCN的方法。
- 我们提出了一系列具有不同分辨率水平的模型,它允许在精度和运行时之间进行权衡,从最先进的性能到具有快速推理和良好性能的模型。
- 我们提出了一个基于transformer 的解码器生成类掩模,它优于我们的线性基线,并可以扩展到执行更一般的图像分割任务。
- 我们证明了我们的方法在ADE20K和Pascal数据集上都产生了最先进的结果,并且在城市景观上具有竞争力。
2. Related work
语义分割 基于全卷积网络(FCN)的结合编码-解码器结构的方法已经成为语义分割的主要方法。最初的方法依赖于一堆连续的卷积,然后是空间池化来执行密集的预测。其他[21, 36, 39, 40]方法对高级特征图进行上采样,并在解码过程中将其与低级特征图相结合,以捕获全局信息和恢复清晰的目标边界。为了扩大第一层卷积的接受域,[1, 4, 34, 41, 43]提出了几种扩张卷积或空洞卷积的方法。为了在更高的层次中捕获全局信息,[9,10,65]最近的工作使用了空间金字塔池来捕获多尺度的上下文信息。结合这些增强和无性空间金字塔池,Deeplabv3+[10]提出了一个简单和有效的编解码器FCN架构。最近的工作[22,23,57,58,61,66]通过编码器特征映射上的注意机制取代池化层,以更好地捕获更大的感受野。
虽然最近的分割方法主要集中在改进FCN上,但卷积对局部操作的限制可能意味着对全局图像上下文的处理效率低下和次优分割结果。因此,我们提出了一个纯的transformer 架构,它在编码和解码阶段捕获模型的每个层的全局上下文。
Transformers for vision Transformer现在是许多自然语言处理(NLP)任务中的最新技术。这种模型依赖于自我注意机制,并捕捉到句子中标记(单词)之间的长期依赖关系。此外, Transformer非常适合并行化,便于在大型数据集上的训练。 Transformer在NLP中的成功启发了计算机视觉中的几种方法,它们将神经网络与自注意形式相结合来处理目标检测[7]、语义分割[53]、全景分割分割[51]、视频处理[54]和少样本分类[18]。
最近,Vision Transformer(ViT)引入了一种用于图像分类的无卷积transformer架构,将输入的图像作为块标记序列进行处理。ViT需要在非常大的数据集上进行训练,而DeiT提出了一种基于标记的蒸馏策略,并使用CNN作为老师,获得了一个在ImageNet-1k数据集上进行训练的竞争性Vision Transformer。同时进行的工作将这项工作扩展到视频分类和语义分割。更详细地说,SETR使用了一个ViT主干网和一个标准的CNN解码器。Swin Transformer使用ViT的一种变体,由局部窗口组成,在层之间移动和上行网作为金字塔FCN解码器。
在这里,我们提出了一种Segmenter,一种用于语义图像分割的transformer编码解码器架构。我们的方法依赖于一个ViT主干,并引入了一个受DETR启发的掩模解码器。我们的体系结构不使用卷积,通过设计捕获全局图像上下文,并在标准图像分割基准上产生竞争性能。
3. Our approach: Segmenter
Segmenter是基于一个完全基于transformer的编码器-解码器架构,将一系列的块嵌入映射到像素级的类注释。该模型的概述如图2所示。块序列由第3.1节中描述的transformer编码器进行编码,并由第3.2节中描述的点向线性映射或mask transformer进行解码。我们的模型是端到端训练与每像素的交叉熵损失。在推理时,在上采样后应用argmax来获得每个像素的单个类。
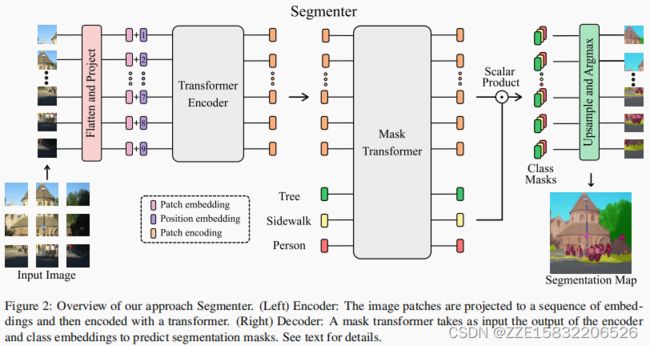
3.1. Encoder
一个图像 x ∈ R H × W × C x∈R^{H×W×C} x∈RH×W×C被分割成一个块序列 x = [ x 1 , . . . , x N ] ∈ R N × P 2 × C x=[x_1,...,x_N]∈R^{N×P^2×C} x=[x1,...,xN]∈RN×P2×C,其中 ( P , P ) (P,P) (P,P)是划分的块的大小, N = H W / P 2 N=HW/P^2 N=HW/P2是块的数量,C是通道的数量。每个块被压平成一个一维向量,然后线性投影到一个块嵌入,产生一个块嵌入序列 x 0 = [ E x 1 , . . . , E x N ] ∈ R N × D x_0=[E_{x_1},...,E_{x_N}]∈R^{N×D} x0=[Ex1,...,ExN]∈RN×D,其中 E ∈ R D × ( P 2 C ) E∈R^{D×(P^2C)} E∈RD×(P2C)。为了获取位置信息,将可学习的位置嵌入点 = [ p o s 1 , . . . , p o s N ] ∈ R N × D =[pos_1,...,pos_N]∈R^{N×D} =[pos1,...,posN]∈RN×D添加到块序列中,得到标记 z 0 = x 0 + p o s z_0=x_0+pos z0=x0+pos的输入序列。
将由L层组成的transformer编码器应用于标记 z 0 z_0 z0的序列,生成上下文化编码 z L ∈ R N × D z_L∈R^{N×D} zL∈RN×D序列。transformer层由一个多头自注意(MSA)块组成,然后是一个由两层组成的点向MLP块组成,在每个块之前应用LayerNorm(LN),在每个块之后添加残差块。
a i − 1 = M S A ( L N ( z i − 1 ) ) + z i − 1 , ( 1 ) a_{i−1}=MSA(LN(z_{i−1}))+z_{i−1},(1) ai−1=MSA(LN(zi−1))+zi−1,(1)
z i = M L P ( L N ( a i − 1 ) ) + a i − 1 , ( 2 ) z_i=MLP(LN(a_{i−1}))+a_{i−1},(2) zi=MLP(LN(ai−1))+ai−1,(2)
其中,i是∈ 1 , . . . , L {1,...,L} 1,...,L。自注意机制由三个点向线性层映射标记到中间表示、query Q ∈ R N × d Q∈R^{N×d} Q∈RN×d、keys K ∈ R N × d K∈R^{N×d} K∈RN×d 和 values V ∈ R N × d V∈R^{N×d} V∈RN×d组成。然后,自我注意的计算方法如下:
M S A ( Q , K , V ) = s o f t m a x ( Q K T √ d ) V ( 3 ) MSA(Q, K, V) = softmax({ {QK^T} \over {√d} }) V (3) MSA(Q,K,V)=softmax(√dQKT)V(3)
transformer编码器将具有位置编码的嵌入式补丁的输入序列 z 0 = [ z 0 , 1 , . . . , z 0 , N ] z_0=[z_{0,1},...,z_{0,N}] z0=[z0,1,...,z0,N]映射到 z L = [ z L , 1 , . . . , z L , N ] z_L=[z_{L,1},...,z_{L,N}] zL=[zL,1,...,zL,N],这是一个包含解码器使用的丰富语义信息的上下文编码序列。
3.2. Decoder
块编码序列 z L ∈ R N × D z_L∈R^{N×D} zL∈RN×D被解码为分割映射 s ∈ R H × W × K s∈R^{H×W×K} s∈RH×W×K,其中K为类数。解码器学习将来自编码器的补丁级编码映射到补丁级的类分数。接下来,这些补丁级类分数通过线性插值双线性插值上采样到像素级分数。我们将在下面描述一个线性解码器,它作为一个基线,而我们的方法是一个掩码转换器,见图2。
Linear 对块的编码 z L ∈ R N × D z_L∈R^{N×D} zL∈RN×D应用点向线性层,产生块级类对数 z l i n ∈ R N × K z_{lin}∈R^{N×K} zlin∈RN×K。然后将序列重塑为2D特征图 s l i n ∈ R H / P × W / P × K s_{lin}∈R^{H/P×W/P×K} slin∈RH/P×W/P×K,并提前上采样到原始图像大小 s ∈ R H × W × K s∈R^{H×W×K} s∈RH×W×K。然后在类维度上应用softmax,得到最终的分割映射。
Mask Transformer 对于基于transformer的解码器,我们引入了一组K个可学习的类嵌入 c l s = [ c l s 1 , . . . , c l s K ] ∈ R K × D cls=[cls_1,...,cls_K]∈R^{K×D} cls=[cls1,...,clsK]∈RK×D,其中K是类的数量。每个类的嵌入都被随机初始化,并分配给一个语义类。它将用于生成类掩码。类嵌入 c l s cls cls由解码器与补丁编码 z L z_L zL联合处理,如图2所示。解码器是一个由M层组成的transformer编码器。我们的mask transformer 通过计算解码器输出的l2标准化补丁嵌入 z M ∈ R N × D z_M∈R^{N×D} zM∈RN×D与类嵌入 c ∈ R K × D c∈R^{K×D} c∈RK×D之间的标量乘积来生成K个掩码。类掩码的集合计算如下:
M a s k s ( z M , c ) = z M c T Masks(z_M, c) = z_Mc^T Masks(zM,c)=zMcT
其中,Masks ( z M , c ) ∈ R N × K (z_M,c)∈R^{N×K} (zM,c)∈RN×K是一组块序列。然后将每个mask序列重塑为二维mask,形成 s m a s k ∈ R H / P × W / P × K s_{mask}∈R^{H/P×W/P×K} smask∈RH/P×W/P×K,并提前上采样到原始图像大小,获得特征图 s ∈ R H × W × K s∈R^{H×W×K} s∈RH×W×K。然后在类维度上应用一个softmax,然后应用一个层范数,得到像素级的类分数,形成最终的分割图。
我们的Mask Transformer受到了DETR[7]、MaxDeepLab[52]和SOLO-v2[55]的启发,它们引入了对象嵌入[7]来生成实例掩码[52,55]。然而,与我们的方法不同的是,MaxDeep-Lab使用了一种基于cnn和transformer的混合方法,并由于计算限制,将像素和类嵌入分割成两个流。使用纯Transformer架构和利用块编码,我们提出了一种简单的方法,在解码阶段联合处理块和类嵌入。这种方法允许产生动态滤波器,随输入而变化。当我们在这项工作中处理语义分割时,我们的Mask Transformer也可以直接适应于通过用对象嵌入替换类嵌入来执行实例分割。
4. Experimental results
4.1. Datasets and metrics
ADE20K 该数据集包含具有细粒度标签的挑战性场景,是最具挑战性的语义分割数据集之一。该训练集包含20,210张图像和150个语义类。验证集和测试集分别包含2000张和3352张图像。
Pascal Context该训练集包含4,996张图像,包括59个语义类和一个背景类。验证集包含5,104张图像。
Cityscapes该数据集包含来自50个不同城市的5000张图像,其中有19个语义类。训练集中有2975张图像,验证集中有500张图像,测试集中有1525张图像。指标。我们报告了所有类的Union(mIoU)的平均值
4.2. Implementation details
Transformer型号。对于编码器,我们建立在视觉转换器ViT[19]的基础上,并考虑表1中描述的“小”、“中”和“大”模型。在Transformer编码器中变化的参数是层数和令牌大小。多头自注意(MSA)块的头部大小固定为64,头的数量是令牌大小除以头部大小,MSA之后的MLP的隐藏大小是令牌大小的4倍。我们还使用了DeiT[49],一种vision transformer的变体。我们考虑代表不同分辨率图像的模型,并使用输入补丁大小为8×8、16×16和32×32。在下面,我们使用一个缩写来描述模型变体和补丁大小,例如SegB/16表示具有16×16输入补丁大小的“基本”变体。基于DeiT的模型用a表示,例如SegB/16
Transformer models 我们的Segmenter在ImageNet上进行预训练,ViT在ImageNet-21k上进行预训练,采用强数据增强和正则化进行预训练,其变体DeiT在ImageNet-1k上进行预训练。原始的ViT模型只使用随机裁剪进行训练,而[47]提出的训练程序结合使用dropout作为正则化,Mixup和RandAugment作为数据扩充。这显著提高了ImageNet的前1位精度,即它在ViT-B/16上获得了2%的+增益。
下面,所有的Segmenter都将使用[47]改进的ViT模型进行初始化。我们使用由图像分类库timm和Google research 提供的公开模型。这两种模型都在224的图像分辨率下进行了预训练,并在ImageNet-1k上以分辨率为384进行了微调,除了ViT-B/8的分辨率为224进行了微调。我们保持补丁大小的固定,并根据数据集对语义分割任务以更高的分辨率进行微调。由于补丁的大小是固定的,增加分辨率会导致更长的标记序列。在[19]之后,我们根据预先训练好的位置嵌入在图像中的原始位置进行双元插值,以匹配微调序列的长度。在第3.2节中描述的解码器用来自被截断的正态分布的随机权值进行初始化。
Data augmentation 在训练过程中,我们遵循语义分割库MMS分割中的标准管道,这意味着减法,将图像随机调整到0.5和2.0之间的比例,以及随机左右翻转。我们随机裁剪大图像,并将小图像填充到固定大小为512×512,Pascal上下文为480×480,城市景观为768×768。在ADE20K上,我们训练了我们最大的模型Seg-L-Mask/16,分辨率为640×640,与Swin Transformer使用的分辨率相匹配。