iris数据_Python数据分析实战,尾鸢花数据集数据分析
本节所使用的尾鸢花数据集是Python中自带的数据集,常用于机器学习分类算法模型,其中sepal_length_cm、sepal_width_cm、petal_length_cm、petal_width_cm、class字段代表的含义分别是花萼长度、花萼宽度、花瓣长度、花瓣宽度、尾鸢花的类别。
一、数据来源
from pandas import Series,DataFrameimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib as mplimport seaborn as sns #导入seaborn绘图库%matplotlib inlineiris_data = pd.read_csv(open('D:python数据分析数据iris-data.csv'))iris_data.head()
二、问题探索
通过数据可视化和分析,按照尾鸢花的特征分出尾鸢花的类别。
三、数据清洗
iris_data.shape(150, 5)
共有150条数据,5列。
iris_data.describe()
由描述统计可以看出,数据没有缺失值。
iris_data['class'].unique() #查看唯一值array(['Iris-setosa', 'Iris-setossa', 'Iris-versicolor', 'versicolor','Iris-virginica'], dtype=object)iris_data.ix[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'iris_data.ix[iris_data['class'] == 'Iris-setossa', 'class'] = 'Iris-setosa'iris_data['class'].unique() #查看唯一值array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)sns.pairplot(iris_data, hue='class')
利用seaborn绘制散点图矩阵,通过第一列可看出,有几个Iris-versicolor样本中的sepal_length_cm值偏移了大部分的点,通过第二行可看出,一个Iris-setosa样本的sepal_width_cm值偏离了大部分点。
iris_data.ix[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
对通过Iris-setosa的花萼宽度绘制直方图也能观测出异常。
过滤小于2.5cm的数据后再做直方图。
iris_data = iris_data.loc[(iris_data['class'] != 'Iris-setosa') | (iris_data['sepal_width_cm'] >= 2.5)]iris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
通过索引选取Iris-versicolor样本中sepal_length值小于0.1的数据,选取异常数据。
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &(iris_data['sepal_length_cm'] < 1.0)]
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &(iris_data['sepal_length_cm'] 发现花瓣宽度有5条缺失值,由于3种分类数据样本均衡,直接将缺失值删除处理。
iris_data.isnull().sum()
发现花瓣宽度有5条缺失值。
iris_data[iris_data['petal_width_cm'].isnull()] #处理缺失值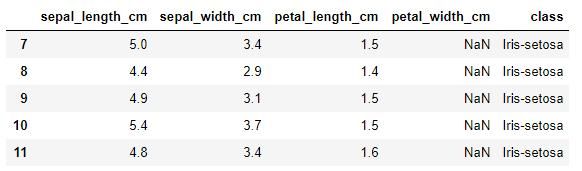
iris_data.dropna(inplace=True)iris_data.to_csv('D:python数据分析数据iris-clean-data.csv', index=False) #保存清洗后的数据iris_data = pd.read_csv(open('D:python数据分析数据iris-clean-data.csv'))iris_data.head()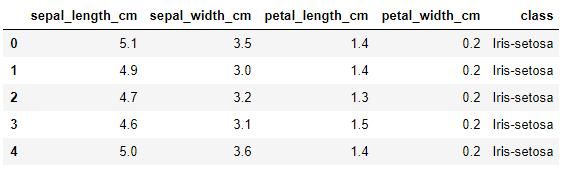
iris_data.shape(144, 5)
数据清洗后,有144条数据,5列。
四、数据探索
sns.pairplot(iris_data, hue='class')
绘制散点矩阵图可以发现,大部分情况下数据接近正态分布,而且Iris-setosa与其他两种花是线性可分的,其他两种花型可能需要非线性算法进行分类。
iris_data.boxplot(column='petal_length_cm', by='class',grid=False,figsize=(6,6))
通过petal_length_cm(花瓣长度)可以轻松区分Iris-setosa与其他两种花。