深度学习模型试跑(十四):Bytetrack(vs2019 训练+trt推理部署)
目录
- 前言
- 一.模型解读
- 二.代码
- 三.数据准备
- 四.模型训练
- 五.VS2019运行C++预测
前言
这里记录了多目标追踪模型Bytetrack在win10/vs2019 上,用自定义数据集训模、tensorrt部署的大致过程。
我的环境:
- Visual Studio 2019
- CUDA 11.5,cudnn 8.2
- CMake 3.17.1
- tensorrt:8.4.1.5
一.模型解读
可以参考实时目标追踪:ByteTrack算法步骤详解和代码逐行解析,模型和代码关键的地方都有做介绍。需要具体研究的建议去看一下github项目,不了解MOT的可以先看下多目标跟踪MOT数据集格式介绍。
二.代码
参考官方
三.数据准备
这里参考了官方的数据准备,可以参照我之前写的yolov5 + deepsort准备数据。我这里只用了MOT17,主要我自己的数据集是照着MOT17的格式处理了一遍,下表中的mot对应的就是MOT17数据集,放在
- 配置自己的数据
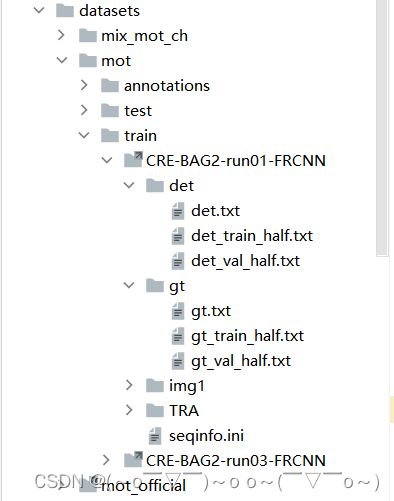
datasets
|——————custom_dataset(mot17格式的)
| └——————train
| └——————sub_dataset_1(记得后面加FRCNN)
| └——————det(这个一般没有,可以训练的检测模型生成,我这里用的是yolox,下面是生成脚本)
| └——————img1
| └——————gt
| └——————…
| └——————sub_dataset_n
| └——————test
|——————mot
| └——————train
| └——————test
└——————crowdhuman
| └——————Crowdhuman_train
| └——————Crowdhuman_val
| └——————annotation_train.odgt
| └——————annotation_val.odgt
└——————MOT20
| └——————train
| └——————test
└——————Cityscapes
| └——————images
| └——————labels_with_ids
└——————ETHZ
└——————eth01
└——————…
└——————eth07
生成det下一系列的txt.py(基于YOLOX demo.py 修改出来的,代码修改思路)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import argparse
import os
import time
from loguru import logger
import cv2
import sys
sys.path.append(r'path to yolox home')#改成自己yolox的路径
import torch
from yolox.data.data_augment import ValTransform
from yolox.data.datasets import COCO_CLASSES
from yolox.exp import get_exp
from yolox.utils import fuse_model, get_model_info, postprocess, vis
from yolox.data.datasets import voc_classes
IMAGE_EXT = [".jpg", ".jpeg", ".webp", ".bmp", ".png"]
Dataset_path = r'path to a sub dataset'#改成自己某个子数据集的路径
def make_parser():
parser = argparse.ArgumentParser("YOLOX Demo!")
parser.add_argument(
"--mot_det_gen", default=os.path.join(Dataset_path,'det\det.txt'),
help="利用yolox制作mot17数据集格式里的det.txt"
)
parser.add_argument(
"--demo", default="image", help="demo type, eg. image, video and webcam"
)
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
parser.add_argument("-n", "--name", type=str, default=None, help="model name")
parser.add_argument(
"--path", default=os.path.join(Dataset_path,'img1'), help="path to images or video"
)
parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")
parser.add_argument(
"--save_result",
action="store_true",
default=True,
help="whether to save the inference result of image/video",
)
# exp file,我用yolox_voc_l的标准把数据训练了一遍,下面两个参数记得改一下
parser.add_argument(
"-f",
"--exp_file",
default='../exps/example/yolox_voc/yolox_voc_l.py',
type=str,
help="please input your experiment description file",
)
parser.add_argument("-c", "--ckpt", default='../YOLOX_outputs/yolox_voc_l/best_ckpt.pth', type=str, help="ckpt for eval")
parser.add_argument(
"--device",
default="gpu",
type=str,
help="device to run our model, can either be cpu or gpu",
)
parser.add_argument("--conf", default=0.8, type=float, help="test conf")
parser.add_argument("--nms", default=0.3, type=float, help="test nms threshold")
parser.add_argument("--tsize", default=None, type=int, help="test img size")
parser.add_argument(
"--fp16",
dest="fp16",
default=False,
action="store_true",
help="Adopting mix precision evaluating.",
)
parser.add_argument(
"--legacy",
dest="legacy",
default=False,
action="store_true",
help="To be compatible with older versions",
)
parser.add_argument(
"--fuse",
dest="fuse",
default=False,
action="store_true",
help="Fuse conv and bn for testing.",
)
parser.add_argument(
"--trt",
dest="trt",
default=False,
action="store_true",
help="Using TensorRT model for testing.",
)
return parser
def get_image_list(path):
image_names = []
for maindir, subdir, file_name_list in os.walk(path):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
ext = os.path.splitext(apath)[1]
if ext in IMAGE_EXT:
image_names.append(apath)
return image_names
class Predictor(object):
def __init__(
self,
model,
exp,
cls_names=voc_classes.VOC_CLASSES,
trt_file=None,
decoder=None,
device="cpu",
fp16=False,
legacy=False,
):
self.model = model
self.cls_names = cls_names
self.decoder = decoder
self.num_classes = exp.num_classes
self.confthre = exp.test_conf
self.nmsthre = exp.nmsthre
self.test_size = exp.test_size
self.device = device
self.fp16 = fp16
self.preproc = ValTransform(legacy=legacy)
if trt_file is not None:
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(trt_file))
x = torch.ones(1, 3, exp.test_size[0], exp.test_size[1]).cuda()
self.model(x)
self.model = model_trt
def inference(self, img):
img_info = {"id": 0}
if isinstance(img, str):
img_info["file_name"] = os.path.basename(img)
img = cv2.imread(img)
else:
img_info["file_name"] = None
height, width = img.shape[:2]
img_info["height"] = height
img_info["width"] = width
img_info["raw_img"] = img
ratio = min(self.test_size[0] / img.shape[0], self.test_size[1] / img.shape[1])
img_info["ratio"] = ratio
img, _ = self.preproc(img, None, self.test_size)
img = torch.from_numpy(img).unsqueeze(0)
img = img.float()
if self.device == "gpu":
img = img.cuda()
if self.fp16:
img = img.half() # to FP16
with torch.no_grad():
t0 = time.time()
outputs = self.model(img)
if self.decoder is not None:
outputs = self.decoder(outputs, dtype=outputs.type())
outputs = postprocess(
outputs, self.num_classes, self.confthre,
self.nmsthre, class_agnostic=True
)
logger.info("Infer time: {:.4f}s".format(time.time() - t0))
return outputs, img_info
def visual(self, output, img_info, cls_conf=0.35):
ratio = img_info["ratio"]
img = img_info["raw_img"]
if output is None:
return img
output = output.cpu()
bboxes = output[:, 0:4]
# preprocessing: resize
bboxes /= ratio
cls = output[:, 6]
scores = output[:, 4] * output[:, 5]
vis_res = vis(img, bboxes, scores, cls, cls_conf, self.cls_names)
return vis_res
def visual_motdet(self, output, img_info, cls_conf=0.35):
ratio = img_info["ratio"]
img = img_info["raw_img"]
if output is None:
return img
output = output.cpu()
bboxes = output[:, 0:4]
# preprocessing: resize
bboxes /= ratio
cls = output[:, 6]
scores = output[:, 4] * output[:, 5]
vis_res = [img, bboxes, scores, cls, cls_conf, self.cls_names]
return vis_res
def image_demo(predictor, vis_folder, path, current_time, save_result, motdet_txt):
if os.path.isdir(path):
files = get_image_list(path)
else:
files = [path]
files.sort()
note = open(motdet_txt, mode='w')
print(motdet_txt)
for file_num,image_name in enumerate(files):
outputs, img_info = predictor.inference(image_name)
result_image = predictor.visual(outputs[0], img_info, predictor.confthre)
result_paras = predictor.visual_motdet(outputs[0], img_info, predictor.confthre)
if save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
save_file_name = os.path.join(save_folder, os.path.basename(image_name))
logger.info("Saving detection result in {}".format(save_file_name))
#cv2.imwrite(save_file_name, result_image)
boxes = result_paras[1]
scores = result_paras[2]
for i in range(len(boxes)):
box = boxes[i]
score = float(scores[i])
x0 = int(box[0])
y0 = int(box[1])
w0 = int(box[2]) - x0
h0 = int(box[3]) - y0
#print(x0,y0,w0,h0,score)
motdet_line = str(file_num)+',-1,'+str(x0)+ ','+str(y0)+ ','+str(w0)+ ','+str(h0)+ ','+str(score)+',-1,-1,-1'
note.write(motdet_line+' \n') # \n 换行符
# cv2.namedWindow("yolox", cv2.WINDOW_NORMAL)
# cv2.imshow("yolox", result_image)
ch = cv2.waitKey(0)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
def imageflow_demo(predictor, vis_folder, current_time, args):
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
if args.save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, os.path.basename(args.path))
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
while True:
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame)
result_frame = predictor.visual(outputs[0], img_info, predictor.confthre)
if args.save_result:
vid_writer.write(result_frame)
else:
cv2.namedWindow("yolox", cv2.WINDOW_NORMAL)
cv2.imshow("yolox", result_frame)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
def main(exp, args):
if not args.experiment_name:
args.experiment_name = exp.exp_name
file_name = os.path.join(exp.output_dir, args.experiment_name)
os.makedirs(file_name, exist_ok=True)
vis_folder = None
if args.save_result:
vis_folder = os.path.join(file_name, "vis_res")
os.makedirs(vis_folder, exist_ok=True)
if args.trt:
args.device = "gpu"
logger.info("Args: {}".format(args))
if args.conf is not None:
exp.test_conf = args.conf
if args.nms is not None:
exp.nmsthre = args.nms
if args.tsize is not None:
exp.test_size = (args.tsize, args.tsize)
model = exp.get_model()
logger.info("Model Summary: {}".format(get_model_info(model, exp.test_size)))
if args.device == "gpu":
model.cuda()
if args.fp16:
model.half() # to FP16
model.eval()
if not args.trt:
if args.ckpt is None:
ckpt_file = os.path.join(file_name, "best_ckpt.pth")
else:
ckpt_file = args.ckpt
logger.info("loading checkpoint")
ckpt = torch.load(ckpt_file, map_location="cpu")
# load the model state dict
model.load_state_dict(ckpt["model"])
logger.info("loaded checkpoint done.")
if args.fuse:
logger.info("\tFusing model...")
model = fuse_model(model)
if args.trt:
assert not args.fuse, "TensorRT model is not support model fusing!"
trt_file = os.path.join(file_name, "model_trt.pth")
assert os.path.exists(
trt_file
), "TensorRT model is not found!\n Run python3 tools/trt.py first!"
model.head.decode_in_inference = False
decoder = model.head.decode_outputs
logger.info("Using TensorRT to inference")
else:
trt_file = None
decoder = None
predictor = Predictor(
model, exp, voc_classes.VOC_CLASSES, trt_file, decoder,
args.device, args.fp16, args.legacy,
)
current_time = time.localtime()
if args.demo == "image":
image_demo(predictor, vis_folder, args.path, current_time, args.save_result, args.mot_det_gen)
elif args.demo == "video" or args.demo == "webcam":
imageflow_demo(predictor, vis_folder, current_time, args)
if __name__ == "__main__":
args = make_parser().parse_args()
exp = get_exp(args.exp_file, args.name)
main(exp, args)
2.将自定义数据转换为coco的数据集格式
cd <ByteTrack_HOME>
python tools/convert_mot17_to_coco.py #注意把第8行 DATA_PATH = 'datasets/mot' 改为自己的数据集路径
3.如果还有其它格式的数据集,可以参考官方将数据进行混合
cd <ByteTrack_HOME>
python tools/mix_data_ablation.py
python tools/mix_data_test_mot17.py
python tools/mix_data_test_mot20.py
四.模型训练
可参考官方教程,我这里直接把train.py直接放到了项目根目录下。
- train.py:
from loguru import logger
import torch
import torch.backends.cudnn as cudnn
from yolox.core import Trainer, launch
from yolox.exp import get_exp
import argparse
import random
import warnings
def make_parser():
parser = argparse.ArgumentParser("YOLOX train parser")
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
parser.add_argument("-n", "--name", type=str, default=None, help="model name")
# distributed
parser.add_argument(
"--dist-backend", default="gloo", type=str, help="distributed backend"
)
parser.add_argument(
"--dist-url",
default=None,
type=str,
help="url used to set up distributed training",
)
parser.add_argument("-b", "--batch-size", type=int, default=64, help="batch size")
parser.add_argument(
"-d", "--devices", default=1, type=int, help="device for training"
)
parser.add_argument(
"--local_rank", default=0, type=int, help="local rank for dist training"
)
parser.add_argument(
"-f",
"--exp_file",
default=None,
type=str,
help="plz input your expriment description file",
)
parser.add_argument(
"--resume", default=False, action="store_true", help="resume training"
)
parser.add_argument("-c", "--ckpt", default=None, type=str, help="checkpoint file")
parser.add_argument(
"-e",
"--start_epoch",
default=None,
type=int,
help="resume training start epoch",
)
parser.add_argument(
"--num_machines", default=1, type=int, help="num of node for training"
)
parser.add_argument(
"--machine_rank", default=0, type=int, help="node rank for multi-node training"
)
parser.add_argument(
"--fp16",
dest="fp16",
default=False,
action="store_true",
help="Adopting mix precision training.",
)
parser.add_argument(
"-o",
"--occupy",
dest="occupy",
default=False,
action="store_true",
help="occupy GPU memory first for training.",
)
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
return parser
@logger.catch
def main(exp, args):
if exp.seed is not None:
random.seed(exp.seed)
torch.manual_seed(exp.seed)
cudnn.deterministic = True
warnings.warn(
"You have chosen to seed training. This will turn on the CUDNN deterministic setting, "
"which can slow down your training considerably! You may see unexpected behavior "
"when restarting from checkpoints."
)
# set environment variables for distributed training
cudnn.benchmark = False
trainer = Trainer(exp, args)
trainer.train()
if __name__ == "__main__":
args = make_parser().parse_args()
exp = get_exp(args.exp_file, args.name)
exp.merge(args.opts)
if not args.experiment_name:
args.experiment_name = exp.exp_name
num_gpu = torch.cuda.device_count() if args.devices is None else args.devices
assert num_gpu <= torch.cuda.device_count()
launch(
main,
num_gpu,
args.num_machines,
args.machine_rank,
backend=args.dist_backend,
dist_url=args.dist_url,
args=(exp, args),
)
- 训练:
#开始训练: python train.py -f exps/example/mot/yolox_x_ablation.py -d 1 -b 2 -c pretrained/yolox_x.pth #恢复训练: - 预测: (记得注释掉./yolox/data/datasets/data_augment.py line203~208)
运行tools/demo_track.py,要修改的地方可以看里面的注释
from loguru import logger
import cv2
import torch
from yolox.data.data_augment import preproc
from yolox.exp import get_exp
from yolox.utils import fuse_model, get_model_info, postprocess, vis
from yolox.utils.visualize import plot_tracking
from yolox.tracker.byte_tracker import BYTETracker
from yolox.tracking_utils.timer import Timer
import argparse
import os
import time
IMAGE_EXT = [".jpg", ".jpeg", ".webp", ".bmp", ".png"]
Dataset_path =r'path to a sub dataset'#改成自己某个子数据集的路径
def make_parser():
parser = argparse.ArgumentParser("ByteTrack Demo!")
parser.add_argument(
"--demo", default="video", help="demo type, eg. image, video and webcam"
)
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
parser.add_argument("-n", "--name", type=str, default='yolox-x', help="model name")
parser.add_argument(
#"--path", default=os.path.join(Dataset_path, 'img1'), help="path to images or video"
"--path", default="../videos/CRE-BAG2-run03.mp4", help="path to images or video,改成自己要预测的数据集"
)
parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")
parser.add_argument(
"--save_result",
action="store_true",
help="whether to save the inference result of image/video",
default=True,
)
# exp file
parser.add_argument(
"-f",
"--exp_file",
default='../exps/example/mot/yolox_x_ablation.py',
type=str,
help="pls input your expriment description file",
)
parser.add_argument("-c", "--ckpt", default='../YOLOX_outputs/yolox_x_ablation/best_ckpt.pth.tar', type=str, help="ckpt for eval,改成自己的训模后的模型")
parser.add_argument(
"--device",
default="gpu",
type=str,
help="device to run our model, can either be cpu or gpu",
)
parser.add_argument("--conf", default=None, type=float, help="test conf")
parser.add_argument("--nms", default=None, type=float, help="test nms threshold")
parser.add_argument("--tsize", default=None, type=int, help="test img size")
parser.add_argument(
"--fp16",
dest="fp16",
default=True,
action="store_true",
help="Adopting mix precision evaluating.",
)
parser.add_argument(
"--fuse",
dest="fuse",
default=False,
action="store_true",
help="Fuse conv and bn for testing.",
)
parser.add_argument(
"--trt",
dest="trt",
default=False,
action="store_true",
help="Using TensorRT model for testing.",
)
# tracking args
parser.add_argument("--track_thresh", type=float, default=0.5, help="tracking confidence threshold")
parser.add_argument("--track_buffer", type=int, default=30, help="the frames for keep lost tracks")
parser.add_argument("--match_thresh", type=int, default=0.8, help="matching threshold for tracking")
parser.add_argument('--min-box-area', type=float, default=10, help='filter out tiny boxes')
parser.add_argument("--mot20", dest="mot20", default=False, action="store_true", help="test mot20.")
return parser
def get_image_list(path):
image_names = []
for maindir, subdir, file_name_list in os.walk(path):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
ext = os.path.splitext(apath)[1]
if ext in IMAGE_EXT:
image_names.append(apath)
return image_names
def write_results(filename, results):
save_format = '{frame},{id},{x1},{y1},{w},{h},{s},-1,-1,-1\n'
with open(filename, 'w') as f:
for frame_id, tlwhs, track_ids, scores in results:
for tlwh, track_id, score in zip(tlwhs, track_ids, scores):
if track_id < 0:
continue
x1, y1, w, h = tlwh
line = save_format.format(frame=frame_id, id=track_id, x1=round(x1, 1), y1=round(y1, 1), w=round(w, 1),
h=round(h, 1), s=round(score, 2))
f.write(line)
logger.info('save results to {}'.format(filename))
class Predictor(object):
def __init__(
self,
model,
exp,
trt_file=None,
decoder=None,
device="cpu",
fp16=False
):
self.model = model
self.decoder = decoder
self.num_classes = exp.num_classes
self.confthre = exp.test_conf
self.nmsthre = exp.nmsthre
self.test_size = exp.test_size
self.device = device
self.fp16 = fp16
if trt_file is not None:
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(trt_file))
x = torch.ones(1, 3, exp.test_size[0], exp.test_size[1]).cuda()
self.model(x)
self.model = model_trt
self.rgb_means = (0.485, 0.456, 0.406)
self.std = (0.229, 0.224, 0.225)
def inference(self, img, timer):
img_info = {"id": 0}
if isinstance(img, str):
img_info["file_name"] = os.path.basename(img)
img = cv2.imread(img)
else:
img_info["file_name"] = None
height, width = img.shape[:2]
img_info["height"] = height
img_info["width"] = width
img_info["raw_img"] = img
img, ratio = preproc(img, self.test_size, self.rgb_means, self.std)
img_info["ratio"] = ratio
img = torch.from_numpy(img).unsqueeze(0)
img = img.float()
if self.device == "gpu":
img = img.cuda()
if self.fp16:
img = img.half() # to FP16
with torch.no_grad():
timer.tic()
outputs = self.model(img)
if self.decoder is not None:
outputs = self.decoder(outputs, dtype=outputs.type())
outputs = postprocess(
outputs, self.num_classes, self.confthre, self.nmsthre
)
# logger.info("Infer time: {:.4f}s".format(time.time() - t0))
return outputs, img_info
def image_demo(predictor, vis_folder, path, current_time, save_result):
if os.path.isdir(path):
files = get_image_list(path)
else:
files = [path]
files.sort()
tracker = BYTETracker(args, frame_rate=30)
timer = Timer()
frame_id = 0
results = []
for image_name in files:
if frame_id % 20 == 0:
logger.info('Processing frame {} ({:.2f} fps)'.format(frame_id, 1. / max(1e-5, timer.average_time)))
outputs, img_info = predictor.inference(image_name, timer)
online_targets = tracker.update(outputs[0], [img_info['height'], img_info['width']], exp.test_size)
online_tlwhs = []
online_ids = []
online_scores = []
for t in online_targets:
tlwh = t.tlwh
tid = t.track_id
vertical = tlwh[2] / tlwh[3] > 1.6
if tlwh[2] * tlwh[3] > args.min_box_area and not vertical:
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
timer.toc()
# save results
results.append((frame_id + 1, online_tlwhs, online_ids, online_scores))
online_im = plot_tracking(img_info['raw_img'], online_tlwhs, online_ids, frame_id=frame_id + 1,
fps=1. / timer.average_time)
# result_image = predictor.visual(outputs[0], img_info, predictor.confthre)
if save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
save_file_name = os.path.join(save_folder, os.path.basename(image_name))
# cv2.imshow('demo', online_im)
cv2.imwrite(save_file_name, online_im)
ch = cv2.waitKey(0)
frame_id += 1
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
# write_results(result_filename, results)
def imageflow_demo(predictor, vis_folder, current_time, args):
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, args.path.split("/")[-1])
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
tracker = BYTETracker(args, frame_rate=30)
timer = Timer()
frame_id = 0
results = []
frame_id_tmp = 0
print(os.path.join(Dataset_path, 'det', 'det.txt'))
det_txt = open(os.path.join(Dataset_path, 'det', 'det.txt'), mode='w')
while True:
if frame_id % 20 == 0:
logger.info('Processing frame {} ({:.2f} fps)'.format(frame_id, 1. / max(1e-5, timer.average_time)))
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame, timer)
# #限制目标检测的x1y1x2y2尺寸要超出边界
# outputs_tmp = outputs[0]
# outputs_tmp[outputs_tmp[:, 0] <= 0, 0] = 0
# outputs_tmp[outputs_tmp[:, 2] <= 0, 2] = 0
# outputs_tmp[outputs_tmp[:, 1] >= torch.from_numpy(np.array(exp.test_size[0])).cuda().float(), 1] = torch.from_numpy(np.array(exp.test_size[0]-1)).cuda().float()
# outputs_tmp[outputs_tmp[:, 3] >= torch.from_numpy(np.array(exp.test_size[1])).cuda().float(), 3] = torch.from_numpy(np.array(exp.test_size[1]-1)).cuda().float()
box_id_tmp = 0
for tmp_i in outputs[0]:
box_id_tmp += 1
tmp_np = tmp_i.cpu().numpy()
# print(str(frame_id_tmp) , str(box_id_tmp) ,tmp_np[:4] , tmp_np[2:4]-tmp_np[0:2] , tmp_np[4]*tmp_np[5]) #打印信息
frame_id_tmp += 1
# 限制因为细胞在边缘,检测框长宽比异常,经过卡尔曼预测之后框尺寸错误的情况;
bbox_ratio_thresh = 2.0
edge = 20
bbox_i = 0
draw_output_results = outputs[0].cpu().numpy()
for draw_box_pos in draw_output_results:
scores = draw_box_pos[4] * draw_box_pos[5]
bboxes = draw_box_pos[:4] # x1y1x2y2
bbox_x = draw_box_pos[0]
bbox_y = draw_box_pos[1]
bbox_w = draw_box_pos[2] - draw_box_pos[0]
bbox_h = draw_box_pos[3] - draw_box_pos[1]
if (bbox_w > bbox_h):
bbox_ratio = bbox_w / bbox_h
fix_size = bbox_w
else:
bbox_ratio = bbox_h / bbox_w
fix_size = bbox_h
if (bbox_ratio < bbox_ratio_thresh):
pass # 尺寸正常,不进行操作
else:
# 尺寸异常,进行修正
draw_box_pos[2] = draw_box_pos[0] + fix_size
draw_box_pos[3] = draw_box_pos[1] + fix_size
outputs_copy = outputs[0][bbox_i]
outputs_copy[2] = torch.tensor(draw_box_pos[0] + fix_size)
outputs_copy[3] = torch.tensor(draw_box_pos[1] + fix_size)
bbox_i += 1
if outputs[0] is not None:
online_targets = tracker.update(outputs[0], [img_info['height'], img_info['width']], exp.test_size)
for tmp_i in range(0, len(online_targets)):
# print(str(frame_id_tmp-1), str(tmp_i), online_targets[tmp_i].tlbr , online_targets[tmp_i].tlwh)
# print(str(frame_id_tmp - 1), str(tmp_i), online_targets[tmp_i].tlbr[0], online_targets[tmp_i].tlbr[1],online_targets[tmp_i].tlbr[2],online_targets[tmp_i].tlbr[3] , online_targets[tmp_i].track_id)
# 输出格式:
single_obj = str(frame_id_tmp - 1) + ',' + '-1' + ',' + str(
format(online_targets[tmp_i].tlbr[0], '.3f')) + ',' + str(
format(online_targets[tmp_i].tlbr[1], '.3f')) + ',' + str(
format(online_targets[tmp_i].tlbr[2], '.3f')) + ',' + str(
format(online_targets[tmp_i].tlbr[3], '.3f')) + ',' + str(
online_targets[tmp_i].score) + ',-1,-1,-1\n'
det_txt.write(single_obj) # \n 换行符
# print(str(frame_id_tmp - 1) + ',' + '-1' + ',' +
# str(format(online_targets[tmp_i].tlbr[0], '.3f')) + ',' +
# str(format(online_targets[tmp_i].tlbr[1], '.3f')) + ',' +
# str(format(online_targets[tmp_i].tlbr[2], '.3f')) + ',' +
# str(format(online_targets[tmp_i].tlbr[3], '.3f')) + ',' +
# str(online_targets[tmp_i].score) + ',-1,-1,-1')
online_tlwhs = []
online_ids = []
online_scores = []
for t in online_targets:
tlwh = t.tlwh
tid = t.track_id
vertical = tlwh[2] / tlwh[3] > 1.6
if tlwh[2] * tlwh[3] > args.min_box_area and not vertical:
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
timer.toc()
results.append((frame_id + 1, online_tlwhs, online_ids, online_scores))
online_im = plot_tracking(img_info['raw_img'], online_tlwhs, online_ids, frame_id=frame_id + 1,
fps=1. / timer.average_time)
if args.save_result:
cv2.imshow('online_im', online_im)
vid_writer.write(online_im)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
frame_id += 1
det_txt.close()
def main(exp, args):
torch.cuda.set_device('cuda:0')
if not args.experiment_name:
args.experiment_name = exp.exp_name
file_name = os.path.join(exp.output_dir, args.experiment_name)
os.makedirs(file_name, exist_ok=True)
# if args.save_result:
vis_folder = os.path.join(file_name, "track_vis")
os.makedirs(vis_folder, exist_ok=True)
if args.trt:
args.device = "gpu"
logger.info("Args: {}".format(args))
if args.conf is not None:
exp.test_conf = args.conf
if args.nms is not None:
exp.nmsthre = args.nms
if args.tsize is not None:
exp.test_size = (args.tsize, args.tsize)
model = exp.get_model()
logger.info("Model Summary: {}".format(get_model_info(model, exp.test_size)))
if args.device == "gpu":
model.cuda()
model.eval()
if not args.trt:
if args.ckpt is None:
ckpt_file = os.path.join(file_name, "best_ckpt.pth.tar")
else:
ckpt_file = args.ckpt
logger.info("loading checkpoint")
ckpt = torch.load(ckpt_file, map_location="cpu")
# load the model state dict
model.load_state_dict(ckpt["model"])
logger.info("loaded checkpoint done.")
if args.fuse:
logger.info("\tFusing model...")
model = fuse_model(model)
if args.fp16:
model = model.half() # to FP16
if args.trt:
assert not args.fuse, "TensorRT model is not support model fusing!"
trt_file = os.path.join(file_name, "model_trt.pth")
assert os.path.exists(
trt_file
), "TensorRT model is not found!\n Run python3 tools/trt.py first!"
model.head.decode_in_inference = False
decoder = model.head.decode_outputs
logger.info("Using TensorRT to inference")
else:
trt_file = None
decoder = None
predictor = Predictor(model, exp, trt_file, decoder, args.device, args.fp16)
current_time = time.localtime()
if args.demo == "image":
image_demo(predictor, vis_folder, args.path, current_time, args.save_result)
elif args.demo == "video" or args.demo == "webcam":
imageflow_demo(predictor, vis_folder, current_time, args)
if __name__ == "__main__":
args = make_parser().parse_args()
print(args)
exp = get_exp(args.exp_file, args.name)
main(exp, args)
-
导出预测模型(torch onnx)
python export_onnx.py --output-name bytetrack_x.onnx -f exps/example/mot/yolox_x_ablation.py -c YOLOX_outputs/yolox_x_ablation/best_ckpt.pth.tar -
转trt模型(onnx trt)
cp path_to_model/bytetrack_x.onnx tensorrt_home/bin (拷贝onnx) cd tensorrt_home/bin trtexec.exe --onnx=bytetrack_x.onnx --saveEngine=bytetrack_x.engine --buildOnly
五.VS2019运行C++预测
主要参照官方给的Deploy里的2、3条
- 将转好的trt模型拷贝到.\YOLOX_outputs\yolox_s_mix_det下,修改并替换CmakeLists,用CMake工具生成vs2019工程,在release模式下编译。
cmakelist.txt (自行修改标记了 # 的地方)
cmake_minimum_required(VERSION 3.0)
project(bytetrack)
list(APPEND CUDA_NVCC_FLAGS "-std=c++11")
set(CMAKE_CXX_FLAGS "-std=c++0x")
set(OpenCV_DIR D:\\software\\opencv\\opencv460\\build) #修改
find_package(OpenCV REQUIRED)
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Release)
set(CUDA_BIN_PATH C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.6) #修改
set(TRT_DIR "D:\\lbq\\TensorRT-8.4.1.5") #修改
set(TRT_INCLUDE_DIRS ${TRT_DIR}\\include)
set(TRT_LIB_DIRS ${TRT_DIR}\\lib)
set(Eigen3_PATH D:\\lbq\\eigen\\eigen-3.4.0) #修改,在网上下载完成后无需编译直接调用
set(Dirent_INCLUDE_DIRS "D:\\lbq\\dirent\\include") #修改,在网上下载完成后无需编译直接调用
find_package(CUDA REQUIRED)
set(CUDA_NVCC_PLAGS ${CUDA_NVCC_PLAGS};-std=c++11;-g;-G;-gencode;arch=compute_86;code=sm_86)
if(WIN32)
enable_language(CUDA)
endif(WIN32)
# include_directories(${PROJECT_SOURCE_DIR}/deepsort/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# tensorrt
link_directories(${TRT_LIB_DIRS})
link_directories(${OpenCV_LIB_DIRS})
include_directories(
${CUDA_INCLUDE_DIRS}
${OpenCV_INCLUDE_DIRS}
${TRT_INCLUDE_DIRS}
${Eigen3_PATH}
${Dirent_INCLUDE_DIRS}
${PROJECT_SOURCE_DIR}/include
)
link_directories(${PROJECT_SOURCE_DIR}/include)
file(GLOB My_Source_Files ${PROJECT_SOURCE_DIR}/src/*.cpp)
add_executable(bytetrack ${My_Source_Files})
target_link_libraries(bytetrack nvinfer)
target_link_libraries(bytetrack cudart)
target_link_libraries(bytetrack ${OpenCV_LIBS})
add_definitions(-O2 -pthread)
- 将主程序代码bytetrack.cpp用我写的替换,注意其中我的文件调用是用了绝对路径,第444行和479行。
#include (h, w)[c]) / 255.0f - mean[c]) / std[c];
blob[c * img_w * img_h + h * img_w + w] = (float)img.at<Vec3b>(h, w)[c];
}
}
}
return blob;
}
static void decode_outputs(float* prob, vector<Object>& objects, float scale, const int img_w, const int img_h) {
vector<Object> proposals;
vector<int> strides = {8, 16, 32};
vector<GridAndStride> grid_strides;
generate_grids_and_stride(INPUT_W, INPUT_H, strides, grid_strides);
generate_yolox_proposals(grid_strides, prob, BBOX_CONF_THRESH, proposals);
//std::cout << "num of boxes before nms: " << proposals.size() << std::endl;
qsort_descent_inplace(proposals);
vector<int> picked;
nms_sorted_bboxes(proposals, picked, NMS_THRESH);
int count = picked.size();
//std::cout << "num of boxes: " << count << std::endl;
objects.resize(count);
cout << "Total count: " << count << endl;
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x) / scale;
float y0 = (objects[i].rect.y) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height) / scale;
// clip
// x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
// y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
// x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
// y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
}
const float color_list[80][3] =
{
{0.000, 0.447, 0.741},
{0.850, 0.325, 0.098},
{0.929, 0.694, 0.125},
{0.494, 0.184, 0.556},
{0.466, 0.674, 0.188},
{0.301, 0.745, 0.933},
{0.635, 0.078, 0.184},
{0.300, 0.300, 0.300},
{0.600, 0.600, 0.600},
{1.000, 0.000, 0.000},
{1.000, 0.500, 0.000},
{0.749, 0.749, 0.000},
{0.000, 1.000, 0.000},
{0.000, 0.000, 1.000},
{0.667, 0.000, 1.000},
{0.333, 0.333, 0.000},
{0.333, 0.667, 0.000},
{0.333, 1.000, 0.000},
{0.667, 0.333, 0.000},
{0.667, 0.667, 0.000},
{0.667, 1.000, 0.000},
{1.000, 0.333, 0.000},
{1.000, 0.667, 0.000},
{1.000, 1.000, 0.000},
{0.000, 0.333, 0.500},
{0.000, 0.667, 0.500},
{0.000, 1.000, 0.500},
{0.333, 0.000, 0.500},
{0.333, 0.333, 0.500},
{0.333, 0.667, 0.500},
{0.333, 1.000, 0.500},
{0.667, 0.000, 0.500},
{0.667, 0.333, 0.500},
{0.667, 0.667, 0.500},
{0.667, 1.000, 0.500},
{1.000, 0.000, 0.500},
{1.000, 0.333, 0.500},
{1.000, 0.667, 0.500},
{1.000, 1.000, 0.500},
{0.000, 0.333, 1.000},
{0.000, 0.667, 1.000},
{0.000, 1.000, 1.000},
{0.333, 0.000, 1.000},
{0.333, 0.333, 1.000},
{0.333, 0.667, 1.000},
{0.333, 1.000, 1.000},
{0.667, 0.000, 1.000},
{0.667, 0.333, 1.000},
{0.667, 0.667, 1.000},
{0.667, 1.000, 1.000},
{1.000, 0.000, 1.000},
{1.000, 0.333, 1.000},
{1.000, 0.667, 1.000},
{0.333, 0.000, 0.000},
{0.500, 0.000, 0.000},
{0.667, 0.000, 0.000},
{0.833, 0.000, 0.000},
{1.000, 0.000, 0.000},
{0.000, 0.167, 0.000},
{0.000, 0.333, 0.000},
{0.000, 0.500, 0.000},
{0.000, 0.667, 0.000},
{0.000, 0.833, 0.000},
{0.000, 1.000, 0.000},
{0.000, 0.000, 0.167},
{0.000, 0.000, 0.333},
{0.000, 0.000, 0.500},
{0.000, 0.000, 0.667},
{0.000, 0.000, 0.833},
{0.000, 0.000, 1.000},
{0.000, 0.000, 0.000},
{0.143, 0.143, 0.143},
{0.286, 0.286, 0.286},
{0.429, 0.429, 0.429},
{0.571, 0.571, 0.571},
{0.714, 0.714, 0.714},
{0.857, 0.857, 0.857},
{0.000, 0.447, 0.741},
{0.314, 0.717, 0.741},
{0.50, 0.5, 0}
};
void doInference(IExecutionContext& context, float* input, float* output, const int output_size, Size input_shape) {
const ICudaEngine& engine = context.getEngine();
// Pointers to input and output device buffers to pass to engine.
// Engine requires exactly IEngine::getNbBindings() number of buffers.
assert(engine.getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
assert(engine.getBindingDataType(inputIndex) == nvinfer1::DataType::kFLOAT);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
assert(engine.getBindingDataType(outputIndex) == nvinfer1::DataType::kFLOAT);
int mBatchSize = engine.getMaxBatchSize();
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], 3 * input_shape.height * input_shape.width * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], output_size*sizeof(float)));
// Create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[inputIndex], input, 3 * input_shape.height * input_shape.width * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(1, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], output_size * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
}
int main() {
cudaSetDevice(DEVICE);
// create a model using the API directly and serialize it to a stream
char *trtModelStream{nullptr};
size_t size{0};
const string engine_file_path = "D:\\lbq\\TensorRT-8.4.1.5\\bin\\bytetrack_x_cell_1.engine";//engine所在的绝对路径
ifstream file(engine_file_path, ios::binary);
if (file.good())
{
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
//CommandLineParser parser(argc, argv, keys);
//parser = CommandLineParser(argc, argv, keys);
//if (TRUE) {
// const string engine_file_path = "D:\\lbq\\TensorRT-8.4.1.5\\bin\\bytetrack_x.engine";
// ifstream file(engine_file_path, ios::binary);
// if (file.good()) {
// file.seekg(0, file.end);
// size = file.tellg();
// file.seekg(0, file.beg);
// trtModelStream = new char[size];
// assert(trtModelStream);
// file.read(trtModelStream, size);
// file.close();
// }
//} else {
// cerr << "arguments not right!" << endl;
// cerr << "run 'python3 tools/trt.py -f exps/example/mot/yolox_s_mix_det.py -c pretrained/bytetrack_s_mot17.pth.tar' to serialize model first!" << std::endl;
// cerr << "Then use the following command:" << endl;
// cerr << "cd demo/TensorRT/cpp/build" << endl;
// cerr << "./bytetrack ../../../../YOLOX_outputs/yolox_s_mix_det/model_trt.engine -i ../../../../videos/palace.mp4 // deserialize file and run inference" << std::endl;
// return -1;
//}
const string input_video_path = "D:\\lbq\\code\\2_tracking\\ByteTrack\\videos\\test.mp4";//测试视频
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
auto out_dims = engine->getBindingDimensions(1);
auto output_size = 1;
for(int j=0;j<out_dims.nbDims;j++) {
output_size *= out_dims.d[j];
}
static float* prob = new float[output_size];
VideoCapture cap(input_video_path);
if (!cap.isOpened())
return 0;
int img_w = cap.get(CAP_PROP_FRAME_WIDTH);
int img_h = cap.get(CAP_PROP_FRAME_HEIGHT);
int fps = cap.get(CAP_PROP_FPS);
long nFrame = static_cast<long>(cap.get(CAP_PROP_FRAME_COUNT));
cout << "Total frames: " << nFrame << endl;
VideoWriter writer("demo.mp4", VideoWriter::fourcc('m', 'p', '4', 'v'), fps, Size(img_w, img_h));
Mat img;
BYTETracker tracker(fps, 30);
int num_frames = 0;
int total_ms = 0;
while (true)
{
if(!cap.read(img))
break;
num_frames ++;
if (num_frames % 20 == 0)
{
cout << "Processing frame " << num_frames << " (" << num_frames * 1000000 / total_ms << " fps)" << endl;
}
if (img.empty())
break;
Mat pr_img = static_resize(img);
float* blob;
blob = blobFromImage(pr_img);
float scale = min(INPUT_W / (img.cols*1.0), INPUT_H / (img.rows*1.0));
// run inference
auto start = chrono::system_clock::now();
//doInference(*context, blob, prob, output_size, pr_img.size());
//const ICudaEngine& engine = context.getEngine();
// Pointers to input and output device buffers to pass to engine.
// Engine requires exactly IEngine::getNbBindings() number of buffers.
assert(engine->getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
assert(engine.getBindingDataType(inputIndex) == nvinfer1::DataType::kFLOAT);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(engine.getBindingDataType(outputIndex) == nvinfer1::DataType::kFLOAT);
// int mBatchSize = engine->getMaxBatchSize();
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], 3 * pr_img.size().height * pr_img.size().width * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], output_size * sizeof(float)));
// Create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
cout << pr_img.size() << endl;
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[inputIndex], blob, 3 * pr_img.size().height * pr_img.size().width * sizeof(float), cudaMemcpyHostToDevice, stream));
//context->enqueue(1, buffers, stream, nullptr);
context->enqueueV2(buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(prob, buffers[outputIndex], output_size * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
vector<Object> objects;
decode_outputs(prob, objects, scale, img_w, img_h);
vector<STrack> output_stracks = tracker.update(objects);
auto end = chrono::system_clock::now();
total_ms = total_ms + chrono::duration_cast<chrono::microseconds>(end - start).count();
for (int i = 0; i < output_stracks.size(); i++)
{
vector<float> tlwh = output_stracks[i].tlwh;
bool vertical = tlwh[2] / tlwh[3] > 1.6;
if (tlwh[2] * tlwh[3] > 20 && !vertical)
{
Scalar s = tracker.get_color(output_stracks[i].track_id);
putText(img, format("%d", output_stracks[i].track_id), Point(tlwh[0], tlwh[1] - 5),
0, 0.6, Scalar(0, 0, 255), 2, LINE_AA);
rectangle(img, Rect(tlwh[0], tlwh[1], tlwh[2], tlwh[3]), s, 2);
}
}
putText(img, format("frame: %d fps: %d num: %d", num_frames, num_frames * 1000000 / total_ms, output_stracks.size()),
Point(0, 30), 0, 0.6, Scalar(0, 0, 255), 2, LINE_AA);
cv::imshow("bytetrack_inference", img);
writer.write(img);
cout << "Current frame latency: " << chrono::duration_cast<chrono::microseconds>(end - start).count() / 1000 << "ms" << endl;
delete blob;
char c = waitKey(1);
if (c > 0)
{
break;
}
}
cap.release();
cout << "FPS: " << num_frames * 1000000 / total_ms << endl;
// destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
3.运行