StackedGAN详解与实现(采用tensorflow2.x实现)
StackedGAN详解与实现(采用tensorflow2.3实现)
-
- StackedGAN原理
- StackedGAN实现
-
- 编码器
- 对抗网络
-
- 鉴别器
- 生成器
- 模型构建
- 模型训练
- 效果展示
StackedGAN原理
StackedGAN提出了一种用于分解潜在表示以调节生成器输出的方法。与InfoGAN学习如何调节噪声以产生所需的输出,StackedGAN将GAN分解为GAN堆栈。每个GAN均以通常的区分生成器生成图片的方式进行独立训练,并带有自己的潜在编码。
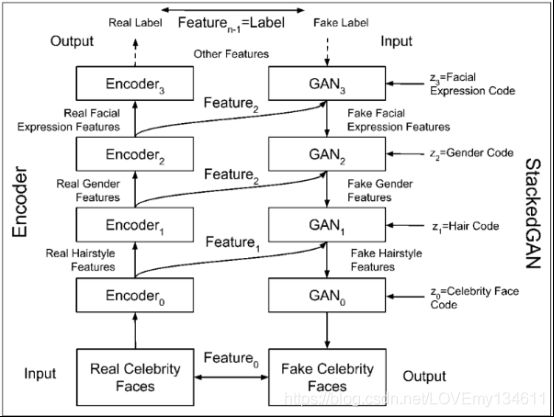 编码器网络由一堆简单的编码器组成,即 E n c o d e r i Encoder_i Encoderi,其中 i = 0 , . . . , n − 1 i = 0,...,n-1 i=0,...,n−1对应于 n n n个特征。每个编码器都提取某些面部特征。例如, E n c o d e r 0 Encoder_0 Encoder0可以是发型特征 F e a t u r e 1 Feature_1 Feature1的编码器。所有简单的编码器都有助于使整个编码器执行正确的预测。
编码器网络由一堆简单的编码器组成,即 E n c o d e r i Encoder_i Encoderi,其中 i = 0 , . . . , n − 1 i = 0,...,n-1 i=0,...,n−1对应于 n n n个特征。每个编码器都提取某些面部特征。例如, E n c o d e r 0 Encoder_0 Encoder0可以是发型特征 F e a t u r e 1 Feature_1 Feature1的编码器。所有简单的编码器都有助于使整个编码器执行正确的预测。
StackedGAN背后的想法是,如果想构建一个可以生成假名人面孔的GAN,应该简单地反转编码器。 StackedGAN由一堆更简单的GAN组成, G A N i GAN_i GANi,其中 i = 0 , . . . , n − 1 i = 0,...,n-1 i=0,...,n−1对应于 n n n个特征。每个 G A N i GAN_i GANi都会学习反转其相应编码器 E n c o d e r i Encoder_i Encoderi的过程。例如, G A N 0 GAN_0 GAN0从伪造的发型特征生成伪造的名人面孔,这与 E n c o d e r 0 Encoder_0 Encoder0的过程相反。
每个 G A N i GAN_i GANi使用一个潜编码 z i z_i zi,以调节其生成器输出。例如,潜编码 z 0 z_0 z0可以修改发型。GAN的堆栈也可以用作合成假名人面孔的对象,从而完成整个编码器的逆过程。每个 G A N i GAN_i GANi的潜编码 z i z_i zi可以用来更改假名人面孔的特定属性。
StackedGAN实现
StackedGAN的详细网络模型。以2个encoder-GAN堆栈为例。
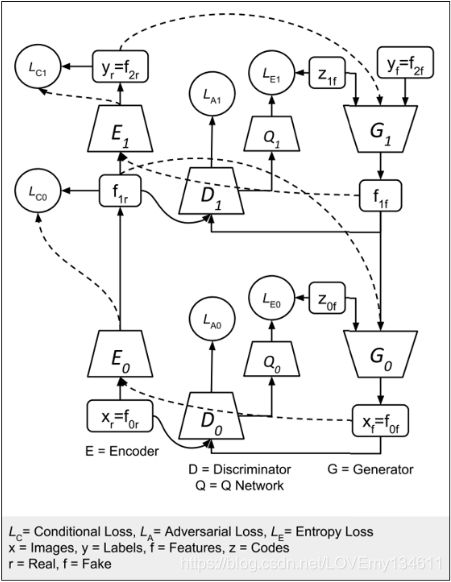 StackedGAN包括编码器和GAN的堆栈。 对编码器进行预训练以执行分类。 G e n e r a t o r 1 Generator_1 Generator1学习合成基于伪标签 y f y_{f} yf和潜编码 z 1 f z_{1f} z1f的特征 f 1 f f_{1f} f1f。 G e n e r a t o r 0 Generator_0 Generator0使用伪特征 f 1 f f_{1f} f1f和潜码 z 0 f z_{0f} z0f产生伪图像。
StackedGAN包括编码器和GAN的堆栈。 对编码器进行预训练以执行分类。 G e n e r a t o r 1 Generator_1 Generator1学习合成基于伪标签 y f y_{f} yf和潜编码 z 1 f z_{1f} z1f的特征 f 1 f f_{1f} f1f。 G e n e r a t o r 0 Generator_0 Generator0使用伪特征 f 1 f f_{1f} f1f和潜码 z 0 f z_{0f} z0f产生伪图像。
StackedGAN从编码器开始。它可能是训练后的分类器,可以预测正确的标签。中间特征向量 f 1 r f_{1r} f1r可用于GAN训练。对于MNIST,可以使用基于CNN的分类器。
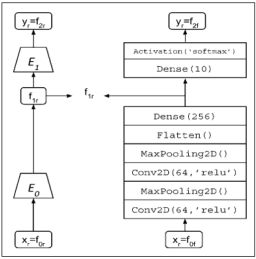 使用Dense层提取256-dim特征。 有两种输出模型, E n c o d e r 0 Encoder_0 Encoder0和 E n c o d e r 1 Encoder_1 Encoder1。 两者都将用于训练StackedGAN。
使用Dense层提取256-dim特征。 有两种输出模型, E n c o d e r 0 Encoder_0 Encoder0和 E n c o d e r 1 Encoder_1 Encoder1。 两者都将用于训练StackedGAN。
编码器
def build_encoder(inputs,num_labels=10,feature1_dim=256):
"""the Encoder Model sub networks
Two sub networks:
Encoder0: Image to feature1
Encoder1: feature1 to labels
#arguments
inputs (layers): x - images, feature1 - feature1 layer output
num_labels (int): number of class labels
feature1_dim (int): feature1 dimenstionality
#returns
enc0,enc1 (models):Description below
"""
kernel_size = 3
filters = 64
x,feature1 = inputs
# Encoder0 or enc0
y = keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
padding='same',
activation='relu')(x)
y = keras.layers.MaxPool2D()(y)
y = keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
padding='same',
activation='relu')(y)
y = keras.layers.MaxPooling2D()(y)
y = keras.layers.Flatten()(y)
feature1_output = keras.layers.Dense(feature1_dim,activation='relu')(y)
#Encoder0 or enc0: image (x or feature0) to feature1
enc0 = keras.Model(inputs=x,outputs=feature1_output,name='encoder0')
#Encoder1 or enc1
y = keras.layers.Dense(num_labels)(feature1)
labels = keras.layers.Activation('softmax')(y)
#Encoder1 or enc1: feature1 to class labels (feature2)
enc1 = keras.Model(inputs=feature1,outputs=labels,name='encoder1')
#return both enc0,enc1
return enc0,enc1
E n c o d e r 0 Encoder_0 Encoder0的输出 f 1 r f_{1r} f1r是希望 G e n e r a t o r 1 Generator_1 Generator1学习进行合成的256维特征向量。可用作 E n c o d e r 0 Encoder_0 Encoder0的辅助输出。训练整个编码器以对MNIST数字 x r x_r xr进行分类。 正确的标签 y r y_r yr由 E n c o d e r 1 Encoder_1 Encoder1预测。 在此过程中,将学习中间特征集 f 1 r f_1r f1r并将其用于 G e n e r a t o r 0 Generator_0 Generator0训练。 当GAN针对此编码器进行训练时,下标 r r r用于强调和区分真实数据与伪数据。
假设编码器输入 x r x_r xr,输出为中间特征 f 1 r f_{1r} f1r和标签 y r y_r yr,则每个GAN都会以通常的鉴别网络-对抗网络方式进行训练。
对抗网络
损失函数:
鉴别器
L i ( D ) = − E f i ∼ p d a t a l o g D ( f i ) − E f i + 1 ∼ p d a t a , z i l o g [ 1 − D ( G ( f i + 1 , z i ) ) ] \mathcal L_i^{(D)} = -\mathbb E_{f_i\sim p_{data}}logD(f_i)-\mathbb E_{f_{i+1}\sim p_{data},z_i}log[1 − D(G(f_{i+1},z_i))] Li(D)=−Efi∼pdatalogD(fi)−Efi+1∼pdata,zilog[1−D(G(fi+1,zi))]
生成器
L i ( G ) a d v = − E f i ∼ p d a t a , z i l o g D ( G ( f i + 1 , z i ) ) \mathcal L_i^{(G)adv} = -\mathbb E_{f_i\sim p_{data},z_i}logD(G(f_{i+1},z_i)) Li(G)adv=−Efi∼pdata,zilogD(G(fi+1,zi))
L i ( D ) c o n d = ∥ E i ( G ( f i + 1 , z i ) ) , f i ∥ 2 \mathcal L_i^{(D)cond} = \| \mathbb E_i(G(f_{i+1},z_i)),f_i \|_2 Li(D)cond=∥Ei(G(fi+1,zi)),fi∥2
L i ( D ) e n t = ∥ Q i ( G ( f i + 1 , z i ) ) , z i ∥ 2 \mathcal L_i^{(D)ent} = \| Q_i(G(f_{i+1},z_i)),z_i \|_2 Li(D)ent=∥Qi(G(fi+1,zi)),zi∥2
L i ( G ) = λ 1 L i ( G ) a d v + λ 2 L i ( D ) c o n d + λ 3 L i ( D ) e n t \mathcal L_i^{(G)} = \lambda_1 \mathcal L_i^{(G)adv}+\lambda_2 \mathcal L_i^{(D)cond} +\lambda_3 \mathcal L_i^{(D)ent} Li(G)=λ1Li(G)adv+λ2Li(D)cond+λ3Li(D)ent
条件损失函数 L i ( D ) c o n d \mathcal L_i^{(D)cond} Li(D)cond确保了在从输入噪声编码 z i z_i zi合成输出 f i f_i fi时,生成器不会忽略输入 f i + 1 f_{i+1} fi+1。 编码器 E n c o d e r i Encoder_i Encoderi必须能够通过反转 G e n e r a t o r i Generator_i Generatori的过程来恢复生成器输入。生成器输入和使用编码器恢复的输入之间的差通过欧几里德距离(均方误差(MSE))测量。
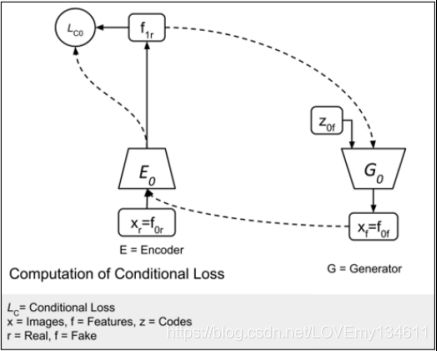 但是,条件损失函数引入了新问题。生成器忽略输入噪声编码 z i z_i zi,仅依赖于 f i + 1 f_{i+1} fi+1。 熵损失函数 L i ( D ) e n t \mathcal L_i^{(D)ent} Li(D)ent确保生成器不会忽略噪声编码 z i z_i zi。 Q网络从生成器的输出中恢复噪声矢量。恢复的噪声与输入噪声之间的差异也可以通过欧几里德距离(MSE)进行测量。
但是,条件损失函数引入了新问题。生成器忽略输入噪声编码 z i z_i zi,仅依赖于 f i + 1 f_{i+1} fi+1。 熵损失函数 L i ( D ) e n t \mathcal L_i^{(D)ent} Li(D)ent确保生成器不会忽略噪声编码 z i z_i zi。 Q网络从生成器的输出中恢复噪声矢量。恢复的噪声与输入噪声之间的差异也可以通过欧几里德距离(MSE)进行测量。

鉴别器
构建 D i s c r i m i n a t o r 0 Discriminator_0 Discriminator0和 D i s c r i m i n a t o r 1 Discriminator_1 Discriminator1的函数。 除特征向量输入 Z 0 Z_0 Z0和辅助网络 Q 0 Q_0 Q0之外,dis0鉴别器与GAN鉴别器类似。创建dis0:
def discriminator(inputs,activation='sigmoid',num_codes=None):
"""discriminator model
Arguments:
inputs (Layer): input layer of the discriminator
activation (string): name of output activation layer
num_labels (int): dimension of one-hot labels for ACGAN & InfoGAN
num_codes (int): num_codes-dim Q network as output
if StackedGAN or 2 Q netwoek if InfoGAN
Returns:
Model: Discriminator model
"""
kernel_size = 5
layer_filters = [32,64,128,256]
x = inputs
for filters in layer_filters:
if filters == layer_filters[-1]:
strides = 1
else:
strides = 2
x = keras.layers.LeakyReLU(0.2)(x)
x = keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = keras.layers.Flatten()(x)
outputs = keras.layers.Dense(1)(x)
if activation is not None:
print(activation)
outputs = keras.layers.Activation(activation)(outputs)
# StackedGAN Q0 output
# z0_recon is reconstruction of z0 normal distribution
z0_recon = keras.layers.Dense(num_codes)(x)
z0_recon = keras.layers.Activation('tanh',name='z0')(z0_recon)
outputs = [outputs,z0_recon]
return keras.Model(inputs,outputs,name='discriminator')
dis1鉴别器由三层MLP组成。 最后一层区分真实和伪。网络共享dis1的前两层。其第三层重建 z 1 z_1 z1。
def build_disciminator(inputs,z_dim=50):
"""Discriminator 1 model
将feature1分类为真实/伪图像,并恢复输入噪声或潜编码
#argumnets
inputs (layer): feature1
z_dim (int): noise dimensionality
#Returns
dis1 (Model): feature1 as real/fake and recovered latent code
"""
#input is 256-dim feature1
x = keras.layers.Dense(256,activation='relu')(inputs)
x = keras.layers.Dense(256,activation='relu')(x)
# first output is probality that feature1 is real
f1_source = keras.layers.Dense(1)(x)
f1_source = keras.layers.Activation('sigmoid',name='feature1_source')(f1_source)
#z1 reonstruction (Q1 network)
z1_recon = keras.layers.Dense(z_dim)(x)
z1_recon = keras.layers.Activation('tanh',name='z1')(z1_recon)
discriminator_outputs = [f1_source,z1_recon]
dis1 = keras.Model(inputs,discriminator_outputs,name='dis1')
return dis1
生成器
gen1生成器由带有标签和噪声编码 z 1 f z_{1f} z1f作为输入的三个密集层组成。 第三层生成伪造的特征 f 1 f f_{1f} f1f。
def build_generator(latent_codes,image_size,feature1_dim=256):
"""build generator model sub networks
Two sub networks:
class and noise to feature1
feature1 to image
#Argument
latent_codes (layers): dicrete code (labels), noise and feature1 features
image_size (int): target size of one side
feature1_dim (int): feature1 dimensionality
#Return
gen0,gen1 (models)
"""
#latent codes and network parameters
labels,z0,z1,feature1 = latent_codes
#image_resize = image_size // 4
#kernel_size = 5
#layer_filters = [128,64,32,1]
#gen1 inputs
inputs = [labels,z1] #10+50=60-dim
x = keras.layers.concatenate(inputs,axis=1)
x = keras.layers.Dense(512,activation='relu')(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Dense(512,activation='relu')(x)
x = keras.layers.BatchNormalization()(x)
fake_feature1 = keras.layers.Dense(feature1_dim,activation='relu')(x)
#gen1: classes and noise (feature2 + z1) to feature1
gen1 = keras.Model(inputs,fake_feature1,name='gen1')
#gen0: feature1 + z0 to feature0 (image)
gen0 = generator(feature1,image_size,codes=z0)
return gen0,gen1
gen0生成器类似于其他GAN生成器.
def generator(inputs,image_size,activation='sigmoid',codes=None):
"""generator model
Arguments:
inputs (layer): input layer of generator
image_size (int): Target size of one side
activation (string): name of output activation layer
labels (tensor): input labels
codes (list): 2-dim disentangled codes for infoGAN
returns:
model: generator model
"""
image_resize = image_size // 4
kernel_size = 5
layer_filters = [128,64,32,1]
## generator 0 of StackedGAN
inputs = [inputs,codes]
x = keras.layers.concatenate(inputs,axis=1)
x = keras.layers.Dense(image_resize*image_resize*layer_filters[0])(x)
x = keras.layers.Reshape((image_resize,image_resize,layer_filters[0]))(x)
for filters in layer_filters:
if filters > layer_filters[-2]:
strides = 2
else:
strides = 1
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Activation('relu')(x)
x = keras.layers.Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
if activation is not None:
x = keras.layers.Activation(activation)(x)
return keras.Model(inputs,x,name='generator')
模型构建
def build_and_train_models():
#build StackedGAN
#数据加载
(x_train,y_train),(x_test,y_test) = keras.datasets.mnist.load_data()
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1,image_size,image_size,1])
x_train = x_train.astype('float32') / 255.
x_test = np.reshape(x_test,[-1,image_size,image_size,1])
x_test = x_test.astype('float32') / 255.
num_labels = len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
#超参数
model_name = 'stackedGAN_mnist'
batch_size = 64
train_steps = 40000
lr = 2e-4
decay = 6e-8
input_shape = (image_size,image_size,1)
label_shape = (num_labels,)
z_dim = 50
z_shape = (z_dim,)
feature1_dim = 256
feature1_shape = (feature1_dim,)
#discriminator 0 and Q network 0 models
inputs = keras.layers.Input(shape=input_shape,name='discriminator0_input')
dis0 = discriminator(inputs,num_codes=z_dim)
optimizer = keras.optimizers.RMSprop(lr=lr,decay=decay)
# 损失函数:1)图像是真实的概率
# 2)MSE z0重建损失
loss = ['binary_crossentropy','mse']
loss_weights = [1.0,10.0]
dis0.compile(loss=loss,loss_weights=loss_weights,
optimizer=optimizer,
metrics=['accuracy'])
dis0.summary()
#discriminator 1 and Q network 1 models
input_shape = (feature1_dim,)
inputs = keras.layers.Input(shape=input_shape,name='discriminator1_input')
dis1 = build_disciminator(inputs,z_dim=z_dim)
# 损失函数: 1) feature1是真实的概率 (adversarial1 loss)
# 2) MSE z1 重建损失 (Q1 network loss or entropy1 loss)
loss = ['binary_crossentropy','mse']
loss_weights = [1.0,1.0]
dis1.compile(loss=loss,loss_weights=loss_weights,
optimizer=optimizer,
metrics=['acc'])
dis1.summary()
#generator models
feature1 = keras.layers.Input(shape=feature1_shape,name='featue1_input')
labels = keras.layers.Input(shape=label_shape,name='labels')
z1 = keras.layers.Input(shape=z_shape,name='z1_input')
z0 = keras.layers.Input(shape=z_shape,name='z0_input')
latent_codes = (labels,z0,z1,feature1)
gen0,gen1 = build_generator(latent_codes,image_size)
gen0.summary()
gen1.summary()
#encoder models
input_shape = (image_size,image_size,1)
inputs = keras.layers.Input(shape=input_shape,name='encoder_input')
enc0,enc1 = build_encoder((inputs,feature1),num_labels)
enc0.summary()
enc1.summary()
encoder = keras.Model(inputs,enc1(enc0(inputs)))
encoder.summary()
data = (x_train,y_train),(x_test,y_test)
#训练对抗网路前,需要已经训练完成的编码器网络
train_encoder(encoder,data,model_name=model_name)
#adversarial0 model = generator0 + discrimnator0 + encoder0
optimizer = keras.optimizers.RMSprop(lr=lr*0.5,decay=decay*0.5)
enc0.trainable = False
dis0.trainable = False
gen0_inputs = [feature1,z0]
gen0_outputs = gen0(gen0_inputs)
adv0_outputs = dis0(gen0_outputs) + [enc0(gen0_outputs)]
adv0 = keras.Model(gen0_inputs,adv0_outputs,name='adv0')
# 损失函数:1)feature1是真实的概率
# 2)Q network 0 损失
# 3)condition0 损失
loss = ['binary_crossentropy','mse','mse']
loss_weights = [1.0,10.0,1.0]
adv0.compile(loss=loss,
loss_weights=loss_weights,
optimizer=optimizer,
metrics=['acc'])
adv0.summary()
#adversarial1 model = generator1 + discrimnator1 + encoder1
enc1.trainable = False
dis1.trainable = False
gen1_inputs = [labels,z1]
gen1_outputs = gen1(gen1_inputs)
adv1_outputs = dis1(gen1_outputs) + [enc1(gen1_outputs)]
adv1 = keras.Model(gen1_inputs,adv1_outputs,name='adv1')
#损失函数:1)标签是真实的概率
#2)Q network 1 损失
#3)conditional1 损失
loss_weights = [1.0,1.0,1.0]
loss = ['binary_crossentropy','mse','categorical_crossentropy']
adv1.compile(loss=loss,
loss_weights=loss_weights,
optimizer=optimizer,
metrics=['acc'])
adv1.summary()
models = (enc0,enc1,gen0,gen1,dis0,dis1,adv0,adv1)
params = (batch_size,train_steps,num_labels,z_dim,model_name)
train(models,data,params)
模型训练
#训练对抗网路前,需要已经训练完成的编码器网络
def train_encoder(model,data,model_name='stackedgan_mnist',batch_size=64):
"""Train Encoder model
# Arguments
model (model): Encoder
data (tensor): train and test data
model_name (string): model name
batch_size (int): train batch size
"""
(x_train,y_train),(x_test,y_test) = data
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['acc'])
model.fit(x_train,y_train,validation_data=(x_test,y_test),
epochs=20,batch_size=batch_size)
model.save(model_name + '-encoder.h5')
score = model.evaluate(x_test,y_test,batch_size=batch_size,verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * score[1]))
训练顺序为:
1. D i s c r i m i n a t o r 1 Discriminator_1 Discriminator1和 Q 1 Q_1 Q1
2. D i s c r i m i n a t o r 0 Discriminator_0 Discriminator0和 Q 0 Q_0 Q0
3. A d v e r s a r i a l 1 Adversarial_1 Adversarial1
4. A d v e r s a r i a l 0 Adversarial_0 Adversarial0
def train(models,data,params):
"""train networks
Arguments
models (models): encoder,generator,discriminator,adversarial
data (tuple): x_train,y_train
params (tuple): parameters
"""
enc0,enc1,gen0,gen1,dis0,dis1,adv0,adv1 = models
batch_size,train_steps,num_labels,z_dim,model_name = params
(x_train,y_train),_ = data
save_interval = 500
z0 = np.random.normal(scale=0.5,size=[16,z_dim])
z1 = np.random.normal(scale=0.5,size=[16,z_dim])
noise_class = np.eye(num_labels)[np.arange(0,16) % num_labels]
noise_params = [noise_class,z0,z1]
train_size = x_train.shape[0]
print(model_name,'labels for generated images: ',np.argmax(noise_class,axis=1))
for i in range(train_steps):
rand_indexes = np.random.randint(0,train_size,size=batch_size)
real_images = x_train[rand_indexes]
# real feature1 from encoder0 output
real_feature1 = enc0.predict(real_images)
# generate random 50-dim z1 latent code
real_z1 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
#real labels
real_labels = y_train[rand_indexes]
#generate fake feature1 using generator1 from real labels and 50-dim z1 latent code
fake_z1 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
fake_feature1 = gen1.predict([real_labels,fake_z1])
#real + fake data
feature1 = np.concatenate((real_feature1,fake_feature1))
z1 = np.concatenate((real_z1,fake_z1))
#label 1st half as real and 2nd half as fake
y = np.ones([2*batch_size,1])
y[batch_size:,:] = 0
#train discriminator1 to classify feature1 as real/fake and recover
metrics = dis1.train_on_batch(feature1,[y,z1])
log = "%d: [dis1_loss: %f]" % (i, metrics[0])
#train the discriminator0 for 1 batch
#1 batch of reanl and fake images
real_z0 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
fake_z0 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
fake_images = gen0.predict([real_feature1,fake_z0])
#real + fake data
x = np.concatenate((real_images,fake_images))
z0 = np.concatenate((real_z0,fake_z0))
#train discriminator0 to classify image as real/fake and recover latent code (z0)
metrics = dis0.train_on_batch(x,[y,z0])
log = "%s [dis0_loss: %f]" % (log, metrics[0])
# 对抗训练
# 生成fake z1,labels
fake_z1 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
#input to generator1 is sampling fr real labels and 50-dim z1 latent code
gen1_inputs = [real_labels,fake_z1]
y = np.ones([batch_size,1])
#train generator1
metrics = adv1.train_on_batch(gen1_inputs,[y,fake_z1,real_labels])
fmt = "%s [adv1_loss: %f, enc1_acc: %f]"
log = fmt % (log, metrics[0], metrics[6])
# input to generator0 is real feature1 and 50-dim z0 latent code
fake_z0 = np.random.normal(scale=0.5,size=[batch_size,z_dim])
gen0_inputs = [real_feature1,fake_z0]
#train generator0
metrics = adv0.train_on_batch(gen0_inputs,[y,fake_z0,real_feature1])
log = "%s [adv0_loss: %f]" % (log, metrics[0])
print(log)
if (i + 1) % save_interval == 0:
genenators = (gen0,gen1)
plot_images(genenators,noise_params=noise_params,
show=False,
step=(i+1),
model_name=model_name)
gen1.save(model_name + '-gen1.h5')
gen0.save(model_name + '-gen0.h5')
效果展示
#绘制生成图片
def plot_images(generators,noise_params,show=False,step=0,model_name='gan'):
"""generator fake images and plot
Arguments
generators (model): gen0 and gen1 models for fake images generation
noise_params (list): noise parameters (label,z0 and z1 codes)
show (bool): whether to show plot or not
step (int): Appended tor filename of the save images
model_name (string): model name
"""
gen0,gen1 = generators
noise_class,z0,z1 = noise_params
os.makedirs(model_name,exist_ok=True)
filename = os.path.join(model_name,'%05d.png' % step)
feature1 = gen1.predict([noise_class,z1])
images = gen0.predict([feature1,z0])
print(model_name,'labels for generated images: ',np.argmax(noise_class,axis=1))
plt.figure(figsize=(2.2,2.2))
num_images = images.shape[0]
image_size = images.shape[1]
rows = int(math.sqrt(noise_class.shape[0]))
for i in range(num_images):
plt.subplot(rows,rows,i + 1)
image = np.reshape(images[i],[image_size,image_size])
plt.imshow(image,cmap='gray')
plt.axis('off')
plt.savefig(filename)
if show:
plt.show()
else:
plt.close('all')
if __name__ == '__main__:
build_and_train_models()
step=10000

修改书写角度的分离编码
