深入tensorflow1.x
文章目录
- 一、tensorflow 安装
- 二、核心概念
-
- 2.1 计算图
- 2.2 Tensor
- 2.3 会话Session
- 2.4 两层神经网络
- 三、深层神经网络
-
- 1. 优化方法
- 2. 指数衰减的学习率
- 3. L 1 L 2 L_1 L_2 L1L2正则化
- 4. 指数加权平均(指数滑动平均)
-
- 4.1 原理
- 4.2 偏差修正
- 四、mnist数据集处理
-
- 变量的管理
- 模型持久化
-
- save model to file
- restore model from saved file
- 五、卷积神经网络
-
- 1. 常用图像识别数据集
- 2. 卷积神经网络
- 六、循环神经网络
-
- RNN
- LSTM
- GUR
- 双向RNN
- DeepRNN
- 循环神经网络的dropout
- 七、自然语言处理
-
- 1. 语言模型的评价规则
- PTB数据预处理
- embedding层
- softmax层
- 以PTB数据集的语言模型
-
- dynamic_rnn
-
- 单层单向lstm
- 单层双向lstm
- 单步多层LSTM
- 一次性执行多步call:dynamic_rnn
- seq2seq模型
- Attention机制
目前所有的算法是基于1.12版本的tensorflow的实现,所以有必要学习一下1.x版本的tensorflow。
一、tensorflow 安装
基于tensorflow 1.4及以上
tensorflow的两个重要的依赖包:
- protocol buffer:谷歌开发的结构化数据处理工具,例如json,xml等。
- 主要的功能是把结构化的数据序列化进行网络传输或存储,然后把序列化的数据再反序列化为结构化数据。protocol buffer 需要定义数据的schema,利用schema来还原数据。使用 - protocol buffer序列化的数据比xml小3到10倍,反序列化时也快20到100倍。
- tensorflow系统中的数据基本上都使用protocol buffer来组织的,分布式的tensorflow的通信协议也gRPC也是以protocol buffer为基础的。
- bazel:谷歌开源的自动化构建工具,谷歌内部的绝大部分应用都是通过bazel构建的。功能类似于Maven等。
可以使用pip安装、docker安装及源码编译安装。
mac使用pip安装1.12.0版本的:
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.12.0-py3-none-any.whl
二、核心概念
- 计算模型
- 数据模型
- 运行模型
2.1 计算图
Tensorflow计算的过程有两个阶段:首先是定义计算,定义的计算是作为计算图上的一个节点。在Tensorflow程序中,会维护自动维护一个计算图,可以通过tf.get_default_graph函数来获取默认的计算图。除了使用默认的计算图,Tensorflow还支持tf.Graph()来创建新的计算图。在不同的计算图中的张量和计算是不可以共享的。
# coding:utf-8
import tensorflow as tf
# 不同的计算图中的计算与张量是相互隔离的
# 创建一个计算图
g1 = tf.Graph()
# 在计算图中定义一个张量v
with g1.as_default():
# 1.12版本把shape在initializer外边定义了
v = tf.get_variable("v", initializer=tf.zeros_initializer(), shape=[1])
# 创建一个新的计算图
g2 = tf.Graph()
with g2.as_default():
v1 = tf.get_variable("v", initializer=tf.ones_initializer(), shape=[1])
# 获取并输出g1中的张量v,结果是[0.]
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
# 获取并输出g2中的张量v,结果是[1.]
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
还可以指定计算图的设备,上一个计算两个常量的计算图:
with g.device("\gpu:0"):
result = a + b
计算图另一个作用是管理Tensorflow中的资源,把资源放到collection中,可以使用tf.add_to_collection函数来把资源放到collection,tf.get_collection函数来获取collection中所有的资源。放入到collection中的可以是常量、变量或队列等资源。
为了管理方便,Tensorflow也自动维护了一些常用的集合。
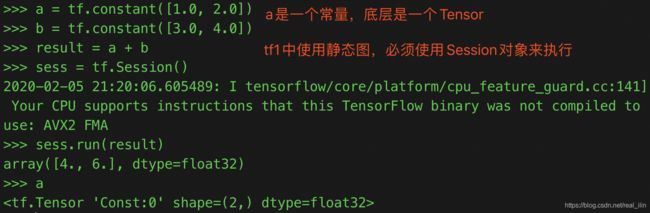
2.2 Tensor
Tensorflow中的张量Tensor是数据管理的模型,有零阶张量(也就是标量),一阶张量可以理解为一维数组,n阶张量可以理解为n维数组。Tensorflow中的张量并不会保存数据,只保存计算过程,是计算结果的引用。有三个属性:name,shape和dtype。
- name是node: src_output形式,node代表结点,src_output表示这个结点的第几个输出值。下面的例子result是来自add结点的第1个输出。
- shape是张量的维度,是一个一维数组,这个数组的长度是2.
- dtype是数据的type,浮点类型默认使用float32,整数默认是使用int32,使用默认类型容易出现类型不匹配的情况,所以一般会指定数据类型。

张量的使用:
- 是整个计算过程的引用,可以存储中间结果;
- 可以用来计算真实的数值;
2.3 会话Session
Session拥有并且管理Tensorflow运行过程中的所有的资源。可以显示的打开Session,并关闭Session。另一种方法是使用上下文管理器with来管理。
当一个会话声明后,可以使用指定session的方法来计算一个Tensor
sess = tf.Session()
result.eval(session=sess)
2.4 两层神经网络
一个两层的神经网络:

这个一个由输入层,隐藏层、输出层组成的典型的两层神经网络。使用向量的形式:
参数W的维度是 i n p u t × o u t p u t input \times output input×output。x的组织形式与Andrew ng的课中的组织形式是不同的,一行代表一个样本,一个样本有两个特征,所以x的维度是一行二列。
a = tf.matmul(x, W1)
y = tf.matmul(a, W2)
# 声明一个二行三列的变量,使用正态分布的对变量初始化
weight = tf.Variable(tf.random_normal([2,3], stddev=2))


两层神经网络的前向传播:
# coding=utf-8
import tensorflow as tf
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 这里x是一行两列的矩阵
x = tf.constant([[0.7, 0.9]])
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
with tf.Session() as sess:
# 对变量执行初始化
# sess.run(w1.initializer)
# sess.run(w2.initializer)
# 下面是对所有的变量进行初始化,而不是对每个变量单独执行
tf.global_variables_initializer().run()
print(sess.run(y))
可以通过tf.global_variables()来获取计算图上的所有变量,对持久化计算图的运行状态有帮助。
为什么要用placeholder?
训练一个神经网络需要进行很多轮的迭代,如果每次使用常量时,则会生成百万个的节点,占用很多的资源。而placeholder是占位的意思,先把计算图上位置占住,当用session计算的时候再把数据值传入。
# coding:utf-8
import warnings
warnings.filterwarnings('ignore')
import tensorflow as tf
import numpy as np
from numpy.random import RandomState
# 生成训练数据
datasize = 128
# 定义批大小
batch_size = 8
rdm = RandomState(1)
X = rdm.random([datasize, 2])
print(X.shape)
Y = np.array([[int(x1 + x2 > 1)] for (x1, x2) in X])
print(Y.shape)
# 定义placeholder
x = tf.placeholder(dtype=tf.float32, shape=(None, 2), name='x-input')
y_ = tf.placeholder(dtype=tf.float32, shape=(None, 1), name='y-input')
# 定义参数
w1 = tf.Variable(initial_value=tf.random_normal(shape=(2, 3), stddev=1, seed=1))
w2 = tf.Variable(initial_value=tf.random_normal(shape=(3, 1), stddev=1, seed=1))
# 定义模型
a = tf.matmul(x, w1)
y_pred = tf.sigmoid(tf.matmul(a, w2))
# 定义loss
cross_entropy = -tf.reduce_mean(
y_ * tf.log(tf.clip_by_value(y_pred, 1e-10, 1.0)) + (1 - y_) * tf.log(tf.clip_by_value(1 - y_pred, 1e-10, 1.0)))
# 向后传播
learning_rate = 0.001
train_step = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cross_entropy)
# 开始迭代
STEMPS = 5000
with tf.Session() as sess:
# 在迭代之前初始化所有的数据
tf.global_variables_initializer().run()
print('before loop w1:{}'.format(sess.run(w1)))
print('before loop w2:{}'.format(sess.run(w2)))
for i in range(STEMPS):
start = i * batch_size % datasize
# 当datasize无法整除batch_size时,end只能取到datasize的位置
end = min(start + batch_size, datasize)
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
# 计算在全部训练数据上的cross entropy
print(f'After loop {i}, cross entropy loss is:{sess.run(cross_entropy, feed_dict={x: X, y_: Y})}')
print('after loop w1:{}'.format(sess.run(w1)))
print('after loop w2:{}'.format(sess.run(w2)))
三、深层神经网络
非线性变换,激活函数:
# coding:utf-8
import tensorflow as tf
a = tf.nn.relu(tf.matmul(x, w1) + biase1)
y = tf.nn.relu(tf.matmul(a, w2) + biase2)
tf.reduce_mean()函数:
print(tf.reduce_mean([[1.0,2.0,3.0],[4.0,5.0,6.0]]))
# 结果是3.5,只是一个数字
1. 优化方法
- batch处理
- 指数衰减的学习率(learning_rate)
- 过拟合处理
- 滑动平均模型:会将每一轮迭代的模型综合起来,从而使得最终得到的模型更加健壮
2. 指数衰减的学习率
![]()
- 一开始有一个基础学习率,在这个基础上衰减,比如0.01
- decay_steps:迭代多少步就衰减一次,一般是num_examples/ batch_size,比如有55000个样本,batch_size为100,则迭代550步就衰减一次。
- global_step:代表此时的迭代轮数,比如1100轮,则global_step / decay_steps =2
- decay_rate:衰减率,比如0.9
则迭代到1100轮的时候的learning_rate是多少?
0.01 × 0. 9 1100 550 = 0.0081 0.01 \times 0.9 ^ {\frac{1100}{550}} = 0.0081 0.01×0.95501100=0.0081
所以是指数衰减的,在Tensorflow中用exponential_decay表示,exponential是指数的意思。
# Example: decay every 100000 steps with a base of 0.96
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
100000, 0.96, staircase=True)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
3. L 1 L 2 L_1 L_2 L1L2正则化
# 在tf.contib.layers模块中
# coding:utf-8
import warnings
warnings.filterwarnings('ignore')
import tensorflow as tf
weights = tf.constant([[1.0, -2.0], [3.0, -4.0]])
with tf.Session() as sess:
# (|1.0| + |-2.0| + |3.0| + |-4.0|) * 0.5 = 5.0
# 参数0.5是正则化项的系数
print(sess.run(tf.contrib.layers.l1_regularizer(.5)(weights)))
# ((1.0)^2 + (-2.0)^2 + 3.0^2 + (-4.0)^2) * 0.5 / 2 = 7.5
print(sess.run(tf.contrib.layers.l2_regularizer(0.5)(weights)))
4. 指数加权平均(指数滑动平均)
4.1 原理
在创建滑动平均模型后,滑动平均模型会对每一个变量维护一个影子变量(shadow variable),影子变量的初始值为相应变量的初始值,每当变量更新时,影子变量的值会更新为:
shadow_variable = decay * shadow_variable + (1-decay) * variable
shadow_variable为 影子变量,variable为待更新的变量,decay为衰减率,衰减率越大模型越稳定,因为从上实在可以看出,衰减率越大,影子变量受变量更新的影响越小。在实际应用中,decay一般会设置成非常接近1的数(如0.999或0.9999)。
[注意!变量的影子变量和变量的滑动平均值是一样的!]
滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大。
而滑动平均为什么会在测试中被使用,来使用模型的健壮性更强呢?
滑动平均可以使模型在测试数据上更健壮(robust)。“采用随机梯度下降算法训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。”
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;
设decay=0.999,一个更直观的理解,在最后的1000次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的1000次抖动进行了平均,这样得到的权重会更加robust。在整个训练过程中影子变量并不会对实际需要训练的变量产生影响啊,后面持久化的变量也不是影子变量。 在训练过程中,为参数维护更新一个影子变量,这样影子变量会停留在最终参数的周围保持稳定。 在测试阶段,使用影子变量代替参数,进行测试。
4.2 偏差修正
指数加权平均值通常都需要偏差修正,TensorFlow中提供的ExponentialMovingAverage()函数也带有偏差修正。
为什么叫做“滑动平均”?
实际上当前计算得到的shadow_variable约等于前 1 1 − d e c a y \frac{1}{1- decay} 1−decay1个的平均值。比如decay=0.98,1/(1-0.98) = 50,当前的为平均的前50个的平均值。
注意一点:当decay非常大,接近1时,计算的shadow_variable是取决于上一个的值,当前轮的weight影响比较小。
在前期的时候,weight值变化比较大时,如果decay值非常接近1,如0.999,平均值就会滞后。所以引入num_updates变量:
d e c a y = { d e c a y , 1 + n u m _ u p d a t e s 10 + n u m _ u p d a t e s } decay = \{ decay , \frac{1+ num\_updates }{10 + num\_updates}\} decay={decay,10+num_updates1+num_updates}
在前期的时候,decay比较小,以减少上一个shadow_variable的影响。
# 在所有的变量上应用滑动平均模型
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECYA, global_step)
average_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, average_op]):
train_op = tf.no_op('train')
四、mnist数据集处理
手写数字识别数据集一共有60000万图片,tensorflow分为了训练集55000张,验证集5000张,测试集10000张。每张图片的维度是28x28=784,每个像素点的值是[0,1]之间的数。标签值是已经经过one hot处理的,是一个10维的数组,如果是某个数字则为1。其实是一个多分类问题。
# coding:utf-8
import warnings
warnings.filterwarnings('ignore')
from tensorflow.examples.tutorials.mnist import input_data
from os.path import dirname, abspath
import os
workspace_path = dirname(dirname(dirname(abspath(__file__))))
mnist = input_data.read_data_sets(os.path.join(workspace_path, 'tensor_flow', 'google_tf', 'data'), one_hot=True)
# Training data 55000
print('Training data size:{}'.format(mnist.train.num_examples))
# Validation data size: 5000
print('Validation data size:{}'.format(mnist.validation.num_examples))
# Test data size: 10000
print('Test data size:{}'.format(mnist.test.num_examples))
# [0, 0, 0.98,...] 28x28=784维的数组
# print('Train data: {}'.format(mnist.train.images[0]))
# 训练数据的label是一个10维数组,[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
print('Train label:{}'.format(mnist.train.labels[0]))
batch_size = 100
xs, ys = mnist.train.next_batch(batch_size)
# X shape:(100, 784)
print('X shape:{}'.format(xs.shape))
# y shape:(100, 10)
print('y shape:{}'.format(ys.shape))
mnist数据集上的两层神经网络:
# coding:utf-8
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import numpy as np
cwd = os.getcwd()
INPUT_NODE = 28 * 28
OUTPUT_NODE = 10
LAYER1_NODE = 500
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
# 正则化项系数
REGULARIZATION_RATE = 0.0001
# 总的训练次数
TRANING_STEPS = 30000
# 滑动平均衰减系数
AVERAGE_MOVING_DECAY = 0.99
def inference(input_tensor, avg_class, weight1, bias1, weight2, bias2):
"""
设置一个可以加入所有参数的添加一层神经网络的函数,
:param input_tensor:
:param avg_class:
:param weight1:
:param bias1:
:param weight2:
:param bias2:
:return: 最后的预测值
"""
if avg_class is None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weight1) + bias1)
return tf.matmul(layer1, weight2) + bias2
else:
# 首先计算出变量的滑动平均值,再计算这一层的值,这里的平均值是如何计算的?
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weight1)) +
avg_class.average(bias1))
return tf.matmul(layer1, avg_class.average(weight2)) + avg_class.average(bias2)
def train(mnist):
x = tf.placeholder(shape=[None, INPUT_NODE], name='x-input', dtype=tf.float32)
y_ = tf.placeholder(shape=[None, OUTPUT_NODE], name='y-input', dtype=tf.float32)
# 生成隐藏层参数
weight1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
bias1 = tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[LAYER1_NODE]))
weight2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
bias2 = tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[OUTPUT_NODE]))
# 预测值
y = inference(x, None, weight1, bias1, weight2, bias2)
# global_step 代表训练轮数的变量,一般是trainable=False,不用计算滑动平均值
global_step = tf.Variable(0, trainable=False)
# 给定平均滑动衰减率和训练轮数,初始化平均滑动类。可以在前期加快训练的速度,它是如何加快速度的?
average_class = tf.train.ExponentialMovingAverage(AVERAGE_MOVING_DECAY, global_step)
# 在所有的变量上使用滑动平均,tf.trainable_variable是返回所有的trainable的变量
variable_average_op = average_class.apply(tf.trainable_variables())
average_y = inference(x, average_class, weight1, bias1, weight2, bias2)
# 计算交叉熵, 使用sparse_softmax_cross_entropy_with_logits
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 计算一个批的平均交叉熵
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算L2正则化
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 正则化只能W进行,一般不对bias正则化
regularization = regularizer(weight1) + regularizer(weight2)
# 计算总的损失 交叉熵损失 + 正则化项
loss = cross_entropy + regularization
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(learning_rate=LEARNING_RATE_BASE,
global_step=global_step,
decay_steps=mnist.train.num_examples / BATCH_SIZE, #
decay_rate=LEARNING_RATE_DECAY)
# 使用optimizer来优化损失 GradientDescentOptimizer
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss=loss,
global_step=global_step)
# 在训练神经网络模型时,每过一篇数据,既要通过反向传播来更新神经网络中的参数,又要更新每一个参数的滑动平均值。
# 为了同时完成两个操作,Tensorflow提供了group机制和control_dependencies机制
with tf.control_dependencies([train_step, variable_average_op]):
train_ops = tf.no_op(name='train')
# 计算滑动平均模型的准确率
correct_predict = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 准备验证集和测试集
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
print(f'Validate set shape:{np.array(mnist.validation.labels).shape}')
for i in range(TRANING_STEPS):
if i % 1000 == 0:
validate_accuracy = sess.run(accuracy, feed_dict=validate_feed)
print(f'After {i} training steps, validation accuracy is: {validate_accuracy}')
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_ops, feed_dict={x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print(f'After {TRANING_STEPS} training steps, test accuracy is: {test_acc}')
def main(argv=None):
print(cwd)
mnist = input_data.read_data_sets(os.path.join(cwd, 'data'), one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
变量的管理
# coding: utf-8
import tensorflow as tf
# 创建变量的两种方式:在创建变量的形式上来看,这两种方式是相同的
# 两者最大的区别是指定变量名的参数,tf.get_variable()是位置参数,而tf.Variable()是默认参数
# 第一种方式是创建一个变量名为v1的变量,如果已经有同名的参数就会报错,而创建失败。
v1 = tf.get_variable('v1', shape=[1], dtype=tf.float32, initializer=tf.constant_initializer(1.0))
v2 = tf.Variable(tf.constant(1.0, shape=[1]), name='v2')
with tf.Session() as sess:
tf.global_variables_initializer().run()
print('--->v1:', sess.run(v1))
print('--->v2:', sess.run(v2))
# TODO
with tf.variable_scope('foo', reuse=True)
get_variable也可以以numpy数据为initializer创建变量。
token_ebms = np.float32(np.random.randn(1000, 100))
print(token_ebms[0])
emb_tables = tf.get_variable('embeddings', initializer=token_ebms, dtype=tf.float32)
with tf.Session() as sess:
tf.global_variables_initializer().run()
emb_tables_val = sess.run(emb_tables)
print(emb_tables_val)
print(type(emb_tables_val))
TensorFlow中的变量一般就是模型的参数,当模型比较复杂时共享变量会变的非常复杂。官网给了一个例子,是当创建两层卷积的过滤器时,每输入一次图片就需要重新创建一次过滤器对应的变量,但是我们希望所有的图片共享这个变量,一共有四个变量,conv1_weights, conv1_biases, conv2_weights, conv2_biases。一般的做法是将这些变量设置为全局变量,这就打破了封装性。还有一种方法是保证封装性的方式是将模型封装成类。
不过,TF提供了Varible Scope这种机制来共享变量,这个机制主要涉及两个函数:
tf.get_variable(<name>, <shape>, <initializer>):# 创建或返回给定名称的变量
tf.variable_scope():# 管理传给get_varible()的变量名称的作用域,创建一个scope
详细介绍tf.get_varible()和tf.varible_scope()
https://www.cnblogs.com/MY0213/p/9208503.html
- tf.get_variable_scope().reuse==True的时候,tf.get_variable()就不是创建变量了,而是从作用域中获取已经创建的变量。否则会报错。
- 当前作用域的名字可以通过tf.get_variable_scope()来获取,并且reuse属性可以通过reuse_variables来设置。
- with tf.variable_scope(),其实就是给变量加上一个作用域,也就是同名的变量如果在不同的作用域中名字是可以相同的。
- 作用域可以相互嵌套,其实就是在变量上加上一个前缀;
- 作用域中的resuse默认是False,调用函数reuse_variables()可设置为True,一旦设置为True,就不能返回到False,并且该作用域的子空间reuse都是True。如果不想重用变量,那么可以退回到上层作用域,相当于exit当前作用域.
- 一个作用域可以作为另一个新的作用域的参数
- 不管作用域如何嵌套,当使用with tf.variable_scope()打开一个已经存在的作用域时,就会跳转到这个作用域。

tf.variable_scope可以控制tf.get_variable的函数语义。在tf.variable中,
- reuse = True时,在variable_scope中所有的get_variable是根据变量名来获取已经存在的变量,如果变量不存在则报错。实际上,如果resue=True则无法创建变量,只是获取已经存在的变量。
- reuse = False 或者 reuse=None,则在variable_scope中get_variable是创建一个新的变量,如果名字已经存在则报错。只能创建,无法获取已经创建好的变量。
模型持久化
save model to file
# coding:utf-8
import warnings
import os
warnings.filterwarnings('ignore', category=FutureWarning)
import tensorflow as tf
cwd = os.getcwd()
v1 = tf.Variable(tf.constant(1.0, shape=[1], name='v1'))
v2 = tf.Variable(tf.constant(2.0, shape=[1], name='v2'))
result = v1 + v2
saver = tf.train.Saver()
model_save_path = os.path.join(cwd, 'model', 'add_model.ckpt')
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(result))
saver.save(sess, model_save_path)
以上代码会把模型保存到model目录下,虽然指定了保存的名字,但是仍然会有三个文件
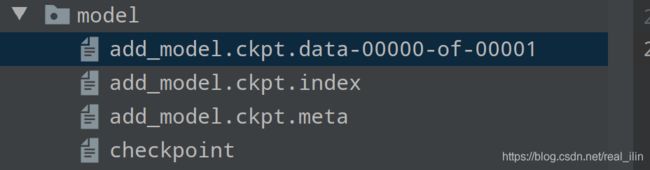
Tensorflow把计算图的结构与参数是分开保存的,其中:
- add_model.ckpt.meta:保存了计算图的结构;
- add_model.ckpt.index和add_model.ckpt.data-00000-of-00001保存了计算图上所有的变量的取值;
- checkpoint:不同文件对应的位置;
restore model from saved file
# coding:utf-8
import tensorflow as tf
import os
cwd = os.getcwd()
v1 = tf.Variable(tf.constant(1.0, shape=[1], name='v1'))
v2 = tf.Variable(tf.constant(2.0, shape=[1], name='v2'))
result = v1 + v2
saver = tf.train.Saver()
model_save_path = os.path.join(cwd, 'model', 'add_model.ckpt')
with tf.Session() as sess:
model = saver.restore(sess, model_save_path)
print(sess.run(result))
loss为Nan的情况:
https://blog.csdn.net/princexiexiaofeng/article/details/79975964
learning_rate太大,出现loss为Nan的情况,减小到原来的1/10再试验。
优化之后的代码:
mnist_inference.py
# -*- coding:utf-8 -*-
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
import tensorflow as tf
# 定义整个网络的前向传播,即神经网络的框架
INPUT_NODE = 28 * 28
HIDDEN_NODE = 500
OUTPUT_NODE = 10
def get_weight_variable(shape, regularizer):
"""
创建一个variable, 在训练时,会创建这些变量,在测试时会通过保存的模型加载这些变量
:param shape:
:param regularizer:
:return:
"""
# weight的stddev=0.1 否则会很大,如果此时learning_rate比较小的话,loss很大
weight = tf.get_variable('weight', shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
# 如果regularizer不为None时,则需要将weight正则化,放到collection中
if regularizer:
tf.add_to_collection('losses', regularizer(weight))
return weight
def inference(input_tensor, regularizer):
"""
定义了两层神经网络
:param input_tensor:
:param regularizer:
:return:
"""
with tf.variable_scope('layer1'): # 用这个variable_scope是为了调用weight时防止名字相同而报错
weight = get_weight_variable([INPUT_NODE, HIDDEN_NODE], regularizer)
# bias是一维的可以直接相加么, 一个矩阵和一个行向量相加,矩阵的列与行向量的维度是一样的
bias = tf.get_variable('bias', [HIDDEN_NODE], initializer=tf.constant_initializer(0.0))
layer1 = tf.matmul(input_tensor, weight) + bias
with tf.variable_scope('layer2'):
weight = get_weight_variable([HIDDEN_NODE, OUTPUT_NODE], regularizer)
bias = tf.get_variable('bias', [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weight) + bias
return layer2
mnist_train.py
# -*- coding:utf-8 -*-
import sys
from tensor_flow import workspace_path
import os
sys.path.append(workspace_path)
from tensor_flow.google_tf.mnist_nn_best import mnist_inference
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
BATCH_SIZE = 100
# 学习率要变小,0.8->0.001
LEARNING_RATE_BASE = 0.001
LEARNING_DECAY = 0.99
MOVING_AVERAGE_DECYA = 0.9
REGULARIZER_RATE = 0.0001
TRAINING_STEPS = 30000
MODEL_SAVE_PATH = os.path.join(workspace_path, 'tensor_flow/google_tf/mnist_nn_best', 'model')
MODEL_SAVE_NAME = 'mninst_model'
def train(mnist):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='input_data')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='output_data')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZER_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(learning_rate=LEARNING_RATE_BASE,
global_step=global_step,
decay_steps=mnist.train.num_examples / BATCH_SIZE,
decay_rate=LEARNING_DECAY)
cross_entropy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy_loss)
# 从名字为losses的collection中拿出所有的weight的正则化项,加到交叉熵损失中,作为总的损失
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 梯度下降的方法,根据loss作反向传播
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step)
# 滑动平均操作
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECYA, global_step)
average_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, average_op]):
train_op = tf.no_op('train')
# 保存模型的saver
saver = tf.train.Saver()
# 开始迭代训练
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, cross_mean_value, step = sess.run([train_op, loss, cross_entropy_mean, global_step],
feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
# 打印一下训练过程的数据
print(
f'After {i} training step, loss with regularization value: {loss_value}, cross entropy loss: {cross_mean_value},step: {step}')
# 这里为什么传入的是global_step?
if not os.path.exists(MODEL_SAVE_PATH):
os.mkdir(MODEL_SAVE_PATH)
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_SAVE_NAME), global_step=global_step)
def main(argv=None):
training_data_path = os.path.join(workspace_path, 'tensor_flow/google_tf/data')
mnist = input_data.read_data_sets(training_data_path, one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
mnist_eval.py
# -*- coding:utf-8 -*-
import time
import tensorflow as tf
from tensor_flow.google_tf.mnist_nn_best import mnist_inference, mnist_train
import os
from tensorflow.examples.tutorials.mnist import input_data
from tensor_flow import workspace_path
EVAL_INTERVAL_SECS = 5
def evaluate(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
y = mnist_inference.inference(x, None)
correct_predict = tf.equal(tf.argmax(y_, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
variable_averages = tf.train.ExponentialMovingAverage(mnist_train.MOVING_AVERAGE_DECYA)
variable_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variable_to_restore)
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print(f'After {global_step} steps training, accuracy: {accuracy_score}')
else:
print('No checkpoint file Found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
training_data_path = os.path.join(workspace_path, 'tensor_flow/google_tf/data')
mnist = input_data.read_data_sets(training_data_path, one_hot=True)
evaluate(mnist)
if __name__ == '__main__':
tf.app.run()
五、卷积神经网络
1. 常用图像识别数据集
- MNIST 数据集: 60000万张手写数字,有10000万张的测试集。图片的大小28*28像素
- CIFAR-10:10个种类的60000张彩色图片,图片的像素为32*32,人工标注的准确率大约94%。目前最好的深度学习算法在CIFAR-10的准确率达到95.59%,已经超过了人类。
- ImageNet:是基本WordNet的大型图库,将近有1500万图片被关联到2000万个名词的同义词集上。ImageNet每年都举办图像识别相关的竞赛(ImageNet Large Scale Visual Recognization Challage, ILSVRC)
- ILSVRC2012来自1000个类别的120万张图片。
2. 卷积神经网络
- 卷积后图像的通道数的计算:
一开始一个图片是一个32323的矩阵,32是高和宽,3是通道的个数,如果使用10个553的Filter过滤之后则第二卷积层的层数是10,也就是filter的个数。 - 卷积后图像大小的计算:
如果没有padding,步长为1的情况:卷积之后得到的维度是n-f+1
如果padding的像素大小为p,由于图片的两个边都要padding,则为2p,如果Filter的移动步长为s,则nxn的图片卷积完得到的大小为
n + 2 p − f s + 1 \frac{n+2p-f}{s}+1 sn+2p−f+1
Tensorflow实现卷积层
# -*- coding: utf-8 -*-
"""
Tensorflow 上实现卷积层是非常简单的,过滤器的参数是变量
"""
import tensorflow as tf
def conv_layer(inputs):
# 过滤器的权重变量
# shape是四维,前两维代表过滤器的尺寸,第三个维度代表当前层的通道个数,
# 第四个维度代表过滤器的个数(也就是下一层的通道个数)
filter_weight = tf.get_variable('weight', shape=[5, 5, 3, 16],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable('bias', shape=[16], initializer=tf.constant_initializer(0.1))
# tf.nn.conv2d实现了卷积的前向传播
# inputs代表输入,是一个四维的矩阵[0, :, :, :]代表第1个图片,第一个维度输入是batch,
# 后三个维度代表当层矩阵上的一个点
# 第二个参数代表filter
# 第三个参数代表步长,也是一个四维向量,第1个和第4个维度是固定为1 ,
# 第二个和第三个维度代表在图片的高和宽上的步长。
# padding: SAME代表不填充
conv = tf.nn.conv2d(inputs, filter_weight, strides=[1, 1, 1, 1], padding='SAME')
# 为每个节点加上bias项
bias = tf.nn.bias_add(conv, biases)
# 经过relu返回最后的结果
return tf.nn.relu(bias)
- 池化层 (pooling layer)
池化层可以有效的缩小矩阵的尺寸,而且可以起到防止过拟合。
# -*- coding: utf-8 -*-
"""
Tensorflow 上实现卷积层是非常简单的,过滤器的参数是变量,并加入池化层
"""
import tensorflow as tf
def conv_layer(inputs):
# 过滤器的权重变量
# shape是四维,前两维代表过滤器的尺寸,第三个维度代表当前层的通道个数,
# 第四个维度代表过滤器的个数(也就是下一层的通道个数)
filter_weight = tf.get_variable('weight', shape=[5, 5, 3, 16],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable('bias', shape=[16], initializer=tf.constant_initializer(0.1))
# tf.nn.conv2d实现了卷积的前向传播
# inputs代表输入,是一个四维的矩阵[0, :, :, :]代表第1个图片,第一个维度输入是batch,
# 后三个维度代表当层矩阵上的一个点
# 第二个参数代表filter
# 第三个参数代表步长,也是一个四维向量,第1个和第4个维度是固定为1 ,
# 第二个和第三个维度代表在图片的高和宽上的步长。
# padding: SAME代表不填充
conv = tf.nn.conv2d(inputs, filter_weight, strides=[1, 1, 1, 1], padding='SAME')
# 为每个节点加上bias项,并用relu函数激活
actived_conv = tf.nn.relu(tf.nn.bias_add(conv, biases))
# 池化层
# ksize是池化层的大小,第1个和第4个维度是1,代表不能在图片之间及深度之间传递
# 第二个和第三个参数代表池化层的尺寸,一般是2x2或3x3
# strides:步长,代表池化层移动的步长。
# padding: 'SAME'表示全0填充,VALID表示不填充
value = tf.nn.max_pool(actived_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding='SAME')
return value
六、循环神经网络
RNN
在一个RNN的cell中的参数都是一样的,随着时间步的移动,计算每一个输入的输出。当前cell的输入包括上一个的状态及x,内部的本质其实就是全连接层。
循环神经网络在每时都有输出,所以RNN的总的损失是所有时刻(或者部分时刻)的损失的和。
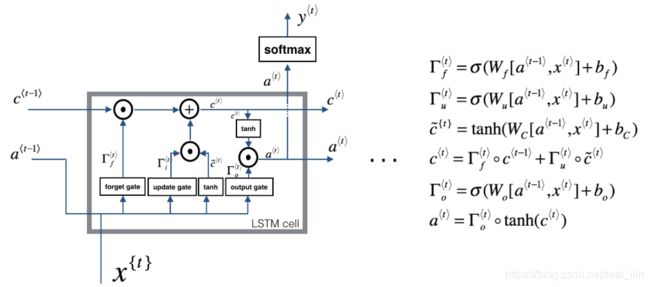
LSTM
LSTM 在1997年由“Hochreiter & Schmidhuber”提出,目前已经成为 RNN 中的标准形式,用来解决上面提到的 RNN 模型存在“长期依赖”的问题。LSTM中有三个门:forget gate,update gate,output gate
- 门的输出是一个(0,1)之间的数,然后乘以需要
LSTM中的参数个数的计算:
比如设置一个LSTM的num_units=128,这个参数其实各个门全连接层的神经单元的个数,再白点就是参数W的输出维度。输入的x的维度是200
则每个门的个数为:(128 + 200)128 +128 = 42112
一共有三个门加一个 c < t > c^{} c<t>的计算参数一共是四个:所以总的参数是421124 = 168448
参数一般是tf.float32:16万个参数总的空间大小为 168448/(1024*1024) = 1.2M
在使用LSTM时,有一个问题:
一层神经网络有kernal的shape为 (256,512),已知:num_units=128, emb_size=128.

GUR
Gated Recurrent Unit(GRU)门控循环单元,GRU(Gated Recurrent Unit)是2014年提出来的新的 RNN 架构,它是简化版的 LSTM。这里的门就是一个0~1的系数,来确定某个组成的权重;
The cat, which already ate …, was full. 前面是cat所以后面的使用单数
The cats, which already ate…, were full. 前面是cats,所以后面是复数。
如何利用神经网络把这点学到?
Simple GRU 有一个新的变量c,代表memory cell
-
替代值 c ~ < t > \widetilde{c}^{
} c <t>是由输入和x使用tanh函数计算出来的
c ~ < t > = t a n h ( W c [ c < t − 1 > , x < t > ] + b c ) \widetilde{c}^{} = tanh(W_c[c^{ c <t>=tanh(Wc[c<t−1>,x<t>]+bc)},x^{ }]+b_c) -
用输入的 c < t − 1 > c^{
} c<t−1>和 x t x^{t} xt及sigmoid函数计算一个0~1的概率,作为门 Γ u \Gamma_u Γu
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) \Gamma_u = \sigma(W_u[c^{
- 更新 c < t − 1 > c^{
} c<t−1>
c t = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > c^{t} = \Gamma_u*\widetilde{c}^{
Full GRU :有两个门 update gate 和relavation gate
-
候选值 c ~ < t > \widetilde{c}^{
} c <t>是由输入和x使用tanh函数计算出来的候选值: c ~ < t > = t a n h ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c ) \widetilde{c}^{
} = tanh(W_c[\Gamma_r*c^{ c <t>=tanh(Wc[Γr∗c<t−1>,x<t>]+bc)},x^{ }]+b_c) -
用输入的 c < t − 1 > c^{
} c<t−1>和 x t x^{t} xt及sigmoid函数计算一个0~1的概率,作为门 Γ u \Gamma_u Γu更新门: Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) \Gamma_u = \sigma(W_u[c^{
},x^{ Γu=σ(Wu[c<t−1>,x<t>]+bu)}]+b_u) -
表示线性相关性
相关门: Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b u ) \Gamma_r=\sigma(W_r[c^{
},x^{ Γr=σ(Wr[c<t−1>,x<t>]+bu)}]+b_u) -
更新 c < t − 1 > c^{
} c<t−1>
双向RNN
双向循环神经网络是两个独立的RNN的叠加在一起组合而成,输出由这个两个循环神经网络简单的拼接。
双向循环神经网络的主体结构就是两个单向循环神经网络的结合。在第一个时刻t,输入会同时提供给这两个方向相反的循环神经网络。两个网络独立进行计算,各自产生这个时刻的新状态和输出,而双向循环神经网络的最终输出是这两个单向循环神经网络的输出的简单拼接。两个循环神经网络除了方向不同以外,苦命结构完全对称。每一层网络中的Cell可以自由选用,可以是RNN,也可以是LSTM。
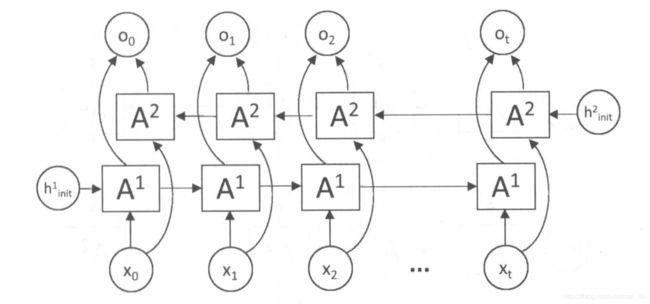
DeepRNN
深层循环神经网络,一层神经网络的表达能力有限,因为一层的神经网络相当于是从输入 x t x_t xt到输出 o t o_t ot只有一层全连接,现在是从输入 x t x_t xt到输出 o t o_t ot经过了L个RnnCell。
这个图从左到右看,一行是一层,每一层的参数是一样的,而不同层的cell的参数是不同的。
从下向上看, A 1 A_1 A1-> A 2 A_2 A2->…-> A L A^L AL,是同一时刻t,上一层的输出是当前层的输入。
在Tensorflow是使用MultiRNNCell来实现深层循环神经网络的前向传播的。

循环神经网络的dropout
类似卷积神经网络只在全连接层使用dropout,循环神经网络也只在不同层之间使用dropout,而不在同一层的不同时间步使用dropout。
# 定义LSTM结构
num_layers = 10
lstm = tf.nn.rnn_cell.BasicLSTMCell
rnn_cells = []
for _ in range(num_layers):
# 用input_keep_prob和output_keep_prob两个参数来控制输入和输入的dropout概率,0.9是保留的,有10%的被dropout
dropout_rnn_cell = tf.nn.rnn_cell.DropoutWrapper(lstm(lstm_hidden_siz), input_keep_prob=0.9,
output_keep_prob=0.8)
rnn_cells.append(dropout_rnn_cell)
stacked_rnn = tf.nn.rnn_cell.MultiRNNCell(rnn_cells)
七、自然语言处理
1. 语言模型的评价规则
复杂度:

复杂度的log形式:
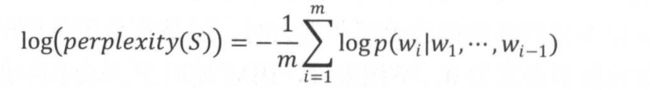
与交叉熵的形式是一样的,交叉熵是描述两个概率分布距离的,也就是真实值与预测之间的误差有多少。交叉熵越大,说明预测的准确性越低,交叉熵越小,说明预测的准确性越高。
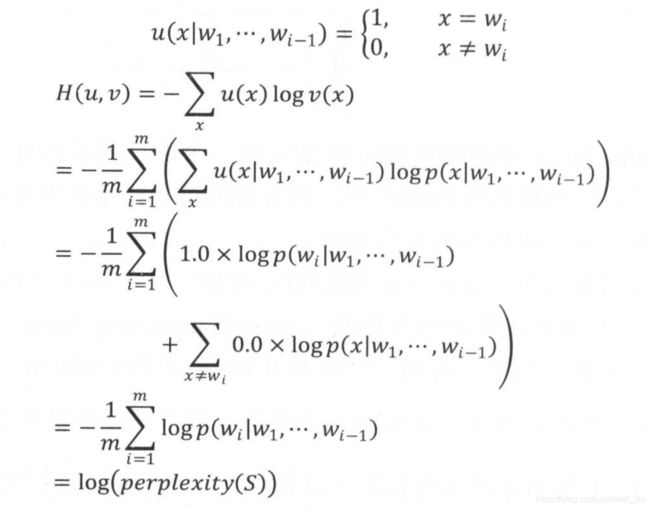
softmax_cross_entropy_with_logits
在神经网络中往往用softmax来归一化,这是为什么?
- 如何从反向传播的度角理解
https://blog.csdn.net/flying_sfeng/article/details/80927098
# -*- coding:utf-8 -*-
import tensorflow as tf
"""
tf.nn.sparse_softmax_cross_entropy_with_logits 与
tf.nn.softmax_cross_entropy_with_logits的区别:
只是在labels参数的形式不同
cross entropy:交叉熵 sum(-y*log(y_pred)),用来衡量两个向量的相似程度
"""
# 词典的大小有3个单词,语料中包含的单词有2个
labels = tf.constant([2, 0])
# logtis不是概率值如果需要计算概率值
# sigmoid也可以计算概率值,那么和softmax有啥区别呢?
# sigmoid是一维的,比如二分类问题中,预测值是一个比较大的数,需要映射到0~1之间。
# 而softmax是多维的,对一个向量来说,向量的和是1,每个位置的值对应的概率值。比如两个单词,第一个单词
# 在词典中的位置是分别的概率
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]])
# softmax之后再求cross entropy
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=predict_logits)
word_prob_distribute = tf.constant([[0, 0, 1], [1, 0, 0]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribute, logits=predict_logits)
# 在实际是应用中softmax_cross_entropy用的比较多,因为真实值的labels可以是一个概率
# 对于没有出现的词的话可以用比较接近0的值来代表
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
smoth_loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits)
total_loss = tf.reduce_mean(loss)
with tf.Session() as sess:
# 下面两个计算的值是一样的,输出的是一个两维的矩阵,代表两个单词的损失
# 如果要计算所有的损失和的话:tf.reduce_mean()来得到一个均值
# sparse cross entropy: [0.32656264 0.4643688 ]
# softmax cross entropy:[0.32656264 0.4643688 ]
# smoth softmax cross entropy:[0.37656265 0.48936883]
# mean loss: 0.3954657316207886
print('sparse cross entropy:', sess.run(cross_entropy))
print('softmax cross entropy:{}'.format(sess.run(loss)))
print('smoth softmax cross entropy:{}'.format(sess.run(smoth_loss)))
print('mean loss:{}'.format(sess.run(total_loss)))
PTB数据预处理
原始数据集是一段段的文字,首先根据训练数据构建词典,把单词转化为单词在词典中的index,另外加入了
为了增加并行处理文本能力,把文本处理成batch的形式。RNN的输入是一个单词的index,输出是输入单词的下一个单词。
批的大小batch_size,一个批内的数据大小是num_time_step。
# -*- coding: utf-8 -*-
from collections import Counter
from operator import getitem
import numpy as np
import os
cwd = os.getcwd()
TRAIN_BATCH_SIZE = 20
TRAIN_NUM_STEP = 35
class Vocab:
"""
根据读入的数据构建vocab
"""
def __init__(self, training_data_path, test_data_path):
self.training_data_path = training_data_path
self.test_date_path = test_data_path
def build_vocab(self):
counter = Counter()
with open(self.training_data_path, 'r', encoding='utf-8') as f:
for line in f:
for word in line.strip().split():
counter[word] += 1
self.counter = counter
words_sorted = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 加入eos 换行符
self.itos = ['' ] + [w[0] for w in words_sorted]
self.word2id = {word: self.itos.index(word) for word in self.itos}
def get_id(self, word):
return self.word2id[word] if word in self.word2id else self.word2id['' ]
def numerical(self, input_file, out_file):
with open(input_file, 'r', encoding='utf-8') as f:
for line in f:
# 在每行上加入换行符,换行符也是有意义的
words = line.strip().split() + ['' ]
words_ids = [str(self.get_id(word)) for word in words]
with open(out_file, 'a', encoding='utf-8') as ff:
ff.write(' '.join(words_ids) + '\n')
def read_data(data_path):
"""
把用id表示的训练数据读取成一个list
:param data_path:
:return:
"""
with open(data_path, 'r', encoding='utf-8') as f:
# 整个文档组成一个string
id_string = ' '.join([line.strip() for line in f.readlines()])
return [int(idx) for idx in id_string.split()]
def make_batches(id_list, batch_size, num_step):
"""
把整个文档的id list 分割成批,一批数据的大小是batch_size * num_step.
训练数据和label:babel是训练数据的下一个单词
一个timestep是一个单词
:param id_list:
:param batch_size:
:param num_step:
:return:
"""
# 最后不够一批的数据就不用了
num_batch = (len(id_list) - 1) // (batch_size * num_step)
data = np.array(id_list[:num_batch * batch_size * num_step])
data = np.reshape(data, [batch_size, num_batch * num_step])
# 按行分割成num_batch个批
data_batches = np.split(data, num_batch, axis=1)
labels = np.array(id_list[1:num_batch * batch_size * num_step + 1])
labels = np.reshape(labels, [batch_size, num_batch, num_step])
labels_batches = np.split(labels, num_batch, axis=1)
return list(zip(data_batches, labels_batches))
if __name__ == '__main__':
data_dir = os.path.join(cwd, 'ptb_data')
# train_data_path = os.path.join(data_dir, 'ptb.train.txt')
# test_data_path = os.path.join(data_dir, 'ptb.test.txt')
# vocab = Vocab(train_data_path, test_data_path)
# vocab.build_vocab()
output_data_path = os.path.join(data_dir, 'ptb.train')
# vocab.numerical(train_data_path, output_data_path)
batches = make_batches(read_data(output_data_path),TRAIN_BATCH_SIZE,TRAIN_NUM_STEP)
print(batches[:])
embedding层
与一般的循环神经网络相比,nlp的应用中加入了embedding层和softmax层
1. 为什么需要word embedding?
现在的输入是一个单词在词典中的index,如果进行one-hot处理后就是一个10000维的向量,这样的话向量太稀疏,也太大。
word ebedding之后,一方面是降维,从10000维降低到200~400维,可以大大减少神经网络的参数量和计算量。另一方面是增加语义信息,ebedding之后的词向量有了语义,比如意思相近的词的词向量的距离更小一些。
假设词向量的维度是EMB_SIZE,词汇表的大小是VOCAB_SIZE,那么所有的单词可以放入到一个大小为VOCAB_SIZE x EMB_SIZE的矩阵内,在读取词向量的时候,可以调用tf.nn.embedding_lookup方法。
# -*- coding: utf-8 -*-
import tensorflow as tf
VOCAB_SIZE = 10000
EMB_SIZE = 200
embedding = tf.get_variable('embedding', [VOCAB_SIZE, EMB_SIZE])
# 输入是一个batch_size=3, num_step=2, 词典大小是7
input_data = [[1, 2], [3, 4], [5, 6]]
# 输出的维度比输入的维度多一个维度,新增维度的大小是EBM_SIZE
# 在语言模型中,一般input_data的维度是batch_size x num_steps,而
# 输出的iput_embeddings的维度是 batch_size x num_steps x EMB_SIZE
# `embedding_lookup`函数作了查找的工作,把id转化为 word embedding vectors
input_embeddings = tf.nn.embedding_lookup(embedding, input_data)
softmax层
softmax层的作用是把循环神经网络的输出转化为一个单词表的每个单词的概率值。
第一步是使用一个线性映射把循环神经网络的输出映射为一个VOCAB_SIZE大小的向量,这一步的输出叫做logits
第二步是把logits计算为一个加和为1的概率向量
# softmax层中的参数
weight = tf.get_variable('weight', [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable('bias', [VOCAB_SIZE])
# 计算logits
# output是循环神经网络的输出,维度是[batch_size x num_step, HIDDEN_SIZE]
# logits的维度是[batch_size x num_step, VOCAB_SIZE]
logits = tf.nn.bias_add(tf.matmul(output, weight), bias)
# 再用softmax函数将logits归一化为一个加和概率为1的向量, 再用这个prob计算交叉熵
prob = tf.nn.softmax(logits)
# 而往往我们并不关注logits的值,而是直接计算cross entropy的值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(target, [-1]), logits=logits)
如果EMB_SIZE = 512, VOCAB_SIEZ=10000, HIDDEN_SIZE=512,则各种层的参数的个数:
- embedding层没有bias,10000*512 = 5120000
- 双层LSTM参数: 2 x [(512 + 512)x512+512]x4 =4198400个
- softmax层:10000*512 + 10000 = 5130000
可见双层LSTM参数占了不到30%
ebedding层和softmax层共享参数可以减少参数量,并且可以提高效果。
以PTB数据集的语言模型
概念:
- batch:把10000个训练样本分成20样本一个的batch来训练。在这个batch的数据上做梯度的反向传播。
- epoch:所有的训练数据循环的次数。比如有10000个训练数据,epoch=5, 则这10000个训练数据循环5遍,相当于有50000个训练样本。
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
import tensorflow as tf
import numpy as np
import os
cwd = os.getcwd()
from tensor_flow.google_tf.nlp.handle_data import read_data, make_batches
TRAIN_BATCH_SIZE = 20
TRAIN_NUM_STEP = 35
EVAL_BATCH_SIZE = 1
EVAL_NUM_STEP = 1
NUM_EPOCH = 5
class PtbModel(object):
def __init__(self, is_training, batch_size=20, num_step=35,
vocab_size=10000, emb_size=300, hidden_size=300,
num_layers=2, lstm_keep_prob=0.9, embedding_keep_prob=0.9,
max_grad_norm=5, share_emb_and_softmax=True):
self.is_training = is_training
self.batch_size = batch_size
self.num_step = num_step
self.vocab_size = vocab_size
self.emb_size = emb_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.emb_size = emb_size
self.lstm_keep_prob = lstm_keep_prob
self.embedding_keep_prob = embedding_keep_prob
self.max_grad_norm = max_grad_norm
self.share_emb_and_softmax = share_emb_and_softmax
self.input_data = tf.placeholder(tf.int32, [self.batch_size, self.num_step], name='inputs')
self.targets = tf.placeholder(tf.int32, [self.batch_size, self.num_step], name='targets')
# embedding layer
embeddings = tf.get_variable('embeddings', [self.vocab_size, self.hidden_size], tf.float32)
# 把输入的单词转化为词向量,inputs: [batch_size, num_step, emb_size]
inputs = tf.nn.embedding_lookup(embeddings, self.input_data)
# 如果是训练的时候,再dropout
if is_training:
inputs = tf.nn.dropout(inputs, self.embedding_keep_prob)
# two layers lstm
lstm_cells = [tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.BasicLSTMCell(self.hidden_size),
input_keep_prob=self.lstm_keep_prob)
for _ in range(self.num_layers)]
cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells)
# 两层lstm的初始化state,包括h和c
self.initial_state = cell.zero_state(self.batch_size, dtype=tf.float32)
# 把结果放到outputs中
outputs = []
state = self.initial_state
with tf.variable_scope('rnn'):
for time_step in range(self.num_step):
if time_step > 0:
tf.get_variable_scope().reuse_variables()
# 每一个时间步输出和状态
cell_outputs, state = cell(inputs[:, time_step, :], state)
outputs.append(cell_outputs)
# 把输出outputs展开为[batch, hidden_size*num_step],再reshape成[batch_size*num_step, hidden_size]的形状
outputs = tf.reshape(tf.concat(outputs, axis=1), [-1, self.hidden_size])
# =======softmax layer==========
if self.share_emb_and_softmax:
# 如果共享参数,embedding层的参数转置之后就是softmax层的参数,但是没有bias
weight = tf.transpose(embeddings)
else:
weight = tf.get_variable('softmax_w', [self.hidden_size, self.vocab_size])
bias = tf.get_variable('softmax_b', [self.vocab_size])
# [batch_size*num_step, vocab_size]
logits = tf.matmul(outputs, weight) + bias
# loss的维度:[batch_size*num_step]一维
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(self.targets, [-1]), logits=logits)
# 这个批的平均损失
self.cost = tf.reduce_sum(loss) / self.batch_size
self.final_state = state
if not is_training:
return
# ==============back propagation========
trainable_variables = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, trainable_variables), self.max_grad_norm)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables))
def run_epoch(session, model, batches, train_op, output_log, step):
total_cost = 0.0
iters = 0
state = session.run(model.initial_state)
for x, y in batches:
# print(np.array(x).shape, np.array(y).shape)
cost, state, _ = session.run([model.cost, model.final_state, train_op], {model.input_data: x, model.targets: y,
model.initial_state: state})
total_cost += cost
iters += model.num_step
if output_log and step % 100 == 0:
print(f'After {step}, perplexity is: {np.exp(total_cost / iters)}')
step += 1
return step, np.exp(total_cost / iters)
def main():
# 定义初始化函数
initializer = tf.random_uniform_initializer(minval=-0.1, maxval=0.1)
# 初始化模型
with tf.variable_scope('language_model', reuse=None, initializer=initializer):
train_model = PtbModel(True, batch_size=TRAIN_BATCH_SIZE, num_step=TRAIN_NUM_STEP)
# 定义测试用的模型,与训练模型共用参数,但是没有dropout
with tf.variable_scope('language_model', reuse=True, initializer=initializer):
eval_model = PtbModel(False, batch_size=EVAL_BATCH_SIZE, num_step=EVAL_NUM_STEP)
# 训练模型
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_batches = make_batches(read_data(os.path.join(cwd, 'ptb_data/ptb.train')), TRAIN_BATCH_SIZE,
TRAIN_NUM_STEP)
eval_batches = make_batches(read_data(os.path.join(cwd, 'ptb_data/ptb.eval')), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
test_batches = make_batches(read_data(os.path.join(cwd, 'ptb_data/ptb.test')), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
step = 0
for i in range(NUM_EPOCH):
print(f"In iteration: {i + 1}")
step, train_pplx = run_epoch(sess, train_model, train_batches, train_model.train_op, True, step)
print(f"Epoch:{i + 1}, train perplexity:{train_pplx}")
_, eval_pplx = run_epoch(sess, eval_model, eval_batches, tf.no_op(), False, 0)
print(f"Epoch:{i + 1}, eval perplexity:{eval_pplx}")
_, test_pplx = run_epoch(sess, eval_model, test_batches, tf.no_op(), False, 0)
print(f"Epoch:{i + 1},test perplexity:{test_pplx}")
if __name__ == '__main__':
main()
dynamic_rnn
在进行自然语言处理时,可能每句话长度不一致,但是在我们将矩阵送入模型时,要求长度是一致的。因此不相同的时间步长要求一致,以最大步长为准。这样也就需要进行填充,但是如果仅仅完成填充,在训练的时候不把这些填充的数据去除的话,那么这些填充位置的向量也会学习到特征,进一步影响梯度的计算,因此需要使用sequence_length来指定有效长度,跳过填充的部分。
单层单向lstm
def one_layer_lstm_cell(batch_size=1, emb_size=200, num_units=128, sequence_len=25):
X = np.random.randn(batch_size, sequence_len, emb_size)
sequence_len = [sequence_len]
# 前4个有值,后面的为padding的,为0
X[0, 4:] = 0
cell = tf.nn.rnn_cell.LSTMCell(num_units=num_units)
outputs, last_state = tf.nn.dynamic_rnn(cell=cell,
dtype=tf.float64,
sequence_length=sequence_len,
inputs=X,
time_major=False)
print('============lstm cell =======')
# outputs是所有时间步的输出
# last_states是一个tuple,里面有两个值,分别是c,h 。 c是最后一个时间步的长期记忆,h是最后一个时间步的短期记忆
print(f'----->outputs:{outputs}')
print(f'----->state:{last_state}')
单层双向lstm
def one_layer_bilstm_cell(batch_size=1, emb_size=200, num_units=128, sequence_len=25):
X = np.random.randn(batch_size, sequence_len, emb_size)
sequence_len = [sequence_len]
cell_fw = tf.nn.rnn_cell.LSTMCell(num_units=num_units)
cell_bw = tf.nn.rnn_cell.LSTMCell(num_units=num_units)
print('========bilstm cell==========')
outputs, last_state = tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw,
inputs=X,
dtype=tf.float64,
sequence_length=sequence_len)
# outputs是一个tuple,里面有两个值。第一个值是前向循环单元每一个时间步的输出,第二个值是反向循环单元每一个时间步的输出。
# states也是一个tuple,里面仍然有两个值分别都是LSTMStateTuple,第一个(前向循环单元最后一个时间步的长期记忆c,
# 前向循环单元最后一个时间步的短期记忆h) 第二个(反向循环单元最后一个时间步的长期记忆c,反向循环单元最后一个时间步的短期记忆h)
print(f'----->outputs:{outputs}')
print(f'----->state:{last_state}')
单步多层LSTM
def multi_lstm():
batch_size = 10
depth = 128
num_units = [100, 400, 300]
last_num_units = num_units[-1]
cells = [tf.nn.rnn_cell.BasicLSTMCell(num_unit) for num_unit in num_units]
# 得到的mul_cells也是RNNCell的子类的对象
mul_cells = tf.nn.rnn_cell.MultiRNNCell(cells)
# 接下来使用mul_cells的call方法,在一个时间步上运行
# 下面三个参数分别是指,3层lstm网络中,每一层lstm,上一个时间步的输出, previous_state包括c和h
previous_state0 = (tf.random_normal([batch_size, 100]), tf.random_normal([batch_size, 100]))
previous_state1 = (tf.random_normal([batch_size, 400]), tf.random_normal([batch_size, 400]))
previous_state2 = (tf.random_normal([batch_size, 300]), tf.random_normal([batch_size, 300]))
"""
这里的inputs 和普通的inputs 不同。普通的inputs的shape是(batch_size,max_step,depth),
这里的inputs的shape是(batch_size,depth),原因在于这里的时间步骤已经指定。
"""
inputs = tf.Variable(tf.random_normal([batch_size, depth]))
# 调用call方法,在当前时间步骤运行网络
outputs, states = mul_cells.call(inputs=inputs, state=(previous_state0, previous_state1, previous_state2))
print(outputs.shape) # (10, 300) Tensor
print(states) # (3,) 元组类型,存有3个LSTMStateTuple对象,((c,h),(c,h),(c,h))
"""
接下来说明一下 outputs和states 这两个返回值
(1)outputs 的shape (batch_size,last_num_units) 表示当前step最后一层的输出
(2)states 包含3个LSTMStateTuple,每一个表示每一层的当前step的输出,这个输出有两个信息,
一个是h表示短期记忆信息,一个是c表示长期记忆信息。维度都是[batch_size,num_units],
states的最后一个LSTMStateTuple中的h就是outputs的最后一个step的输出
"""
一次性执行多步call:dynamic_rnn
一次性执行多步call方法 :tf.nn.dynamic_rnn
基础的RNNCell有一个很明显的问题:对于单个的RNNCell,我们使用它的call函数进行运算时,只是在序列时间上前进了一步。比如使用x1、h0得到h1,通过x2、h1得到h2等。这样的h话,如果我们的序列长度为10,就要调用10次call函数,比较麻烦。对此,TensorFlow提供了一个函数,使用该函数就相当于调用了n次call函数。即通过{h0,x1, x2, …., xn}直接得{h1,h2…,hn}。
还有一个作用是:根据输入的sequence_length,读取batch里的每一条数据,在读取了相应的内容之后就跳过后面的输入。这样就把padding的数据跳过了。
并且输入的每个batch的time step也不一定相同,但是dynamic会根据每个batch的max_sequence_length来展开rnn的cell。在计算权重的时候也是一样的,需要把padding位置的wight设置为0,这样就不会引起梯度的计算了。
tf.nn.dynamic_rnn返回值详解
def dynamic_rnns(num_steps=2, emb_size=3, num_units=5):
"""
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
:param num_steps:
:param emb_size:
:param num_units:
:return:
"""
X = tf.placeholder(tf.float32, [None, num_steps, emb_size]) # [batch_size, num_steps, emb_size]
lstm_cell = tf.nn.rnn_cell.BasicRNNCell(num_units=num_units)
seq_length = tf.placeholder(tf.int32, [None]) # [batch_size]
outputs, last_state = tf.nn.dynamic_rnn(lstm_cell, X, sequence_length=seq_length, dtype=tf.float32)
X_batch = np.array([
# step 0 step 1
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2 (padded with zero vectors)
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]] # instance 4
])
seq_length_batch = [2, 1, 2, 2]
with tf.Session() as sess:
tf.global_variables_initializer().run()
outputs_val, last_state_val = sess.run([outputs, last_state],
feed_dict={X: X_batch, seq_length: seq_length_batch})
print(f'outputs.shape:{outputs_val.shape}, last_state.shape:{last_state_val.shape}')
print(f'outputs_val: \n{outputs_val}')
print(f'last_state_val: \n{last_state_val}')
输入是一个(4, 2, 5)的一批数据,batch_size是4,有2个time_step,RNN cell中的神经元的个数是5。先说outputs是啥:outputs是最后一层RNN的所有time step的h,而state是所有层的最后一个time step的h。如果是LSTM cell的话,则state中是h和c。这个其实很好理解:既然是ouputs,则每个time step要有一个对应的输出,因为每一个time step就是一个单词。而state只要保留最后一个就好了,这样可以作为下一个batch的输入。
outputs是一个(4, 2, 5)Tensor,分别是[batch_size, num_steps, num_units], last_state是一个[batch_size, num_units]的Tensor。
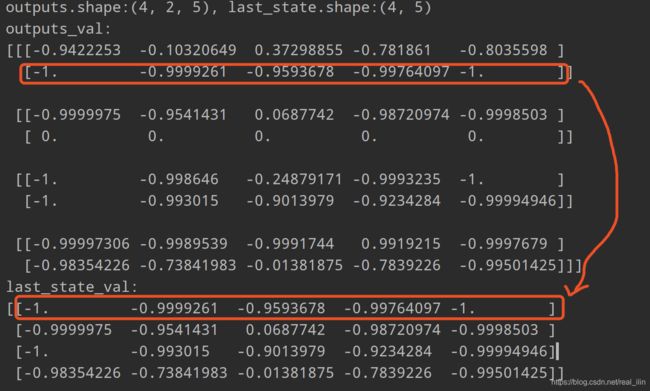
多层RNN
def dynamic_rnns(num_steps=2, emb_size=3, num_units=5, num_layers=3):
"""
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
"""
X = tf.placeholder(tf.float32, [None, num_steps, emb_size]) # [batch_size, num_steps, emb_size]
rnn_cells = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicRNNCell(num_units=num_units) for _ in range(num_layers)])
seq_length = tf.placeholder(tf.int32, [None]) # [batch_size]
outputs, last_state = tf.nn.dynamic_rnn(rnn_cells, X, sequence_length=seq_length, dtype=tf.float32)
X_batch = np.array([
# step 0 step 1
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2 (padded with zero vectors)
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]] # instance 4
])
seq_length_batch = [2, 1, 2, 2]
with tf.Session() as sess:
tf.global_variables_initializer().run()
outputs_val, last_state_val = sess.run([outputs, last_state],
feed_dict={X: X_batch, seq_length: seq_length_batch})
# 这里直接打印的是ouputs,而不是outputs_val
print(f'outputs.shape:{outputs}, \n last_state.shape:{last_state}')
print(f'outputs_val: \n{outputs_val}')
print(f'last_state_val: \n{last_state_val}')
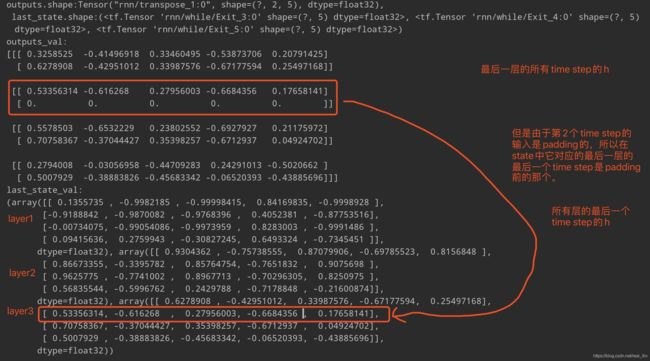
双向LSTM
def bidirection_lstms(num_units=5, emb_size=3, num_steps=2):
"""tf.nn.bidirectional_dynamic_rnn(
cell_fw,
cell_bw,
inputs,
sequence_length=None,
initial_state_fw=None,
initial_state_bw=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)"""
X = tf.placeholder(tf.float32, [None, num_steps, emb_size])
seq_len = tf.placeholder(tf.int32, [None])
lstm_fw = tf.nn.rnn_cell.BasicLSTMCell(num_units=num_units)
lstm_bw = tf.nn.rnn_cell.BasicLSTMCell(num_units=num_units)
outputs, last_state = tf.nn.bidirectional_dynamic_rnn(lstm_fw, lstm_bw, X, sequence_length=seq_len,
dtype=tf.float32)
X_batch = np.array([
# step 0 step 1
[[0, 1, 2], [9, 8, 7]], # instance 1
[[3, 4, 5], [0, 0, 0]], # instance 2 (padded with zero vectors)
[[6, 7, 8], [6, 5, 4]], # instance 3
[[9, 0, 1], [3, 2, 1]] # instance 4
])
seq_length_batch = [2, 1, 2, 2]
with tf.Session() as sess:
tf.global_variables_initializer().run()
outputs_val, last_state_val = sess.run([outputs, last_state],
feed_dict={X: X_batch, seq_len: seq_length_batch})
print(f'outputs.shape:{outputs}, \n last_state.shape:{last_state}')
print(f'outputs_val: \n{outputs_val}')
print(f'last_state_val: \n{last_state_val}')
先forward,再backward:

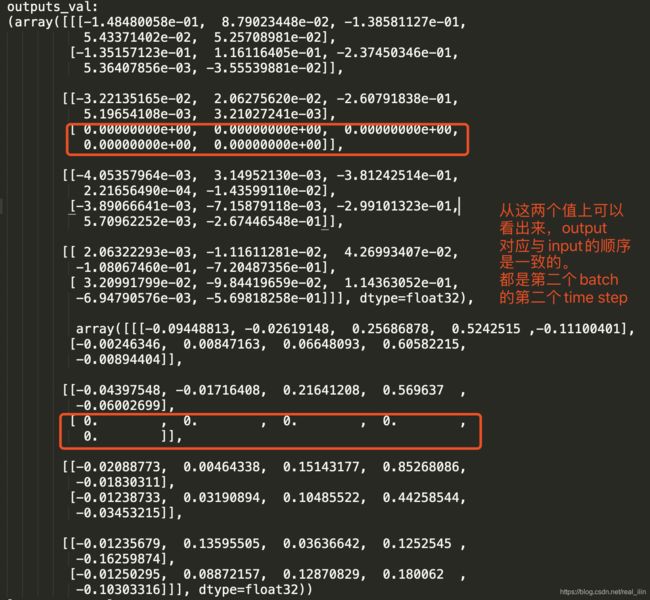

seq2seq模型
Seq2seq于2014年提出来,可以用于机器翻译方面。思想也比较简单:用一个循环神经网络读入句子,把句子压缩成一个固定维度的编码中;再用另一个循环神经网络将其解压成目标语言的句子。这两个神经网络分别称为编码器(Encoder)和解码器(Decoder),这个模型又称为Encoder-decoder模型。
解码器部分的结构与语言模型几乎完全相同:输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为log perplexity。语言模型中使用的一些技巧,如共享softmax层与词向量的参数,都可以直接应用到Seq2Seq模型的解码器中。
编码器则更简单,它解码器一样也拥有词向量层和循环神经网络,但是由于在编码阶段并未输出,因此是不需要softmax层的。
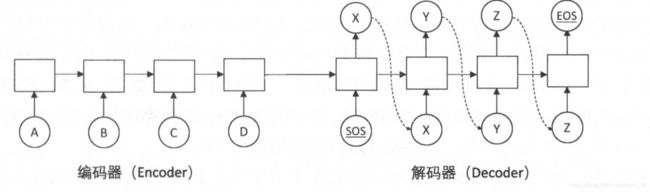
在训练的过程中,Encoder顺序读入每个单词的词向量,然后将最后的隐藏状态复制到Decoder作为初始状态。Decoder的第一个输入是一个特殊的符号
机器翻译最重要的公开数据集是WMT数据集,全称是Workshop on Statistical Machine Translation.
假设有四个句子,组成batch_size为2的两个batch,并对句子进行了填充。
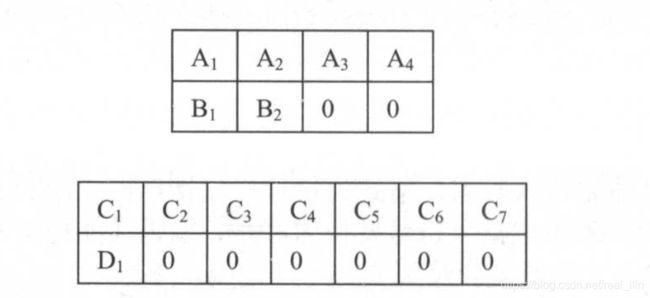
Corpus处理:
# -*- coding: utf-8 -*-
import os
import nltk.tokenize as tk
from typing import List, Tuple
import logging
from collections import Counter
cwd = os.getcwd()
class Preprocessor:
def __init__(self, raw_en_path, raw_zh_path, en_vocab_size=10000,
zh_vocab_size=4000, logger=None):
self.raw_en_path = raw_en_path
self.raw_zh_path = raw_zh_path
self.en_vocab_size = en_vocab_size
self.zh_vocab_size = zh_vocab_size
self.logger = logger if logger is not None else logging
self.handle_data()
def handle_data(self):
# preprocess
self.preprocess_corpus()
# tokenize
self.tokenize_sentences()
# build vocab
self.build_vocab()
# numerical
self.numerical()
# padding
self.padding()
def preprocess_corpus(self):
delete_tags = ['' , '' , '' , '' , ', ']
contain_tags = [(''</span><span class="token punctuation">,</span> <span class="token string">' '), ('' , '')]
def is_deleted(sentence: str) -> bool:
for t in delete_tags:
if sentence.startswith(t):
return True
else:
continue
return False
def only_drop_tags(sentence: str) -> str:
for t in contain_tags:
if sentence.startswith(t[0]):
s = sentence.replace(t[0], '')
s = s.replace(t[1], '')
return s
else:
continue
return sentence
def read_lines(file_path, is_zh=False):
target_lines = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if is_deleted(line):
continue
line = only_drop_tags(line)
if is_zh:
line = line.strip().replace(' ', '')
# if not is_zh:
# line = line.lower()
target_lines.append(line.strip())
return target_lines
self.en_lines, self.zh_lines = read_lines(self.raw_en_path), read_lines(self.raw_zh_path, is_zh=True)
if len(self.en_lines) != len(self.zh_lines):
raise ValueError(
f"The lines of en corpus {len(self.en_lines)} not match zh corpus'lines {len(self.zh_lines)} ")
print(f"en lines:{len(self.en_lines)}, zh lines:{len(self.zh_lines)}")
def tokenize_sentences(self):
en_tokens = []
zh_tokens = []
for line in self.en_lines:
tokenizer = tk.WordPunctTokenizer()
tokens = tokenizer.tokenize(line)
en_tokens.append(tokens)
for line in self.zh_lines:
zh_tokens.append(list(line))
# the shape of self.en_tokens is [[word1, word2, ...,],[word1, word2,.. ]]
self.en_tokens, self.zh_tokens = en_tokens, zh_tokens
self.max_en_sentence_len = max([len(words) for words in self.en_tokens])
self.max_zh_sentence_len = max(len(words) for words in self.zh_tokens)
print(f"max en sentence len:{self.max_en_sentence_len}")
print(f'max zh sentence len:{self.max_zh_sentence_len}')
def build_vocab(self):
def count_words(tokens, vocab_size):
counter = Counter()
for words in tokens:
for word in words:
counter[word] += 1
words_sorted = sorted(counter.items(), key=lambda x: x[1], reverse=True)
itos = ['' , '' , '' ] + [w[0] for w in words_sorted]
if vocab_size is not None:
print(f'total words in vocab:{len(itos)}')
itos = itos[:vocab_size]
word2id = {word: itos.index(word) for word in itos}
return word2id
self.en_vocab = count_words(self.en_tokens, self.en_vocab_size)
self.zh_vocab = count_words(self.zh_tokens, self.zh_vocab_size)
print(f"en vocab size:{len(self.en_vocab)}, zh vocab size: {len(self.zh_vocab)}")
def numerical(self):
def _get_id(word, vocab):
return vocab[word] if word in vocab else vocab['' ]
def _numerical(line_words, vocab):
numerical_lines = []
for words in line_words:
words = words + ['' ]
words_ids = [str(_get_id(word, vocab)) for word in words]
numerical_lines.append(' '.join(words_ids))
return numerical_lines
# self.en_numerical_tokens shape []
self.en_numerical_tokens = _numerical(self.en_tokens, self.en_vocab)
self.zh_numerical_tokens = _numerical(self.zh_tokens, self.zh_vocab)
def padding(self):
pass
@staticmethod
def write_lines(path, lines):
with open(path, 'w', encoding='utf-8') as f:
f.write('\n'.join(lines))
def get_abs_path(filename):
return os.path.join(cwd, 'data/en-zh', filename)
if __name__ == '__main__':
raw_files = ['train.tags.en-zh.en', 'train.tags.en-zh.zh']
lines_files = ['train.line.en', 'train.line.zh']
words_files = ['train.words.en', 'train.words.zh']
ids_files = ['train.ids.en', 'train.ids.zh']
processor = Preprocessor(get_abs_path(raw_files[0]), get_abs_path(raw_files[1]))
Preprocessor.write_lines(get_abs_path(lines_files[0]), processor.en_lines)
Preprocessor.write_lines(get_abs_path(lines_files[1]), processor.zh_lines)
Preprocessor.write_lines(get_abs_path(words_files[0]), [' '.join(tokens) for tokens in processor.en_tokens])
Preprocessor.write_lines(get_abs_path(words_files[1]), [' '.join(tokens) for tokens in processor.zh_tokens])
Preprocessor.write_lines(get_abs_path(ids_files[0]), processor.en_numerical_tokens)
Preprocessor.write_lines(get_abs_path(ids_files[1]), processor.zh_numerical_tokens)
en_ids = '1,127,13,5,692,1771,2'
en_s = 'life in the deep oceans'
print([processor.en_vocab[w] for w in en_s.split()])
zh_s = '深海中的生命-大卫.盖罗'
print([processor.zh_vocab[w] for w in list(zh_s)])
- 生成batch数据
# -*- coding: utf-8 -*-
import tensorflow as tf
import os
import numpy as np
import logging
cwd = os.getcwd()
MAX_LEN = 50 # 限定句子的最大单词数量。
SOS_ID = 1 # 目标语言词汇表中的ID。
src_file_path = os.path.join(cwd, 'data/en-zh', 'train.ids.en')
tgt_file_path = os.path.join(cwd, 'data/en-zh', 'train.ids.zh')
def iterator(src_path=src_file_path, target_path=tgt_file_path, batch_size=100, logger=None):
en_lines = []
with open(src_path, 'r', encoding='utf-8') as f:
for line in f:
en_lines.append([int(index) for index in line.strip().split()])
zh_label_lines = []
zh_input_lines = []
with open(target_path, 'r', encoding='utf-8') as ff:
for line in ff:
ids = [int(index) for index in line.strip().split()]
zh_label_lines.append(ids)
ids_input = [SOS_ID] + ids[:-1]
zh_input_lines.append(ids_input)
assert len(en_lines) == len(zh_input_lines)
# logger.info(f'en_lines len:{len(en_lines)}, zh lines len:{len(zh_input_lines)},label len:{len(zh_label_lines)}')
sentences = []
for en, zh, label in zip(en_lines, zh_input_lines, zh_label_lines):
if min(len(en), len(zh)) > MAX_LEN:
continue
sentences.append((en, zh, label))
num_batches = (len(sentences) - 1) // batch_size + 1
# logger.info(f'---->num batches:{num_batches}-----')
for i in range(num_batches):
batch_examples = sentences[i * batch_size:(min(len(sentences), i * batch_size + batch_size))]
en_batch = []
zh_batch = []
label_batch = []
for x, y, z in batch_examples:
en_batch.append(x)
zh_batch.append(y)
label_batch.append(z)
en_seq_len = [len(w) for w in en_batch]
zh_seq_len = [len(w) for w in zh_batch]
en_batch = padding(en_batch, en_seq_len)
zh_batch = padding(zh_batch, zh_seq_len)
label_batch = padding(label_batch, zh_seq_len)
yield en_batch, en_seq_len, zh_batch, zh_seq_len, label_batch
def padding(inputs, seq_len):
max_seq_len = max(seq_len)
batch_size = len(inputs)
padded_inputs = np.zeros(shape=(batch_size, max_seq_len), dtype=np.int32)
for i, ids in enumerate(inputs):
padded_inputs[i, :len(ids)] = ids
return padded_inputs
def zip_test():
en_inputs = [[1, 2], [28, 12, 2, 3]]
en_seq_len = [len(w) for w in en_inputs]
zh_inputs = [[1], [23, 32, 3, 5]]
zh_seq_len = [len(w) for w in zh_inputs]
sentences = []
for x, y in zip(en_inputs, zh_inputs):
if min(len(x), len(y)) < 1:
continue
else:
sentences.append((x, y))
print(sentences[:2])
if __name__ == '__main__':
for en, en_len, zh, zh_len, labels in iterator():
print(en.shape)
print(en)
print(en_len)
print('*' * 40)
print(zh)
print(zh_len)
print('*' * 40)
print(labels)
break
- 模型
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import logging
class MTModel(object):
def __init__(self, hidden_size=1024, num_layers=2, src_vocab_size=10000,
tgt_vocab_size=4000, max_grad_norm=5,
share_emb_and_sofmax=True, emb_keep_prob=0.9,
learning_rate=0.001,
initializer=tf.random_normal_initializer(stddev=0.1),
logger=None):
self.hidden_size = hidden_size
self.num_layers = num_layers
self.src_vocab_size = src_vocab_size
self.tgt_vocab_size = tgt_vocab_size
self.max_grad_norm = max_grad_norm
self.share_emb_and_softmax = share_emb_and_sofmax
self.emb_keep_prob = emb_keep_prob
self.learning_rate = learning_rate
self.initializer = initializer
self.logger = logger if logger is not None else logging
self.add_placehoders()
self.forward()
self.backward()
self.logger.info('Init model finised!')
def add_placehoders(self):
self.src_inputs = tf.placeholder(tf.int32, [None, None], 'src_inputs') # [batch_size, seq_len]
self.src_seq_len = tf.placeholder(tf.int32, [None], 'src_seq_len') # [batch_size]
self.tgt_inputs = tf.placeholder(tf.int32, [None, None], 'tgt_inputs') # [batch_size, seq_len]
self.tgt_seq_len = tf.placeholder(tf.int32, [None], 'tgt_seq_len') # [batch_size]
self.tgt_labels = tf.placeholder(tf.int32, [None, None], 'tgt_labels') # [batch_size, seq_len]
self.global_step = tf.Variable(0, trainable=False)
def forward(self):
with tf.variable_scope('encoder'):
# Encoder和Decoder使用的embedding params
self.enc_embeddings = tf.get_variable('src_emb_params', [self.src_vocab_size, self.hidden_size],
initializer=self.initializer)
# embedding layer
src_emb = tf.nn.dropout(tf.nn.embedding_lookup(self.enc_embeddings, self.src_inputs),
keep_prob=self.emb_keep_prob)
self.enc_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(self.hidden_size)
for _ in range(self.num_layers)])
# outputs and laste_state are Tuple
# [batch_size, seq_len, hidden_size], state.shape: [batch_size, hidden_size]
enc_outputs, enc_state = tf.nn.dynamic_rnn(self.enc_cell, src_emb,
sequence_length=self.src_seq_len,
dtype=tf.float32)
# decoder的初始state是encoder层的last_state
with tf.variable_scope('decoder'):
# embedding layer
self.dec_embeddings = tf.get_variable('tgt_emb_params', [self.tgt_vocab_size, self.hidden_size],
initializer=self.initializer)
tgt_emb = tf.nn.dropout(tf.nn.embedding_lookup(self.dec_embeddings, self.tgt_inputs),
keep_prob=self.emb_keep_prob)
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(self.hidden_size)
for _ in range(self.num_layers)])
dec_outputs, dec_state = tf.nn.dynamic_rnn(self.dec_cell, tgt_emb,
sequence_length=self.tgt_seq_len,
initial_state=enc_state)
with tf.variable_scope('softmax_layer'):
if self.share_emb_and_softmax:
self.sofmax_w = tf.transpose(self.dec_embeddings)
else:
self.sofmax_w = tf.get_variable('softmax_w', [self.hidden_size, self.tgt_vocab_size])
self.sofmax_b = tf.get_variable('softmax_b', [self.tgt_vocab_size])
batch_size = tf.shape(dec_outputs)[0]
# softmax layer
output = tf.reshape(dec_outputs, [-1, self.hidden_size])
logits = tf.matmul(output, self.sofmax_w) + self.sofmax_b # [batch_size*seq_len, tgt_vocab_size]
# 计算Decoder每一步的损失 每一个样本的损失,里面包含了padding的样本
# loss shape : 一维,[batch_size*seq_len]
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(self.tgt_labels, [-1]), logits=logits)
# 在计算损平均损失时,需要将填充位置的权重设置为0, 以避免无效位置预测干扰
label_weights = tf.sequence_mask(self.tgt_seq_len, maxlen=tf.shape(self.tgt_labels)[1],
dtype=tf.float32) # [batch_size, max_seq_len]
label_weights = tf.reshape(label_weights, [-1])
total_cost = tf.reduce_sum(label_weights * loss) # 不能直接用tf.reduce_mean,因为样本中有padding的样本
self.cost_per_batch = total_cost / tf.to_float(batch_size)
self.cost_per_token = total_cost / tf.reduce_sum(label_weights)
def backward(self):
# GradientDescentOptimizer
# trainable_variables = tf.trainable_variables()
# grads = tf.gradients(self.cost_per_batch, trainable_variables)
# grads, _ = tf.clip_by_global_norm(grads, self.max_grad_norm)
# optimizer = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate)
# self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables))
# Adam optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
self.train_op = optimizer.minimize(self.cost_per_batch, global_step=self.global_step)
def inference(self, src_input, dec_max_step=100):
SOS_ID, EOS_ID = 1, 2
src_size = tf.convert_to_tensor([len(src_input)], dtype=tf.int32)
src_input = tf.convert_to_tensor([src_input], dtype=tf.int32)
# 用训练好的encoder的embedding参数来对输入的英文句子作embedding
src_emb = tf.nn.embedding_lookup(self.enc_embeddings, src_input)
with tf.variable_scope('encoder'):
enc_outputs, enc_state = tf.nn.dynamic_rnn(self.enc_cell, src_emb, sequence_length=src_size,
dtype=tf.float32)
with tf.variable_scope('decoder/rnn/multi_rnn_cell'):
init_array = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True, clear_after_read=False)
init_array = init_array.write(0, SOS_ID)
# 构建初始的循环状态,包括encoder输出的state, 存储句子的数组及步数
init_loop_var = (enc_state, init_array, 0)
def continue_loop_conditions(state, trg_ids, step):
return tf.reduce_all(tf.logical_and(
tf.not_equal(trg_ids.read(step), EOS_ID),
tf.less(step, dec_max_step - 1)
))
def loop_body(state, trg_ids, step):
# 读取最后一步输出的单词,并取其词向量
self.logger.debug(trg_ids.size())
trg_inputs = [trg_ids.read(step)]
trg_emb = tf.nn.embedding_lookup(self.dec_embeddings, trg_inputs)
self.logger.debug('---->trg_emb', trg_emb)
# 直接使用decoder的cell来一步步的计算,dec_outputs:[batch_size, max_seq_len, hidden_size]
dec_outputs, next_state = self.dec_cell.call(inputs=trg_emb, state=state)
# 计算logits
dec_outputs = tf.reshape(dec_outputs, [-1, self.hidden_size])
logits = tf.matmul(dec_outputs, self.sofmax_w) + self.sofmax_b
next_id = tf.argmax(logits, axis=1, output_type=tf.int32)
# 把预测到zh单词写到动态数组中
# 这里有一个坑 trg_ids = trg_ids.write(step+1, next_id[0]) right
# trg_ids.write(step+1, next_id[0]) wrong
trg_ids = trg_ids.write(step + 1, next_id[0])
return next_state, trg_ids, step + 1
final_state, final_ids, final_step = tf.while_loop(continue_loop_conditions, loop_body, init_loop_var)
return final_ids.stack()
if __name__ == '__main__':
mt_model = MTModel()
print(mt_model)
for v in tf.global_variables():
print(v)
feed = dict()
feed[mt_model.src_inputs] = np.random.randint(low=0, high=10000, size=[128, 50])
feed[mt_model.src_seq_len] = np.random.randint(low=0, high=50, size=[128])
feed[mt_model.tgt_inputs] = np.random.randint(low=0, high=4000, size=[128, 50])
feed[mt_model.tgt_seq_len] = np.random.randint(low=0, high=50, size=[128])
feed[mt_model.tgt_labels] = np.random.randint(low=0, high=4000, size=[128, 50])
sentence_ids = [95, 14, 10, 701, 4, 2]
pred_op = mt_model.inference(sentence_ids)
with tf.Session() as sess:
tf.global_variables_initializer().run()
cost_val, _ = sess.run([mt_model.cost_per_batch, mt_model.train_op], feed_dict=feed)
print(cost_val)
outputs_val = sess.run(pred_op)
print(outputs_val)
- 训练
# -*- coding: utf-8 -*-
import tensorflow as tf
import sys
from os.path import abspath, dirname
sys.path.append(dirname(dirname(dirname(dirname(abspath(__file__))))))
from tensor_flow.google_tf.seq2seq.datasets import iterator
from tensor_flow.google_tf.seq2seq.seq_model import MTModel
from tensor_flow.google_tf.seq2seq.basic_logging import init_logger
import os
import numpy as np
import logging
cwd = os.getcwd()
def run_epoch(model, session, saver, step, ckpt_path, logger=None):
for en_inputs, en_seq_len, zh_inputs, zh_seq_len, labels in iterator():
cost_per_token_val, _ = session.run([model.cost_per_token, model.train_op],
feed_dict={model.src_inputs: en_inputs,
model.src_seq_len: en_seq_len,
model.tgt_inputs: zh_inputs,
model.tgt_seq_len: zh_seq_len,
model.tgt_labels: labels})
if step % 10 == 0:
logger.info('After {} step, per token cost: {:.4f}'.format(step, cost_per_token_val))
if step % 200 == 0:
saver.save(session, ckpt_path, global_step=step)
step += 1
def main():
logger_path = os.path.join(cwd, 'log')
init_logger(logger_path)
logger = logging.getLogger('logger')
mt_model = MTModel(logger=logger)
saver = tf.train.Saver()
ckpt_path = os.path.join(cwd, 'model', 'mt-model')
num_epoches = 5
step = 0
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(num_epoches):
logger.info(f'---------------Running the epoch {i}--------------')
run_epoch(model=mt_model, session=sess, saver=saver, step=step, ckpt_path=ckpt_path,
logger=logger)
if __name__ == '__main__':
main()
训练完成后,从checkpoint中加载模型,并对一个新的句子(英译汉)进行预测。与训练时不同,训练的时候,Decoder可以读取汉语句子作为输入,但是在预测时就没有汉语句子可以输入了。所以在预测时Decoder读取tf.while_loop来实现的。
Attention机制
浅谈 Attention 机制的理解

在上图中, h i h_i hi表示编码器在第 i i i个单词上的输出, s j s_j sj是Decoder在预测第 j j j个单词时的状态。有一个问题是Encoder和Decoder的时间步的长度是不一样的? i i i和 j j j是如何对应的呢?其实没有对应,在解码的时候,每一步的context是单独计算的。如果把Encoder层的输出作为一个hidden_size维的向量时,在每个维度上乘了个权重,本质上还是带权重的特征。
计算 j j j时刻的context的方法如下:
α i , j = e x p ( e ( h i , s j ) ) ∑ i e x p ( e ( h i , s j ) ) \alpha_{i,j}=\frac{exp(e(h_i,s_j))}{\sum_i exp(e(h_i,s_j))} αi,j=∑iexp(e(hi,sj))exp(e(hi,sj))
c o n t e x t j = ∑ i α i , j h i context_j=\sum_i \alpha_{i,j} h_i contextj=i∑αi,jhi
其中 e ( h i , s j ) e(h_i,s_j) e(hi,sj)是计算原文各个单词与当前解码器状态的“相关度”的函数。最常用的 e ( h , s ) e(h,s) e(h,s)函数定义是一个带有单个隐藏层的前馈神经网络:
e ( h , s ) = U t a n h ( V h + W s ) e(h,s)=U tanh(Vh+Ws) e(h,s)=Utanh(Vh+Ws)
这个函数构成了一个包含一个隐藏层的全连接神经网络。这个模型是是Dzmitry Bahdanau等在第一次提出注意力机制的论文中采用的模型。除此之外,还有Minh-Thang Luong等提取的 e ( h , s ) = h T W s e(h,s)=h^TWs e(h,s)=hTWs或者直接使用两个状态之间的点乘 e ( h , s ) = h T s e(h,s)=h^Ts e(h,s)=hTs。
在计算得到第j步context向量之后,context被加入到j+1时刻作为循环层的输入。
还有两个注意的地方:
- Encoder采用了一个双向循环网络;
- 取消了Encoder与Decoder之间的连接,Decoder完全依赖于注意力机制获取原文信息。取消这一连接使得Encoder与Decoder可以自由选择模型。例如它们可以选择不同层数,不同维度、不同结构的循环神经网络。可以在Encoder中使用双向LSTM,而在Decoder中使用单向LSTM,甚至可以使用卷积网络作为Encoder,用循环神经网络作为Decoder.
参考:
https://blog.csdn.net/u014453898/article/details/83303312