pandas处理Excel基本方法
学习总结主要参考了视频内容https://www.bilibili.com/video/BV1hk4y1C73S?p=2&vd_source=7771577bd8c0c69d43ee27a1c1ac8a1a
主要总结了使用pandas处理Excel表格,以及将Excel数据显示为图表。
1.用pandas创建一个Excel表格:使用to_excel('pandas1.xlsx')’创建
import pandas as pd
df = pd.DataFrame()
df.to_excel('pandas1.xlsx')
print('done!')
成功创建:

2.简单的往Excel加入数据:
import pandas as pd
zd = {
'id':[i for i in range(1,6)],
'name':['Jenny','Danny','Li Ming','Tim','Wang']
}
df = pd.DataFrame(zd)
df.to_excel('pandas1.xlsx')
print('done!')

3.选择某一列作为索引:df = df.set_index('id')
import pandas as pd
zd = {
'id': [i for i in range(1, 6)],
'name': ['Jenny', 'Danny', 'Li Ming', 'Tim', 'Wang']
}
df = pd.DataFrame(zd)
df = df.set_index('id')
df.to_excel('pandas1.xlsx')
print('done!')
4.打开Excel表格(openpyxl包需要安装好):
import pandas as pd
pd = pd.read_excel('Pandas_study.xlsx',engine='openpyxl')
print(pd.shape)
print(pd.index)
print(pd.columns)

5.查看表格前几行或者后几行:
import pandas as pd
pd = pd.read_excel('Pandas_study.xlsx',engine='openpyxl')
print(pd.head(3))
print(pd.tail(3))

6特殊情况:
情况1:第一行为脏数据,不需要:
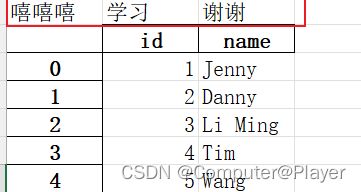
可以使用pd = pd.read_excel('pandas1.xlsx',engine='openpyxl',header=1)
import pandas as pd
pd = pd.read_excel('pandas1.xlsx',engine='openpyxl',header=1)
print(pd)
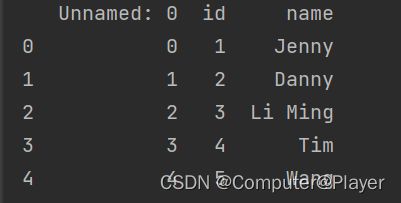
情况2:没有columns名字:
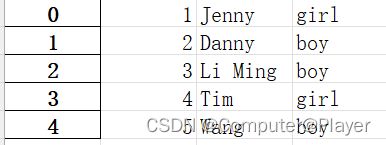
使用:pd = pd.read_excel('pandas1.xlsx',engine='openpyxl',header=None)

可以自己设置columns:
import pandas as pd
pd = pd.read_excel('pandas1.xlsx',engine='openpyxl',header=None)
print(pd)
pd.columns=['id','name','sex']
print(pd)

保存前你会发现左边的0-4是自动生成的index,保存也会加上,为了不要可以写成index=False:
import pandas as pd
pds = pd.read_excel('pandas1.xlsx', engine='openpyxl', header=None)
pds.columns = ['id', 'name', 'sex']
pds.to_excel('pandas2.xlsx', index=False)
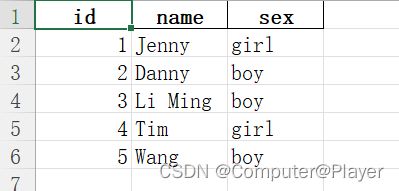
7读取文件把某行设置为index:
import pandas as pd
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl',index_col='id')
print(pds)

8行列单元格操作
import pandas as pd
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name='one')
s2 = pd.Series([11, 22, 33], index=[1, 2, 3], name='two')
s3 = pd.Series([41, 22, 83], index=[1, 2, 3], name='three')
s = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})
print(s)
s0 = pd.DataFrame([s1,s2,s3])
print(s0)
s0=s0.T
print(s0)

9.Excel表格特殊情况读取:

这种情况直接读取会有问题:pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
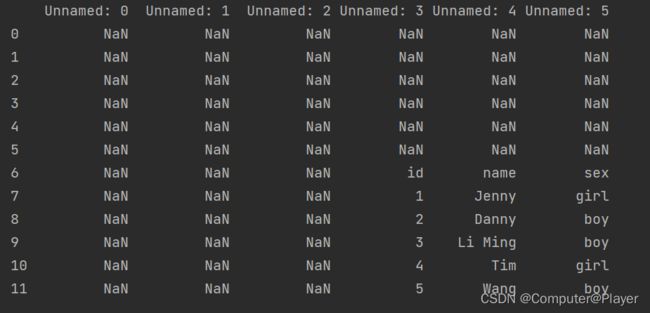
所以这种情况我们需要对读取文件进行设置:
import pandas as pd
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl',skiprows=7,usecols='D:F',index_col='id')
print(pds)

10.计算列:
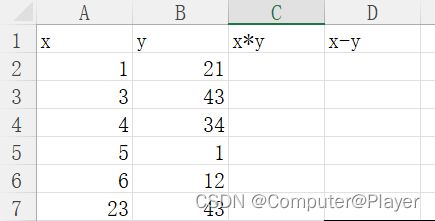
我们让C,D列进行计算,如下:
import pandas as pd
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
#方法一
pds['x*y']=pds['x']*pds['y']
#方法二,可以进行部分计算
for i in range(0,len(pds['x'])):
pds['x-y'].at[i]=pds['x'].at[i]-pds['y'].at[i]
print(pds)

可以把这些数据保存到Excel表格。
11.排序:

import pandas as pd
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds.sort_values(by='y',inplace=True,ascending=False)#ascending默认为True,从小到大排序,False为从大到小排序
print(pds)

12.apply()使用
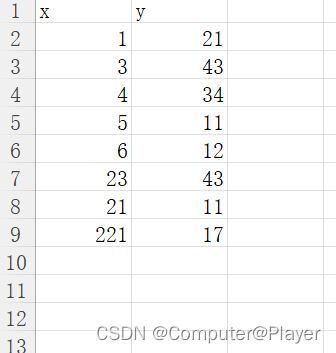
import pandas as pd
def num5_20(y):
return 5<y<20
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds = pds.loc[pds['y'].apply(num5_20)]
print(pds)
或者使用lambda表达式
import pandas as pd
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds = pds.loc[pds['y'].apply(lambda a: 5 < a < 20)]
print(pds)

13.Excel表数据展示柱状图:

import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
#方法一
pds.plot.bar(x='name',y='x')
#方法二
plt.bar(pds.name,pds.x)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
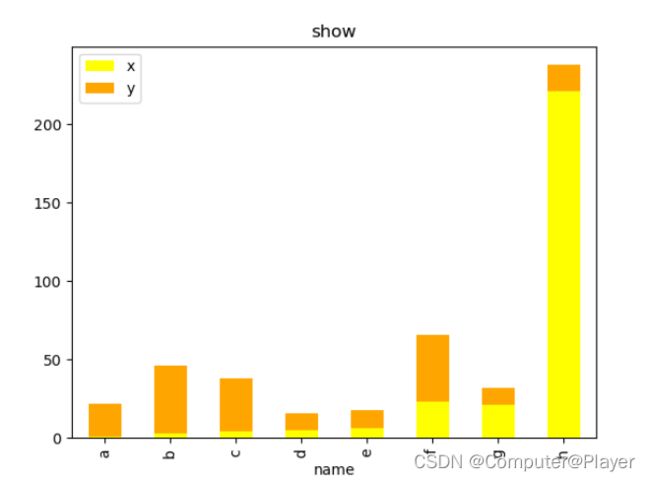
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds.plot.bar(x='name', y=['x', 'y'], color=['yellow', 'orange'], title='show')
plt.show()

使用stacked=True进行叠加:
import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds.plot.bar(x='name', y=['x', 'y'],stacked=True, color=['yellow', 'orange'], title='show')
plt.show()
转为水平的使用plot.barh
import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
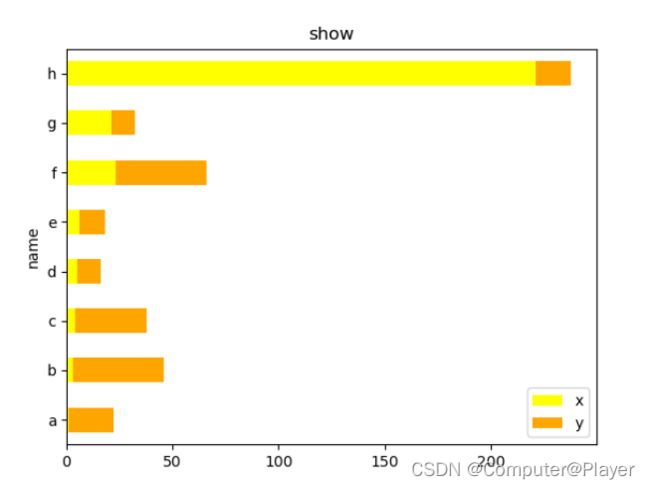
pds.plot.barh(x='name', y=['x', 'y'],stacked=True, color=['yellow', 'orange'], title='show')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl',index_col='name')
pds['x'].plot.pie(title='name_x',startangle=10,fontsize=6)
# pds.plot.barh(x='name', y=['x', 'y'],stacked=True, color=['yellow', 'orange'], title='show')
plt.show()

折线图:
import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl', index_col='name')
pds.plot(y=['x', 'y'])
plt.title('name-x-y', fontsize=12, fontweight='bold')
plt.show()

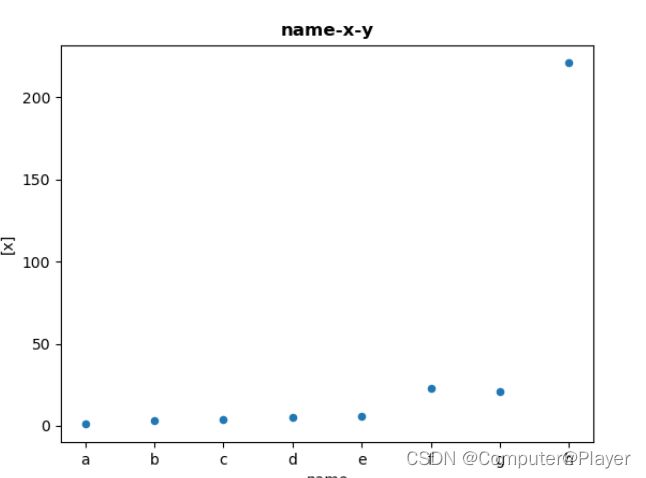
散点图:
import pandas as pd
import matplotlib.pyplot as plt
pds = pd.read_excel('pandas2.xlsx', engine='openpyxl')
pds.plot.scatter(x='name', y=['x'])
plt.title('name-x-y', fontsize=12, fontweight='bold')
plt.show()
14.相关系数函数corr()
series.corr(other[, method, min_periods])
用途:
检查两个变量之间变化趋势的方向以及程度,值范围-1到+1,0表示两个变量不相关,正值表示正相关,负值表示负相关,值越大相关性越强。
15.合并表格
有以下两个表格:


我们需要把表合并:merge()
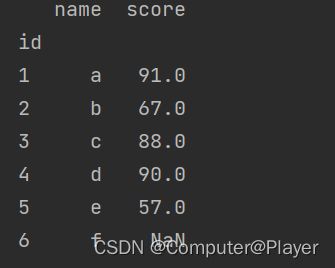
import pandas as pd
pds1 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='name',index_col='id')
pds2 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='score',index_col='id')
pds = pds1.merge(pds2,on='id')
print(pds)

我们发现少了一个学生,所以代码需要修改为:pds = pds1.merge(pds2, how='left', on='id')
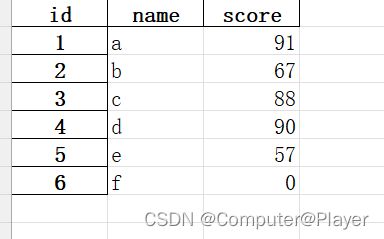
可以进行保存:
import pandas as pd
pds1 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='name', index_col='id')
pds2 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='score', index_col='id')
# pds = pds1.merge(pds2, how='left', on='id')
pds = pds1.merge(pds2, how='left', left_on='id', right_on='id').fillna(0)
pds.score = pds.score.astype('Int64')#或者(int)
pds.to_excel('pandas1.xlsx', sheet_name='name_score')
但我们会发现遇到一个问题,pandas1.xlsx被重写,只剩下name_score一个sheet中,原本的name,score没有了,只有最后一个存储的数据,并不符合我们的需求。解决方法如下:
import pandas as pd
pds1 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='name', index_col='id')
pds2 = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='score', index_col='id')
# pds = pds1.merge(pds2, how='left', on='id')
pds = pds1.merge(pds2, how='left', left_on='id', right_on='id').fillna(0)
pds.score = pds.score.astype('Int64')#或者(int)
writer = pd.ExcelWriter('pandas1.xlsx')
pds1.to_excel(writer, sheet_name='name')
pds2.to_excel(writer, sheet_name='score')
pds.to_excel(writer, sheet_name='name_score')
writer.save()

16数据校验
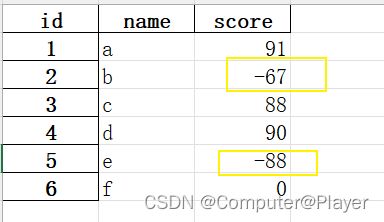
import pandas as pd
def score_test(row):
try:
assert 0 <= row.score <= 100
except:
print(row.rname, 'has a wrong score')
pds = pd.read_excel('pandas1.xlsx', engine='openpyxl', sheet_name='name_score', index_col='id')
pds.apply(score_test, axis=1) # axis=0为从上到下

axis 参数指定在 DataFrame 中应用特定方法或函数的方向。axis=0 代表函数是列式应用,axis=1 表示函数是行式应用在 DataFrame 上。
一个 DataFrame 对象有两个轴,分别是 “axis=0" 和 “axis=1“ ,“axis=0” 代表“跨行”,“axis=1“代表“跨列”,显而易见Series 与 DataFrame 共享相同的 “axis=0" 方向——它沿着跨行的方向。

不理解可以看:https://zhuanlan.zhihu.com/p/444973350