小白解读论文:Multi-Task Multi-Sensor Fusion for 3D Object Detection
1. 前言
先明白标题含义。Multi-Sensor指标定好的LiDAR-Camera系统。Multi-Task指3d和2d目标识别(侧重于车辆,2D and 3D box regression),路面检测(ground estimation),以及深度补(depth completion)。文章实验以3D目标检测为主。
流程图如下所示:

图1:整体流程图
流程图略显复杂。作者说他们的方法是双阶段的。大多数目标检测文章都是双阶段(不管它是单任务检测还是多任务检测)。第一个阶段得到一些粗糙的3d框,并提取ROI特征;第二个阶段利用这些ROI特征来优化这些3d框,得到最终的结果。为什么采用多任务的目标检测呢?大概是希望深度补全和地面检测获得的信息,能够对目标检测有所帮助吧。同时补全的深度图也能用于其他应用,比如三维重建。一举两得。本篇论文是基于Multi-Task的3d目标检测。为了便于理解,我先讲它的Single-Taks的目标检测,然后再扩展讲它的Multi-Task的目标检测。由浅入深吧。
2. 单任务的检测识别
单任务的检测识别的技术路线:
把LiDAR点云变成BEV图像。做点到点的特征融合Point-wise feature fusion(对应Dense Fusion),把RGB图的特征添加至BEV特征图中,更新了BEV图部分特征。使用更新后的BEV图像特征生成最初的3d框(对应3D Box Estimation)。筛选这些结果,得到一批较精细的3d框结果。再做ROI到ROI的特征融合ROI-wise feature fusion,把3d框分别投影在BEV图和RGB图上,通过ROIAlign技术,得到分别的ROI Feature。对BEV图上的ROI Feature做Rotate ROI Crop(对应Rotated ROI Crop)。最后把ROI Features拼在一起,放入FC层,回归出精细的2D框和3D框参数(对应2D&3D Regression)。具体细节将在下面交代。
吐槽:单任务检测的pipeline大概是作者2018年ECCV目标检测论文的延伸。但构思精巧。
2.1 BEV图像生成
文章没有直接处理点云,而是把它们转化为俯视图BEV。使用BEV图像来表示LiDAR点云。这么做的举动是希望把雷达点云当作图像来处理。考虑到雷达点云稀疏性,转换BEV的时候需要先对点云进行插值体素化(Voxel,类似于图像中的膨胀操作)。这样BEV图像会更加稠密,利于提取特征。BEV图可以用![]() 张量表示。
张量表示。
2.2 特征提取网络
提取RGB图像和BEV图像的网络分别是LiDAR Backbone Network和Image Backbone Network。LiDAR Backbone Network由四层残差块(Residue Block)和一层特征金字塔层(Feature pyramid network,简称FPN层)组成。每一个残差块由数量不等的残差层(Residue Layer)组成。FPN层的介绍可参考这个博客,由![]() 上采样,
上采样,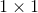 卷积层和向量拼接操作组成。Image Backbone Network由Res-18Net的前四个卷积模块(Convolutional Block)和FPN层组成。每个卷积模块由两个残差层(Residue Layer)构成。最终结果是获得RGB特征和BEV特征。这些特征的尺寸是原图像的
卷积层和向量拼接操作组成。Image Backbone Network由Res-18Net的前四个卷积模块(Convolutional Block)和FPN层组成。每个卷积模块由两个残差层(Residue Layer)构成。最终结果是获得RGB特征和BEV特征。这些特征的尺寸是原图像的![]() 倍。
倍。
2.3 点到点的特征融合
Point-wise feature fusion就是把RGB丰富的特征信息添加到BEV特征中,进而指导目标检测过程。对应图1中的Dense Fusion。作者画了图解释Dense Fusion,如图2所示。单纯从图上看,这个过程主要由Multi-scale Fusion和Continous Fusion组成。

图2:Dense Fusion图示
Multi-scale Fusion由FPN网络组成的。通过上采样和卷积,把不同尺度下的特征图合并为一个整体的特征,记为multi-scale features。该特征的前两个维度应该跟左边数第一个特征是一样的。Continous Fusion是借鉴了作者在ECCV2018发的文章思路。作者想用LiDAR点云建立multi-scale features和不同尺度下BEV特征图之间的关联。过程大概是这样的:遍历BEV特征图中有值的像素p,找到它在BEV图上的位置(缩放比),得到它在雷达坐标系下位置,在点云中找跟它最近的LiDAR点,两者距离记为d,把最近LiDAR点投影在RGB图像上,把投影后的像素按缩放比,找到它在multi-scale features下的位置,进而提取出对应![]() 特征向量。把距离和特征向量拼起来,得到
特征向量。把距离和特征向量拼起来,得到![]() 特征向量,把这个特征向量放在多层感知机中(Multi-Layer Perceptron,简称MLP),输出一个特征向量res,最后在BEV特征图中的p位置对应特征向量的末尾拼接上res。考虑到LiDAR点云稀疏,BEV特征图中有值的像素也是稀疏的,那么这样的Continous Fusion也是稀疏的,即只有少数区域添加了新的特征向量。作者说后续操作中有深度补全,补全后的深度可以生成更加稠密的伪LiDAR点云(pseudo LiDAR point),届时Continous Fusion会变得更为稠密。
特征向量,把这个特征向量放在多层感知机中(Multi-Layer Perceptron,简称MLP),输出一个特征向量res,最后在BEV特征图中的p位置对应特征向量的末尾拼接上res。考虑到LiDAR点云稀疏,BEV特征图中有值的像素也是稀疏的,那么这样的Continous Fusion也是稀疏的,即只有少数区域添加了新的特征向量。作者说后续操作中有深度补全,补全后的深度可以生成更加稠密的伪LiDAR点云(pseudo LiDAR point),届时Continous Fusion会变得更为稠密。
2.4 生成最初检测结果
3d框大致由9个变量组成(预测3d box的中心xyz和长宽高hwl和置信度score和类别class和y轴角度,九个变量)。把更新后的BEV特征送入一个的卷积核中得到![]() 的张量(用九个变量刻画一个3d框),即产生了
的张量(用九个变量刻画一个3d框),即产生了![]() 个候选3d框(proposal box)。对这一堆检测结果进行筛选,去掉置信度低的,去掉重叠框(非极大值抑制NMS),最后能得到一些高质量(High quality)的3d候选框。这是无Anchor的Proposal Region的常见生成方法之一。
个候选3d框(proposal box)。对这一堆检测结果进行筛选,去掉置信度低的,去掉重叠框(非极大值抑制NMS),最后能得到一些高质量(High quality)的3d候选框。这是无Anchor的Proposal Region的常见生成方法之一。
2.5 ROI到ROI的特征融合
ROI-wise feature fusion就是在ROI层面上做融合。把2.4节得到的3d候选框投影在BEV图像和RGB图像上,能够在这两种类型的图像上生成数个方框区域(Region of Interest,简称ROI)。ROI特征(ROI Feature)指ROI在放在Backbone Network中生成的特征,它可以由特征图在相应区域剪裁而成(Crop)。通俗地讲,它就是框框中的特征。ROI Feature可喂入全连接层(Fully Connected Layers,简称FC层),用于精细化回归2d框和3d框。考虑到直接把ROI Feature连接全连接层会有过多的学习参数,影响推断速度,早期目标检测方法使用ROIPooling技术(类似于池化的操作),把ROI Feature变成尺寸更小的张量。但是ROIPooling容易使小目标变得难以检测,因为小目标很容易被池化没了。所以自Mask-RCNN后,现在目标检测方法使用ROIAlign。ROIAlign使用双线性插值,可以保有更多局部信息。和ROIPooling一样,ROIAlign目的也是把ROI Feature变成尺寸更小的张量。相关知识可以参考 这个博客和另外一个博客的讲解。
理论上来说,使用ROIAlign技术可以得到RGB图像上的ROI特征,也能得到BEV图像上的ROI特征。但是BEV图下会出现一个问题。BEV图像的ROI特征可能会出现反转180度情况。讨论这篇论文的另外一篇博客也有所解释。毕竟我没做过这块还是小白,所以反转问题我就没太看懂(笑)。以后看懂了再做更新吧。反转问题也出现在其他文章中,比如Frustum PointNet和RTM3D中。不知道性质一不一样。简而言之,为了解决这个问题,作者把BEV图像上的ROI特征进行旋转(旋转之后,局部坐标系也要跟着变化),这是图1中Rotate ROI Crop的含义。
最终,RGB上和BEV上的ROI特征将拼接(Cat)形成Multi-Sensor ROI Feature。这个简单的拼接就是所谓的ROI到ROI的特征融合。Multi-Sensor ROI Feature将通过两个FC层,回归出精确的RGB图像上2D框和点云中的3D框。在图1总对应模块2D&3D Regression。
3. 多任务的检测识别
作者认为地面估计和深度补全会辅助3d目标识别。它们起到的作用各不相同。地面估计用来估计地面位置,然后计算出所有点云相对地面的坐标(canonicalize the LiDAR point clouds)。这样一来点云的Z值就是表示它的高度值。它不同类别的统计特征有利于3d目标检测,比如车的Z值在0.8~1.5米,人的Z值在1.5~1.8米。深度补全的作用是建立更加稠密的Point-wise feature fusion,它在2.3节就讲到了。
总结一下多任务的检测识别的技术路线:
通过地面估计(对应Ground Estimation)模块得到地面的位置,规范化点云坐标,进而得到规范化后的BEV图像。该规范化的BEV图像进入LiDAR Backbone Network得到新的特征。通过深度补全,得到稠密的深度图,进而得到伪LiDAR点云(对应Pesudo LiDAR point)。把伪LiDAR点云输入至Dense Fusion模块建立稠密Point-wise feature fusion,进而更新BEV图像特征。然后再做ROI-wise feature fusion,最后经过2D&3D Regression模块得到回归结果。
可见,多任务的目标检测算法是单任务算法的扩展而已。也是有意义的扩展。
3.1 地面估计
使用UNet模型估计地面点。输入是原始BEV图像。输出仅包含地面点的BEV图。作者在这一段讲到Mapping,感觉稍微有点扯哈。估计出地面之后,就可以得到点云相对于地面的高度(具有物理意义的高度值),然后更新BEV图,这是地面估计的作用,利于后续3d框检测。
3.2 深度补全
毕竟深度补全是个辅助性质的任务,所以这一块的网络搭建比较简单。根据雷达相机外参数,把LiDAR点云投影在成像平面上得到稀疏深度图。然后把稀疏深度图和RGB图绑在一起输入到Image Backbone Network中得到“复合的”特征,这个特征经过四层卷积和两层上采样,最后输出稠密深度图。稠密深度图生成Pseudo点云,用于建立更加稠密的Point-wise feature fusion,在第2.3节介绍了。题外话。这篇论文作者在ICCV2019发的深度补全论文“Learning joint 2d-3d representations for depth completion”很有参考价值。这篇论文的思想与这篇文章中contiouns fusion和他2018年ECCV的那篇文章有相同之处。
注释:contiouns fusion是个非常不错的idea。大佬用它发了ECCV2018,ICCV2019,和CVPR2019. contiouns fusion建立了雷达点云和相机图像之间的联系。
3.3 训练策略
这篇论文的损失函数比较直观:
![]()
 指目标分类的损失函数,使用的是二值交叉熵(binary cross entropy),用于分类车和非车。
指目标分类的损失函数,使用的是二值交叉熵(binary cross entropy),用于分类车和非车。 是3D box estimation模块的损失函数,
是3D box estimation模块的损失函数,![]() 是3D box refinement模块的损失函数,它们都是对
是3D box refinement模块的损失函数,它们都是对![]() 误差的Smooth L1范数。
误差的Smooth L1范数。![]() 是2D box refinement模块的损失函数,它是对
是2D box refinement模块的损失函数,它是对![]() 误差的Smooth L1范数。
误差的Smooth L1范数。![]() 是深度误差函数,使用的是L1范数。训练使用Adam optimizer,使用4个GPU。训练了50个Epoch。
是深度误差函数,使用的是L1范数。训练使用Adam optimizer,使用4个GPU。训练了50个Epoch。
4. 文章综述
文章综述也很不错。有两块值得注意。
Multi-sensor fusion for 3D detection。最近的方法诸如F-PointNet,MV3D,AVOD,和ContFuse。个人认为,ContFuse(contiouns fusion)对LiDAR稀疏数据很有益。可以读读这两篇论文:
(1)Ming Liang, Bin Yang, Shenlong Wang, and Raquel Urtasun. Deep continuous fusion for multi-sensor 3d object detection. In ECCV, 2018(作者那篇ECCV2018)
(2)Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep parametric continuous convolutional neural networks. In CVPR, 2018(跟图神经网络也很相似)
3D detection from multi-task learning。HDNET和SBNet分割路面辅助3d目标检测识别。Mono3D和Wang的方法使用语义分割辅助3d目标识别。深度补全对3d目标检测非常重要,可以读读这篇论文:
(3)Yun Chen, Bin Yang, Ming Liang, and Raquel Urtasun. Learning joint 2d-3d representations for depth completion. In ICCV 2019(作者那篇ICCV2019)
5. 结束语
设计基于LiDAR-camera系统的3d目标检测算法,应该首要考虑传感器的特性。LiDAR的特性是点云稀疏(Sparsity),而RGB图像是稠密的(Dense)。所以怎样融合这两种性质的传感数据是个关键问题。这篇论文采用的contiouns fusion技术和深度补全技术解决了这个问题。主流方法差不多都是使用ROI feature,这篇论文也不例外,但是它独特的网络设计技巧超越了那些方法。总之,这是篇不错的论文。