ECCV 2022 吊打MixUp和CutMix!MMLab&商汤提出TokenMix
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
本篇分享 ECCV 2022 论文『TokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers』,MMLab&商汤提出超强数据增强策略TokenMix!吊打MixUp和CutMix!
详细信息如下:

论文地址:https://arxiv.org/abs/2207.08409[1]
代码地址:https://github.com/Sense-X/TokenMix[2]
01
摘要
CutMix是一种流行的增强技术,通常用于训练现代卷积和Transformer视觉网络。它最初是为了鼓励卷积神经网络(CNN)更多地关注图像的全局上下文而不是局部信息,从而极大地提高了CNN的性能。然而,作者发现它对基于Transformer的结构的好处有限,这些结构自然具有全局感受野。
本文提出了一种新的数据增强技术TokenMix来提高视觉Transformer的性能。TokenMix通过将混合区域划分为多个独立的部分,在token级混合两幅图像。此外,作者还表明,CutMix中的混合学习目标,即一对ground truth标签的线性组合,可能是不准确的,有时甚至是违反直觉的。为了得到一个更合适的目标,作者提出了根据预训练的教师模型中两幅图像的基于内容的神经激活映射来分配目标分数。
通过在不同视觉Transformer架构上的大量实验表明,本文提出的TokenMix算法能够帮助视觉Transformer聚焦于前景区域来推断类别,并增强其对遮挡的鲁棒性,同时具有一致的性能提升。
02
Motivation
深度神经网络在视觉表征的学习中占据主导地位,并在各种下游任务中显示出有效性,包括图像分类、目标检测、语义分割等。为了进一步提高性能,引入了各种数据增强策略,包括手动创建的和自动搜索的。近年来,基于多幅图像混合的数据增强技术在各种视觉任务中表现出了令人印象深刻的性能。
这种“混合”图像的标签是基于它们的原始标签创建的。MixUp首次尝试通过样本对的线性组合生成混合训练样本。CutMix提出在区域级别上混合样本对,用目标图像中相应区域的内容来替换源图像中随机的局部矩形区域。此外,一系列工作试图通过更复杂的策略来改进CutMix,选择用于混合的矩形大小和位置。
一般而言,CutMix及其变体使用区域级剪切和粘贴混合技术来强制卷积神经网络(CNN)更多地关注图像的全局上下文,而不仅仅是局部信息。虽然CutMix增强也可以用于训练视觉转Transformer,但区域级别的混合策略变得不那么有效。作者回顾了CutMix增强的设计,并认为对于基于Transformer的体系结构来说,这是一种次优策略。
一方面,CutMix中的区域级混合在源图像中切割出一个矩形区域,并将内容混合到目标图像中。由于CNN主要是为编码局部图像内容而设计的,CutMix的区域级混合可以有效地防止CNN过度关注局部上下文。然而,对于自然具有来自第一层的全局感受野的基于Transformer的体系结构,区域级混合的益处较小。
另一方面,CutMix仅根据源图像和目标图像之间的裁剪面积比为增强图像分配混合标签,而不管其裁剪内容如何。然而,CutMix的切割区域和位置是随机选择的,并且无论切割内容是前景还是背景,都会分配相同的标签,这不可避免地将标签噪声引入学习目标,并导致不稳定的训练。
最近有一些工作试图通过仔细选择切割的显著区域或使用交替优化来确定切割区域来缓解这个问题。然而,由于显著区域可能与前景区域不正确对应,标签噪声问题仍有待研究。

在本文中,作者提出了token混合(TokenMix),这是一种token级增强技术,可以很好地应用于训练各种基于transformer的架构。与之前的方法不同,TokenMix在token级别直接混合两个图像,以促进输入token的交互,并在考虑图像语义信息的情况下生成更合理的目标。
首先,为了训练Transformer以更好地编码长程依赖,作者直接在token级别进行切割,并允许将切割区域分离为多个独立部分。因此,切割区域可以分布在整个图像中。token级混合鼓励transformer更好地编码长程依存关系,以正确分类包含增强token的混合图像。TokenMix中的所有混合token都随机确定为块,而不是依赖替代优化或额外网络来确定要混合的区域,这更容易用少量超参数实现。
此外,以前的方法通常将混合目标分配给增强图像,这等于源图像和目标图像的ground truth标签的线性组合。标签的线性组合比被确定为源图像的切割区域和目标图像的总大小之间的面积比。作者发现,此类目标分数可能非常不准确。如上图(a)所示,即使混合区域具有显著不同的语义,也会将相同的目标分配给这两种情况。
遵循蒸馏的精神,作者提出根据两个混合图像的基于内容的神经激活图将目标分数分配给增强的目标图像。具体来说,首先使用预训练的神经网络获得源图像和目标图像的神经激活图,该神经网络不需要完全训练。将两个混合区域的分数计算为空间归一化神经激活图的总和,并将其合并为最终目标。
直觉是,即使是部分训练的分类网络的神经激活图也可以比使用原始分数平均更好地定位对象的某些部分。在对神经激活图进行空间归一化后,具有丰富语义信息的区域将被分配高分,其他区域将被分配低分,从而产生更稳健的目标。神经激活图是离线生成的,因此引入的额外训练开销可以忽略不计(+0.8%)。
相反,DeiT中使用的蒸馏方法依赖于教师网络的在线推理从增强图像生成目标分数,而增强图像无法离线生成目标分数,因此几乎使训练时间加倍。作者提出的方法将切割区域的激活总结为图像级目标分数,并且不太可能受到单个token错误激活的影响。
实验表明,本文方法的结果目标更合理,这不仅提高了提出的TokenMix和原始CutMix的性能并稳定了训练。用本文的方法代替在CutMix中生成目标分数的方法,使用DeiT-S在ImageNet上获得了+0.7%的top-1精度增益。此外,由于生成的目标分数更利于学习,本文的方法具有更长的训练时间。具体来说,作者在使用DeiT-S的ImageNet上进行400个epoch的训练时,达到81.2%的top-1精度。
总之,本文的贡献如下:
提出了token混合(TokenMix),这是一种token级增强技术,可以很好地推广到各种基于transformer的架构中。
提出了使用基于内容的神经激活图来分配混合图像的目标分数,这对TokenMix和CutMix增强都有好处。
实验结果表明,TokenMix提高了transformer对图像内容的编码能力和对遮挡的鲁棒性。在ImageNet上,本文的方法将DeiT-S的top-1精度从79.8%提高到80.8%。
03
方法
在本节中,作者首先回顾了CutMix的一般过程,并说明了将CutMix应用于Transformer的局限性。然后,提出了TokenMix,它通过在token级别混合图像来进行图像增强,并用神经激活图分配目标分数。
3.1 Revisiting CutMix Augmentation
为了增强CNN的定位能力,CutMix提出将样本对与随机矩形二元掩码混合。和y分别表示训练图像及其标签。给定一对训练样本和,CutMix生成一个新的训练样本,如下所示:
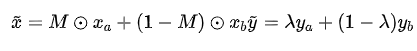
其中表示矩形掩码,⊙ 表示元素乘法,λ从β分布中采样。二进制掩码M是一个随机采样的矩形,这保证了。与Mixup类似,CutMix将生成图像的混合目标指定为和的线性组合。
作者认为CutMix中的区域级混合可能不适合基于Transformer的架构。由于CNN主要用于编码局部图像内容,使用CutMix进行训练可以有效防止CNN过度关注局部环境。然而,基于transformer的架构可能从CutMix中受益较少,因为其所有层都具有全局感受域。
此外,混合图像的标签是和的线性组合,混合比λ仅根据掩模的大小估计,这在许多情况下可能不合适。虽然最近有一些方法试图通过选择显著区域来最大化混合图像中的显著性来改进CutMix,但显著区域可能无法正确对应目标类别,并且标签噪声问题仍然严重。
3.2 TokenMix
在本文中,作者提出TokenMix来混合一对图像,以生成混合图像和学习目标。作者在token级别生成掩码M,以鼓励更好地学习长程依赖,并根据两个混合图像基于内容的神经激活图分配混合图像的目标分数,这符合蒸馏的一般精神,以创建更稳健的目标。

上图显示了本文提出的TokenMix的概述。作者首先将输入图像x划分为不重叠的patch,然后线性投影到视觉token。然后作者根据掩模输出比λ生成了一个随机掩码。按如下方式创建混合新训练样本:

其中表示所有token的集合,⊙表示逐元素乘法,表示掩码的第i个token,和分别是和的空间归一化神经激活映射的第i个token。神经激活图由预训练网络的最后一层在分类头之前生成。
作者将mask区域划分为多个分离的部分,而不是mask整个矩形区域。对于每个部分,作者随机选择掩码token牌的数量和纵横比。作者将token的最小数量设置为14,并在范围内对纵横比进行对数均匀采样。反复mask图像的一部分,直到被mask token的总数达到预定义的比率。作者将λ设置为0.5,而不是从β分布中采样λ。
本文的直觉是,与遮挡整个矩形区域相比,分布式遮挡区域更容易识别。为了便于研究,作者还引入了一致随机版本,其中每个掩蔽部分仅为单个token。虽然完全随机混合对CNN的性能有害,但作者表明,简化版本仍然有益于Transformer。
为了解决CutMix生成的目标分数不准确的问题,作者使用预训练教师网络生成的两个混合图像的基于内容的神经激活图来设置目标分数。直觉是,并非所有区域都对应于前景对象。
具体来说,语义信息丰富的区域比其他区域对目标分数的影响更大。受通过教师网络设置图像目标分数的蒸馏技术的启发,作者将设计扩展为通过组合两个混合图像的教师网络神经激活图来设置目标分数。如上图所示,将两个混合区域的目标分数计算为掩模内或掩模外的空间归一化神经激活图的总和。然后,作者将两个目标分数合并为混合图像的最终目标。
与之前的技术相比,本文提出的TokenMix有两个主要优点:
明确鼓励Transformer更好地编码长程依存关系,以正确分类图像和内部混合的其他图像。作者表明,当在各种视觉Transformer中使用时,本文的方法可以获得一致的精度增益,并且还增强了Transformer的遮挡鲁棒性。
使用基于内容的神经激活图生成的混合图像的目标标签比以前利用蒸馏技术的方法更具鲁棒性。此外,作者证明了本文的方法促进了Transformer更好地定位区分区域,并具有注意力权重。
04
实验
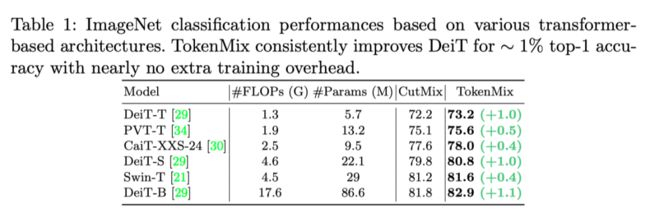
作者使用TokenMix在ImageNet-1K数据集上报告了结果。如上表所示,TokenMix在各种基于Transformer的架构(即DeiT、PVT、CaiT和Swin transformer)上持续改进了CutMix。

本文提出的TokenMix由两部分组成,即token级混合和标签细化。作者将这两部分解耦,然后通过固定一部分将其与以前的方法进行比较。在上表中,作者使用相同的数据增强方法将TokenMix与ReLabel和TokenLabeling进行了比较。

作者进一步将TokenMix与上表中以前基于混合的增强方法进行了比较。为了更公平的比较,只使用ImageNet中的标签。如上表所示,与其他方法相比,TokenMix具有性能优势。作者发现,引入更多前景区域的方法无法改善视觉Transformer上的CutMix。相反,本文提出的TokenMix提高了CutMix的精确度+0.5%。
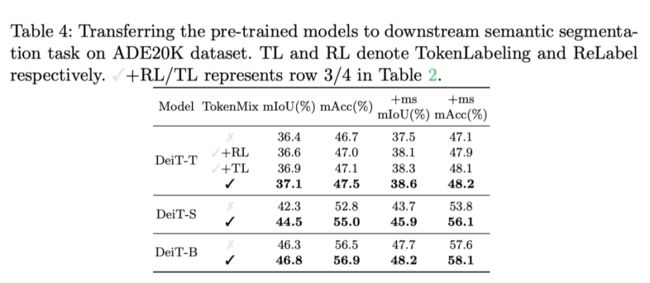
如上表所示,作者发现来自TokenMix的更好的预训练可以持续提高ADE20K数据集的分割性能。

CutMix基于混合图像对的标签的线性组合来分配混合图像的目标,如果剪切前景区域,这可能不准确。作者发现,不准确的标签使Transformer对输入图像的注意力不正确。如上图所示,使用CutMix会将Transformer的注意力转移到背景区域。相比之下,TokenMix帮助transformers学会更加关注前景领域,并带来一致的性能增益。

上图展示了示例图像和不同遮挡率下的预测置信度。图像下的红色分数由TokenMix预测,绿色分数由CutMix预测。当大量patch被丢弃时,用TokenMix训练的模型具有高置信度,而用CutMix训练的模型输出低置信度。

上图展示了ImageNet top-1 DeiT-S在不同下降率下的精度。使用CutMix训练的模型与使用TokenMix训练的模型之间的差距随着下降率的增加而增加。

上表展示了使用单一或随机抽样的多种混合方法之一训练DeiT-B的性能。

上表展示了用不同的方法生成激活图的结果。

上图为TokenMix和CutMix生成的目标分数。对于每个三元子图,左边是输入图像,中间是神经激活图,右边是mask图像。CutMix生成的分数以绿色显示,而红色分数由本文的方法生成。本文的方法生成的目标分数更合理,尤其是当前景被切割时。

为了测试本文提出的目标分数是否与CutMix兼容,作者进行了使用CutMix混合图像对的实验,但使用本文的方法生成目标,并使用各种主干进行训练,例如DeiT-S、Swin-T和ResNet50。如上表所示,本文方法在这些主干上实现了一致的性能提升。

上表和上图展示了不同mask采样策略的结果,可以看出基于block进行采样的能够达到更好的效果。

上表展示了在不同mask采样策略上进行标签细化的结果。可以看出基于block的策略通过标签细化获得更高的精度。

上表显示了长期训练的结果。由于教师网络的神经激活图生成的目标可以为训练Transformer提供更合适的分数和更具挑战性的样本,从而降低过拟合方案的风险,因此本文提出的TokenMix可以享受更长的训练时间。

由于混合图像可能包含不同类别的多个对象,作者采用二进制交叉熵(BCE)损失,而不是典型的交叉熵(CE)损失[35,2]。当使用提出的TokenMix进行训练时,使用BCE损失将DeiT-S的精度提高了+0.5%,因为剪切和粘贴操作可能会生成具有不同类别的多个对象的混合图像。
05
总结
在本文中,作者提出了token混合(TokenMix),这是一种token级增强策略,可以很好地推广到各种基于transformer的架构中。TokenMix的动机是两个关键观察结果:1)区域级混合对基于Transformer的架构不太有利,2)使用线性组合分配混合图像的目标可能不准确,甚至违反直觉。
作者提出的TokenMix直接在token级别进行切割,并使用基于内容的神经激活映射获得混合图像的目标。实验结果表明,TokenMix具有增强遮挡鲁棒性和帮助视觉Transformer聚焦输入图像前景区域的特性。此外,TokenMix不断改进各种基于transformer的架构,包括DeiT、PVT和Swin transformer。
参考资料
[1]https://arxiv.org/abs/2207.08409
[2]https://github.com/Sense-X/TokenMix
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
