课程向:深度学习与人类语言处理 ——李宏毅,2020 (P20)
BERT and its family:Introduction and Fine-tune
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
深度学习与人类语言处理 P20 系列文章目录
- BERT and its family:Introduction and Fine-tune
- 前言
- I How to pre-train
-
- 1.1 CoVe
- 1.2 Self-supervised
- 1.3 Next Token
-
- 1.3.1 LSTM
- 1.3.2 Self-attention
- 1.3.3 Flaw
- II BERT
-
- 2.1 Mask
- 2.2 CBOW -> BERT
- 2.3 Masking methods
- 2.4 SpanBert
- III XLNet
- IV MASS/BART
- V UniLM
- VI ELECTRA
- VII Sentence Level
-
- 7.1 Skip Thought & Quick Thought
- 7.2 NSP & SOP
- 7.3 T5 & C4
前言
上篇中(P18)我们对经典伟大的语言模型进行了概述总结
而在本篇中,我们将继续讲解以 BERT 为代表的语言模型,进行介绍以及模型的微调,文章将从三个方面讲解:
1 What is pre-train model (P19)
2 How to fine-tune (P19)
3 How to pre-train (P20)
本篇将讲解 预训练模型有关概念与技术:从BERT、XLNet、MASS/BART、UniLM 到 ELECTRA
过去,在NLP领域通常是一个任务一个模型,但今天已经逐渐迈向希望模型先了解普遍的语言,再去解各式各样的NLP任务。
I How to pre-train
1.1 CoVe
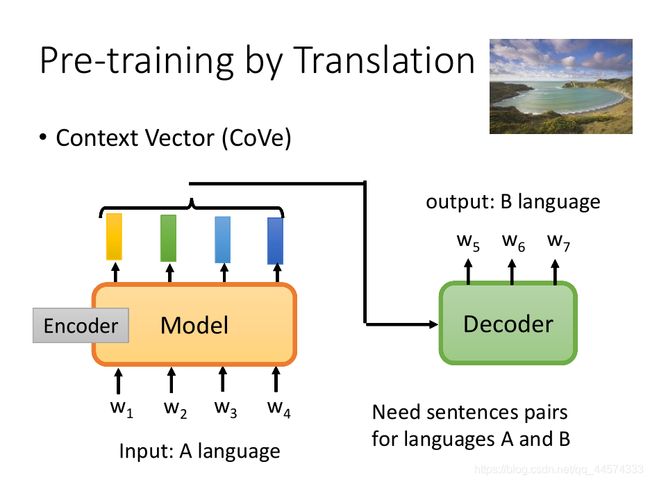
上篇假设已经有了预训练模型,我们已经讲过怎么把这个预训练模型Fine-tune到各式各样的任务上。那怎样才能训练得到这个预训练模型呢?
老师可以找到相关的最早的文献资料便是CoVe,Contexyt Vector,如上图,这种预训练模型可以训练得到与上下文相关的词向量embedding。CoVe是在通过翻译任务训练得到这个预训练模型的。首先收集到翻译的数据对 语言A的句子与对应语言B的句子,将语言A句当作模型Model的输入,而这个Model做的就是Encoder的事,将语言A句中的每个token都编码成一个向量表示,再将这个向量表示丢给Decoder部分,输出对应语言B句的token sequence。在翻译任务训练结束后,将模型Model取出,便是语言A的与上下文相关的预训练模型了。
值得注意的是,CoVe选用的是Translation 翻译任务训练得到预训练模型的,而不是其他NLP任务。这个任务选择是一定道理的,翻译任务可以做到输入句A句中每一个token都有被考虑到,才能去输出对应翻译句B。而如果选用的是Summarization 摘要这种任务,找出重要的词汇并无视那些不重要的词汇,模型Encoder很有可能会将所有不重要的token都输出一个“不重要”的embedding表示,这样的话模型可能就没有办法学到每一个token的embedding表示。
但是,用Translation 翻译这样的任务是需要大量的pair data,成对的翻译资料才有办法训练得到这样的模型。而收集大量的成对训练资料还是非常困难的,所以我们期待的是通过没有标注的文字就直接去训练出一个预训练模型。
1.2 Self-supervised

通过无标注的文本数据去训练模型的方法通常被叫做“unsupervised learning”无监督学习,但Yann LeCun表示这个词汇是有一定欺骗性和迷惑性的,便改称“self-supervised learning”自监督学习。
Self-supervised learning,就是指模型学会从输入的一部分去预测其余的输入。换句话说,输入的一部分被用作一个监督信号,该输入的其余部分作为反馈。
而对于模型而言,如上图,
- 上图下面左侧的是Supervised,有监督学习,模型需要学会如果通过x预测y,其中y被称为label标签,这个是需要人为标注的。
- 上图下面右侧的是Self-supervised,自监督学习,模型需要学会通过输入的一部分 x ′ x^{'} x′去预测输入的其余部分 x ′ ′ x^{''} x′′,而 x ′ + x ′ ′ = x x^{'}+x^{''} = x x′+x′′=x
那怎么通过无标注数据制造这种输入和输出的关系呢,也就是 x ′ − > x ′ ′ x^{'} -> x^{''} x′−>x′′。
1.3 Next Token

对于文本而言,最经典的做法就是给一个sequence预测下一个token,具体训练过程如上图。
在模型输入w1,得到h1时,将h1通过Linear Transform与softmax后得到每一个token的概率分布,其中概率最大的token为预测的token,而训练时就是最小化这个概率分布与真实的下一个token的CrossEntropy。得到w2,再将其输入到模型中,同样的计算流程预测得到w3,依次预测训练结束。
需要注意的是,这个输出embedding的模型不能随意使用可以考虑全部输入部分的模型,如attention,在训练时,我们是将w1-w4这一串sequence输入到模型中,我们希望的是w1预测w2,w1+w2预测w3,w1+w2+w3预测w4,这样在预测w2时是不能让模型看到w2的,因为如果可以看到的话,模型Encode很有可能学会的就是,将w2的表示作为w1的embedding,依次把下一个token的表示作为上一个token的embedding,这样的Encode就像是作弊一样,学不到什么。因此,如上图所示,在w1作为输入时模型是绝不能看到w2的,w1和w2作为输入时模型时绝不能看到w3的…
像这样预测下一个token是最早的Self-supervised Model所使用的技巧,这也是非常自然的,在过去NLP领域的人就知道要训练语言模型,而语言模型本来做的就是预测下一个token,所以本篇讲的这些预训练模型就是语言模型。
那该用什么样的架构来训练这个语言模型,来预测下一个token呢?
1.3.1 LSTM

最早使用的便是LSTM,在这些使用LSTM训练语言模型中最知名的便是ELMo。
1.3.2 Self-attention

而今天人们不再选用LSTM,很多时候会把LSTM换为self-attention,并加入一定attention限制,就如上面所讲的不能让模型看到要预测的下一个token。
1.3.3 Flaw
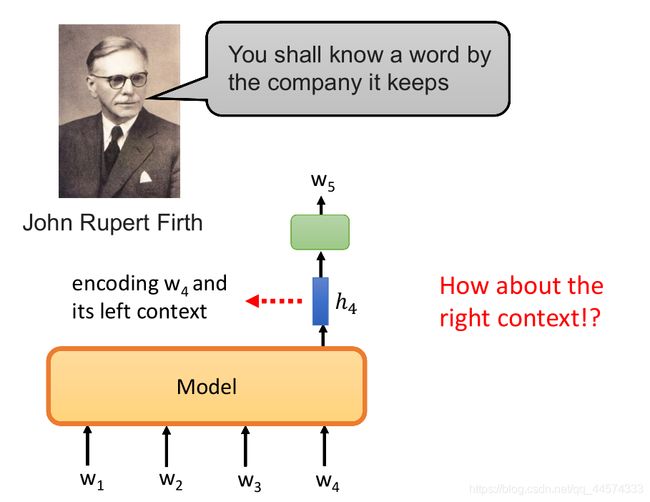
You shall know a word by the company it keeps —— John Rupert Firth
了解一个词的词义,要看常常和它一起出现,和它相邻的词
上面所讲的预测下一个token的模型方法,都存在这样一个问题,在预测下一个token时,模型仅仅考虑到了这个token左侧的部分,而右侧的信息都被忽略了。

ELMo这篇论文确实考虑了看右侧信息的问题,如上图所示,比如在预测w5时,我们会通过正向LSTM处理w1-w4,除此之外,还会通过反向LSTM处理w7-w5去预测w4。会将正反方向的LSTM得到的向量组合起来作为embedding输出。
这样左边的文本也考虑到了,右边的文本也被考虑到了,那这样就可以了吗?这还不够,因为在模型考虑左边的文本时它是看不到右边的文本的,同样在考虑右边的文本时是看不到左边的文本的,所以模型在考虑句子时是不完整的,只一半一半的看,正向的LSTM和反向的是没有交汇的。
那能够实现考虑整句后再预测token么?BERT就可以实现。
II BERT
2.1 Mask
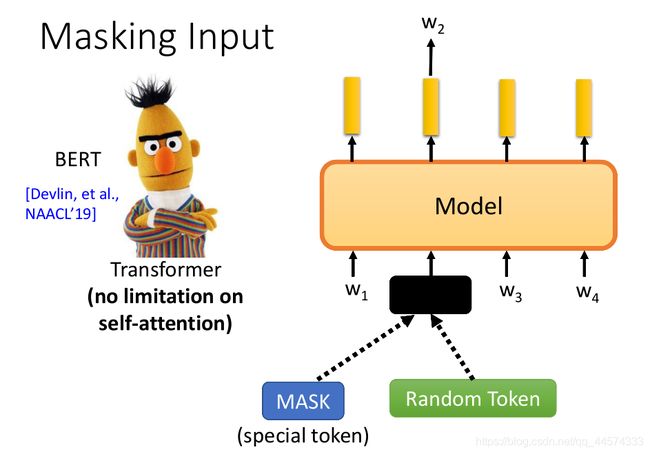
BERT不再是预测next token,而是随机Mask掉一些token或者用其他随机token去替换,通过剩余的token去预测这个被Mask掉的或者替换掉的token。这样self-attention就没有任何限制了,也就是每一个token都可以attend到所有的token,如上图,在预测w2可以看到全部的token。
2.2 CBOW -> BERT
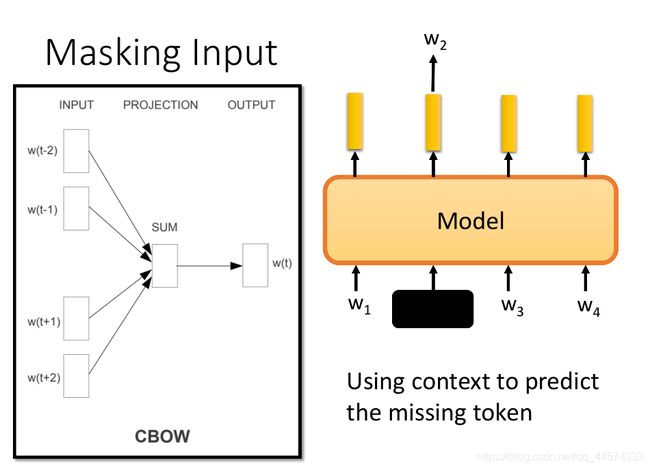
其实回溯历史,其实BERT这个想法与Word2vec中的CBOW很像,对于CBOW,我们会根据window里上文几个token和下文同样多token来预测中间的token,而对于BERT其实不过是将window无限化,上文可以任意长,可以从头看到此,下文也一样,可以从尾看到此。模型的思想大同小异,只是模型的复杂程度不同。
2.3 Masking methods

在原始的BERT里面,要MASK掉的token就是随即决定的,但是随机决定MASK的token好么?也许不够好,如在中文任务中,一个token通常就是一个字,而往往把一个字盖起来,从这个字的附近可以较容易地预测到这个字的,如“黑[MASK]江”,是很容易猜到这个MASK的是“龙”这个字的,此时模型都不需要看其余部分了。
所以盖起来一个token,模型很可能只会考虑左右几个token就够了,根本学不到特别长的dependency依赖关系,只看左右一些就结束了。所以怎么办呢?就有一些比较复杂的Masking方法:
-
WWM(Whole Word Masking):一次盖住一整个词汇,示例如上图。
-
Phrase-level & Entity-level:一次盖住好几个词汇(连续的几个词汇组成Phrase段)或盖住实体(NER可得到实体,如人名、地名),这就是ERNIE所做的。
2.4 SpanBert

还有一种Masking方法就是SpanBert,一次MASK很长的范围,至于一次盖多少个token是按照一定概率选择的,如上图一个盖一个token的概率大约是23%,10个token的概率大约是3%。
SpanBert论文中还统计了各式MASK方式在不同任务上的效果,如上表。
除此之外,SpanBert中还提出了一种训练方法,叫做SBO

一般MASK盖后,我们要做的只是把盖住的部分预测回来,SBO希望根据被盖住部分左右两边的embedding去预测被盖住范围内有什么样的东西。
举例而言,如上图,我们将 w 3 , w 8 w_3,w_8 w3,w8的embedding输入给SBO,以及数字3也作为输入,希望SBO能够输出盖住部分的第三个,也就是 w 6 w_6 w6。
这种做法是希望,一个部分左右两边的token的embedding可以包含这个部分,一个span前后两边包含了整个span的讯息,具体会留在coreference指代关系里讲。
III XLNet

XLNet中的XL指的是 Transformer-XL,也就是模型内部用的不是一般的Transformer,而是Transformer-XL,它可以跨段读取资讯,可以有相对位置编码等,这些与预训练模型无关,老师没再细讲。
XLNet也是红极一时,没有那么好懂,详细的数学式请参见原始论文。XLNet觉得BERT存在这样的一个问题,假如给出“This is New York City”,原来的BERT总是把New York一起盖住,就没有办法让模型学到由New去预测York,以及根据York去预测New,被盖住部分的这两个词是独立的,没有相关性的一个一个被预测出来。但老师在此不太认同这种观点,在BERT里面随机盖住的时候,是有可能仅仅盖住“New”或“York",此时两个词汇间就有相关性。
XLNet大致的概念就是乱序语言模型,如上图,一般而言,无论是BERT还是其他语言模型,都不会改变原始语言的句子内词序,而在XLNet中将随机打乱词序,再MASK预测,如”习度学[深]“预测”深“,而在实现时不需要打乱词序就可以做到这样的效果,如上图,可以让attention只看一部分,比如度和习就要预测学。以及它不会给模型看MASK 这个token,只不过还是会告诉模型我们要预测的token是输入部分的第几个token,这样做是因为具体NLP任务数据中是没有MASK这个特殊的token的。
IV MASS/BART
不过像BERT这样的语言模型其实是”不善言辞“的,也就是说它并不擅长做生成式句子的产生。对于传统的语言模型,它是容易产生句子,因为在训练的过程中,就根据一整个句子的前一部分去预测next token,依次预测最终得到一整个句子。而BERT是会看整个句子,MASK掉其中的一部分,通过整个句子的其余部分去预测MASK掉的,因此,称BERT是不善言辞的。不过这些讨论都只局限在autoregressive model自回归模型,即在生成句子时是由左及右的依次生成的。下次会讲non-autoregressive model不需要由左及右的依次生成sequence,这种情况下BERT可能就善于言辞了。
不过以下的讨论,我们都假设只局限在autoregressive model自回归模型 情况下,此时BERT是不善言辞的。

所以假设我们要解的是seq2seq模型的NLP任务,BERT只能当作Encoder,Decoder的部分是没办法pre-train到,那有没有办法可以pre-train一整个seq2seq模型呢?是有办法的。
此时的训练目标就是Reconstruct重构输入序列,如上图,也就是输入给模型一串sequence, w 1 , w 2 , w 3 , w 4 w_1,w_2,w_3,w_4 w1,w2,w3,w4,模型首先encode,再做attention,丢到decode里同样输出 w 1 , w 2 , w 3 , w 4 w_1,w_2,w_3,w_4 w1,w2,w3,w4。在此,一定要把输入序列做某种程度的破坏,如果输入序列没有任何破坏,这个seq2seq模型学不到任何东西,只要原样输出即可了。
哪有什么破坏的方法呢?这里有两种做法,1 MASS,2 BART

对输入序列具体的破坏方法有如下几种方法:
- MASS:MASS的想法和原来的BERT相像,将输入序列的一个token用MASS(其实就是MASK)盖住
- Delete:将输入序列的某个token删除掉
- permutation:对输入序列中包含的多个句子进行句子顺序的打乱,如AB [SEP] CDE改为CDE [SEP] AB
- rotation:将输入序列某些放到尾部的东西拿到前面来,改变输入序列的起始部分,把ABCDE 改为 DEABC
- Text Infilling:会在输入序列里面加入MASK,一种是随机插入,比如将ABCDE改为AB[MASK]CDE,另一种是只加一个MASK,但其实MASK掉了几个token,比如将ABCDE改为AB[MASK]E
在BART这篇论文中,也进行了上述Corruption的实验,最后的实验结论是,permutation和rotation的效果并不好,但Text Infilling效果最好。
V UniLM
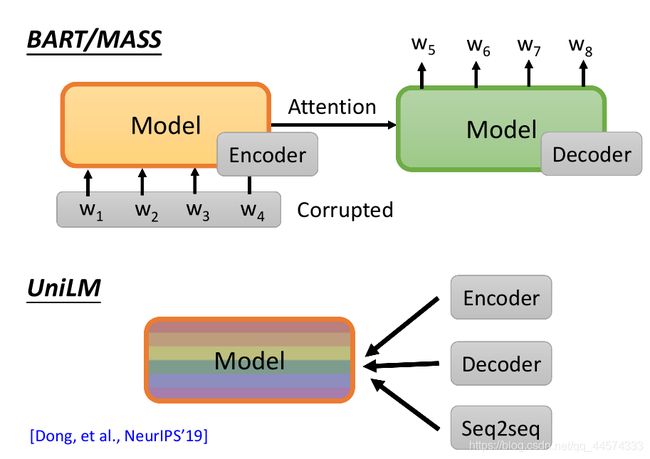
还有一个神奇的模型,UniLM,这个模型既是Encoder,又是Decoder,还是一个Seq2seq模型。那这个UniLM是怎么运作的呢?如下图。

UniLM只有一个模型,它不切分出Encoder和Decoder部分,这个模型同时进行三种训练:
- 第一种训练:和BERT一样,把一些token MASK起来,预测MASK的token
- 第二种训练:同时也做GPT的训练,把它当作语言模型来用,强制模型只能attend左边的token
- 第三种训练:也可以当作seq2seq模型使用,把输入序列分成两个部分,输入第一部分时,第一部分的token可以互相attend,互相做self-attention,相当于Encoder,但第二部分的sequence输入时,它只能attend到左边的部分,相当于Decoder。
VI ELECTRA
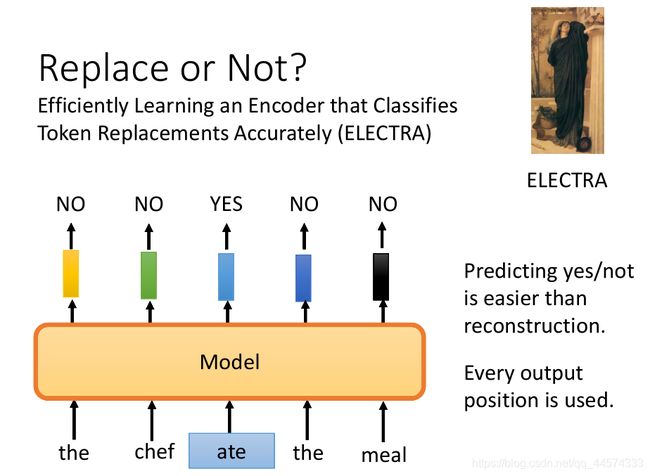
到目前为止,所讲的预训练模型都是要预测token,下一个token或者被盖住的token。但是有没有其他做法呢?其实预测一个token需要的运算量是很大的,有这样一个方法可以避开需要预测需要生成东西,ELECTRA。
相较于预测token,ELECTRA不做预测,只回答二分类的问题,对于输入序列的某些token,不进行MASK,而是置换成其他词汇,接下来,ELECTRA要做的就是判断输入序列中token哪一个被替换了。
这样做的好处有 1 预测Yes/No比reconstruction重构更简单,2 每一个位置都有一定的反馈,在类似BERT中没有被MASK部分的token输出什么就不管了。
此时,问题来了,怎么置换出文法上没有错,语义上改变的句子呢?

如果置换的词是一些奇奇怪怪的词,这样是很容易被判断出来的,ELECTRA就学不到什么有用的东西,所以怎么办呢?
用了另外一个比较小的BERT去预测这个替换词,将需要被替换的词MASK起来,将BERT预测的输出填到替换词位置,让ELECTRA去判断哪个词是由BERT预测得到然后替换而来的。这种方法有点像GAN,这个BERT不需要训练的很好,希望它预测的会有点错。但其实也不能被称为GAN,因为如果是GAN的话,在训练时是希望这个小BERT去骗过ELECTRA的,但显然这不是我们的训练目标。这个小BERT就是自己玩自己的。
VII Sentence Level
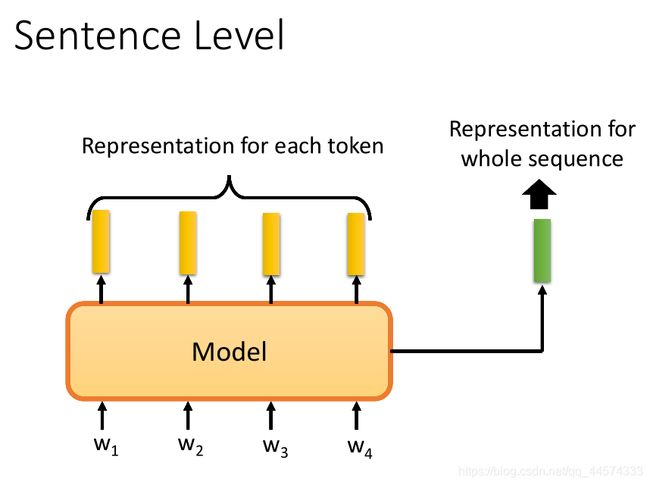
到目前为止,我们讲的技术都是给每一个token一个embedding,但有时候我们要做的不是给每一个token一个embedding,而是给整个sequence一个整体的embedding,用这个embedding来表示这个sequence。那怎么产生sentence embedding呢?
7.1 Skip Thought & Quick Thought

有两种方式:
- Skip Thought:通过Encoder编码输入序列 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3得到一个embedding表示,再将这个embedding输入给Decoder预测生成下一句的序列 w 4 , w 5 , w 6 , w 7 w_4,w_5,w_6,w_7 w4,w5,w6,w7。通过这种方式训练得到的sentence embedding将会得到 如果两个句子后接的句子一样,那么这两个句子的embedding就类似。
- Quick Thought:进阶版,有两个句子,各自通过Encoder得到embedding,如果这两个句子是相邻的,那这两个embedding的距离越小越好。如果这两个句子是不相邻的,这两个embedding的距离越大越好。这样就避开了生成的问题。
7.2 NSP & SOP
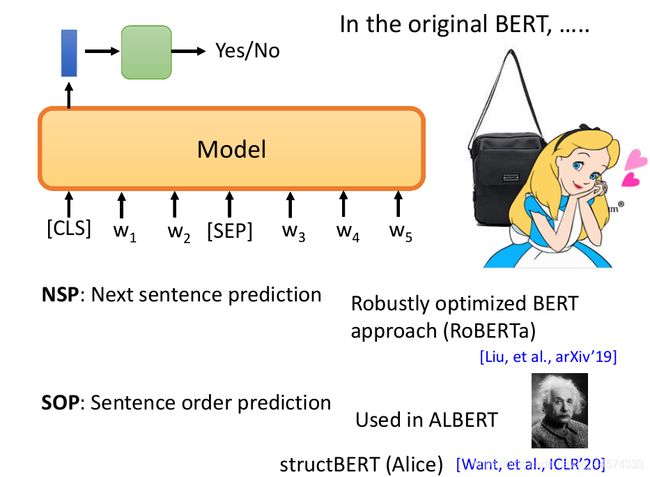
在原始BERT中,会在句子的开头加[CLS],之后再根据这个特殊token的embedding判断整个句子的类别。
NSP:根据[CLS]的embedding,在BERT中判断两个句子是否相接。 RoBERTa、XLNet、SpanBERT这些文章也说到NSP结果没有很好,没什么用。
SOP:给机器两个本来相接的句子颠倒过来,让机器去判断是否颠倒。
7.3 T5 & C4

讲了如此多的预训练模型,究竟哪一种模型好呢?T5就是Google将收集到的所有预训练模型收集起来,进行实现统计,用的数据是C4,具体文献40多页这个就请大家自己研读。
至此,BERT、XLNet、MASS/BART、UniLM、 ELECTRA等预训练模型有关的概念与技术到此结束。