多语言机器翻译 | (1)多语言翻译模型简介
摘录自 机器翻译 基础与模型 东北大学
低资源机器翻译面临的主要挑战是缺乏大规模高质量的双语数据。这个问题往往伴随着多语言的翻译任务[1]。也就是,要同时开发多个不同语言之间的机器翻译系统,其中少部分语言是富资源语言,而其它语言是低资源语言。针对低资源语言双语数据稀少或者缺失的情况,一种常见的思路是利用富资源语言的数据或者系统帮助低资源机器翻译系统。这也构成了多语言翻译的思想,并延伸出大量的研究工作,其中有三个典型研究方向:基于枢轴语言的方法[2]、基于知识蒸馏的方法[3]、基于迁移学习的方法[4,5],下面进行介绍。
文章目录
-
-
- 1. 基于枢轴语言的方法
- 2. 基于知识蒸馏的方法
- 3. 基于迁移学习的方法
-
- 3.1 参数初始化方法
- 3.2 多语言单模型系统
- 4. 参考文献
-
1. 基于枢轴语言的方法
传统的多语言翻译中,广泛使用的是基于枢轴语言的翻译(Pivot-based Translation) [2,5]. 这种方法会使用一种数据丰富的语言作为枢轴语言(Pivot Language)。翻译过程分为两个阶段:源语言到枢轴语言的翻译,枢轴语言到目标语言的翻译。这样,通过资源丰富的枢轴语言将源语言和目标语言桥接在一起,达到解决源语言-目标语双语数据缺乏的问题。比如,想要得到泰语到波兰语的翻译,可以通过英语做枢轴语言。通过“泰语 → 英语 → 波兰语”的翻译过程完成泰语到波兰语的转换。
在统计机器翻译中,有很多基于枢轴语言的方法[6,7,8,9], 这些方法也已经广泛用于低资源翻译任务[2, 10,11, 12]。由于基于枢轴语言的方法与模型结构无关,这些方法也适用于神经机器翻译,并且取得了不错的效果[5, 13]。
基于枢轴语言的方法可以被描述为如图16.11所示的过程。这里,使用虚线表示具有双语平行语料库的语言对,并使用带有箭头的实线表示翻译方向,令 x、y 和 p 分别表示源语言、目标语言和枢轴语言,对于输入源语言句子 x 和目标语言句子 y,其翻译过程可以被建模为:
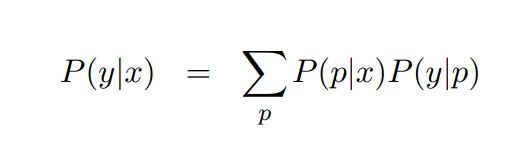
其中,p表示一个枢轴语言句子。 P(p|x) 和 P(y|p)的求解可以直接复用既有的模型和方法。不过,枚举所有的枢轴语言句子 p 是不可行的。因此一部分研究工作也探 讨了如何选择有效的路径,从 x 经过少量 p 到达 y [14]。
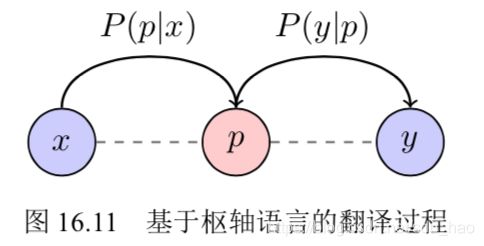
虽然基于枢轴语言的方法简单且易于实现,但该方法也有一些不足。例如,它需 要两次翻译,时间开销较大。而且在两次翻译中,翻译错误会进行累积从而产生错 误传播问题,导致模型翻译准确性降低。此外,基于枢轴语言的方法仍然假设源语 言和枢轴语言(或者目标语言和枢轴语言)之间存在一定规模的双语平行数据,但 是这个假设在很多情况下并不成立。比如,对于一些资源极度稀缺的语言,其到英 语或者汉语的双语数据仍然十分匮乏,这时使用基于枢轴语言的方法的效果往往也 并不理想。虽然存在以上问题,基于枢轴语言的方法仍然受到工业界的青睐,很多 在线翻译引擎也在大量使用这种方法进行多语言的翻译。
2. 基于知识蒸馏的方法
为了缓解基于枢轴语言的方法中存在的错误传播等问题,可以采用基于知识蒸馏的方法[3, 15]. 知识蒸馏是一种常用的模型压缩方法[16], 针对低资源翻译任务,基于教师-学生框架的方法基本思想如图16.12所示。其中,虚线表示具有平行语料库的语言对,带有箭头的实线表示翻译方向。这里,将枢轴语言 p 到目标语言y的的翻译模型 P(y|p)当作教 师模型,源语言 x 到目标语言y的翻译模型P(y|x)当作学生模型。然后,用教师模型来指导学生模型的训练, 这个过程中学习的目标就是让P(y|x)尽可能接近P(y|p), 这样学生模型就可以学习到源语言到目标语言的翻译知识. 举个例子,假设 图16.12中 x 为源语言德语"hallo", p为中间语言英语"hello", y 为目标语言法语"bonjour", 则德语“hallo”翻译为法语“bonjour”的概率应该与英语“hello”翻译 为法语“bonjour”的概率相近。
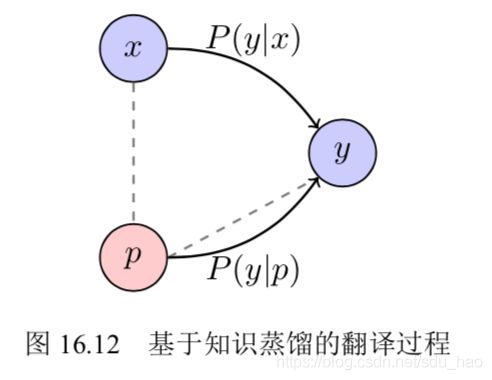
需要注意的是,基于知识蒸馏的方法基于一个假设:如果源语言句子 x、枢轴语言句子 p 和目标语言句子 y 这三者互译,则 P (y|x) 应接近 P (y|p),即:

和基于枢轴语言的方法相比,基于知识蒸馏的方法无需训练源语言到枢轴语言 的翻译模型,也就无需经历两次翻译过程。不过,基于知识蒸馏的方法仍然需要显性 地使用枢轴语言进行桥接,因此仍然面临着“源语言 → 枢轴语言 → 目标语言”转 换中信息丢失的问题。比如,当枢轴语言到目标语言翻译效果较差时,由于教师模 型无法提供准确的指导,学生模型也无法取得很好的学习效果。
3. 基于迁移学习的方法
迁移学习(Transfer Learning)是一种机器学习的方法,指的是一个预训练的模型 被重新用在另一个任务中,而并不是从头训练一个新的模型 [16]。迁移学习的目标是 将某个领域或任务上学习到的知识应用到新的领域或问题中。在机器翻译中,可以 用富资源语言的知识来改进低资源语言上的机器翻译性能,也就是将富资源语言中 的知识迁移到低资源语言中。
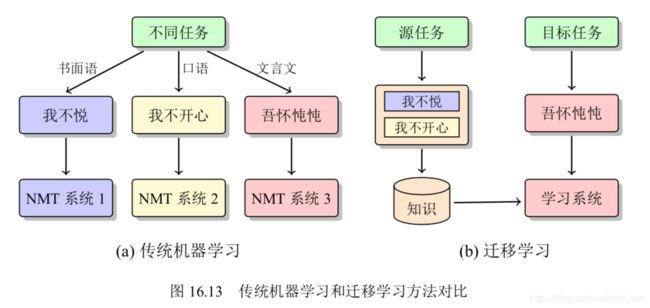
基于枢轴语言的方法需要显性地建立“源语言 → 枢轴语言 → 目标语言”的路 径。这时,如果路径中某处出现了问题,就会成为整个路径的瓶颈。如果使用多个枢 轴语言,这个问题就会更加严重。不同于基于枢轴语言的方法,迁移学习无需进行 两次翻译,也就避免了翻译路径中错误累积的问题。如图16.13所示,迁移学习将所有任务分类为源任务和目标任务,目标是将源任务中的知识迁移到目标任务当中。
3.1 参数初始化方法
在解决多语言翻译问题时,首先需要在富资源语言上训练一个翻译模型,将其 称之为父模型(Parent Model)。在对父模型的参数进行初始化的基础上,训练低资 源语言的翻译模型,称之为子模型(Child Model),这意味着低资源翻译模型将不会 从随机初始化的参数开始学习,而是从父模型的参数开始[17, 18, 19]。这时,也可以把 参数初始化过程看作是迁移学习。在图16.14中,左侧模型为父模型,右侧模型为子 模型。这里假设从英语到汉语的翻译为富资源翻译,从英语到西班牙语的翻译为低 资源翻译,则首先用英中双语平行语料库训练出一个父模型,之后再用英语到西班 牙语的数据在父模型上微调得到子模型,这个子模型即为迁移学习的模型。此过程 可以看作是在富资源语言训练模型上使用低资源语言的数据进行微调,将富资源语 言中的知识迁移到低资源语言中,从而提升低资源语言的模型性能。
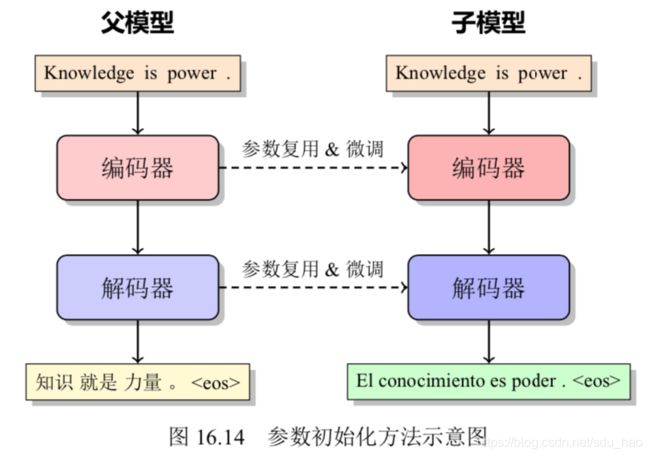
这种方法尽管在某些低资源语言上取得了成功,但在资源极度匮乏或零资源的 翻译任务中仍然表现不佳[20] 。具体而言,如果子模型训练数据过少,无法通过训练 弥补父模型跟子模型之间的差异,因此微调的结果很差。一种解决方案是先预训练 一个多语言的模型,然后固定这个预训练模型的部分参数后训练父模型,最后从父 模型中微调子模型[21] 。这样做的好处在于先用预训练提取父模型的任务和子模型的 任务之间通用的信息(保存在模型参数里),然后强制在训练父模型的时候保留这些 信息(通过固定参数),这样最后微调子模型的时候就可以利用这些通用信息,减少 父模型和子模型之间的差异,使得微调的结果得到提升[22] 。
3.2 多语言单模型系统
多语言单模型方法(Multi-lingual Single Model-based Method)也可以被看做是一 种迁移学习。多语言单模型方法尤其适用于翻译方向较多的情况,因为为每一个翻 译方向单独训练一个模型是不实际的,不仅因为设备资源和时间上的限制,还因为 很多翻译方向都没有双语平行数据[23, 24, 25]。 比如,要翻译 100 个语言之间互译的系 统,理论上就需要训练 100 × 99 个翻译模型,代价十分巨大。这时就可以使用多语 言单模型方法。
多语言单模型系统是指用单个模型具有多个语言方向翻译的能力。对于源语言 集合 G x G_x Gx 和目标语言集合 G y G_y Gy,多语言单模型的学习目标是学习一个单一的模型,这 个模型可以进行任意源语言到任意目标语言的翻译,即同时支持所有 { ( l x , l y ) ∣ x ∈ G x , y ∈ G y } \{(l_x,l_y)| x\in G_x, y\in G_y\} {(lx,ly)∣x∈Gx,y∈Gy}的翻译。多语言单模型方法又可以进一步分为一对多[26]、多对一[27] 和 多对多[28] 的方法。不过这些方法本质上是相同的,因此这里以多对多翻译为例进行介绍。
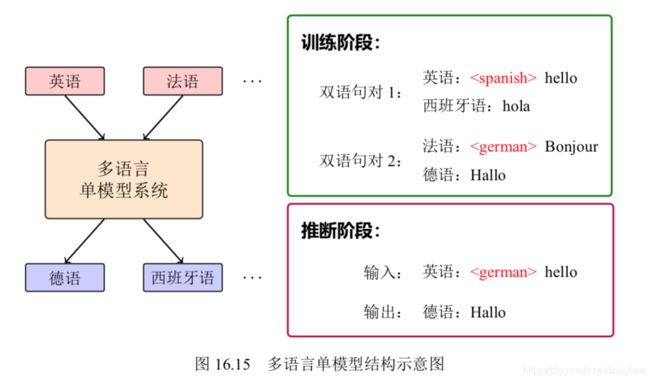
在模型结构方面,多语言模型与普通的神经机器翻译模型相同,都是标准的编 码器-解码器结构。多语言单模型方法的一个假设是:不同语言可以共享同一个表 示空间。因此,该方法使用同一个编码器处理所有的源语言句子,使用同一个解码 器处理所有的目标语言句子。为了使多个语言共享同一个解码器(或编码器),一 种简单的方法是直接在输入句子上加入语言标记,让模型显性地知道当前句子属于 哪个语言。如图16.15所示,在此示例中,标记“”表示目标句子为西班牙 语,标记“”表示目标句子为德语,则模型在进行翻译时便会将句子开头 加有“”标签的句子翻译为西班牙语[23] 。假设训练时有英语到西班牙语
“ Hello”→“Hola”和法语到德语“ Bonjour”→“Hallo”的双语 句对,则在解码时候输入英语“ Hello”时就会得到解码结果“Hallo”。
多语言单模型系统无需显性训练基于枢轴语言的翻译系统,而是共享多个语言 的编码器和解码器,因此极大地提升了数据资源的利用效率。其适用的一个极端场景是零资源翻译,即源语言和目标语言之间没有任何平行数据。以法语到德语的 翻译为例,假设此翻译语言方向为零资源,即没有法语到德语的双语平行数据,但 是有法语到其他语言(如英语)的双语平行数据,也有其他语言(如英语)到德语的双语平行数据。这时直接运行图16.15所示模型,可以学习到法语到英语、英语到 德语的翻译能力,同时具备了法语到德语的翻译能力,即零资源翻译能力。从这个 角度说,零资源神经机器翻译也需要枢轴语言,只是这些枢轴语言数据仅在训练期 间使用[23] ,而无需生成伪并行语料库。这种使用枢轴语言的方式也被称作隐式桥接(Implicit Bridging)。
另外,使用多语言单模型系统进行零资源翻译的一个优势在于,它可以最大程度上利用其它语言的数据。还是以上面提到法语到德语的零资源翻译任务为例,除 了使用法语到英语、英语到德语的数据之外,所有法语到其它语言、其它语言到德 语的数据都是有价值的,这些数据可以强化对法语句子的表示能力,同时强化对德语句子的生成能力。这个优点也是16.3.1节所介绍的传统基于枢轴语言方法所不具备 的。
不过,多语言单模型系统经常面临脱靶翻译问题,即把源语言翻译成错误的目标语言,比如要求翻译成英语,结果却是汉语或者英语夹杂其他语言的字符。这是因为多语言单模型系统对所有语言都使用一样的参数,导致不同语言字符混合时不容易让模型进行区分。针对这个问题,可以在原来共享参数的基础上为每种语言添加额外的独立的参数,使得每种语言拥有足够的建模能力,以便于更好地完成特定 语言的翻译[29,30]。
4. 参考文献
- Raj Dabre, Chenhui Chu, and Anoop Kunchukuttan. “A survey of multilingual neural machine translation”. In: volume 53. 5. ACM Computing Surveys, 2020, pages 1–38 (cited on pages 532, 536).
- Hua Wu and Haifeng Wang. “Pivot language approach for phrase-based statistical machine translation”. In: volume 21. 3. Machine Translation, 2007, pages 165–181 (cited on pages 532, 533).
- Yun Chen, Yang Liu, Yong Cheng, and Victor O. K. Li. “A Teacher-Student Framework for Zero-Resource Neural Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2017, pages 1925–1935 (cited on pages 409, 532, 533).
- Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda B. Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, and Jeffrey Dean. “Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”. In: volume 5. Transactions of the Association for Computational Linguistics, 2017, pages 339–351 (cited on pages 528, 532, 536, 537, 551).
- Yunsu Kim, Petre Petrov, Pavel Petrushkov, Shahram Khadivi, and Hermann Ney. “Pivot-based Transfer Learning for Neural Machine Translation between Non-English Languages”. In: Annual Meeting of the Association for Computational Linguistics, 2019, pages 866–876 (cited on pages 532, 533).
- Masao Utiyama and Hitoshi Isahara. “A Comparison of Pivot Methods for Phrase-Based Statistical Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2007, pages 484–491 (cited on page 533).
- Samira Tofighi Zahabi, Somayeh Bakhshaei, and Shahram Khadivi. “Using Context Vectors in Improving a Machine Translation System with Bridge Language”. In: Annual Meeting of the Association for Computational Linguistics, 2013, pages 318–322 (cited on page 533).
- Xiaoning Zhu, Zhongjun He, Hua Wu, Conghui Zhu, Haifeng Wang, and Tiejun Zhao. “Improving Pivot-Based Statistical Machine Translation by Pivoting the Co-occurrence Count of Phrase Pairs”. In: Conference on Empirical Methods in Natural Language Processing, 2014, pages 1665–1675 (cited on page 533).
- Akiva Miura, Graham Neubig, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. “Improving Pivot Translation by Remembering the Pivot”. In: Annual Meeting of the Association for Computational Linguistics, 2015, pages 573–577 (cited
on page 533). - Trevor Cohn and Mirella Lapata. “Machine Translation by Triangulation: Making Effective Use of Multi-Parallel Corpora”. In: Annual Meeting of the Association for Computational Linguistics, 2007 (cited on page 533).
- Hua Wu and Haifeng Wang. “Revisiting Pivot Language Approach for Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2009, pages 154–162 (cited on page 533).
- Adrià De Gispert and Jose B Marino. “Catalan-English statistical machine translation without parallel corpus: bridging through Spanish”. In: International Conference on Language Resources and Evaluation, 2006, pages 65–68 (cited on page 533).
- Yong Cheng, Yang Liu, Qian Yang, Maosong Sun, and Wei Xu. “Neural Machine Translation with Pivot Languages”. In: volume abs/1611.04928. CoRR, 2016 (cited on page 533).
- Michael Paul, Hirofumi Yamamoto, Eiichiro Sumita, and Satoshi Nakamura. “On the Importance of Pivot Language Selection for Statistical Machine Translation”. In: Annual Conference of the North American Chapter of the Association for Com- putational Linguistics, 2009, pages 221–224 (cited on page 533).
- Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, and Tie-Yan Liu. “Multilingual Neural Machine Translation with Knowledge Distillation”. In: International Conference on Learning Representations, 2019 (cited on page 533).
- Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. “Distilling the Knowledge in a Neural Network”. In: volume abs/1503.02531. CoRR, 2015 (cited on pages 409, 435, 436, 458, 474, 533, 534).
- Jiatao Gu, Yong Wang, Yun Chen, Victor O. K. Li, and Kyunghyun Cho. “Meta- Learning for Low-Resource Neural Machine Translation”. In: Conference on Em- pirical Methods in Natural Language Processing, 2018, pages 3622–3631 (cited on page 535).
- Chelsea Finn, Pieter Abbeel, and Sergey Levine. “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”. In: volume 70. Proceedings of Machine Learning Research. International Conference on Machine Learning, 2017, pages 1126– 1135 (cited on page 535).
- Jiatao Gu, Hany Hassan, Jacob Devlin, and Victor O. K. Li. “Universal Neural Machine Translation for Extremely Low Resource Languages”. In: Annual Con- ference of the North American Chapter of the Association for Computational Lin- guistics, 2018, pages 344–354 (cited on page 535).
- Tom Kocmi and Ondrej Bojar. “Trivial Transfer Learning for Low-Resource Neu- ral Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2018, pages 244–252 (cited on page 536).
- Baijun Ji, Zhirui Zhang, Xiangyu Duan, Min Zhang, Boxing Chen, and Weihua Luo. “Cross-Lingual Pre-Training Based Transfer for Zero-Shot Neural Machine Translation”. In: volume 34. 01. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pages 115–122 (cited on page 536).
- Zehui Lin, Xiao Pan, Mingxuan Wang, Xipeng Qiu, Jiangtao Feng, Hao Zhou, and Lei Li. “Pre-training Multilingual Neural Machine Translation by Leveraging Alignment Information”. In: Conference on Empirical Methods in Natural Lan- guage Processing, 2020, pages 2649–2663 (cited on page 536).
- Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda B. Viégas, Martin Wattenberg, Greg Corrado, Mac- duff Hughes, and Jeffrey Dean. “Google’s Multilingual Neural Machine Trans- lation System: Enabling Zero-Shot Translation”. In: volume 5. Transactions of the Association for Computational Linguistics, 2017, pages 339–351 (cited on pages 528, 532, 536, 537, 551).
- Raj Dabre, Chenhui Chu, and Anoop Kunchukuttan. “A survey of multilingual neural machine translation”. In: volume 53. 5. ACM Computing Surveys, 2020, pages 1–38 (cited on pages 532, 536).
- Matiss Rikters, Marcis Pinnis, and Rihards Krislauks. “Training and Adapting Mul- tilingual NMT for Less-resourced and Morphologically Rich Languages”. In: Eu- ropean Language Resources Association, 2018 (cited on page 536).
- Daxiang Dong, Hua Wu, Wei He, Dianhai Yu, and Haifeng Wang. “Multi-Task Learning for Multiple Language Translation”. In: Annual Meeting of the Associa- tion for Computational Linguistics, 2015, pages 1723–1732 (cited on pages 528, 536, 551).
- Jason Lee, Kyunghyun Cho, and Thomas Hofmann. “Fully Character-Level Neural Machine Translation without Explicit Segmentation”. In: volume 5. Transactions of the Association for Computational Linguistics, 2017, pages 365–378 (cited on pages 414, 536, 551).
- Orhan Firat, Kyunghyun Cho, and Yoshua Bengio. “Multi-Way, Multilingual Neu- ral Machine Translation with a Shared Attention Mechanism”. In: Annual Confer- ence of the North American Chapter of the Association for Computational Linguis- tics, 2016, pages 866–875 (cited on pages 536, 551).
- Biao Zhang, Philip Williams, Ivan Titov, and Rico Sennrich. “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2020, pages 1628–1639 (cited on page 537).
- Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Sid- dharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaud- hary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, and Armand Joulin. “Beyond English-Centric Multilingual Machine Translation”. In: volume abs/2010.11125. CoRR, 2020 (cited on page 537).