深度学习零散知识点笔记1
个人学习笔记,可能从各个地方的博客中截图粘贴,先谢了。
看下面的内容需要你理解CNN的基础知识,下面两个链接是CNN神经网络的可视化。
https://www.bilibili.com/video/av23951169?from=search&seid=12019935558685869597
卷积神经网络的三维可视化
1 三大顶会和NIPS
1 CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。
2 ICCV 的全称是 IEEE International Conference on Computer Vision,即国际计算机视觉大会,由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。不同于在美国每年召开一次的CVPR和只在欧洲召开的ECCV,ICCV在世界范围内每两年召开一次。ICCV论文录用率非常低,是三大会议中公认级别最高的 [1] 。ICCV会议时间通常在四到五天,相关领域的专家将会展示最新的研究成果。2019年ICCV将在韩国首尔举办。
3 ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议) ,两年一次,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一。每次会议在全球范围录用论文300篇左右,主要的录用论文都来自美国、欧洲等顶尖实验室及研究所,中国大陆的论文数量一般在10-20篇之间。ECCV2010的论文录取率为27%。
———————————————————————————————————————————————————————
4 NIPS(NeurIPS),全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议 [1] 。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议 [2]
2 Faster R-CNN
年份:2015
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun



- R-CNN和Fast R-CNN都是通过selective search生成区域推荐框的(2000个左右),Faster R-CNN才使用的anchor推荐(300个左右,测试,NMS之后)
- Faster R-CNN主要任务就是通过RPN替代原来的selective search,在生成区域推荐框的时候也是正负尽量128:128数量选取,不够的话1:3比例选取,进行训练。
- roi pooling层,与sppnet的区别。SPP针对同一个输入使用了多个不同尺寸的池化操作,把不同尺度的结果拼接作为输出;而ROI Pooling可看作单尺度的SPP,对于一个输入只进行一次池化操作。https://blog.csdn.net/qq_35586657/article/details/97885290

3 SSD
paper:https://arxiv.org/abs/1512.02325
具体看https://blog.csdn.net/ytusdc/article/details/86577939
1 网络结构
1 分别将VGG16的全连接层FC6和FC7转换成 3x3 的卷积层 Conv6和 1x1 的卷积层Conv7
2 去掉所有的Dropout层和FC8层
3 同时将池化层pool5由原来的 stride=2 的 2x2 变成stride=1的 3x3 (猜想是不想reduce特征图大小)
4 添加了Atrous算法(hole算法),目的获得更加密集的得分映射
5 然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测
6 采用conv4; conv7; conv8 ;conv9 ;conv10 ; avg pooling六层特征图进行多尺度采样。
7 在conv4层后增加了batch normalization
2 算法细节
1 多尺度特征映射。大检小,小检大
2 Default box 和 Prior box(先验框)
default box个数和生成公式

Prior box概念
正负样本1:3
4 采用卷积预测
3 训练过程

4 其他
IUO大于0.5选为正例
1、Matching strategy(匹配策略):
2、Hard negative mining:
3、Data augmentation(数据增强):主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本)
4、Atrous Algothrim(获得更加密集的得分映射)
5、NMS(非极大值抑制)
5 速度快的原因
- 首先SSD是一个单阶段网络,只需要一个阶段就可以输出结果;而Faster-rcnn是一个双阶段网络,尽管Faster-rcnn的BB少很多,但是其需要大量的前向和反向推理(训练阶段),而且需要交替的训练两个网络;
- Faster-rcnn中不仅需要训练RPN,而且需要训练Fast-rcnn,而SSD其实相当于一个优化了的RPN网络,不需要进行后面的检测,仅仅前向推理就会花费很多时间;
- YOLO网络虽然比SSD网络看起来简单,但是YOLO网络中含有大量的全连接层,和FC层相比,CONV层具有更少的参数;同时YOLO获得候选BB的操作比较费时;SSD算法中,调整了VGG网络的架构,将其中的FC层替换为CONV层,这一点会大大的提升速度,因为VGG中的FC层都需要大量的运算,有大量的参数,需要进行前向推理;
- 使用了atrous算法,具体的提速原理还不清楚,不过论文中明确提出该算法能够提速20%。
- SSD设置了输入图片的大小,它会将不同大小的图片裁剪为300x300,或者512x512,和Faster-rcnn相比,在输入上就会少很多的计算。
6 SSD网络结构优劣分析
优点
SSD算法的优点应该很明显,运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。SSD对不同横纵比的object的检测都有效,这是因为算法对于每个feature map cell都使用多种横纵比的default boxes,这也是本文算法的核心。最后本文也强调了增加数据集的作用,包括随机裁剪,旋转,对比度调整等等。
缺点
1、需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。(相比之下,YOLO2使用聚类找出大部分的anchor box形状,这个思想能直接套在SSD上)
2、虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。所以增加输入图像的尺寸对于小的object的检测有帮助。另外增加数据集(此处主要是指裁剪)对于小的object的检测也有帮助,原因在于随机裁剪后的图像相当于“放大”原图像,所以这样的裁剪操作不仅增加了图像数量,也放大了图像。
---------------------
作者:ytusdc
来源:CSDN
原文:https://blog.csdn.net/ytusdc/article/details/86577939
版权声明:本文为博主原创文章,转载请附上博文链接!
4 YOLO
https://zhuanlan.zhihu.com/p/32525231
1 YOLO V1
1 网络结构
- 先预训练的Googlenet,然后去掉了最后的两个全连接,做backbone
- 加上四个随机初始化的卷积层,和两个全连接层

PBox
- 整张图分为m个cell,每个cell两个PBox,根据目标中心点掉落在哪个cell,确定最后的特征图(m*m维,在长宽尺寸上)通过哪个位置预测结果
- xy是针对cell的位置,wh是针对整张图的比例,都是相对比例
- 由于预置框比较少,所以定位不太准
结果保存形式

类别置信度(class-specific confidence scores):
![]()
2 网络训练
基本都是MSE形式

3 需要注意的点
- 检测过程大体三个阶段:resize+convolution+nms
- 先训练分类网络: 224x224尺寸训练,googlenet的前20层+average pooling layer++full connect layer
- 再训练检测网络:448x448(细粒度要求)尺寸训练,预训练的20层conv+4个新conv+2个full connect layer
- 小box出错更不能容忍所以用

- 专职化两个box中选IOU值大的训练(IOU最大者偏移会更少一些,可以更快速的学习到正确位置)
4 缺点
- YOLO对相互靠的很近的物体(挨在一起且中心点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
- YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。
2 YOLO V2
1 8个改进措施
- 每个卷积后都添加BN,yolov2放弃了所有dropout
- 高分辨率分类器,在imagenet训练完之后,加了10个使用尺寸为448的输入epoch finetuning网络,这样有个缓冲,是yolov2能够更好的适应448大小尺寸
- 新的backbone使用了darknet19
- 借鉴RPN的anchor box,每个box都有一套自己的预测结果,v1两个框只有一个预测结果
- 聚类挑选合适的anchor box,通过每个框的IOU值进行的聚类统计
- 细粒度检测Fine-Grained Features
- 还原真实框的方法和fasterrcnn不同,Direct location prediction
- 多尺度训练Multi-Scale Training
2 其他
-
使用卷积代替全连接
-
32倍下采样,分了13个格子
-
依然取IOU最大的进行训练,先根据gt中心落在那个cell中,然后在这个cell中选取IOU最大的作为正样本训练
3 训练
依然是MSE

3 YOLO V3
图引用自https://blog.csdn.net/leviopku/article/details/82660381#t4


1 端到端一个loss function搞定训练
2 位置回归的计算方法
目标真实位置获得,以cell为参照物进行转换,和anchor的直接通过偏移系数转换不同(这样偏移参数训练比较难)


对比Faster R-CNN



3 预置框(聚类获得bbox)
v1是一个cell两个预置框,两框共用同一结果。v2借鉴anchor机制,通过聚类选择了每个cell预置框的数量和size。v3还是聚类选择预置框,不过v3选择了9个预置框,每3个负责一个featuremap的cell,多尺度机制,大图预测小目标,小图预测大目标
4 v3采用了FPN结构
作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个concat,之后再卷积计算处理作为最终结果
5 逻辑回归
- 在trainning阶段,目标的gt中心落在哪一个cell里,采用此cell与目标IOU最大的框进行训练。
- 在predict阶段,使用逻辑回归得到最佳的框,其他框即使超过阈值,也不要,就留一个框。减少计算量https://blog.csdn.net/leviopku/article/details/82660381
- 将多类别概率输出的softmax换成逻辑回归,因为opendataDatabase里数据有多标签,softmax没法输出多标签,逻辑回归进行二分类来解决这个问题,所以v3的损失函数也是平方误差损失的总和+二值交叉熵损失,使用逻辑回归代替了激活函数
6 大量采用BN和leaky-relu并且使用残差模块并且不存在池化和全连接
- 从v2开始引入BN操作,v3开始大量使用BN和残差结构,v2是没有使用残差模块的
- v2是通过池化缩小32倍,v3通过stride缩小
7 输出尺寸
13 26 52
channel =bbox_number*(x+y+w+h+c)
8 损失函数
v1、v2视为回归问题,采用均方差函数
只有v1写了损失函数,v2、v3没有明确写,v3论文说,使用了平方误差损失的总和+二值交叉熵
5 LSTM
普通RNN

LSTM
[译] 理解 LSTM(Long Short-Term Memory, LSTM) 网络 - wangduo - 博客园
https://zhuanlan.zhihu.com/p/32085405
上面两个只能了解运作流程,但是你很难知道lstm的内部和数据的流动究竟是怎么样的,比如我问你一个问题,time_step=10的程序中cell一共有几个?实现lstm需要几个参数?看下面吧
LSTM的输入输出究竟是什么样的

关键词
门层、门控信号、细胞状态、时间步、总参数量

- LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。上面的Ct是长时细胞状态,下面的ht可以理解为短时或工作状态。
- 上图中的门是以层的状态存在的,忘记门层使用sigmoid,输入门层有两个激活函数,一个是sigmoid决定什么值我们将要更新,二是tanh输出的是要更新的候选向量。然后更新细胞状态。更新完毕后处理输出门层,输出值也是两个层操作的,首先细胞状态通过tanh将值转为(-1,1)范围,第二是Xt通过sigmoid选择什么需要输出,两个值点乘就是最后的输出。
- sigmoid层大部分是作为门控信号(0,1),tanh则是将值转为到(-1,1)范围。
- 在经过激活函数的时候,由于你的设定,n_hidden = 128所以你的(128+28)就有线性组合成了128维(mnist手写字为例)
- LSTM 拥有三个门,四个状态
双向LSTM
解决只依靠前面信息的问题,可以综合考虑前后信息提升准确率。
我今天不舒服,我打算____一天。
只根据‘不舒服‘,可能推出我打算‘去医院‘,‘睡觉‘,‘请假‘等等,但如果加上后面的‘一天‘,能选择的范围就变小了,‘去医院‘这种就不能选了,而‘请假‘‘休息‘之类的被选择概率就会更大。
6 GRU

- 将忘记门和输入门合成了一个单一的更新门,同样还混合了细胞状态和隐藏状态
- update gate的作用类似于input gate和forget gate,(1-z)相当于input gate, z相当于forget gate
区别
- GRU和LSTM的性能在很多任务上不分伯仲
- GRU 参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
- 从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将hidden state 传给下一个单元,而LSTM则用memory cell 把hidden state 包装起来
- 最大的相似之处就是, 在从t-1 到 t 的更新时都引入了加法。好处就是防止梯度消失
6 ResNet
https://zhuanlan.zhihu.com/p/31852747
https://v.youku.com/v_show/id_XMzM4MDM2NzA2OA==.html?refer=seo_operation.liuxiao.liux_00003303_3000_Qzu6ve_19042900
https://zhuanlan.zhihu.com/p/31852747
关键词
网络退化、恒等映射、残差单元、短路连接
关键操作
- ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。
- ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。
疑问-为什么要残差为0:
当残差为0时,此时堆积层仅仅做了恒等映射(权值全为1),至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
实例
https://blog.csdn.net/u013093426/article/details/81166751
resnet为什么work
- 使网络更容易在某些层学到恒等变换(identity mapping)。在某些层执行恒等变换是一种构造性解,使更深的模型的性能至少不低于较浅的模型。这也是作者原始论文指出的动机。
- 残差网络是很多浅层网络的集成(ensemble),层数的指数级那么多。主要的实验证据是:把 ResNet 中的某些层直接删掉,模型的性能几乎不下降。
- 残差网络使信息更容易在各层之间流动,包括在前向传播时提供特征重用,在反向传播时缓解梯度信号消失。原作者在一篇后续文章中给出了讨论。
残差模块
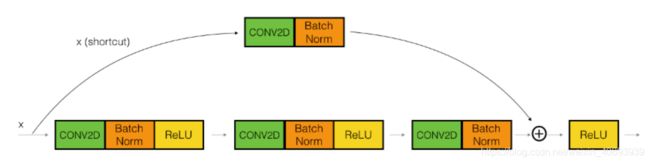
请注意resnet用的是relu
恒等残差块——The identity block

为什么两种模块
处理通道数量不一致问题,第二个是为了防止卷积后通道数和原来数目对不上改进的,目前知道的原因就是这个
卷积残差块——The convolutional block
目的是处理尺寸不一致为题
7 RetinaNet
https://zhuanlan.zhihu.com/p/53259174
预备知识
- easy negative:全是背景
- easy positive:全是物体
- hard negative:包含部分物体,但大部分为背景
- hard positive:包含部分背景,但大部分为物体
关键点
1 主要解决了onestage不精准的问题,论文指出造成不精准主要是因为正负样本难易样本不均衡导致。
2 网络结构ResNet+FPN+两个subnet
3 最重要的改动是损失函数,如下αt解决正负样本不均衡的问题,Pt解决难以样本不能区分处理的问题
4 FPN不说了,两个subNet主要是用于回归位置和分类用的,RetinaNet是onestage网络了,所以这里的subNet实际上是类似改动的RPN网络,与RPN相比主要增加了类别预测并调整了IUO阈值以0.5判断,我记得RPN是0.3&0.7。使用的sigmoid做最后类别预测的输出,FPN每个尺寸特征图的分类subNet都是4个3x3xC的卷积核,最后3x3xKA(K类别数,A锚框数。

6 优化器:SGD、batchsize16、分类是FLoss 位置回归是smoothL1

8 TensorFlow
1 简述TensorFlow计算图
1 Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图。
2 可以把计算图看做是一种有向图,Tensorflow中的每一个节点都是计算图上的一个Tensor, 也就是张量,而节点之间的边描述了计算之间的依赖关系(定义时)和数学操作(运算时)。
3 Tensorflow计算的过程就是利用的Tensor来建立一个计算图,然后使用Session会话来启动计算,最后得到结果的过程。
2 padding 的vaild和same
https://www.2cto.com/kf/201708/673033.html

9 pytorch
pytorch中文文档
gitbook
Torchvision
torchvision主要包括一下几个包:
- vision.datasets : 几个常用视觉数据集,可以下载和加载,这里主要的高级用法就是可以看源码如何自己写自己的Dataset的子类
- vision.models : 流行的模型,例如 AlexNet, VGG, ResNet 和 Densenet 以及 与训练好的参数。
- vision.transforms : 常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor ,numpy 数组到tensor , tensor 到 图像等。
- vision.utils : 用于把形似 (3 x H x W) 的张量保存到硬盘中,给一个mini-batch的图像可以产生一个图像格网。
10 Keras
keras中文文档-快速开始
- keras的核心数据结构是model,是一种组织网络层方式,最简单的模型是使用 Sequential 顺序模型,他由多个网络层线性堆叠。
- model = Sequential()实例化一个model类
- 可以简单地使用 .add() 来堆叠模型:
- 在完成了模型的构建后, 可以使用 .compile() 来配置学习过程
- 使用.fit() 进行训练,可以使用迭代器批量训练数据节省内存
除了上述的sequential,通过layer的搭建方法是也是很流行的
https://blog.csdn.net/Irene_Loong/article/details/89509429
10 啥是Golbal average pooling(GAP)?
2014年Golbal Average Pooling 第一次出现在论文Network in Network中,后来又很多工作延续使用了GAP,实验证明:Global Average Pooling确实可以提高CNN效果。
- GAP的意义是对整个网络从结构上做正则化防止过拟合,同时达到FC的效果。全连接层过多的参数容易造成过拟合,这也是催生dropout的原因,dropout不就是主要处理全连接层的嘛
- 不用在乎网络输入的图像尺寸。
- 使用gap也有可能造成收敛变慢。
过程参考一下链接
简书GAP
10 余弦相似度、欧氏距离
余弦相似度
https://www.cnblogs.com/dsgcBlogs/p/8619566.html
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
余弦计算公式
欧氏距离
N维向量间的欧氏距离计算公式

两者对比

- 欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现样本间差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
- 余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。比如图中B点朝原方向远离坐标轴原点,则AB间的欧式距离肯定是增大的,但是余弦值不会变化。
- 例如,对一部影片的评价,A用户为(1,2,3),B(3,7,9)C(7,3,9)。计算余弦距离的话AB的差异更小,说明,用户AB的审美观点是一致的,只不过A更严格一点,是一类人。但是计算欧式距离BC可能更近,BC是一类人,这显然不合理,所以余弦距离适合做评分系统。欧式距离的话适合比较样本间的相似性。
高维时建议使用余弦相似度
- 余弦相似度在高维的情况下依然保持“相同时为1,正交时为0,相反时为-1”的性质。
- 欧式距离的数值受维度的影响,范围不固定,并且含义也比较模糊。
11 Upsampling、Unpooling、Deconvolution的区别
upsampling
最近邻插值
设原图为m*n,扩大到M*N
计算扩大系数K= m/M
开始对扩大后的图中每个像素位置赋值,如要对(x1,y2)赋值,则f(x1,y2) =f (x= x1*K,y = y1*K)。x,y为原图坐标,如果不能得到整数则根据小数四舍五入

线性插值、双线性插值
单线性插值就是线性函数对y的推导过程,双线性的话就是两次单线性的组合
https://blog.csdn.net/xbinworld/article/details/65660665
Deconvolution
https://blog.csdn.net/qq_27871973/article/details/82973048

最重要的就是反卷积的过程,大致可以理解为卷积操作的数学本质,卷积核与特征图的点积,是可以写成矩阵相乘的,这样的话卷积操作就可以借助上面的图示矩阵与特征图相乘完成,反卷积可以通过乘上图矩阵的转置实现
12 Fully Convolutional Networks(FCN)和Feature Pyramid Networks(FPN)
FCN
https://blog.csdn.net/qq_36269513/article/details/80420363
- 全卷积结构Full convolution,将CNN最后的FC换成(channel*size*size)大小的卷积核
- 反卷积结构Deconvolution——对池化结果上采样,(所以才不会和上层特征图一样),请看11
- 跳级结构Skip Architecture,为了使分类结果更加精细,添加语义信息的作用
- 最后逐个像素计算softmax分类的损失,通过逐个像素地求其在channel 中,该像素位置的最大数值描述(概率)作为该像素的分类
FPN
- 自底向上,正常卷积过程
- 自顶向下,上采样方法为最近邻插值。请看11
- 对应元素相加,通道数不变
- 侧连接再卷积得出结果
13 OCR之CTC损失
一文读懂CRNN+CTC
1. CTC损失函数出现的原因
如果使用softmax计算loss,则需要将特征矩阵的每一列都与样本标签相对应,这样就需要训练时候,标记每个字符在样本中的位置,在通过cnn的感受野对齐到label,工作量巨大,而且实际上是很难对齐的。
这个问题同样存在语音识别的过程中,有人说话快有人说话慢的帧对齐问题。
所以CTC(Connectionist Temporal Classification/联结主义时间分类)提出一种不需要对齐的计算loss的方法,广泛应用与文本识别和语音识别领域。
2. CTC损失函数的计算方式(过程方式)

3 β压缩变换,出问题
14 目标检测的常用评价指标
https://zhuanlan.zhihu.com/p/56961620
- 准确率(accuracy) :(TP+TN)/(TP+FP+TN+FN),所有预测正确的样本数,占所有参加测试的样本数的比例
- 精确率(precision):TP/(TP+FP),所有判断是正例的样本中,真为正例的比例。(反例一样,也就是说他是衡量某一类的指标)
- 召回率(recall):TP/(TP+FN),判断正确的正例,占所有样本中正例的比例。(反例一样,同上)
- AP:AP等于PR曲线下的面积,针对的是单个类别,代表模型对某一类目标的预测性能
- mAP:mAP则是所有类别的AP平均,代表的是模型整体性能
- 检测速度:检测一幅图中所有目标所需要的时间
- IOU:交并比,不说了最好理解的。
- 还有机器学习1笔记里面那一堆
15 为什么都用maxpooling而很少用meanpooling
https://blog.csdn.net/qq_18644873/article/details/84949649
- max pooling使网络具有平移不变性的重要原因。
- mean pooling对保留图片的背景信息好,maxpooling对保存纹理特征好。
16 动态图和静态图的区别
TensorFlow是“定义 - 运行”,在图形结构中定义条件和迭代,然后运行它。另一方面,PyTorch是“按运行-定义”,其中图结构是在正向计算过程中实时定义的。换句话说,TensorFlow使用静态计算图,而PyTorch使用动态计算图。基于动态图的方法为复杂体系结构(如动态神经网络)提供了更易于操作的调试功能和更强的处理能力。基于静态图的方法可以更方便地部署到移动设备,更容易部署到更具不同的体系结构,以及具有提前编译的能力。
这个意思是不是说,如果部署到嵌入式设备时,TensorFlow是可以提前编译出结果,可以烧到硬件上,而pytorch的这种边运行边编译的缺点,导致嵌入式设备没法用,因为编译过程终端设备是无法完成的。
因此,PyTorch更适合于爱好者和小型项目的快速原型开发,而TensorFlow更适合大规模部署,尤其是在考虑跨平台和嵌入式部署时。 TensorFlow经受了时间的考验,并且仍然被广泛使用。它对大型项目具有更多功能和更好的可扩展性。 PyTorch越来越容易学习,但它并没有与TensorFlow相同的一体化整合功能。这对于需要快速完成的小型项目非常有用,但对于产品部署并不是最佳选择。
17 add和concat的区别
add
对应通道的值相加,隐藏的含义是,原来的特征中信息量增加了,但是特征数量没有增加
代表有resnet和FPN和LSTM和GRU的pointwise的乘和加
concat
通道拼接,是代表特征数量增加了,计算量也增加了
代表有DenseNet和YOLOv3,LSTM和GRU的输入