【异构知识蒸馏:IVIF】
Heterogeneous Knowledge Distillation for Simultaneous Infrared-Visible Image Fusion and Super-Resolution
(同时进行红外-可见光图像融合和超分辨率的异构知识蒸馏)
近年来,红外-可见光图像融合引起了越来越多的关注,并且出现了许多出色的方法。但是,当融合低分辨率图像时,大多数融合结果都是低分辨率的,限制了融合结果的实际应用。尽管有些方法可以同时实现低分辨率图像的融合和超分辨率,但由于缺乏高分辨率融合结果的指导,融合性能的提高受到限制。为了解决这个问题,我们提出了一种具有多层注意嵌入的异构知识蒸馏网络 (HKDnet),以共同实现红外和可见光图像的融合和超分辨率。准确地说,所提出的方法由高分辨率图像融合网络 (teacher network) 和低分辨率图像融合和超分辨率网络 (student network) 组成。教师网络主要融合高分辨率输入图像,引导学生网络获得融合和超分辨率联合实施的能力。为了使学生网络更加关注可见输入图像的纹理细节,我们设计了一种角嵌入注意机制。该机制集成了通道注意力,位置注意力和角落注意力,以突出可见图像的边缘,纹理和结构。对于输入的红外图像,通过挖掘层间特征的关系来构建双频注意 (dual-frequency attention (DFA)),以突出红外图像的显着目标在融合结果中的作用。实验结果表明,与现有方法相比,该方法保留了可见光和红外模态的图像信息,达到了良好的视觉效果,并显示了准确而自然的纹理细节。
介绍
本文提出了一种具有多层注意嵌入的异构知识蒸馏网络 (HKDnet),以共同实现红外和可见光图像的融合和超分辨率。所提出的方法包括高分辨率图像融合网络以及低分辨率图像融合和超分辨率网络。前者网络融合高分辨率输入图像,引导低分辨率图像融合和超分辨率网络,实现融合和超分辨率的结合。它被称为教师网络。后一个网络是在教师网络的指导下训练的,被称为学生网络。异构知识提炼所需的知识是教师网络的融合特征和融合图像。在整个网络的训练过程中,教师网络中的知识将继续转移到学生网络中。为了解决同时图像融合和超分辨率时缺乏高分辨率融合图像标签的问题,我们以教师网络生成的高分辨率融合图像为标签,监督学生网络的训练。
在现有的知识提炼工作中,教师和学生网络通常共享相同的任务。教师网络更复杂,性能更高,而学生网络就网络结构而言是轻量级网络。在这项工作中,教师网络的任务与学生网络的任务不同。教师网络只负责融合高分辨率图像,学生网络负责低分辨率图像的融合和超分辨率。本工作中建议的教师网络具有更少的参数和更少的计算量。它为学生网络培训提供高分辨率融合图像标签。学生网络需要实现图像融合和超分辨率。它有更多的网络层,需要更重的计算量。学生网络接收到低分辨率红外和可见光图像后,可以直接生成高分辨率融合图像。教师网络包括编码器、融合层和解码器。学生网络包括实现融合和超分辨率的模块,比教师网络更复杂。因此,建议的网络是HKDnet。
我们针对学生网络中的不同模态图像设计不同的注意机制,以突出其信息差异。可见图像携带大量信息,例如边缘细节和纹理结构。通过将信息集成到融合结果中,可以提高融合性能。对于可见图像,角嵌入注意 (CEA) 机制旨在使网络能够专注于输入可见图像的纹理细节。CEA机制集成了通道注意力,位置注意力和角落注意力,以突出可见图像的边缘,纹理和结构。与可见光图像相比,红外图像携带了大量目标的亮度信息,反映了物体的显著性。如果可以将亮度信息传递到融合结果中,则有助于改善融合结果的视觉效果并突出物体的显着性。因此,对于输入红外图像,通过挖掘层特征之间的关系来构建双频注意 (DFA),以突出红外图像的显着对象在融合结果中的作用。
贡献
1)提出了一种异构知识蒸馏模型,该模型首先将知识蒸馏的思想引入到红外-可见光图像融合和超分辨率的联合实现中,以解决由于缺乏标签指导而导致的融合质量差的问题。该模型使用异构教师网络来生成伪标签,并应用标签和融合的特征来训练学生网络以同时进行图像融合和超分辨率。
2)为红外和可见光图像设计了不同的特征提取分支。对于可见图像的特征提取,提出了CEA机制,该机制集成了角点注意,位置注意和通道注意,以突出可见图像的纹理,边缘和结构在融合和超分辨率中的作用。
3)对于红外图像的特征提取,提出了DFA机制,该机制可以保留红外图像中的显着性信息。该机制通过挖掘网络不同层特征之间的关系来保留红外图像的显着亮度信息,从而对显着区域赋予更大的权重。
相关工作
Infrared and Visible Images Fusion
(对于红外和可见光的融合发展史:略)
上述方法假设源图像是高分辨率的,并且仅在该假设下才能获得令人满意的融合结果。为此,通常使用超分辨率方法来提高源图像融合后的分辨率。但是,在第一步中生成的伪像可能会传播到下一步,从而降低了最终结果的视觉质量。为了使图像融合更加可行,需要一个统一的框架来同时实现图像融合和超分辨率。
Joint Implementation of Image Fusion and Super-Resolution
Yin等人提出了一种基于稀疏表示的图像融合和超分辨率同时实现的方法。假定放大的低分辨率源图像的高频分量具有与重建结果相同的稀疏编码系数。系数用于重建高分辨率融合图像。Iqbal和Chen等人通过假设高分辨率图像块及其相应的低分辨率版本的表示系数相同,实现了同时图像融合和超分辨率。根据融合图像与源图像具有相同或相似结构张量的原理,Li等人提出了基于分数阶微分和变分方法的图像融合和超分辨率联合框架。Xie等人提出了同时图像融合和超分辨率的残差补偿方法。这些方法对于低尺度因子表现良好。对于较高的 (例如4 ×) 因子,视觉质量会严重降低。
Teacher–Student Network
知识蒸馏
师生网络是迁移学习的一种,其中教师网络是一个更复杂的网络,具有更好的性能和泛化能力。教师网络可以用较少的参数指导学生网络,以达到与其相似的性能。Li等人提出使用教师网络,并将其软输出针对未标记数据作为小型学生网络。Hinton等人发现,教师网络软输出中封装的附加信息有助于培养学生网络。基于此,Romero等人提出了师生网络分阶段培养策略。学生网络首先学习教师网络的中间特征,然后使用教师网络的实际软输出进行培训。基于中间特征表示,Yim等人提出将知识蒸馏从一个DNN应用到另一个相同架构的DNN,并报告说学生模型比老师训练更快,精度更高。Zagoruyko和Komodakis等人在每个剩余阶段结束时,迫使学生匹配老师的注意力图 (每个空间位置中通道维度的标准)。
图像融合和超分辨率联合实现的挑战是缺乏高分辨率融合图像作为标签。目前,同时图像融合和超分辨率包括传统方法和基于深度学习的方法。传统方法效率低,不便于实际应用。由于缺乏对高分辨率融合图像的监督,现有的基于深度学习的方法仅对低放大倍数有很好的效果,融合和超分辨率的视觉效果不佳。受知识蒸馏的启发,我们提出了一种具有多层注意力嵌入的异构网络,用于红外和可见光图像的同时融合和超分辨率。与现有的师生网络不同,本工作中建议的教师网络具有更少的参数和更少的计算量。它为学生网络培训提供高分辨率融合图像标签。
方法

提出了一种具有多层注意嵌入的异构知识蒸馏框架,如图1所示,以同时实现红外-可见图像融合和超分辨率。该框架主要由五个部分组成: 1) 教师网络; 2) 特征提取模块; 3) 特征融合模块; 4) 超分辨率模块; 5) 损失与训练策略。
教师网络由编码器、融合层和解码器组成。通过将高分辨率源图像输入到预先训练的教师网络中,获得高清融合标签图像。
学生网络由特征提取模块、特征融合层和超分辨率模块组成。通过将低分辨率源图像馈送到学生网络中,可以获得高分辨率融合图像。
教师网络中高分辨率源图像的融合特征和融合结果用于指导学生网络的训练。
通过前馈网络,学生网络直接学习参数Sθs的映射函数θs:

其中 I l I^l Ilir和 I l I^l Ilvis 分别为低分辨率红外和可见光图像, I s I^s Isf为学生网络生成的高分辨率融合图像。学生网络通过以下方式进行优化:

其中Ls是学生网络的损失函数, I t I^t Itf是教师网络生成的标签。具体地, I t I^t Itf由教师网络的映射函数Tθt生成:


其中,O和I分别为训练时教师网络的输出图像和输入图像,Lt为教师网络的损失函数。
Teacher Network
教师网络包括编码器、融合层和解码器。编码器由一个3 × 3卷积层和一个密集连接的块组成。卷积层用于提取浅层特征。密集连接的块包含三个卷积层。将每一层的输出级联作为下一层的输入,避免信息丢失,进一步增强高频信息。解码器由四个卷积层组成。教师网络的结构类似于DenseFuse网络。但是,DenseFuse的融合结果会遭受严重的亮度损失,因此我们也使用残差连接将源图像特征输入到解码器。除了融合的特征之外,红外和可见源图像的特征也被馈送到解码器中。令Fir,Fvis和Ff分别表示红外源图像特征,可见源图像特征和融合特征。解码器的输出 I t I^t Itf可以表示为:

其中W2是解码器D的权重集,α 是控制红外和可见图像特征的输入比率的平衡参数。为了使融合结果补充更多的源图像像素强度信息,α 的值保持在0到1之间。
Feature Extraction Module(学生网络)
在图像融合中,源图像的显著性信息对提高融合图像的质量起着至关重要的作用。
DFA嵌入到红外图像特征提取分支中,以帮助网络提取红外图像中的像素强度信息。在红外图像特征提取分支中,采用3 × 3卷积层提取低分辨率红外源图像 I l I^l Ilir的浅层特征 F s F^s Fsir。深度特征 F d F^d Fdir是通过残差组 (residual group (RG)) 获得的。最后,由六个DFA块 (DFABs) 组成的DFAG获得了增强的 F e F^e Feir特性。
CEA被引入可见图像特征提取分支,以支持网络提取可见图像中的纹理细节信息和上下文信息。在可见光图像特征提取分支中,采用3 × 3卷积层提取低分辨率可见光源图像 I l I^l Ilvis的浅层特征 F s F^s Fsvis,通过两个级联RGs得到深度特征 F d F^d Fdvis。最后,通过CEA模块获得了增强的功能。
图像特征的频率随网络深度而变化。如果结合相邻网络层的特征来提取不同频率特征之间的相关性,则相关性可以增强图像特征。在红外图像中,强度代表热辐射信息。受不同频率特征具有互补信息的知识启发,相邻网络层的特征被哈达玛积(点积)融合。然后,通过softmax获得DFA映射。随着网络的训练,来自相邻层的特征的相关性将被自适应地编码到DFA映射中。通过使用DFA图对红外图像的特征进行加权,将为强度更高的区域分配更重要的权重,以增强热辐射信息。

基于上述思想,我们提出了DFAG,其中包含六个DFAB。DFAB的具体结构如图2所示,将特征F输入到两个级联的RCAB中,得到表示能力更强的特征D ∈ R c × h × w R^{c × h × w} Rc×h×w。然后,将D馈入三个卷积层,以获得D1 ∈ R c × h × w R^{c × h × w} Rc×h×w,D2 ∈ R c × h × w R^{c × h × w} Rc×h×w和D3 ∈ R^{c × h × w}$。D1和D2的哈达玛积经过softmax层后,可以得到DFA映射MDFA ∈ R c × h × w R^{c × h × w} Rc×h×w:

其中,MDFA中的元素表示对象特征的显着性,该显着性随对象亮度的增加而增加。得到加权特征E ∈ R c × h × w R^{c × h × w} Rc×h×w:

其中 δ 是从0学习的权重参数。在E中,较亮物体的显着性得到了增强。从图2中可以看出,在通过DFAG之后获得增强的特征 F e F^e Feir红外图像特征 F d F^d Fdir。
对于可见图像,如果更多地关注与纹理和边缘相对应的特征,则保留源图像的显着性信息将是有益的。通过捕获可见图像中对象之间的上下文关系,可以获得更好的特征表示。因此,我们设计了CEA机制来预测不同空间位置的可见图像特征的权重,并捕获空间和通道维度上的特征关系。如图3所示,CEA机制集成了通道注意力,位置注意力和角落注意力。 F d F^d Fdvis是CEA的输入。当 F d F^d Fdvis通过1 × 1卷积时,得到Fv ∈ R c × h × w R^{c × h × w} Rc×h×w。Fv分别输入角落,位置和通道注意模块。

1) Corner Attention Module:
根据每个区域在不同方向上的梯度变化,可以将图像分为平滑区域,边缘区域和角落区域。角落包含关键的方向提示,并控制边缘和纹理的外观。在角落密集的区域,也有大量的边缘和纹理。因此,注意角区域相当于注意图像的纹理边缘细节。受上述想法的启发,我们提出了一个角落注意模块。将特征Fv输入角点注意模块,通过Harris算法进行处理,得到角点注意图MCOA ∈ R c × h × w R^{c × h × w} Rc×h×w。
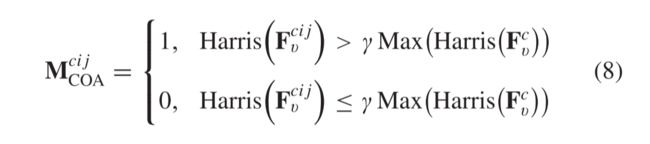
其中c = 1,2,…,C,i = 1,2,…,W和j = 1,2,…,H。 M c i j M^{cij} McijCOA = 1表示Fv的第c通道的位置 (i,j) 属于角点区域,反之亦然,不属于角点区域。 F c F^c Fcv表示Fv的第1个通道。Harris(x) 表示x由Harris函数处理。值越大,x越接近拐角区域。γ是一个介于0和1之间的系数。
同时,将特征Fv ∈ R c × h × w R^{c × h × w} Rc×h×w输入到1 × 1卷积中,以获得新的特征B ∈ R c × h × w R^{c × h × w} Rc×h×w。然后,应用MCOA和B的点积,获得增强的可见图像特征C ∈ R c × h × w R^{c × h × w} Rc×h×w。通过将Fv和C的元素相加得到最终输出FCOA。FCOA中的元素 F c i j F^{cij} FcijCOA可以表示为:

其中 β 被初始化为0,随着网络提取特征的能力的提高,这将被分配一个更大的值。从 (9) 可以看出,特征Fv的所有位置均由角注意图MCOA加权。因此,可见图像的边缘角区域受到了更多的关注。
2) Position Attention Module:

判别特征对于图像处理很重要,通过捕获长距离上下文信息获得。基于此,使用自我注意机制来捕获可见图像中的上下文。位置注意模块的结构如图3所示。Fv被重塑为Fv,r ∈ R C × N R^{C × N} RC×N,其中N = H × W。在Fv,r和Fv,r的转置之间使用矩阵乘法,然后,采用像素级softmax函数计算位置i (i = 1,2,…,N) 和j (j = 1,2,…,N) 之间的相关性:

其中Fv,r (i,j) 表示位置j在Fv,r的第i个通道上的特征。最后,增强的可见图像特征FPOA ∈ R C × H × W R^{C × H × W} RC×H×W可以通过:
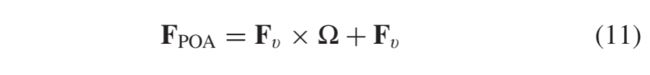
其中 Ω∈ R N × N R^{N × N} RN×N是由 ω i,j组成的矩阵。从 (11) 可以看出,FPOA是原始特征Fv与按位置注意的增强特征之间的加权和。因此,Fv中相似的语义特征可以相互增强,从而提高了特征的区分度。
3) Channel Attention Module:
对于可见图像,可以将每个通道的特征图视为图像的映射,并且在不同通道中的映射通常是不同的。通过挖掘不同通道之间的依赖关系,并为那些映射值较大的通道分配更大的权重,我们可以获得具有更强表示能力的特征图。基于该思想,通道注意模块用于捕获不同通道之间的依赖性,如图3所示。与位置注意模块类似,Fv也被重塑为Fv,r ∈ R C × N R^{C × N} RC×N。矩阵乘法用于对Fv,r及其转置 F T F^T FTv,r的不同通道之间的依赖性进行建模,并使用像素级softmax函数来计算第i个 (i = 1,2,…,C) 第j (i = 1,2,…,C) 通道上的通道。

最后,通道注意力增强的特征可以表述为

融合了功能FCOA,FPOA和FCHA,以获得更好的特征表示。然后,使用1 × 1卷积来获得增强的特征 F e F^e Fevis。
Feature Fusion Strategy and Super-Resolution Network
假设Fir ∈ R c × h × w R^{c × h × w} Rc×h×w和Fvis ∈ R c × h × w R^{c × h × w} Rc×h×w代表红外和可见光图像的特征。C是频道的数量。H和W分别是行数和列数。假设Fir ∈ R c × h × w R^{c × h × w} Rc×h×w和Fvis ∈ R c × h × w R^{c × h × w} Rc×h×w代表红外和可见光图像的特征。C是频道的数量。H和W分别是行数和列数。l1-norm和softmax用于融合Fir和Fvis。在获得Fir和Fvis之后,需要一种特征融合策略来融合它们。l1-norm和softmax用于融合Fir和Fvis。师生网络中的融合层采用相同的融合策略。具体地,分别计算Fir和Fvis各位置的所有信道特征的l1-norm,得到活动水平图Mir ∈ R H × W R^{H × W} RH×W和Mvis ∈ R H × W R^{H × W} RH×W

最后,通过Wir和Wvis对Fir和Fvis的每个通道的特征进行加权求和,得到融合特征

我们选择RCAN作为超分辨率的基本网络。与RCAN不同的是,我们的超分辨率模块中只有五个RGs,而RCAN中有十个RGs。此外,我们的超分辨率模块中的高分辨率特征提取和图像重建是由教师网络指导的。
Loss Function
原始的红外和可见图像是真实图像,它们的低分辨率版本用作模型训练的输入。为了实现更好的性能和特征学习能力,损失函数使学生网络能够使用多任务学习同时进行融合和超分辨率。由于缺乏真实数据作为同时融合和超分辨率的标签,教师网络生成相应的伪标签来训练学生网络。
在教师网络训练中,同时利用像素损失和结构相似性损失,使输入图像和重建图像具有相似的像素强度和结构。由于可见图像中的纹理细节主要由梯度变化表示,因此使用梯度损失来约束重建图像,使其梯度变化类似于输入图像。此外,感知损失 用于实现重建图像的更好视觉效果。教师网络的总损失可以表示为

其中Lt、Lpixel、Lssim、Lgrad和Lpercep分别表示总损失、像素损失、结构相似性损失、梯度损失和感知损失。Μ 是权重参数,它平衡了结构相似性损失对总损失的贡献。像素损耗Lpixel、结构相似性损耗Lssim、梯度损耗Lgrad、感知损耗Lpercep定义为:

其中||·||2表示l2-norm。SSIM(·)表示结构相似性函数。对于梯度损失,首先,计算输入图像和输出图像的梯度,然后,使用它们之间的欧氏距离来获得梯度损失值。▽表示梯度算子。对于感知损失,输入和输出图像被馈送到预先训练的VGG16网络中,以获得它们各自的特征表示。它们之间的欧几里得距离被定义为感知损失。Φ i,j表示VGG网络中第i个maximun池化层之前的第j个卷积 (激活) 得到的特征图。
教师网络的预培训完成后,我们开始学生网络的培训。由于学生网络结构复杂,因此在前60个时期仅对融合部分进行训练,以使其具有初步的融合能力,从而为融合特征提供更好的表征知识,以用于后续的超分辨率。在此阶段,低分辨率红外和可见光光源图像被馈送到学生网络和教师网络中。教师网络解码器倒数第二层的输出为 F t F^t Ftf,用作学生网络低分辨率特征融合的标签。学生网络的融合部分的输出是低分辨率融合特征 F s F^s Fsf。在 F s F^s Fsf和 F t F^t Ftf之间,l1损失用于训练学生网络的融合部分
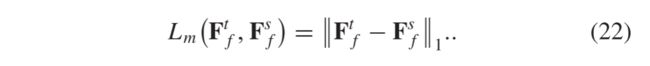
由于均方误差的损失会导致输出图像模糊 ,因此使用l1损失为学生网络提供更好的收敛性。为了将丰富的高分辨率融合特征知识从教师网络传递到学生网络,在两个网络的中间层特征中还使用了l1损失。学生网的总损失由

I s I^s Isf和 I t I^t Itf分别是教师网络生成的标签和学生网络生成的高分辨率融合图像,φ 是一个平衡参数, T m T^m Tm是教师网络中第m层的特征, S n S^n Sn是学生网络中第n层的特征。H是一组候选特征对。我们在提出的方法中使用了两个特征对。第一特征对是教师网络和学生网络中倒数第二层的特征,第二特征对是教师网络中倒数第四层的特征和学生网络中倒数第三层的特征。
Training Strategy
培训分为两个步骤: 1) 教师网络培训和2) 学生网络培训。
在教师网络的训练阶段,我们只训练网络的编码器和解码器,其中没有训练融合层。教师网络培训完成后,将生成的标签用于监督和培训学生网络。
在学生网络的培训过程中,我们使用两个阶段: 1) 在前60个时期中训练融合部分; 2) 用Ls训练整个学生网络,如算法1中所示的HKDnet训练过程中所述。