[2022AAAI]Knowledge Distillation for Object Detection via Rank Mimicking and ... 论文笔记
目录
-
- 摘要
- Method
-
- Rank mimicking
- Prediction-guided Feature Imitation
- 总损失
- 实验
- 总结
论文全名有点长,题目放不下了:
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
已经被AAAI2022接收。
摘要
出发点:student性能差的两个原因:
1.候选框排序差别很大,如下图所示。对于简单的目标(图1a),两个模型的最终留下的bbox是由同一个anchor(对于anchor-free方法而言是anchor points)回归的。但是对于难一点的框却不是(图1b),这说明对于难例样本,两者的anchor置信度排名不一样,作者将这个排序信息用于知识蒸馏中。
![[2022AAAI]Knowledge Distillation for Object Detection via Rank Mimicking and ... 论文笔记_第1张图片](http://img.e-com-net.com/image/info8/8bb2aaf3f617419fad9448a9ade20995.jpg)
2.student和teacher的特征和预测之间都存在着很大的gap,所谓的特征差异性(Pdif = Ptea - Pstu)和预测差异性(Fdif = Ftea - Fstu),作者是直接通过特征图相减得到的。问题的关键是:这个gap的位置还不一样(图中inconsistency处),这说明了虽然这一部分区域特征差异性很大,但是预测差异性很小,此处的特征差异性根本不用蒸馏,,这个发现确实让人眼前一亮。因此,作者提出了预测指导特征模仿的思路,用预测差异性来指导特征模仿学习。
![[2022AAAI]Knowledge Distillation for Object Detection via Rank Mimicking and ... 论文笔记_第2张图片](http://img.e-com-net.com/image/info8/14046c0084734e7c95d4ff7e1e0e5960.jpg)
基于上述两个问题,作者提出了Rank Mimicking(RM)和Prediction-guided Feature Imitation (PFI)两个点来对一阶段的检测器进行蒸馏,前者将teacher对候选框的排名作为一种待蒸馏的知识,后者用预测结果差异性来计算特征差异性,进而student模型的提高检测结果。
Method
首先简单介绍了一些比较通用的做法,包括分类结果蒸馏和特征蒸馏。分类那提了一下交叉熵损失,然后讲了一下Hinton提出的用teacher模型的类别结果作为软标签,以KL散度作为损失的过程。
Rank mimicking
基于出发点1,作者提出了Rank mimicking。
作者认为softlabel+KL散度的方式在检测中效果不好的原因主要有两个:一是许多检测方法在计算分类损失时都将80类分类问题(CEloss)转化为80个二分类问题(BCEloss),即:在计算损失时采用的BCEloss,而非CEloss,用BCEloss就抛弃了不同类别之间的结构关系(没有softmax,不同类别的概率和不为1)。二是不同许多检测器将类别分数作为NMS期间box排序的一部分,因此软标签可能会导致类别置信度不好,从而导致NMS结果不好,从而降低检测性能。
作者的做法是,对于一个目标j,假设有N个anchor负责对该个物体进行预测(该N个anchor称为该个物体的positive anchor),那么对于student和teacher网络,均将这N个anchor的预测的类别分数取出来,然后分别对student模型和teacher模型的N个正anchor类别分数进行softmax,即左边公式。这样就将获得N个正anchor的预测分布。再利用KL散度让teacher和student的N个正anchor的分数分布一致,即右边这个公式。其中M表示当前图像中的待检测目标格式。


这样做的意义是,teacher模型的N个正anchor中,某个分数高,那么我要求student模型的该个anchor的分数也高,低的话同理。两个模型对于所有positive anchor的预测类别分数具有同样的分布。与hinton的softlabel方法相比,这种方法将所有正anchor作为一个整体,用KL散度去蒸馏他的分布情况,而softlabel方法忽略了不同anchor的分数之间的内在联系。
除了学习分类分数的分布外,还可以要求学习回归的分布情况,操作应该一样的,但是回归一般会回归四个量,分类分布+四个回归分布,一共五个,损失有点多…但是作者实验表明点会提高
值得注意的是,上述是对分类结果进行蒸馏,而且也用到了标签信息和标签分配情况,来寻找positive anchor。
Prediction-guided Feature Imitation
预测差异大的区域承载着学生落后于老师的原因,因为我们最后只要预测结果,不会去管中间特征层。但是从上面的右图可以看到,预测差异大的位置特征差异可能会很小,而预测差异小的位置特征差异可能会很大,如果直接进行无差别的特征蒸馏,那显然那些特征差异比较大、预测差异比较小的区域会在反向传播中占据主导地位,这导致特征蒸馏效果差,甚至会伤害student的训练。
其实看到文章出发点和这个模块的名字就想到这里会怎么设计了。即:用teacher和student模型所有的预测类别分数差的l2距离来表示两个模型的预测差异性,即左边式子。其中c代表类别数,得到的P是一个H×W的mask(PFI mask),某个点的值越大,则代表S和T的预测差异性越大。这个思想与FRS、GID都有点像,GID也是用分数差来代表两个模型的预测差异性,而FRS是用teacher的分数作为特征丰富度mask进行特征蒸馏学习。然后再利用该mask作为每个像素点的权重来指导FPN处的特征蒸馏,即后面两个式子:

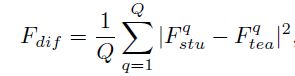

总损失
包含上述两个部分和gt loss。α=4,β=1.5。
![]()
实验
作者分别做了以R50-R18作为teacher=student对,在RetinaNet、FCOS、ATSS、GFL上的试验,Rank mimicking大部分能提高不到一个点,Prediction-guided Feature Imitation能提高2个点出头,两个损失一起能提高更多一点。还有以RetinaNet作为检测器的R101-R50、mbv2-mbv2half实验。
用作者提出的PFI mask也比不用mask、用gtmask、只用positive samples和只用negative samples的效果好。其中点数是positive mask < negative mask < gt mask < while map < PFI。
与Fitnet、FGFI、GID、DeFeat相比,该方法效果也更好。
总结
作者的发现属实让人眼前一亮,即预测差异性较小的地方,其特征差异性可能很大,反之亦然。其次,student和teacher的anchor的置信度排名也确实会影响到NMS。这是本文的两个出发点,没啥毛病,尤其是第一个出发点,如果论文说的这种情况普遍存在的话,那之前的很多特征蒸馏算法是不太合理的,但是从本论文的点数来看应该不至于。
针对第一点,作者对以预测差异性作为mask,利用该mask来进行特征蒸馏学习。针对第二点,作者将每个目标的N个正anchor的预测分数通过softmax转化为一个概率分布问题,然后利用KL散度来让两个模型的分布相同。
我感觉第二个出发点提点少的一个原因是,可能对于student模型而言,可能最终的预测结果是由负anchor提供的,如图1左边的猫的边界框所示,两个模型的预测结果中心点隔这么远,可能student模型的bbox就是负anchor回归而来的,此时对正anchor的分数分布情况进行蒸馏是对该个目标的检测没有帮助的。由此衍生的一个问题是,一些负anchor的分布情况是否也有蒸馏价值?其次,如果一个目标分配得到的anchor很少,那也这个KL散度能传授的知识也很有限。