Tensorflow手写汉字识别训练精度99%,为什么测试准确率才50%?教你一招轻松解决图像自动裁切处理问题
项目场景:
应用在Tensorflow手写汉字识别测试场景
问题描述:
最近有个小伙伴做毕业设计找到了我,他很奇怪为什么在用tensorflow进行手写汉字训练的时候,明明精度都已经达到了99%,但是测试的时候,却总是识别错误。
于是我找他拿到源码,首先肯定是先跑起来再说。小伙伴用Flask给自己搭了个用鼠标手写汉字的微服务器。
具体如下:

可以明显看到,这个书字写的还是算很标准的,但是左边top5里面识别准确率最高的竟然是“为”字。
刚开始小伙伴以为是训练精度不够,还特意训练了一晚上,训练了近13万步,精度都达到了99%,应该没问题,可是测试出来为什么却相差这么大?
原因分析:
遇到这种情况,小伙伴们不要慌,我们第一时间应该从训练集去思考,因为如果训练精度已经很高,但测试精度却很低,很有可能是训练采用的样本和测试使用的数据间相差很大。
于是我就翻出它的训练样本集看看关于汉字“书”这块的训练样本。

对比下面测试样本图片,我们来看一看。聪明的小伙伴们应该看出差别来了吧?

貌似就是测试样本周围留白太多了,导致测试样本与训练样本有很大差异,自然在测试样本中准确率就不会太高了,那真的是这样吗?
我们再来测试下,把文字写满整个框,测试下准确率吧。瞬间准确率就提高到99%啦,原因找到,就这样结束了吗?那就太low了,我们程序员不应该就这样就算了,代码是写给人来服务的,不能让人去迁就代码。
 接下来我们研究下更加人性化的解决方案吧
接下来我们研究下更加人性化的解决方案吧
解决方案:
问题的根源就是:要把汉字周围留白去掉。
那我们就开始图像处理,直接用图像处理中的强者Opencv吧!
这里大家要注意图像处理基本套路:先灰度化,后生成二值图像,然后找轮廓,求出外接最大矩形,最后裁切。
这个套路可以用到很多地方,小伙伴收藏用起来,以后图像处理不迷路!
代码如下:
import cv2
import time
def cv_show(name, img):
'''
用于显示图片
'''
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def image_prepare(image_path):
'''
用于图片自动裁切留白
'''
im = cv2.imread(image_path) #读取图片
im = cv2.resize(im, (64, 64)) #用于统一图片尺寸
# cv_show('yi', im)
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) #用于转化灰度
ret, thresh = cv2.threshold(gray, 155, 255, cv2.THRESH_BINARY_INV) #生成二值化图像,注意这里要反转下
# cv_show('out_1', thresh)
_, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) #寻找所有图片轮廓
# draw_img = im.copy()
# res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2) # 画出图片轮廓
# cv_show('res', res)
min_x = 0
min_y = 0
max_x = 0
max_y = 0
for i, cnt in enumerate(contours):
if i == 0:
x, y, w, h = cv2.boundingRect(cnt)
min_x = x
min_y = y
max_x = x + w
max_y = y + h
else:
x, y, w, h = cv2.boundingRect(cnt)
if x < min_x:
min_x = x
if y < min_y:
min_y = y
if (x + w) > max_x:
max_x = x + w
if (x + h) > max_y:
max_y = y + h
area = (max_x-min_x) * (max_y-min_y)
# print(max_x,min_x)
# print(max_y,min_y)
# print(area)
if area > 700: # 这里是针对汉字一做的面积判断,如果面积小于700,则直接保留原图,否则做自动裁切处理
if min_x >= 2 & min_y >= 2 & max_y <= 61 & max_x <= 61:
im = im[(min_y - 2):(max_y + 2), (min_x - 2):(max_x + 2)]
else:
im = im[min_y:max_y, min_x:max_x]
try:
im = cv2.resize(im, (64, 64))
except:
print('请不要靠近边缘')
else:
print(area)
return im
# cv_show('image', im)
return im
def crop_new_image(image_path):
im = image_prepare(image_path)
cv2.imwrite(image_path, im)
if __name__ == '__main__':
im = image_prepare(image_path=r'image/text_finish.png')
cv2.imwrite(r'image/text_finish4.png', im)
把这个图像自动裁切周围留白函数放到主代码中,运行一下,看看效果吧!
测试中还发现关于汉字“一”的bug,如果把汉字一的留白全去掉,则会出现很大不准,所以这里用了面积大小做了个判断,如果小于阈值,则用原图,不进行裁切。
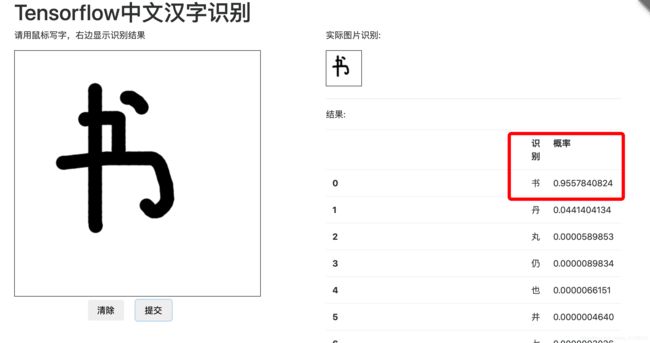
问题得到最终解决,拿走不谢!
眼瞅着马上也要到一年一度的盛大毕业季了,在这里,也祝所有今年毕业的小伙伴们,都能顺顺利利毕业,最后找到自己心仪的工作。
码字不易,小伙伴们可以支持下我 关注、收藏,点赞,一键三连。
另外如果有任何问题,可以随时评论区留言或者私信我。
本文只供大家学习相关知识使用,不以任何商业盈利为目的,转载或分享请注明相关来源。如涉及到相关侵权,请联系我删除。
欢迎志同道合者互相交流学习,可以加我微信号:Zhihua_Steven,或者扫以下二维码添加我的微信。
