CVPR 2022 | 最全25+主题方向、最新50篇GAN论文汇总
一顿午饭外卖,成为CV视觉前沿弄潮儿
35个主题!ICCV 2021最全GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
在最新的视觉顶会CVPR2022会议中,涌现出了大量基于生成对抗网络GAN的论文,广泛应用于各类视觉任务;
下述论文已分类打包好!后台回复 CVPR2022 (长按红字、选中复制)获取分类、按文件夹汇总好的论文集,gan起来吧!!!
梳理不易,麻烦各位看官,转发、分享、在看三连,多多鼓励小编!!!
一、3D
1、FLAG: Flow-based 3D Avatar Generation from Sparse Observations
为了生成逼真合理的虚拟形象姿势,从头戴式设备 (HMD) 应用于此任务的信号流通常仅限于头部姿势和手部姿势估计得来。
虽然这些信号很有价值,但它们是人体的不完整表示,因此很难生成合理的虚拟全身。通过从稀疏观察中开发基于流的 3D 人体生成模型来应对这一挑战,其中不仅学习 3D 人体姿势的条件分布,还学习从观察到潜在空间的概率映射,从中生成一个合理的姿势以及关节的不确定性估计。

2、3D Shape Variational Autoencoder Latent Disentanglement via Mini-Batch Feature Swapping for Bodies and Faces
在人脸和身体的 3D 生成模型中学习解耦的、可解释的和结构化的潜在表征仍是一个悬而未决的问题。当需要对身份特征进行控制时,这个问题尤其严重。
本文提出一种直观而有效的自监督方法来训练 3D 形状变分自动编码器 (VAE),方法可以分离身份特征的潜在表示。通过在不同形状之间交换任意特征来管理小批量生成,可以定义一个损失函数,利用潜在表示中的已知差异和相似性。实验结果表明,最先进的潜在解耦方法无法解开面部和身体的身份特征,提出的方法则正确地解耦了这些特征的生成,同时保持了良好的表示和重建能力。
代码和预训练模型可在github.com/simofoti/3DVAE-SwapDisentangled

二、GAN改进
3、Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values
提出Polarity采样,一种即插即用方法,用于控制预训练的深度生成网络(pre-trained deep generative networks,DGNs)的生成质量和多样性。本文展示了一些最先进的 DGN 的整体生成质量(例如,就 Frechet Inception 距离而言)改进的定量和定性结果,包括 StyleGAN3、BigGAN-deep、NVAE、用于不同的有条件和无条件图像生成任务。特别是,Polarity采样将 FFHQ 数据集上的 StyleGAN2 的FID 表现更新为2.57,LSUN 汽车数据集上的StyleGAN2 表现为 FID 2.27,AFHQv2 数据集上 StyleGAN3 的 FID 3.95。

4、Feature Statistics Mixing Regularization for Generative Adversarial Networks
在生成对抗网络中,改进判别器是生成性能的关键之一。本文研究判别器的偏差,以及通过去偏是否会提高生成性能。经验证据表明判别器对图像的风格(例如纹理和颜色)很敏感。作为一种补救措施,提出特征统计混合正则化(feature statistics mixing regularization,FSMR),它鼓励判别器的预测对输入图像的风格保持不变。具体来说,在判别器的特征空间中生成原始图像和参考图像的混合特征,并应用正则化,使混合特征的预测与原始图像的预测一致。
广泛的实验证明这种正则化降低对风格的敏感性,并提高各种 GAN 架构的性能。此外,将 FSMR 添加到最近提出的基于增强的 GAN 方法中进一步提高了图像质量。
https://github.com/naver-ai/FSMR

三、发型编辑
5、HairCLIP: Design Your Hair by Text and Reference Image
发型编辑是计算机视觉和图形学中一个有趣且具有挑战性的问题。许多现有方法需要精心绘制的草图或掩膜作为编辑的条件输入,但是这些交互既不简单也不高效。为了将用户从繁琐的交互过程中解放出来,本文提出了一种新的交互发型编辑模式,可以根据用户提供的文本或参考图像单独或联合操作头发属性。
为此,在共享嵌入空间中对图像和文本条件进行编码,并通过利用对比语言-图像预训练 (CLIP) 模型强大的图像文本表示能力提出统一的头发编辑框架。通过精心设计的网络结构和损失函数,框架可以以一种解耦的方式执行高质量的编辑。大量实验证明了方法在操作准确性、编辑结果的视觉真实性和无关属性保留方面的优越性。
https://github.com/wty-ustc/HairCLIP
四、风格迁移
6、Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization
任意风格迁移 (Arbitrary style transfer,AST) 和域泛化 (domain generalization,DG) 是重要但具有挑战性的视觉学习任务,可以作为特征分布匹配问题。在高斯特征分布的假设下,传统的特征分布匹配方法通常匹配特征的均值和标准差。然而,现实世界数据的特征分布通常比高斯分布要复杂得多,仅使用一阶和二阶统计量无法准确匹配,而使用高阶统计量进行分布匹配在计算上是令人望而却步的。
这项工作首次提出通过精确匹配图像特征的经验累积分布函数 (empirical Cumulative Distribution Functions,eCDF) 来执行精确分布匹配 (Exact Histogram Matching,EFDM),提出的方法有效在各种 AST 和 DG 任务上得到验证。
https://github.com/YBZh/EFDM

7、Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
大多数条件视频合成方法使用单一模态作为条件,这有很大的局限性。例如,以图像为条件的模型生成用户期望的特定运动轨迹是有问题的,因为没有提供运动信息的手段。相反,语言信息可以描述所需的动作,但不能精确地定义视频的内容。
基于联合或单独提供的文本和图像,这项工作提出一个多模式视频生成框架。利用视频量化表示的最新进展,并应用具有多种模态的双向transformer作为输入来预测离散的视频表示。为了提高视频质量和一致性,提出一种经过自学习训练的新视频token和一种用于采样视频token的改进掩码预测算法。引入文本增强以提高文本表示的鲁棒性和生成视频的多样性。框架可以包含各种视觉模式,例如分割掩膜、绘图和部分遮挡的图像。它可以生成比用于训练的序列长得多的序列。
此外,模型可以提取文本提示所建议的视觉信息,例如“图像中的一个物体正在向东北移动”,并生成相应的视频。对三个公共数据集和一个新收集的标有面部属性的数据集进行评估,实现了最好的生成结果。

8、Style-ERD: Responsive and Coherent Online Motion Style Transfer
动作风格迁移是丰富角色动画的常用方法,通常在离线设置下分段处理运动。但对于在线动画应用程序,例如来自动作捕捉的实时头像动画,需要将动作作为具有最小延迟的流进行处理。
这项工作实现一种灵活、高质量的运动风格迁移方法Style-ERD,以在线方式使用Encoder-Recurrent-Decoder结构对运动进行风格化,以及结合特征注意和时间注意力的判别器。方法使用统一的模型将运动风格化为多种目标风格。虽然方法针对在线设置,但它在运动真实感和风格表现力方面优于以前的离线方法,并提高运行时效率。

9、Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer
最近对 StyleGAN 的研究表明,通过有限数据的迁移学习,在艺术肖像的生成方面效果非常不错。
本文提出 DualStyleGAN 来探索更具挑战性的基于参考样本的高分辨率肖像风格迁移,可灵活控制原始人脸域和艺术肖像域的双重风格。与 StyleGAN 不同,DualStyleGAN 通过分别用“内风格路径”和新的“外风格路径”来表征肖像的内容和风格,提供了一种自然的风格迁移方式。精心设计的外风格路径使模型能够分层调整颜色和复杂的结构样式,以精确复制参考风格。
此外,引入了一种渐进式微调方案,即使对网络架构进行了上述修改,也可以将模型的生成空间平滑地转换到目标域。
实验证明DualStyleGAN 在高质量肖像风格迁移和灵活的风格控制方面优于最先进的方法。https://github.com/williamyang1991/DualStyleGAN

10、CLIPstyler: Image Style Transfer with a Single Text Condition
现有神经风格迁移方法,需要参考风格图像将风格图像的纹理信息转移到内容图像。然而,在许多实际情况下,用户可能没有参考风格图像,但仍有兴趣通过想象它们来迁移风格。
为处理这样的应用,提出一个新框架,可在“没有”风格图像的情况下进行风格转换,只需风格的文本描述。使用 CLIP 的预训练文本图像嵌入模型,演示了仅在单个文本条件下对内容图像风格化。提出一种带有多视图增强的补丁式文本图像匹配损失,用于逼真的纹理迁移。

五、结合transformer
11、TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
StyleGAN 等最新进展促进了可控人脸编辑技术的发展。尽管如此,这些方法仍然无法获得具有高可控性的合理编辑结果,特别是对于复杂属性。
这项研究强调了dual-space GAN 中的交互对于更可控编辑的重要性。提出 TransEditor,一种新的基于 Transformer 的框架来增强这种交互。此外,开发了一种新的编辑和逆映射策略,以提供额外的编辑灵活性。大量实验证明了所提出的框架在图像质量和编辑能力方面的优越性,表明 TransEditor 在高度可控的面部编辑方面的有效性。
https://github.com/BillyXYB/TransEditor

12、Styleformer: Transformer based Generative Adversarial Networks with Style Vector
本文提出 Styleformer,基于 Transformer 结构的风格向量来合成图像,有效地应用了修改后的 Transformer 结构(例如,增加了多头注意力和 Prelayer 归一化),并引入了新的 Attention Style Injection 模块,这是一种用于自注意力操作的风格调制和解调方法。新的生成器组件在 CNN 的缺点中具有优势,可以处理远程依赖和理解对象的全局结构。
提出了两种使用 Styleformer 生成高分辨率图像的方法。首先,将 Linformer 应用于视觉合成领域(Styleformer-L),使 Styleformer 能够生成更高分辨率的图像,并在计算成本和性能方面有所提高。这是第一个使用 Linformer 进行图像生成的案例。其次,结合 Styleformer 和 StyleGAN2 (Styleformer-C) 来有效地生成高分辨率的合成场景,Styleformer 捕获组件之间的远程依赖关系。通过这些调整,Styleformer 在单对象和多对象数据集中实现了与最先进技术相当的性能。此外,风格混合和注意力图可视化的结果证明了模型的优势和效率。

六、人脸生成
13、Sparse to Dense Dynamic 3D Facial Expression Generation
本文提出一种基于neutral 3D face和表情标签生成动态 3D 面部表情的方案。这涉及解决两个子问题:(i)对表情的时间动态进行建模,以及(ii)对neutral mesh进行变形以获得具有表现力的对应部分。使用一组稀疏 3D关键点的运动来表示表达式的时间演化,通过训练manifold-valued GAN (Motion3DGAN)来学习生成这些关键点。
为了生成表情mesh,训练一个 Sparse2Dense 网格解码器 (S2D-Dec)。这可以了解一组稀疏关键点的运动如何影响整个面部表面的变形,而与身份无关。CoMA 和 D3DFACS 数据集的实验结果表明,方案在动态表情生成和mesh重建方面都比以前的解决方案带来了显著改进,同时保留了对未见数据的良好泛化能力。


七、少样本学习
14、Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
有限数据训练生成对抗网络 (GAN) 一直是一项具有挑战性的任务。一种解决方案是从一个在大规模源域上训练好的GAN 开始,用少量样本适应目标域,称为少样本生成模型适应。
然而,现有方法在极少的样本数设置(少于 10 个)中容易出现模型过度拟合和崩溃。为了解决这个问题,提出一种宽松的空间结构对齐(relaxed spatial structural alignment,RSSA)方法来校准目标生成模型。设计了一个跨域空间结构一致性损失,包括自相关和干扰相关一致性损失。它有助于对齐源域和目标域的合成图像对之间的空间结构信息。为了放松跨域对齐,将生成模型的原始潜在空间压缩到一个子空间。从子空间生成的图像对被拉得更近。定性和定量实验表明了方法的有效性。
源代码:https://github.com/StevenShaw1999/RSSA

八、深度补全
15、RGB-Depth Fusion GAN for Indoor Depth Completion
深度图depth map承担了许多下游视觉任务,但有不完整的局限,所以已有越来越多的深度补全方法来缓解这个问题。虽然大多数现有方法可以从稀疏和均匀采样的深度图生成准确的密集深度图,但它们不适合补充缺失深度值的大连续区域。
本文设计一种新的双分支端到端融合网络,它以一对 RGB 和不完整的深度图像作为输入来预测密集且完整的深度图。第一个分支采用编码器-解码器结构,借助从 RGB 图像中提取的局部引导信息,从原始深度图中回归局部密集深度值。在另一个分支中,提出一种 RGB 深度融合 GAN,将 RGB 图像转换为细粒度纹理深度图。采用名为 W-AdaIN 的自适应融合模块在两个分支之间传播特征,并附加一个置信度融合头来融合分支的两个输出以获得最终的深度图。
在 NYU-Depth V2 和 SUN RGB-D 上的大量实验表明,提出的方法明显提高了深度补全性能。

九、视频生成
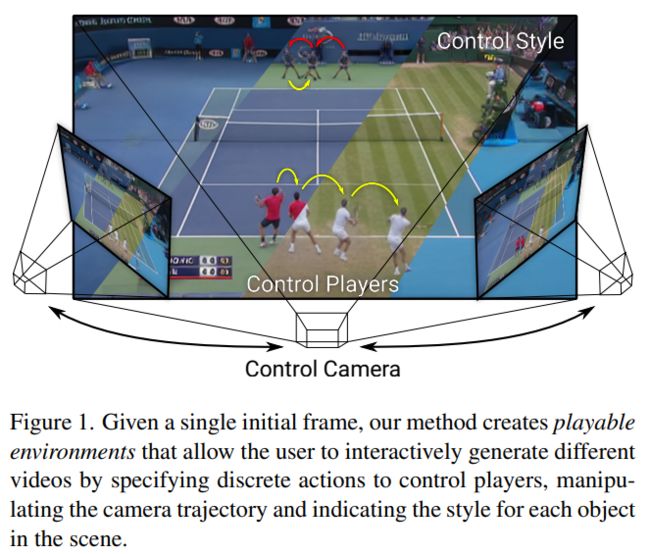
16、Playable Environments: Video Manipulation in Space and Time
本文展示了所谓的“Playable Environments”:一种用于在空间和时间中生成和操作交互式视频的新表示。在推理时使用单张图像,新框架可以让用户在 3D 中移动对象,同时通过提供一系列所需的动作来生成视频。这些动作是以无监督的方式学习的。可以控制相机以获得所需的视点。
方法为每一帧构建一个环境状态,可以通过提出的动作模块进行操作,并通过体积渲染解码回图像空间。为了支持物体的不同外观,使用基于风格的调制扩展了神经辐射场。方法在各种单目视频的集合上进行训练,只需要估计的相机参数和 2D 对象位置。为了设定具有挑战性的基准,引入了两个具有摄像机运动的大规模视频数据集。方法可以实现一些以前的视频合成工作无法实现的创造性应用,包括可播放的 3D 视频生成、风格化和编辑操作等。
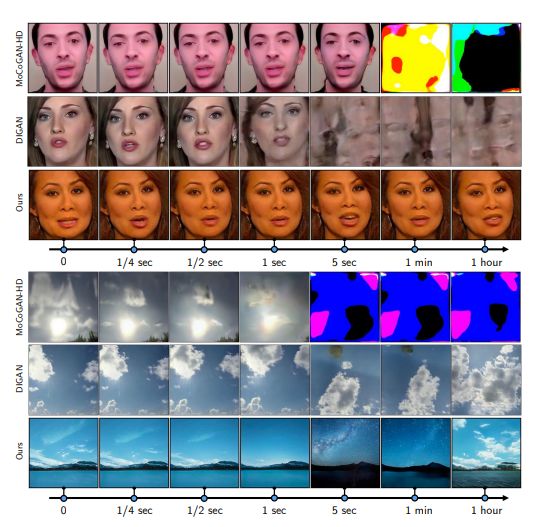
17、StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
视频可以展示连续的事件,但大多数视频合成框架在时间上离散地处理它们。这项工作考虑到视频的时间连续信号信息,扩展神经表示的范式以构建一个连续时间视频生成器。
为此,首先通过位置嵌入的镜头设计连续运动表示。然后,探讨了在非常稀疏的视频上进行训练的问题,并证明了一个好的生成器可以通过每个剪辑使用少至 2 帧来学习。之后,重新考虑了传统的图像+视频判别器配对,并设计了一个整体判别器,通过简单地连接帧的特征来聚合时间信息。这降低了训练成本,并为生成器提供了更丰富的学习信号,使得第一次可以直接在 10242 个视频上进行训练。
方法在 StyleGAN2 之上构建模型,以相同的分辨率进行训练同时实现几乎相同的图像质量,而仅增加 5% 的成本。此外,潜在空间具有相似的特性,方法可以及时传播空间操作。可以以任意高帧速率生成任意长的视频,而之前的工作很难以固定速率生成 64 帧。
项目网站:https://universome.github.io/stylegan-v
十、说话人驱动
18、FaceFormer: Speech-Driven 3D Facial Animation with Transformers
由于人脸可能有较复杂的几何形状和 3D 视听数据的有限可用性,语音驱动的 3D 面部动态化具有挑战性。先前的工作通常专注于学习具有有限上下文的短音频窗口的音素级特征,偶尔会导致嘴唇运动不准确。
为了解决这个限制,提出一个基于 Transformer 的自回归模型 FaceFormer,它对长期音频上下文进行编码并自回归预测一系列 3D 面部网格。
为了应对数据稀缺问题,整合了自监督的预训练语音表示。此外,设计了两种非常适合这一特定任务的有偏注意力机制,包括有偏的跨模态多头 (MH) 注意力和具有周期性位置编码策略的有偏的因果 MH 自注意力。前者有效地对齐音频运动模式,而后者提供了泛化到更长音频序列的能力。广泛的实验和感知用户研究表明,方法优于现有的最新技术。

19、Depth-Aware Generative Adversarial Network for Talking Head Video Generation
说话人生成可以合成人脸视频,包含分别来自给定源图像和驱动视频的身份和姿势信息。现有工作严重依赖从输入图像中学习的 2D 表示(例如外观和运动)。然而,密集的 3D 面部几何(例如像素深度)对于这项任务非常重要,因为它对我们从本质上生成准确的 3D 面部结构并将噪声信息与可能杂乱的背景区分开来特别有益。然而,密集的 3D 几何标注对于视频来说成本高得令人望而却步,并且通常不适用于此视频生成任务。
本文介绍一种自监督几何学习方法,可以自动从人脸视频中恢复密集的 3D 几何(即深度),而不需要任何昂贵的 3D 标注数据。基于学习到的密集深度图,利用它们来估计捕捉人头关键运动的稀疏面部关键点。深度还用于学习 3D 感知的跨模态(即外观和深度)注意力,以指导生成运动场以扭曲源图像表示。所有这些贡献构成了一个新的深度感知生成对抗网络(DaGAN)。大量实验表明,提出的方法可生成高度逼真的人脸,并在看不见的人脸上也取得显著的效果。

十一、图像编辑
20、High-Fidelity GAN Inversion for Image Attribute Editing
提出一种新的高保真生成对抗网络 (GAN) 逆映射框架,该框架能够在保留图像特定细节(例如背景、外观和照明)的情况下进行属性编辑。
首先从有损数据压缩的角度分析高保真 GAN 逆映射的挑战。由于潜码低比特率( low bitrate )的特点,以前的工作难以在重建和编辑的图像中保留高保真细节。增加潜码的大小可以提高 GAN 逆映射的准确性,但代价是可编辑性较差。
为在不影响可编辑性的情况下提高图像保真度,提出了一种失真咨询方法(distortion consultation approach),使用失真图作为高保真重建的参考。在DCI(distortion consultation inversion)中,首先将失真图投影到high-rate的潜码上,然后通过融合更多细节补充潜码的信息。为了实现高保真编辑,提出了一个自监督训练方案的自适应失真对齐 (ADA) 模块,它弥合了编辑图像和逆映射图像之间的差距。
广泛实验表明,逆映射和编辑质量都有明显的提高。https://tengfeiwang.github.io/HFGI/

21、Attribute Group Editing for Reliable Few-shot Image Generation
即使最先进的生成对抗网络 (GAN),少样本图像生成也是一项具有挑战性的任务。由于GAN训练过程不稳定,训练数据有限,生成的图像往往质量低,多样性低。
这项工作提出一种新的“基于编辑”的方法,即属性组编辑(Attribute Group Editing,AGE),用于少样本图像生成。思路是任何图像都是属性的集合,并且特定属性的编辑方向在所有类别中共享。AGE 检查在 GAN 中学习的内部表示并识别语义上有意义的方向。
具体来说,类嵌入,即来自特定类别的潜码均值向量,用于表示类别相关的属性,而与类别无关的属性是通过Sparse Dictionary Learning在样本嵌入和类嵌入间的差异学习而来。给定一个在已知类别上训练好的 GAN,可以通过编辑类别无关属性来合成未见类别的不同图像,同时保持类别相关属性不变。在不重新训练 GAN 的情况下,AGE 不仅能够为数据有限的下游视觉应用生成更逼真和多样化的图像,而且还能够实现具有可解释类别无关方向的可控图像编辑。
https://github.com/UniBester/AGE

十二、图像编辑-逆映射
22、HyperInverter: Improving StyleGAN Inversion via Hypernetwork
https://di-mi-ta.github.io/HyperInverter/
近年来,由于对 GAN 潜在空间的探索和利用,现实世界的图像处理取得了惊人的进展。GAN 逆映射是这种思路的第一步,旨在将真实图像映射到潜码。不幸的是,大多数现有的 GAN 逆映射方法至少不能满足下面列出的三个要求之一:高重建质量、可编辑性和快速推理。
本文提出一种新的两阶段策略,可同时满足所有要求。在第一阶段,训练一个编码器将输入图像映射到 StyleGAN2 W 空间,这被证明具有出色的可编辑性,但重建质量较低。在第二阶段,通过利用hypernetwork在逆映射过程中恢复丢失的信息来补充初始阶段的重建能力。由于Hypernetwork分支和由于在 W 空间中进行的逆映射,而具有出色的可编辑性,这两个步骤相互补充以产生高重建质量。方法完全基于编码器,因此推理速度快。在两个具有挑战性的数据集上进行的大量实验证明了方法的优越性。

23、HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
https://yuval-alaluf.github.io/hyperstyle/
将真实图像逆映射到 StyleGAN 的潜在空间中,这是得到了大量研究的问题。然而,由于重建和可编辑性之间的内在权衡,将现有方法应用于现实真实场景仍是一个挑战:可以准确表示真实图像的潜在空间区域通常会受到语义控制退化的影响。一些工作提出通过微调生成器的方法来缓解,但这种微调方案对于普遍使用是不切实际的,因为它需要对每个新图像进行漫长的训练阶段。
这项工作将这种方法引入基于编码器的逆映射,提出 HyperStyle,这是一个学习调制 StyleGAN 权重的超网络,以在潜在空间的可编辑区域中较好地表达给定的图像。一种简单的调制方法需要训练具有超过 30 亿个参数的超网络。通过仔细的网络设计,将其减少到与现有编码器一致。HyperStyle 产生的重建可与具有编码器近乎实时推理能力的优化技术相媲美。最后,本文展示了 HyperStyle 在逆映射任务之外的几个应用场景中的有效性,包括编辑在训练期间从未见过的域外图像。

24、Style Transformer for Image Inversion and Editing
现有的 GAN逆映射方法,无法同时提供用于可靠重建和灵活编辑的潜码空间。本文提出一种用于预训练 StyleGAN 的基于transformer的图像逆映射和编辑模型,该模型不仅失真小,而且具有高质量和编辑灵活性。所提出的模型采用 CNN 编码器来提供多尺度图像特征作为键和值。同时它将生成器的不同层要确定的风格码作为查询。它首先将查询标记初始化为可学习的参数,并将它们映射到 W+ 空间。然后利用多阶段交替自注意力和交叉注意力,更新查询以反转生成器的输入。此外,基于逆映射潜码,通过预训练的潜在分类器,研究了基于参考图像和标签的属性编辑,并实现了灵活的图像到图像转换和高质量的结果。
https://github.com/sapphire497/style-transformer

十三、图像超分
25、GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
人脸图像超分辨率常依靠面部先验来恢复真实细节并保留身份信息。在 GAN 先验的帮助下,最近的进展可以取得令人印象深刻的结果。但这些方法,要么设计复杂的模块,要么采用复杂的训练策略来微调生成器。
这项工作提出一种可控的人脸 SR 框架,称为 GCFSR(generative and controllable face SR framework),可以重建具有真实身份信息的图像,而无需任何额外的先验。设计了两个称为风格调制和特征调制的模块。风格调制生成逼真的面部细节,特征调制模块则动态融合多级编码特征和以放大因子为条件的生成特征。可以以端到端的方式从头开始训练简单而优雅的架构。
只有对抗性损失,对于小的放大因子(≤8),GCFSR 可以产生令人惊讶的好结果。加入 L1 和感知损失后,GCFSR 可以优于在大因子 (16, 32, 64)下也比最好方法更优。

26、Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution
生成对抗网络(GAN)在单图像超分辨率(SISR)任务中,由于其产生丰富细节的潜力而最近引起越来越多关注。然而GAN 训练不稳定的,常在生成细节中引入感知上不愉快的伪影。
本文训练基于 GAN 的 SISR 模型,以稳定生成感知逼真的细节,同时抑制视觉伪影。基于对伪影区域的局部统计数据常不同于感知友好细节区域的观察,开发了一个框架来区分 GAN 生成的伪影和真实细节。提出的局部判别学习(LDL)方法简单而有效,可容易地插入现成的 SISR 方法并提高它们的性能。实验表明,LDL 优于最先进的基于 GAN 的 SISR 方法,不仅在合成数据集和真实数据集上实现了更高的重建精度,而且还实现了卓越的感知质量。
https://github.com/csjliang/LDL

十四、图像去雨
27、Unpaired Deep Image Deraining Using Dual Contrastive Learning
https://cxtalk.github.io/projects/DCD-GAN.html
从一组未配对的干净和带雨图像中学习单图像去雨(single image deraining ,SID)网络是实用且有价值的,因为获取配对的真实世界数据几乎是不可行的。然而,如果没有配对数据作为监督,学习 SID 网络是具有挑战性的。此外,在 SID 任务中简单地使用现有的非配对学习方法(例如,非配对对抗学习和循环一致性约束)不足以学习从雨天输入到干净输出的潜在关系,因为雨天和干净图像之间存在显着的域差距。
本文提出一种有效的未配对 SID 对抗框架,通过深度特征空间中的双重对比学习方式探索未配对样本的相互属性,称为 DCDGAN。所提出的方法主要由两个协作分支组成:双向转换分支(Bidirectional Translation Branch ,BTB)和对比引导分支(Contrastive Guidance Branch,CGB)。具体来说,BTB 充分利用对抗性一致性的循环架构来生成丰富的样本对,并通过为其配备双向映射来挖掘两个域之间的潜在特征分布。同时,CGB 通过鼓励相似的特征分布更接近而将不相似的特征推得更远,从而隐式约束不同样本在深层特征空间中的嵌入,以更好地促进雨水去除并帮助图像恢复。
大量实验表明,方法在合成数据集和真实数据集上优于现有的非配对去雨方法,并与几个全监督或半监督模型产生可比较的结果

十五、图像修复
28、Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
近年来,图像修复取得了重大进展。然而,如何恢复具有清晰纹理和合理结构的受损图像仍是一项艰巨的任务。一些特定的方法只处理规则的纹理,而由于卷积神经网络(CNNs)的局部限制而忽略整体结构。另一方面,基于注意力的模型可以更好地学习结构恢复的长期依赖关系,但由于大图像推理计算量大受到限制。
本文提出增加一个结构恢复器,促进图像的渐进式修复。该模型在固定的低分辨率草图空间中,用基于注意力的transformer模型来恢复整体结构。代码发布在:https//github.com/dqiaole/zITS_inrow

29、MISF:Multi-level Interactive Siamese Filtering for High-Fidelity Image Inpainting
尽管现有深度生成的图像修复方法取得不错进展,但跨场景泛化差,与实际应用相去甚远,生成的图像通常包含伪影、填充像素与实际理想有很大差异。
本文研究了image-level predictive filtering在图像修复中的优势和挑战:该方法可以保留局部结构并避免伪影,但无法填充大的缺失区域。因而,提出在深度特征级别的语义filtering。
方法利用有效的语义和图像级别信息填充来进行高保真修复。https://github.com/tsingqguo/misf
30、MAT: Mask-Aware Transformer for Large Hole Image Inpainting
在修复问题中模拟远程交互非常重要。为了实现这一目标,现有方法利用独立的注意力技术或transformer,但考虑到计算成本,通常分辨率较低。
本文提出了一种新的基于transformer的大面积修复模型,它结合了transformer和卷积的优点来有效地处理高分辨率图像。精心设计框架的每个组件恢复图像的高保真度和多样性。
代码https://github.com/fenglinglwb/MAT

十六、图像外修复
31、Diverse Plausible 360-Degree Image Outpainting for Efficient 3DCG Background Creation
针对具有窄视野的单张图像,本文通过估计其周围环境来解决从生成 360 度图像的问题。以前的方法存在过拟合训练分辨率和确定性生成的问题。本文提出一种使用transformer 进行场景建模的补全方法以及改进输出图像上 360 度图像属性的新方法。
具体来说,使用带有transformer 的 CompletionNets 来执行各种补全,并使用 AdjustmentNet 来匹配输入图像的颜色、拼接和分辨率,从而能够以任何分辨率进行推理。为了改善输出图像上 360 度图像的属性,还提出WS 感知损失和循环推理。方法在定性和定量上都优于最先进的 (SOTA) 方法。此外,提出一个思路将结果用于 3DCG 场景的照明和背景。

十七、图像转换
32、Exploring Patch-wise Semantic Relation for Contrastive Learning in Image-to-Image Translation Tasks
最近,已提出基于对比学习的图像转换方法,这类方法对比不同的空间位置以增强空间对应性。但常忽略图像内的不同语义关系。
为了解决这个问题,提出了一种新的语义关系一致性(semantic relation consistency,SRC)正则化以及解耦对比学习,通过关注单张图像的图像块之间的异构语义来利用不同的语义。为了进一步提高性能,通过利用语义关系提出了一种hard negative mining。针对三个任务验证了方法:单模态和多模态图像转换,以及用于图像转换的 GAN 压缩任务。实验结果证实了方法在所有三个任务中的优越性。

33、FlexIT: Towards Flexible Semantic Image Translation
像GAN这类深度生成模型,极大地提高了图像合成的技术水平,并且能够在人脸等结构化数据域中生成逼真图像。最近的图像编辑工作通过将图像投影到 GAN 潜在空间并控制潜在向量来进行。但这些方法有数据的局限性,泛化性并非很好,且只能进行有限的编辑操作。
本文的 FlexIT,可采用任何输入图像和用户定义的文本指令进行编辑,实现灵活自然的编辑。首先,FlexIT 将输入图像和文本组合映射到CLIP 多模态嵌入空间中;通过自动编码器的潜在空间,将输入图像迭代地变换到目标点,通过各种正则化项确保连贯性和质量。本文还提出一种用于语义图像转换的评估方法。

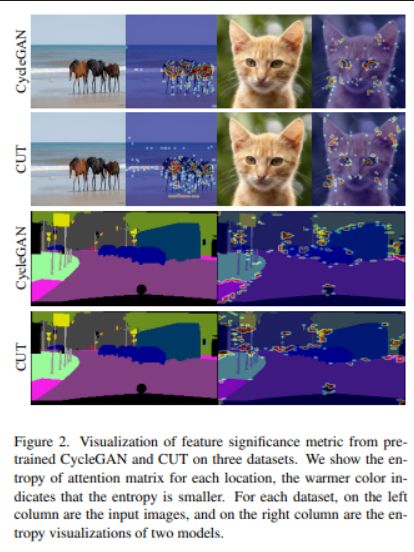
34、QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
未配对的图像到图像 (I2I) 转换通常需要在不同域中最大化源图像和转换后图像之间的互信息,这对于生成器保留源内容并防止其发生不必要的修改非常重要。自监督对比学习已经成功应用于 I2I,通过将来自同一位置的特征限制为比来自不同位置的特征更接近,它隐含地确保结果从源获取内容。但以前的工作使用来自随机位置的特征来施加约束,这可能不合适,因为某些位置包含的源域信息较少。
本文通过有意选择重要的锚点进行对比学习来解决这些问题,设计了一个查询选择注意(QS-Attn)模块,它比较源域中的特征距离,给出一个注意矩阵,每行都有一个概率分布。然后根据从分布计算的重要性度量来选择查询。选择的那些被认为是对比损失的锚。同时,减少的注意力矩阵用于在两个域中路由特征,以便在合成中保持源关系。
在三个不同的 I2I 数据集中验证提出的方法,表明在不添加可学习参数的情况下提高了图像质量。https://github.com/sapphire497/query-selected-attention
35、Modulated Contrast for Versatile Image Synthesis
感知图像之间的相似性一直是各种视觉生成任务中长期存在的基本问题。通过计算逐点绝对偏差来测量图像间距离,这往往会估计实例分布的中值并导致生成图像中的模糊和伪影。
本文的 MoNCE,是一种通用度量,引入了图像对比度来学习用于感知多方面图像间距离的校准度量。提出根据负样本与锚的相似性自适应地重新加权负样本,有助于从信息负样本中进行对比学习。由于图像距离测量涉及多个局部块级对比目标,因此在 MoNCE 中引入了最优传输,以在多个对比目标之间协同调节负样本的推动力。
对多个图像转换任务的广泛实验表明,所提出的 MoNCE 大大优于各种主流指标。

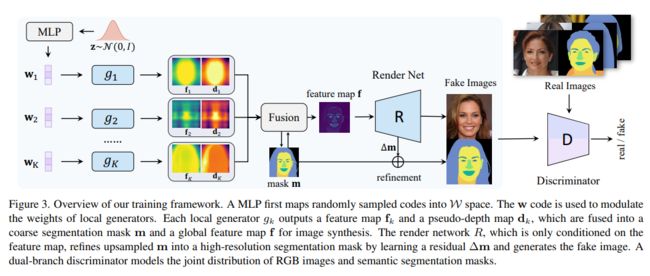
36、SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
https://semanticstylegan.github.io/
最近的研究表明,StyleGAN 为图像合成和编辑的下游任务提供了极具前景的先验模型。然而,由于 StyleGAN 的潜码旨在控制全局样式风格,因此很难实现对合成图像的细粒度控制。
本文提出 SemanticStyleGAN,其中一个生成器被训练来分别对局部语义部分进行建模,并以组合的方式合成图像。不同局部部分的结构和纹理由相应的潜码控制。实验结果表明,模型在不同的空间区域之间提供了强大的解耦。当与为 StyleGAN 设计的编辑方法相结合时,它可以实现更细粒度的控制来编辑合成或真实图像。
该模型还可以通过迁移学习扩展到其他领域。因此,作为具有内置解耦的通用先验模型,它可以促进基于 GAN 的应用程序的开发并实现更多潜在的下游任务。
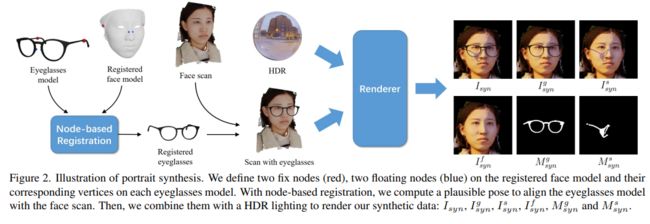
37、Portrait Eyeglasses and Shadow Removal by Leveraging 3D Synthetic Data
https://github.com/StoryMY/take-off-eyeglasses
在肖像中,眼镜可能会遮挡面部区域并产生投射阴影,这会降低面部验证和表情识别等许多技术的性能。去除人像眼镜对于处理这些问题至关重要。然而,完全取下眼镜具有挑战性,因为它们引起的照明效果(例如投射阴影)通常很复杂。
本文提出一种新的框架来去除眼镜及其从面部图像中投射的阴影。该方法以先检测后移除的方式工作,其中眼镜和投射阴影都被检测到,然后从图像中移除。由于缺乏用于监督训练的配对数据,提出了一个新的合成肖像数据集,其中包含用于检测和删除任务的中间和最终监督。此外,应用跨域技术来填补合成数据和真实数据之间的空白。据我们所知,所提出的技术是第一个同时移除眼镜及其投射阴影的技术。
38、Pix2NeRF: Unsupervised Conditional π-GAN for Single Image to Neural Radiance Fields Translation
https://github.com/primecai/Pix2NeRF
提出一种生成对象或特定类别场景的神经辐射场 (NeRF),以单输入图像为条件。这是一项具有挑战性的任务,因为训练 NeRF 需要同一场景的多个视图,以及难以获得的相应姿势。
方法基于 π-GAN,一种用于无条件 3D 感知图像合成的生成模型,它将随机潜在代码映射到一类对象的辐射场。联合优化 (1) π-GAN 目标以利用其高保真 3D 感知生成和 (2) 精心设计的重建目标。后者包括一个与 π-GAN 生成器耦合的编码器,以形成一个自动编码器。与以前的小样本 NeRF 方法不同,方法无监督,能够在没有 3D、多视图或姿势监督的情况下使用独立图像进行训练。方法的应用包括 3d 头像生成、使用单个输入图像的以对象为中心的新颖视图合成和 3d 感知超分辨率等。

39、Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation
https://github.com/batmanlab/MSPC
不成对的图像到图像转换 (I2I) 是一个不适定问题,它可以有无限数量的转换函数可以将源域分布映射到目标分布。因此,在设计合适的约束方面付出了很多努力,例如循环一致性 (CycleGAN)、几何一致性 (GCGAN) 和基于对比学习的约束 (CUTGAN)。然而,这些众所周知的约束有其局限性:(1)对于特定的 I2I 任务,它们要么过于严格,要么过于薄弱;(2) 当源域和目标域之间存在明显空间变化时,这些方法会导致内容失真。
本文提出一种称为最大空间扰动一致性 (maximum spatial perturbation consistency,MSPC) 的通用正则化技术,它强制空间扰动函数 (spatial perturbation function,T) 和translation operator(G) 是可交换的(即 T ◦ G = G ◦ T)。此外,引入了两个对抗性训练组件来学习空间扰动函数。第一个让 T 与 G 竞争以实现最大扰动。第二个让 G 和 T 与判别器竞争,以对齐由对象大小变化、对象失真、背景中断等引起的空间变化。
方法在大多数 I2I 基准测试中优于最先进的方法。还引入了一个新的基准,即从正面到侧面的人脸数据集,以强调 I2I 对现实世界应用程序的潜在挑战。最后进行消融实验来研究方法对空间扰动严重程度的敏感性及其对分布对齐的有效性。

40、Marginal Contrastive Correspondence for Guided Image Generation
基于样本的图像转换任务,在条件输入和样本(来自两个不同的域)之间建立了密集的对应关系,以利用详细的样本风格来实现逼真的图像转换。现有工作通过最小化两个域之间的特征距离来隐式地建立跨域对应关系。如果没有明确利用域不变特征,这种方法可能无法有效地减少域间隙,这通常会导致次优对应。
本文设计一个边际对比学习网络 (Marginal Contrastive Learning Network,MCL-Net),它探索对比学习以学习域不变特征,以实现基于示例的图像转换。然而,仅与域不变语义建立对应关系可能会损害纹理模式并导致纹理生成质量下降。因此,设计一个自相关图(Self-Correlation Map,SCM),它结合了场景结构作为辅助信息,大大改善了构建的对应关系。对多种图像转换任务的定量和定性实验表明,所提出的方法始终优于最先进的方法。

41、GAN-Supervised Dense Visual Alignment
https://www.wpeebles.com/gangealing
提出GAN 监督学习应用于密集的视觉对齐问题。受经典 Congealing 方法的启发,GANgealing 算法训练空间转换器,将随机样本从在未对齐数据上训练的 GAN 映射到常见的联合学习目标模式。
展示了八个数据集的结果,证明方法成功地对齐了复杂的数据并建立密集对应关系。GANgealing 优于过去的自监督对应算法,并且在几个数据集上的表现与(有时甚至超过)最先进的监督对应算法相当,这是在没有使用任何对应监督或数据增强,而只接受过关于GAN 生成数据的设置下。论文还展示了方法在增强现实、图像编辑和图像数据集自动预处理方面的应用。

十八、文字转图
42、Text to Image Generation with Semantic-Spatial Aware GAN
文本到图像合成(Text-to-image synthesis,T2I)旨在生成在语义上与文本描述一致的逼真图像。现有方法通常建立在条件生成对抗网络 (GAN) 之上,并使用句子特征嵌入从噪声中初始化图像,然后使用细粒度的词嵌入迭代地细化特征。但有个限制:即使生成的图像在整体上与描述相匹配,个别图像区域或某些东西的部分通常无法识别,或与句子中的单词表意一致。
为此,提出一种新的语义空间感知 GAN ,用于从输入文本中合成图像。具体来说,引入了一个简单有效的语义空间感知块,它(1)学习以文本为条件的语义自适应变换,以有效地融合文本特征和图像特征,以及(2)以弱监督的方式学习语义掩码,依赖于当前的文本图像融合过程,以便在空间上指导转换。
https://github.com/wtliao/text2image

十九、异常检测
43、Generative Cooperative Learning for Unsupervised Video Anomaly Detection
视频异常检测在弱监督和单分类 (one-class classification,OCC) 设置中得到了很好的研究。然而,无监督视频异常检测方法非常稀少,这可能是因为异常发生频率较低且通常定义不明确,再加上缺乏标签信息的监督,可能会对学习算法的性能产生不利影响。这个问题具有挑战性但也很有价值,因为它可以完全消除获得费力注释的成本,并使此类系统能够在没有人工干预的情况下进行部署。
本文提出了一种用于视频异常检测的新型无监督生成协作学习 (unsupervised Generative Cooperative Learning ,GCL) 方法,利用异常的低频来构建生成器和判别器之间的交叉监督。从本质上讲,两个网络都以合作的方式接受训练,实现无监督学习。对 UCF 犯罪和 ShanghaiTech 这两个大规模视频异常检测数据集进行了广泛的实验。

二十、隐私保护
44、Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-robust Makeup Transfer
https://github.com/CGCL-codes/AMT-GAN
虽然人脸识别(FR)系统在识别和验证方面表现出惊人的性能,但它们也因其对用户的过度使用而引起隐私问题,特别是对于社交网络上广泛传播的公共人脸图像。最近,一些研究采用对抗性示例来保护照片不被未经授权的人脸识别系统识别。然而,现有的对抗性人脸图像生成方法存在视觉尴尬、白盒设置、可迁移性弱等诸多局限,难以应用于现实中的人脸隐私保护。
本文提出对抗性妆容迁移 GAN (AMT-GAN),这是一种新的人脸保护方法,旨在构建对抗性人脸图像,同时保持更强的黑盒可迁移性和更好的视觉质量。AMT-GAN 利用生成对抗网络 (GAN) 来合成具有从参考图像迁移的妆容的对抗性面部图像。特别是,引入了一个新的正则化模块和一种联合训练策略,以协调对抗性噪声和妆容迁移中的循环一致性损失之间的冲突,在攻击强度和视觉变化之间取得理想的平衡。大量实验证明,与现有技术相比,AMT-GAN 不仅可以保持舒适的视觉质量,而且比商业 FR API 具有更高的攻击成功率。

二十一、语义生成
45、Interactive Image Synthesis with Panoptic Layout Generation
用户常常希望,可以控制生成图像的场景结构,从用户引导输入进行交互式图像合成是一项具有挑战性的任务。尽管基于布局的图像合成方法取得了一定进展,但为了在交互场景中获得逼真的假图像,现有方法需要高精度输入,可能需要多次调整,对新手用户不友好。当边界框的放置受到扰动时,基于布局的模型会在构建的语义布局中出现“缺失区域”,从而在生成的图像中出现不希望的伪影。
这项工作提出全景布局生成对抗网络 (Panoptic Layout Generative Adversarial Networks,PLGAN) 来应对这一挑战。PLGAN 将对象类别区分为具有无定形边界的部分(“stuff”),和具有明确定义的形状的部分(“things”),通过单独的分支构建,再融合到全景布局中。在 COCO-Stuff、Visual Genome 和 Landscape 数据集上通过实验将 PLGAN 与基于布局的最先进模型进行比较,优势不仅体现在视觉上,而且在IS、FID、分类准确度得分方面进行了定量验证

二十二、域适应
46、Unsupervised Domain Adaptation for Nighttime Aerial Tracking
https://github.com/vision4robotics/UDAT
先前在目标跟踪方面的进展大多忽略了夜间的性能,夜间条件阻碍了相关空中机器人应用的发展。本文提出一种用于夜间空中跟踪的新型无监督域适应框架(nighttime aerial tracking, UDAT)。具体来说,提供了一种对象发现方法来从原始夜间跟踪视频生成训练patch。为了解决域差异,在特征提取器上使用 Transformer 来对齐来自两个域的图像特征。使用 Transformer 日/夜特征判别器,日间跟踪模型经过对抗性训练,以在夜间进行跟踪。
此外,构建了一个开创性的基准,即 NAT2021,用于无监督域自适应夜间跟踪,其中包括 180 个手动注释跟踪序列的测试集和超过 276k 未标记的夜间跟踪帧的训练集。详尽的实验证明了所提出的框架在夜间空中跟踪中的鲁棒性和领域适应性。

二十三、姿势迁移
47、Exploring Dual-task Correlation for Pose Guided Person Image Generation
姿势引导的人物图像生成 (Pose Guided Person Image Generation,PGPIG) 是将人物图像从源姿势转换为给定目标姿势的任务。大多数现有方法无法捕获合理的纹理映射。为了解决这个问题,提出一种新的双任务姿态Transformer 网络( Dual-task Pose Transformer Network,DPTN),引入一个辅助任务(即源到源任务)并利用双任务相关性来提升 PGPIG 的性能。
DPTN包含‘源到源’的自重构分支、‘源到目标’生成的转换分支。通过在它们之间共享部分权重,源到源任务学习的知识可以有效地辅助源到目标的学习。此外,使用Pose Transformer Module (PTM) 将这两个分支连接起来,以自适应地探索双重任务的特征之间的相关性。这种相关性可以建立源和目标之间所有像素的细粒度映射,促进源纹理传输以增强生成的目标图像的细节。
大量实验表明,DPTN 在 PSNR 和 LPIPS 方面都优于最先进的技术。此外,DPTN 仅包含 979 万个参数,明显小于其他方法。https://github.com/PangzeCheung/Dual-task-PoseTransformer-Network

二十四、logo字体生成
48、Aesthetic Text Logo Synthesis via Content-aware Layout Inferring
文字类的LOGO设计在很大程度上依赖于专业设计师的创造力和专业知识,其中安排元素布局是最重要的流程之一。但很少有人关注这项需要考虑许多因素(例如字体、语言学、主题等)的任务。
本文提出一个内容感知的布局生成网络,该网络将字形图像及其相应的文本作为输入,并自动为它们合成美学布局。具体来说,设计了一个双判器模块,包括一个序列判别器和一个图像判别器,以分别评估字符放置轨迹和合成文本的渲染形状。此外,融合了来自文本的语言学信息和来自字形的视觉语义信息来指导布局预测,这两者在专业布局设计中都发挥着重要作用。
为了训练和评估方法,构建了一个名为 TextLogo3K 的数据集,由大约 3,500 个文本logo图像及其像素级的注释组成。对该数据集的实验研究证明了方法在合成视觉上令人愉悦的文本logo方面的有效性,并验证了其相对于现有技术的优越性。
https://github.com/yizhiwang96/TextLogoLayout

二十五、人脸/头部交换
49、Few-Shot Head Swapping in the Wild
头部交换任务,旨在将 源头部 完美地放置在目标身体上,这对于各种娱乐场景都非常重要。虽然换脸引起了很多关注,但换头的任务很少被探索,尤其是在少样本设置下。由于其在头部建模和背景混合方面的独特需求,它本质上具有挑战性。
本文提出 Head Swapper (HeSer),它通过两个精心设计的模块实现少样本的头部交换。首先,设计了一个 Head2Head Aligner,通过多尺度信息,将姿势和表情信息从目标整体迁移到源头部。其次,为了解决交换过程中肤色变化和头部背景不匹配的挑战,引入了 Head2Scene Blender 来同时修改面部肤色并填充头部周围背景中不匹配问题。
https://jmliu88.github.io/HeSer/

50、High-resolution Face Swapping via Latent Semantics Disentanglement
用预训练GAN 模型的固有先验知识,提出一种新的高分辨率人脸交换方法。尽管先前的研究可以利用生成先验来产生高分辨率结果,但它们的质量可能会受到潜在空间纠缠语义的影响。
本文通过利用生成器的渐进性,从浅层派生结构属性和从更深层派生外观属性,明确地解开潜在语义。结构属性中的身份和姿势信息通过引入关键点驱动的结构转移潜在方向进一步分离。解开的潜码产生丰富的生成特征,这些特征混合产生合理的交换结果。通过对潜在空间和图像空间实施两个时空约束,进一步扩展到视频人脸交换。大量实验表明,所提出方法在质量和一致性方面优于最先进的图像/视频人脸交换方法。
代码:https://github.com/cnnlstm/FSLSD_HiRes

猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
一顿午饭外卖,成为CV视觉的前沿弄潮儿!
ICCV 2021 | 35个GAN主题,最全GAN论文汇总
超110篇!CVPR 2021最全GAN论文汇总梳理!
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
