SMP-EWECT-如何利用pytorch transformers实现一个bert分类模型(第一篇)
如何利用pytorch transformers实现一个bert分类模型
- 说在前面的话
- 比赛简介
-
- 数据分析
- Bert Baseline搭建
-
- Bert初探
- 数据读取
- 数据加载
- 模型训练
- 模型的评估与保存
- 超参数的设置
- 总结
说在前面的话
假期期间参加了一个情感分析的比赛,smp的ewect任务,侥幸获得了三等奖,希望可以通过这边博客记录一下自己从零开始做比赛的心得,希望各位不吝指正。这是这个系列的第一篇,我将在这里面介绍一下比赛开始是我们对数据的分析,并用pytorch的transformers框架搭建一个baseline分类模型。
比赛简介
这个比赛所用的预料多数来自微博数据,情感分析任务可以简化为一个分类问题。
数据分析
在本次评测中,微博按照其蕴含的情绪分为以下六个类别之一:积极、愤怒、悲伤、恐惧、惊奇和无情绪;按照数据所在领域可以分为两类:通用与疫情。
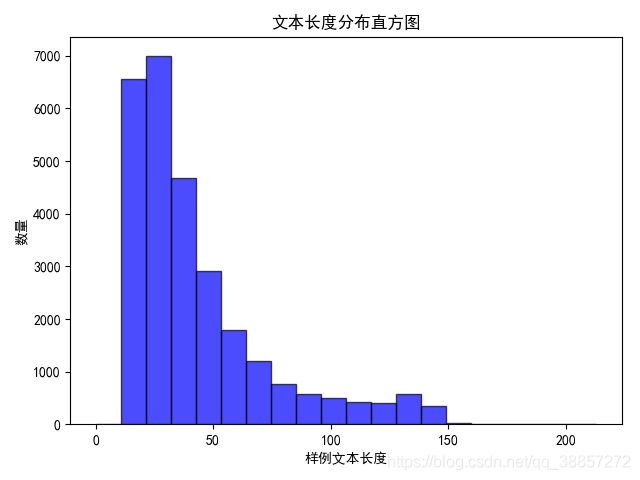
为了确定模型输入的最佳长度,我们先对输入的文本数据进行了长度分析,对两部分预料的统计结果如下:
- usual文本长度分布
- virus文本长度分析
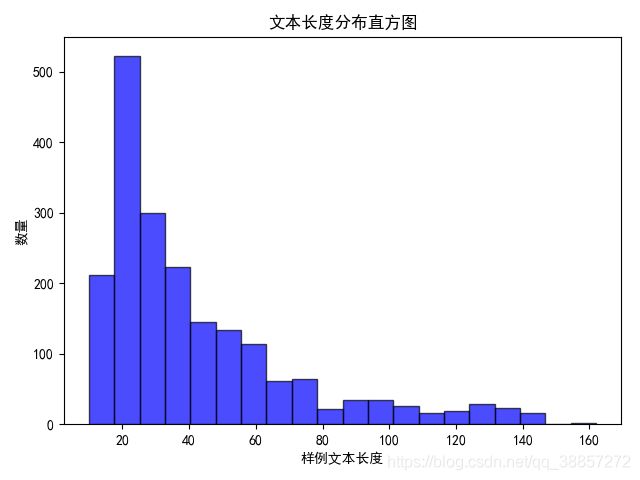
根据上述数据得到的数据分布,我们最终采用150作为数据的最长长度,这里提一下,由于bert的multi-head attention结构,运行的时间复杂度与sequence length大概是 n 2 n^2 n2的关系。而且随着sequence length的增加,程序所占的显存也会明显增加。(这里提出一个小问题,希望有人能给予回答,multi-head attention中运用mask矩阵将超出句子真实长度的attention权重设置为0,从而将pad的字符mask掉。这里想问一下,如果将长度设置的很长,会影响模型的精度吗?)
接下来我们对数据的类别进行了分析,发现各个类别的数据分布非常不均衡,尤其是在疫情数据集中尤其明显,这里暂且不说,接下来说说如何利用transformers搭建一个baseline,如何去训练和预测模型。
Bert Baseline搭建
Bert是由google提出的一个预训练模型,全名是双向transformers编码器表示,这里不说具体的原理,感兴趣的同学可以去网上查阅资料,这里主要说下使用。Bert发布后,引起了各大公司和高校的兴趣,开始对Bert的结果和训练方法上进行了自己的改进,如百度的ERNIE,哈工大的Bert-wwm等,随着模型的数量越来越多,Transformers随之出现,它的前身是pytorch-pretrained-bert这个库,原本是为了解决pytorch加载基于tensorflow训练的bert模型而出现的,随着时间的发展,这个库现在可以直接加载一众预训练模型,包括Roberta,Albert,Electra等(ps 百度的ERNIE是基于PaddlePaddle框架的,这个库暂时不支持直接加载下载的权重,有需要的同学可以找网上的转化脚本)。此外该库还提供了一个所有模型的下载地址
Bert初探
想要使用预训练模型,我们首先要把它加载到内存里,Transformers对这个过程进行了封装,我们调用下面代码就可以直接实现了,config加载的是模型的config文件,主要是模型的一些超参数,embedding shape,num layers等,model加载的是模型的weight文件,主要是模型每一层的权重是多少。tokenizer加载的是vocab文件,这个类还包含了一些将数据句子转化为模型输入token的功能。
from transformers import BertConfig, BertForSequenceClassification, BertTokenizer
config = BertConfig.from_pretrained('你的Bert下载路径',num_labels=6)
model = BertForSequenceClassification.from_pretrained(
'你的Bert下载路径',
config=config)
tokenizer = BertTokenizer.from_pretrained('你的Bert下载路径')
利用上述代码我们就可以将预训练的模型加载到我们的电脑中了,接下来我们试着使用一下。
input_text = "我是一个自然语言处理爱好者"
inputs = tokenizer.encode_plus(input_text)
print(inputs)
{'input_ids': [101, 2769, 3221, 671, 702, 5632, 4197, 6427, 6241, 1905, 4415, 4263, 1962, 5442, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
我们可以看到,通过tokenizer的encode_plus函数,我们得到了一个键值对,分别对应与bert的不同类型输入,这里没有生成position_ids是由于当输入未提供position_ids时,模型会根据输入自行生成对应的position_ids。注,position_ids和输入的内容无关,只和句子的长度有关,因此将其放在了模型的内部来生成。
transformers库为我们提供了一个分类的基础模型BertForSequenceClassification,下面我们定义该模型的输入,该模型forward的原型如下:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
labels=None,
):
在上述所需的输入中,我们还需要输入该文本对应的labels,代表每句文本对应的标签id。
下面我们试着调用这个模型。
import torch
input_ids = torch.tensor(input_ids, dtype=torch.long)
token_type_ids = torch.tensor(token_type_ids, dtype=torch.long)
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
labels = torch.tensor(labels, dtype=torch.long)
output = model(input_ids = input_ids,
token_type_ids = token_type_ids,
attention_mask = attention_mask,
labels = labels)
loss, logits = outputs[0], outputs[1]
通过上述我们已经基本了解如何将一句话送入Bert进行分类。
下面我们针对本次任务构建一个包括训练和预测到代码
数据读取
打开本次比赛的数据,我么
我们一般训练模型时,都会将多句话同时送入模型,一方面是为了利用模型的并行计算提高计算效率,另一方面,尽可能大的batch size也会提高模型的稳定性与泛化效果。由于每个句子的长度不同,我们无法将其同时将其送入模型中进行训练,所以我们需要将句子的input_ids,token_type_ids,padding到同一长度。并通过attention_mask来指示各个padding后结果的真实长度。
input_texts = ["我是一个自然语言处理爱好者", "我是一个自然语言处理爱好者", "我是一个自然语言处理爱好者"]
labels = ['neural', 'neural', 'neural']
# 由于模型的输入应为一个数值,我们将label 映射到一个数字
labels = ['angry', 'surprise', 'fear', 'happy', 'sad', 'neural']
label_map = {label: i for i, label in enumerate(label_list)}
# 为了方便后续的操作,我们定义一个模型类,用于存放模型输入的各个部分
class SentimentInputFeatures(object):
def __init__(self, input_ids, attention_mask, token_type_ids, label):
self.input_ids = input_ids
self.attention_mask = attention_mask
self.token_type_ids = token_type_ids
self.label = label
# 模型输入应为一个batch size * sequence length的矩阵,
#为了应对同一batch中句子长度不同的问题,我们利用0将其pad到同一长度
for example in examples:
input = tokenizer.encode_plus(
text=example,
max_length=max_length,
truncation=True,
)
input_ids, token_type_ids, attention_mask = \
inputs["input_ids"], inputs["token_type_ids"], inputs["attention_mask"]
padding_length = max_length - len(input_ids)
input_ids = input_ids + ([1] * padding_length)
attention_mask = attention_mask + ([0] * padding_length)
token_type_ids = token_type_ids + ([0] * padding_length)
label = int(label_map[example.label])
features.append(
SentimentInputFeatures(input_ids, attention_mask, token_type_ids, label)
)
return features
经过上述处理,我们将输入句子转化成了一系列features列表。
数据加载
torch中加载数据主要通过一个DataLoader类,我们通过下述代码来初始化一个DataLoader实例。
train_dataloader = DataLoader(train_dataset,
sampler=train_sampler,
batch_size=train_batch_size,
collate_fn=collate_batch)
我们前面说过了,在训练过程中我们以一个个batch的形式来训练整个数据集,每个batch都是从数据集中抽样而来,sampler决定了数据的抽样方式,我们一般使用torch.utils.data中的RandomSampler、SequentialSampler。collate_fn,会在生成一个batch之前调用。
for batch in data_loader:
......
在产生这个batch之前,会调用data_loader的collate_fn函数。这里借鉴transformers库中的写法,定义collate_fn如下:
def collate_batch(features):
first = features[0]
if hasattr(first, "label") and first.label is not None:
if type(first.label) is int:
labels = torch.tensor([f.label for f in features], dtype=torch.long)
else:
labels = torch.tensor([f.label for f in features], dtype=torch.float)
batch = {"labels": labels}
for k, v in vars(first).items():
if k not in ("label", "label_ids") and v is not None and not isinstance(v, str):
batch[k] = torch.tensor([getattr(f, k) for f in features], dtype=torch.long)
上述代码主要想将features转化为模型输入的key-value对形式,key即为模型的输入参数,value即为模型参数对应的输入值。
模型训练
- 梯度下降
for step, batch in enumerate(train_dataloader):
model.train()
inputs = {}
for k, v in batch.items():
inputs[k] = v.to(args.device)
outputs = model(**inputs)
loss, logits = outputs[0], outputs[1]
# logging.info('*** loss = %f ***',loss)
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
- 梯度累计
这里使用了args.gradient_accumulation 这个用于对梯度进行累计更新,以模拟更大的batch size。比如对两个batch size为4的batch进行累计,就相当于进行了一个batch size为8的batch。
上述的loss.backward仅仅只是对传入样本进行反向传播,之后进行梯度累计。模型的真正更新需要放在下面这一步
if (step + 1) % args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(),args.max_grad_norm)
optimizer.step()
model.zero_grad()
optimizer.step是用于对模型累计梯度的更新,zero_grad用于对累计梯度的清零,不然梯度会在训练中不断累计。
- warm up and weight decay
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。关于warm up 的作用可以参考这篇文章
# 计算总共的更新步骤,也就是warm up要进行的步骤。
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# 定义不需要weight decay的参数,这里的愿意,我也不太清楚,手动狗头
no_decay = ['bias', 'LayerNorm.weight', 'transitions']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters,lr=args.learning_rate,eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
之后在上述更新梯度的步骤中加入下面一行代码,来改变学习率,实现warm up
optimizer.step()
# 加入代码
scheduler.step()
model.zero_grad()
模型的评估与保存
上述过程中我们已经可以实现一个模型对于数据的训练过程了。在这个训练过程中,模型对于训练数据的loss会不断下降直到0为止。但是,通常情况下,我们并不是用训练集开评估模型的好坏,而是用一个在训练集中从未出现的样本集合来作为测试集,以此来评估模型对于一个任意数据的学习能力。为此我们需要使用一个dev数据集,来进行模型的选择,这个dev数据集也是从未在训练集中出现的样本集合。综上,我们一般会对数据集划分如三,train、dev、test。train用于对数据的训练,dev用于对模型的选择,test用于最终测试模型的结果好坏。
if (global_step % 50 == 0 and global_step <= 100) or(global_step % 100 == 0 and global_step < 1000) \
or (global_step % 200 == 0):
best_acc = evaluate_and_save_model(args,model,eval_dataset,_,global_step,best_acc)
上述定义了一个golbal_step变量,每间隔一定的时间,会对当前的模型在dev上进行评估,如果效果超越了之前的模型就把当前的模型进行保存。
def evaluate_and_save_model(args, model, eval_dataset,epoch, global_step, best_f_score, best_epoch, k_fold=None):
eval_loss, label_acc, label_f_score = evaluate(args, model, eval_dataset)
# logging.info("Evaluating EPOCH = [%d/%d] global_step = %d eval_loss = %f label_acc = %f label_f_score = %f",
# epoch + 1, args.num_train_epochs,global_step,eval_loss, label_acc, label_f_score)
if label_f_score > best_f_score:
best_f_score = label_f_score
best_epoch = epoch
improve = '*'
model.save_pretrained(args.output_dir)
else:
improve = ''
msg = ' Iter: {0:>6}, Val Loss: {1:>5.2}, Val F1: {2:>6.2%}, Val Acc: {3:>6.2%}, {4}'
logging.info(msg.format(global_step, eval_loss, label_f_score, label_acc,improve))
return best_f_score, best_epoch
评估函数如下,后面的测试函数和评估函数基本一致。
def evaluate(args, model, eval_dataset,is_test=False):
eval_output_dirs = args.output_dir
if not os.path.exists(eval_output_dirs):
os.makedirs(eval_output_dirs)
eval_sampler = SequentialSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset,
sampler=eval_sampler,
batch_size=args.eval_batch_size,
collate_fn=collate_batch)
# logging.info("***** Running evaluation *****")
# logging.info(" Num examples = %d", len(eval_dataset))
# logging.info(" Batch size = %d", args.eval_batch_size)
total_loss = 0. # loss 的总和
total_sample_num = 0 # 样本总数目
preds = None # 记录所有样本的预测值
out_label_ids = None # 记录所有样本的真实值
# for batch in tqdm(eval_dataloader, desc="Evaluating"):
for batch in tqdm(eval_dataloader):
model.eval()
with torch.no_grad():
inputs = {}
for k, v in batch.items():
inputs[k] = v.to(args.device)
outputs = model(**inputs)
loss, logits = outputs[0], outputs[1]
# 为了应对最后一个batch数目不足batch size的情况
total_loss += loss * list(batch.values())[0].shape[0] # loss * 样本个数
total_sample_num += list(batch.values())[0].shape[0] # 记录样本个数
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
loss = total_loss / total_sample_num
preds = np.argmax(preds, axis=1)
label_f_score = f1_score(y_true=out_label_ids, y_pred=preds, average='macro')
label_acc = accuracy_score(out_label_ids, preds)
model.train()
if is_test:
report = classification_report(y_true=out_label_ids, y_pred=preds, target_names=eval_dataset.get_labels(),digits=4)
confusion = confusion_matrix(y_true=out_label_ids, y_pred=preds)
return loss, label_acc, label_f_score,report,confusion
return loss, label_acc, label_f_score
至此模型的训练和评估已经基本完成。
超参数的设置
在训练过程中我们需要指定一些超参数和一些路径,可以通过argparser中的ArgumentParser类来实现。
parser = argparse.ArgumentParser()
parser.add_argument("--log_dir", default="roberta_wwm_sentiment.log", type=str, required=True,
help="设置日志的输出目录")
总结
综上,我们定义一个模型首先需要定义数据加载部分,这个部分可以通过定义若干类来实现,通过类来将各个参数和值进行绑定。之后通过定义data loader的callate_fn来将类转化为模型所需要的输入格式。
之后我们需要定义模型,这里我们使用transformers中定义的BertForSequenceClassification类来实现,在后续文章中,我们对这个基本模型进行改进,制定更过个性化的模型。
最后我们定义模型的训练、评估与保存过程,来进行模型的训练。完整的代码可以访问我的github来获取。