《学术小白的学习之路 07》自然语言处理之 LDA主题模型 01
本文主要是学习参考杨秀璋老师的博客,笔记总结与记忆。
原文链接
文章目录
- 书山有路勤为径,学海无涯苦作舟(行行代码要手敲)
- 零、吃水不忘挖井人
- 一、LDA主题模型
-
- 1.1简介
- 1.2安装
- 二、LDA主题识别
-
- 2.1前期操作
-
- 2.1.1生成TF-IDF文本权重矩阵
- 2.1.2 调用LDA模型
- 2.2 计算文档的主题分布
- 2.3 主题关键词的Top-N
- 2.4 可视化处理
-
- (1) 文档-主题分布图
- (2) 主题-词语分布图
书山有路勤为径,学海无涯苦作舟(行行代码要手敲)

零、吃水不忘挖井人
原文链接
一、LDA主题模型
1.1简介
LDA(文档主题生成模型)通常由包含词、主题和文档三层结构组成。
LDA模型属于无监督学习,它是将一篇文档的每个词都以一定概率分布在某个主题上,并从这个主题中选择某个词语。
文档到主题的过程是服从多项分布的,主题到词的过程也是服从多项分布的。
文档主题生成模型(又称为盘子表示法(Plate Notation),下图是模型的标示图,其中双圆圈表示可测变量,单圆圈表示潜在变量,箭头表示两个变量之间的依赖关系,矩形框表示重复抽样,对应的重复次数在矩形框的右下角显示。LDA模型的具体实现步骤如下:
- 从每篇网页D对应的多项分布θ中抽取每个单词对应的一个主题z。
- 从主题z对应的多项分布φ中抽取一个单词w。
重复步骤(1)(2),共计Nd次,直至遍历网页中每一个单词。

1.2安装
从gensim中下载ldamodel扩展包安装,也可以使用Sklearn机器学习包的LDA子扩展包,也可从github中下载开源的LDA工具。下载地址如下所示。
gensim:https://radimrehurek.com/gensim/models/ldamodel.html
scikit-learn:利用pip install sklearn命令安装扩展包,LatentDirichletAllocation函数即为LDA原型
github:https://github.com/ariddell/lda
也可以使用的是通过“pip install lda”安装的官方LDA模型。
pip install lda
二、LDA主题识别
Python的LDA主题模型分布可以进行多种操作,常见的包括:
- 输出每个数据集的高频词TOP-N
- 输出文章中每个词对应的权重及文章所属的主题
- 输出文章与主题的分布概率,文本一行表示一篇文章,概率表示文章属于该类主题的概率;
- 输出特征词与主题的分布概率,这是一个K*M的矩阵,K为设置分类的个数,M为所有文章词的总数。
2.1前期操作
2.1.1生成TF-IDF文本权重矩阵
先要对文本数据进行分词和数据的清洗操作,对清洗完的数据进行生成文本的权重矩阵。
#coding=utf-8
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#读取语料
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) #计算个词语出现的次数
word = vectorizer.get_feature_names() #获取词袋中所有文本关键词
#计算TF-IDF值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X) #将词频矩阵X统计成TF-IDF值
#查看数据结构 输出tf-idf权重
print(tfidf.toarray())
weight = tfidf.toarray()
2.1.2 调用LDA模型
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit(X)
#model.fit_transform(X)
参数n_topics表示设置3个主题,n_iter表示设置迭代次数500次,并调用fit(X)或fit_transform(X)函数填充训练数据.
2.2 计算文档的主题分布
老师的语料数据一共9行文本,每一行文本对应一个主题,其中1-3为贵州主题,4-6为数据分析主题,7-9为爱情主题。
现在使用LDA文档主题模型预测各个文档的主体分布情况,即计算文档-主题(Document-Topic)分布,输出9篇文章最可能的主题代码如下。
#coding=utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import lda
import numpy as np
#生成词频矩阵
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
#LDA分布
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit(X)
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("shape: {}".format(doc_topic.shape))
for n in range(9):
topic_most_pr = doc_topic[n].argmax()
print(u"文档: {} 主题: {}".format(n,topic_most_pr))
2.3 主题关键词的Top-N
计算主题-词语(Topic-Word)分布
代码如下所示,首先分别计算各个主题下的关键词语。
#主题-单词(Topic-Word)分布
word = vectorizer.get_feature_names()
topic_word = model.topic_word_
for w in word:
print(w,end=" ")
print('')
n = 5
for i, topic_dist in enumerate(topic_word):
topic_words = np.array(word)[np.argsort(topic_dist)][:-(n+1):-1]
print(u'*Topic {}\n- {}'.format(i, ' '.join(topic_words)))
过代码计算各个主题通过LDA主题模型分析之后的权重分布,代码如下:
#主题-单词(Topic-Word)分布
print("shape: {}".format(topic_word.shape))
print(topic_word[:, :3])
for n in range(3):
sum_pr = sum(topic_word[n,:])
print("topic: {} sum: {}".format(n, sum_pr))
2.4 可视化处理
(1) 文档-主题分布图
#coding=utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import lda
import numpy as np
#生词频矩阵
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
#LDA分布
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit_transform(X)
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("shape: {}".format(doc_topic.shape))
for n in range(9):
topic_most_pr = doc_topic[n].argmax()
print("文档: {} 主题: {}".format(n+1,topic_most_pr))
#可视化分析
import matplotlib.pyplot as plt
f, ax= plt.subplots(9, 1, figsize=(10, 10), sharex=True)
for i, k in enumerate([0,1,2,3,4,5,6,7,8]):
ax[i].stem(doc_topic[k,:], linefmt='r-',
markerfmt='ro', basefmt='w-')
ax[i].set_xlim(-1, 3) #三个主题
ax[i].set_ylim(0, 1.0) #权重0-1之间
ax[i].set_ylabel("y")
ax[i].set_title("Document {}".format(k+1))
ax[4].set_xlabel("Topic")
plt.tight_layout()
plt.savefig("result.png")
plt.show()
它是计算文档Document1到Document9各个主题分布情况。X轴表示3个主题,Y轴表示对应每个主题的分布占比情况。如果某个主题分布很高,则可以认为该篇文档属于该主题。例如Document1、Document7和Document8在第1个主题分布最高,则可以认为这两篇文章属于主题1。

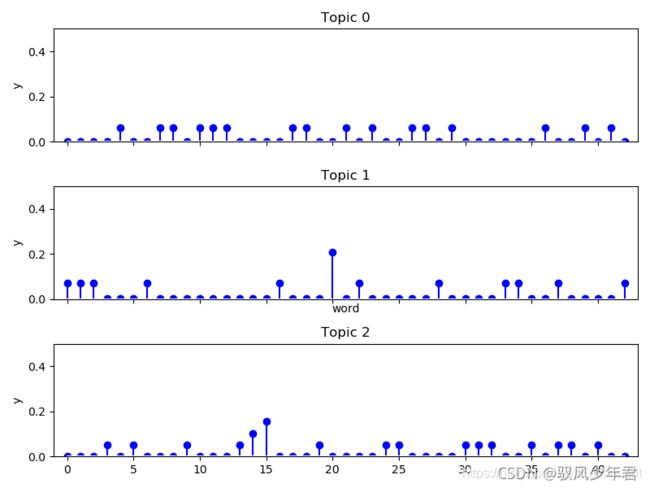
(2) 主题-词语分布图
该图用于计算各个单词的权重,供43个特征或单词。
#coding=utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import lda
import numpy as np
#生词频矩阵
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
#LDA分布
model = lda.LDA(n_topics=3, n_iter=500, random_state=1)
model.fit_transform(X)
#文档-主题(Document-Topic)分布
doc_topic = model.doc_topic_
print("shape: {}".format(doc_topic.shape))
for n in range(9):
topic_most_pr = doc_topic[n].argmax()
print(u"文档: {} 主题: {}".format(n+1,topic_most_pr))
topic_word = model.topic_word_
#可视化分析
import matplotlib.pyplot as plt
f, ax= plt.subplots(3, 1, figsize=(8,6), sharex=True) #三个主题
for i, k in enumerate([0, 1, 2]):
ax[i].stem(topic_word[k,:], linefmt='b-',
markerfmt='bo', basefmt='w-')
ax[i].set_xlim(-1, 43) #单词43个
ax[i].set_ylim(0, 0.5) #单词出现频率
ax[i].set_ylabel("y")
ax[i].set_title("Topic {}".format(k))
ax[1].set_xlabel("word")
plt.tight_layout()
plt.savefig("result2.png")
plt.show()
计算主题topic0、topic1、topic2各个单词权重分布情况。横轴表示43个单词,纵轴表示每个单词的权重。