【pytorch基础学习笔记】零基础速成,了解pytorch基础语法和应用
目录
1.pytorch简介
2.pytorch环境安装
3.pytorch入门
Tensors (张量)
pytorch自动微分
pytorch神经网络
1.pytorch简介
Torch是一个有大量机器学习算法支持的科学计算框架,是一个与Numpy类似的张量(Tensor) 操作库,其特点是特别灵活,但因其采用了小众的编程语言是Lua,所以流行度不高,这也就有了PyTorch的出现。所以其实Torch是 PyTorch的前身,它们的底层语言相同,只是使用了不同的上层包装语言。
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。
PyTorch提供了两个高级功能: 具有强大的GPU加速的张量计算(如Numpy); 包含自动求导系统的深度神经网络;
和tensorflow相比:
TensorFlow和Caffe都是命令式的编程语言,而且是静态的,首先必须构建一个神经网络,然后一次又一次使用相同的结构,如果想要改 变网络的结构,就必须从头开始。但是对于PyTorch,通过反向求导技术,可以让你零延迟地任意改变神经网络的行为,而且其实现速度 快。正是这一灵活性是PyTorch对比TensorFlow的最大优势。PyTorch的代码对比TensorFlow而言,更加简洁直观,底层代码也更容易看懂。
pytorch优点:支持GPU 、灵活、支持动态神经网络 、底层代码易于理解 、 命令式体验 、自定义扩展。
缺点:不支持快速傅里 叶、沿维翻转张量和检查无穷与非数值张量;针对移动端、嵌入式部署以及高性能服务器端的部署其性能表现有待提升。框架较新,社区没有那么强大。
2.pytorch环境安装
安装anaconda(Anaconda是一个用于科学计算的Python发行版,支持Linux、Mac和Window系统,提供了包管理与环境管理的功能,可以很方便地解决Python并存、切换,以及各种第三方包安装的问题)
官网下载:Anaconda | Individual Edition
安装完成后,进行Anaconda的环境变量配置,打开控制面板->高级系统设置->环境变量->系统变量找到Path,点击编辑,加入三个文件夹的存储路径(注意三个路径之间需用分号隔开)
至此,Anaconda 3.5 windows版就安装设置好了,打开程序找到Anaconda Navigator,启动后即可看到相关界面。
安装pytorch:PyTorch
使用pip: windows+pip+python3.7+None
使用conda: windows+conda+python3.7+None
验证是否安装成功:打开Anaconda的Jupyter新建python文件,运行demo
3.pytorch入门
什么是pytorch?
PyTorch 是一个基于 Python 的科学计算包,主要定位两类人群:
- NumPy 的替代品,可以利用 GPU 的性能进行计算。
- 深度学习研究平台拥有足够的灵活性和速度
基础知识
Tensors (张量)
Tensors (张量):类似于 NumPy 的 ndarrays ,同时 Tensors 可以使用 GPU 进行计算。
from __future__ import print_function
import torch#构造一个5x3矩阵,不初始化
x = torch.empty(5, 3)
print(x)
#构造一个随机初始化的矩阵
x = torch.rand(5, 3)
print(x)#构造一个矩阵全为 0,而且数据类型是 long.
x = torch.zeros(5, 3, dtype=torch.long)
print(x)#构造一个张量,直接使用数据:
x = torch.tensor([5.5, 3])
print(x)#创建一个 tensor 基于已经存在的 tensor。
x = x.new_ones(5, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
print(x)
#获取其维度信息
print(x.size())
#输出
torch.Size([5, 3])注意:torch.Size 是一个元组,所以它支持左右的元组操作
#加法1
y = torch.rand(5,3)
print(x+y)
#加法2
ptint(torch.add(x+y))
#提供一个输出tensor作为参数
result = torch.empty(5,3)
torch.add(x,y,out=result)
print(result)
#加法: in-place
y.add_(x)
print(y)#改变大小:如果你想改变一个 tensor 的大小或者形状,你可以使用
x = torch.randn(4,4)
y=x.view(16)
z=x.view(-1,8)
print(x.size(),y.size(),z.size())
#如果你有一个元素 tensor ,使用 .item() 来获得这个 value
x= torch.randn(1)
print(x)
print(x.item)
pytorch自动微分
autograd 包是 PyTorch 中所有神经网络的核心。
该 autograd 软件包为 Tensors 上的所有操作提供自动微分。它是一个由运行定义的框架,这意味着以代码运行方式定义你的后向传播,并且每次迭代都可以不同。
tensor
torch.Tensor 是包的核心类。如果将其属性 .requires_grad 设置为 True,则会开始跟踪针对 tensor 的所有操作。完成计算后,您可以调用 .backward() 来自动计算所有梯度。该张量的梯度将累积到 .grad 属性中。
要停止 tensor 历史记录的跟踪,您可以调用 .detach(),它将其与计算历史记录分离,并防止将来的计算被跟踪。
要停止跟踪历史记录(和使用内存),您还可以将代码块使用 with torch.no_grad(): 包装起来。在评估模型时,这是特别有用,因为模型在训练阶段具有 requires_grad = True 的可训练参数有利于调参,但在评估阶段我们不需要梯度。
还有一个类对于 autograd 实现非常重要那就是 Function。Tensor 和 Function 互相连接并构建一个非循环图,它保存整个完整的计算过程的历史信息。每个张量都有一个 .grad_fn 属性保存着创建了张量的 Function 的引用,(如果用户自己创建张量,则g rad_fn 是 None )。
如果你想计算导数,你可以调用 Tensor.backward()。如果 Tensor 是标量(即它包含一个元素数据),则不需要指定任何参数backward(),但是如果它有更多元素,则需要指定一个gradient 参数来指定张量的形状。
import torch
#创建一个张量,设置 requires_grad=True 来跟踪与它相关的计算
x = torch.ones(2,2,requires_grad=True)
print(x)
#针对张量做一个操作
y = x+2
print(y)
#y作为操作的结果被创建,所以它有 grad_fn
print(y.grad_fn)
#针对y做更多的操作
z = y*y*3
out=z.mean()
print(z,out)
#.requires_grad_( ... ) 会改变张量的 requires_grad 标记。输入的标记默认为 False ,如果没有提供相应的参数
a = torch.randn(2,2)
a=((a*3)/(a-1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b=(a*a).sum()
print(b.grad_fn)梯度
#我们现在后向传播,因为输出包含了一个标量,out.backward() 等同于out.backward(torch.tensor(1.))
out.backward()
#打印梯度 d(out)/dx
print(x.grad)
案例:雅可比向量积
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
#现在在这种情况下,y 不再是一个标量。torch.autograd 不能够直接计算整个雅可比,但是如果我们只想要雅可比向量积,只需要简单的传递向量给 backward 作为参数。
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)
print(x.grad)
#通过将代码包裹在 with torch.no_grad(),来停止对从跟踪历史中 的 .requires_grad=True 的张量自动求导
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)pytorch神经网络
神经网络可以通过 torch.nn 包来构建。神经网络是基于自动梯度 (autograd)来定义一些模型。一个 nn.Module 包括层和一个方法 forward(input) 它会返回输出(output)。
例如:数字图片识别网络:
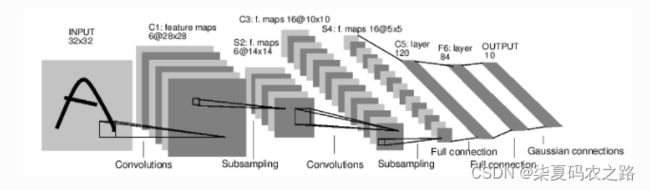
这是一个简单的前馈神经网络,它接收输入,让输入一个接着一个的通过一些层,最后给出输出。
一个典型的神经网络训练过程包括以下几点:
1.定义一个包含可训练参数的神经网络
2.迭代整个输入
3.通过神经网络处理输入
4.计算损失(loss)
5.反向传播梯度到神经网络的参数
6.更新网络的参数,典型的用一个简单的更新方法:weight = weight - learning_rate *gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
#一个模型可训练的参数可以调用net.parameters()返回
params = list(net.parameters())
print(len(params))
print(params[0].size())
#尝试随机生成一个 32x32 的输入。注意:期望的输入维度是 32x32 。为了使用这个网络在 MNIST 数据及上,你需要把数据集中的图片维度修改为 32x32
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
#把所有参数梯度缓存器置零,用随机的梯度来反向传播
net.zero_grad()
out.backward(torch.randn(1, 10))
#损失函数
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
#当我们调用 loss.backward(),整个图都会微分,而且所有的在图中的requires_grad=True 的张量将会让他们的 grad 张量累计梯度
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
#为了实现反向传播损失,我们所有需要做的事情仅仅是使用 loss.backward()。你需要清空现存的梯度,要不然帝都将会和现存的梯度累计到一起现在我们调用 loss.backward() ,然后看一下 con1 的偏置项在反向传播之前和之后的变化
net.zero_grad() # zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
#更新神经网络参数
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
#如果你是用神经网络,你想使用不同的更新规则,类似于 SGD, Nesterov-SGD, Adam, RMSProp, 等。为
#了让这可行,我们建立了一个小包:torch.optim 实现了所有的方法。使用它非常的简单。
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update