Transformer在目标检测领域的开山之作DETR模型
关注公众号,发现CV技术之美
目标检测算法,pipeline太复杂?不同任务人工设计不同的非极大值抑制(NMS)阈值、生成新的锚点(Anchor)?是不是直接戳中了各位开发者的痛点!莫慌,今天小编就为万千开发者破局~这个破局点就是:基于transform的目标检测算法DETR,简洁的pipeline,去除NMS、Anchor设计,且在COCO数据集上的指标与Faster RCNN相当。
本项目将为大家详细介绍DETR算法。同时,将带领大家使用飞桨2.1版本在COCO数据集上实现基于DETR模型的目标检测,以及使用训练好的模型进行评估和预测。DETR检测效果如图1所示:

图1 DETR检测效果
看可以看出DETR将上图中的目标(人、包、椅子等)基本都可以正确检测出来,效果还是不错的~
是不是已经有小伙伴按耐不住想直接上手试试了?
小编识趣地赶紧送上开源代码的传送门 ⬇️ 大家一定要Fork收藏以免走失,也给开源社区一些认可和鼓励。
点击阅读原文可前往AI Studio社区查看源代码与原理讲解,使用免费GPU一键运行
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/2290729
而这个DETR到底是如何设计,从而有这么好的性能的呢?下面小编就带大家来领略一下:
01
COCO数据集
COCO的全称是Common Objects in Context,是一个用于object detection(目标检测)、segmentation(分割)和captioning(看图说话)的大规模数据集。COCO通过在Flickr上搜索80个对象类别和各种场景类型来收集图像。
%cd work/code/
首先解压数据集,执行如下代码即可,解压执行一次就可以。
!mkdir /home/aistudio/dataset
!unzip -q -o /home/aistudio/data/data105593/train2017.zip -d /home/aistudio/dataset
!unzip -q -o /home/aistudio/data/data105593/val2017.zip -d /home/aistudio/dataset
!unzip -q -o /home/aistudio/data/data105593/annotations_trainval2017.zip -d /home/aistudio/dataset
print('完整数据集解压完毕!')解压之后,完整COCO数据存储结构:
|-- coco
|-- annotations:标注文件
|-- person_keypoints_train2017.json:关键点检测
|-- person_keypoints_val2017.json
|-- captions_train2017.json:看图说话
|-- captions_val2017.json
|-- instances_train2017.json:目标实例
|-- instances_val2017.json
|-- images:图片
|-- train2017
|-- val2017然后安装pycocotools,用于加载、解析和可视化COCO数据集,代码实现如下:
!pip install pycocotools02
DETR模型介绍
2.1 整体结构
DETR即Detection Transformer,是Facebook AI 的研究者提出的 Transformer 的视觉版本,可以用于目标检测,也可以用于全景分割。这是第一个将 Transformer成功整合为检测pipeline中心构建块的目标检测框架。与之前的目标检测方法相比,DETR有效地消除了对许多手工设计的组件的需求,例如非最大抑制(Non-Maximum Suppression,,NMS)程序、锚点(Anchor)生成等。
这篇文章提出了一个非常简单的端到端的框架,DETR 的网络结构很简单,分为三个部分,第一部分是一个传统 CNN ,用于提取图片高纬特征;第二部分是一个Transformer 结构,Encoder 和 Decoder 来提取 Bounding Box;最后使用 Bipartite matching loss 来训练网络。

图2 DETR网络结构
2.2 DETR模型介绍
详细介绍DETR的流程,首先把一张3通道图片输入backbone为CNN的网络中,提取图片特征,然后结合位置信息,输入到transformer模型的编码器和解码器中,得到transformer的检测结果,每个结果就是一个box,其中每个box表示一个元组,包含物体的类别和检测框位置。

图3 DETR详细网络结构
2.2.1 ResNet
使用ResNet作为backbone提取图片特征,同时会使用一个1*1的卷积进行降维。因为transformer的编码器模块只处理序列输入,所以后续还需要把CNN特征展开为一个序列。
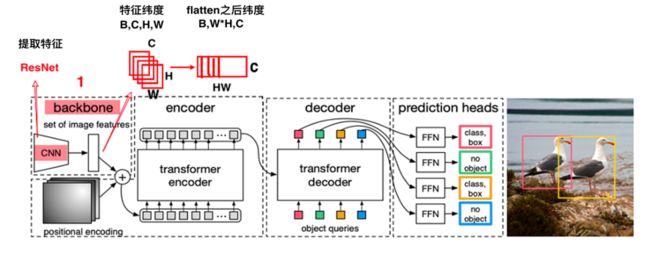
图4 bockbone
2.2.2 DETR Transformer
接下来我们一步一步讲解DETR,首先是位置编码部分,将ResNet提取的特征图转成特征序列后,图像就失去了像素的空间分布信息,所以Transformer就引入位置编码。把特征序列和位置编码序列拼接起来,作为编码起的输入:
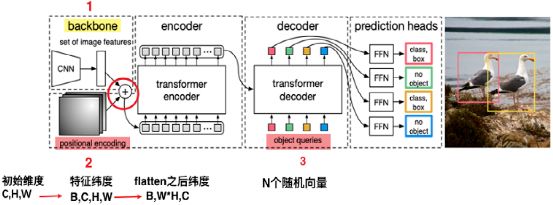
图5 位置编码
DETR论文提出了两种编码方式:
spatial positional encoding
object queries
1)第一种spatial positional encoding,从图5可以看到既会输入到encoder也会输入到decoder中。spatial positional encoding也包含两种计算方式:
learned
emmbeding向量,从网络中学习;
sine

PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;dmodeld_{model}dmodel表示词向量的维度;i表示词向量的位置。因此,上述公式表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,从而来填满整个PE矩阵,然后concatenate送到编码器中。
2)第二种object queries,一开始object queries是N个随机向量,将这些随机向量编码,然后将其与该图像特征结合起来,因此可以认为这些随机输入经过解码器,相当于去图像信息中去查询,图像特征通过注意力机制的转换,得到检测框和类别预测。相当于可学习的anchor,从而解决手工设计anchor的问题。论文中可视化20个object queries,不同的点表示不同大小的box:
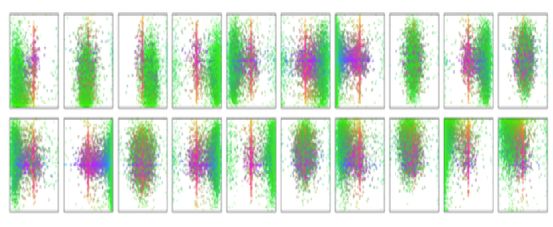
图6 object queries可视化
蓝色:竖直、框较大的box
红色:水平、框较大的box
绿色:较小的box
接着一起看下DETR的Encoder和Decoder结构,包含多头自注意力、残差结构、归一化、前馈神经网络:

图7 DETR的Encoder和Decoder
2.2.3 HungarianMatcher
HungarianMatcher实现了bipartite matching loss,使用的是匈牙利算法,最终匹配方案是选取“loss总和”最小的分配方式。计算公式如下:

该算法实现预测值与真值之间最优的匹配,并且是一一对应,不会多个预测值匹配到同一个ground truth上,这样就无需NMS后处理了。假设预测结果是N个,那么标注信息也要是N个,如下图假设N=6,但真实标签2个,剩下的4个(标注如果小于N就用无物体信息去填充)标注信息都是用无类别来填充:

图8 HungarianMatcher例子
2.2.4 DETRLoss
DETR损失包含两部分:
分类损失:交叉熵损失函数
检测框位置损失:L1损失和IOU损失的加权和,且Iou的计算采用了GIou算法,解决真实框和检测框没重叠时,Iou始终为0的问题。

2.2.5 DETRHead
transformer输出序列直接送到FFN分类器,得到预测类别和检测框坐标:
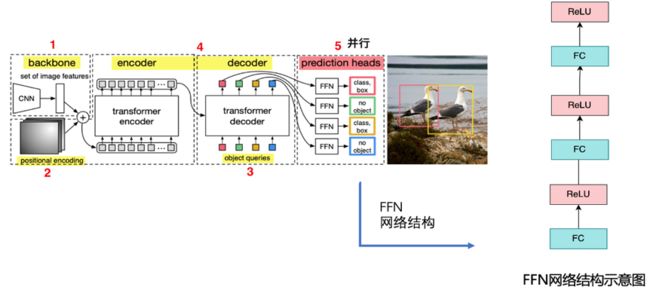
图9 DETRHead结构图
03
模型训练
了解了DETR原理,接下来通过飞桨框架实现模型模型,训练脚本启动命令:
python main.py --mode='train' --dataset_dir='dataset/'
--image_dir='train2017'
--anno_path='annotations/instances_train2017.json'mode:设置不同的模型,'train'表示训练
dataset_dir:COCO数据集路径
image_dir:训练图片路径
anno_path:训练标注文件路径
04
模型评估
使用训练好的模型在COCO验证集上的进行评估,评估脚本启动命令
python main.py --mode='eval' --dataset_dir='dataset/' --image_dir='val2017' --anno_path='annotations/instances_val2017.json' --pretrained_model='pretrained_model/detr'我们也可以下载DETR预训练模型,放在pretrained_model/目录下,使用预训练模型在COCO验证集上进行验证,结果如下:
模型链接:https://aistudio.baidu.com/aistudio/projectdetail/2290729

图10 预训练模型评估指标
05
模型训练
使用保存好的模型,对数据集中的某一张图片进行模型推理,观察模型效果,具体代码实现如下:
python main.py --mode='test'
--infer_img='test_imgs/000000014439.jpg'
--anno_path='dataset/annotations/instances_val2017.json'
--pretrained_model='pretrained_model/detr'Infer_img:待测试图片
anno_path:用于获取标签类别
PaddleEdu使用过程中有任何问题欢迎在https://github.com/PaddlePaddle/awesome-DeepLearning 提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~
参考文献:
[1]Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Springer, Cham, 2020: 213-229.
注:文中图片、公式来源End-to-End Object Detection with Transformers论文

戳下面的原文阅读,更有料!