【数据增广】无监督增广——RandAugment
一年多没有写博客了,一转眼回国就入职了。最近在从事关于计算机视觉方面的工作,一方面也是为了记录自己平日学习的点滴与思考养成良好的阅读习惯,另一方面也是为自己的知识技能库做一些储备。
言归正传,我们来看论文。
这是2019年11月由google brain团队发布的一篇关于无监督数据增广的文章,名称为
RandAugmentation:Practical automated data augmentation with reduced search space
本博为阅读思考及个人翻译,有问题的地方还请大家多多指正。
Repo:
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
摘要
近期研究表明,数据增广可以显著提高深度学习的泛化性能,尤其是在图像分类和目标检测方面均取得了不错的成果。尽管这些策略主要目的是为了提升精度,与此同时,在半监督机制下因为对原有数据集进行了扩充,从而增加了数据集的鲁棒性。
常见的图像识别任务中,增广的过程一般都是作为预处理阶段的任务之一。往往由于数据集过大而造成极大的计算损耗障碍。此外,由于所处的阶段不同,这些方法无法像模型算法一样随意调整正则化强度(尽管数据增广的效果直接取决于模型和数据集的大小)。
传统自动数据增广的策略通常是基于小数据集在轻量模型上训练后再应用于更大的模型。这就在策略上造成了一定的限制约束。本文则解决了这两大限制。RandAugment可以将数据增广所产生的增量样本空间大大缩小,从而使其可与模型训练过程捆绑在一起完成,避免将其作为独立的预处理任务来完成。此外,本文设置了增广强度的正则化参数,可以根据不同的模型和数据集大小进行调整。RandAugment方法可以作为外置工具作用于不同的图像处理任务、数据集工作中。
在CIFAR-10/100、SVHN和ImageNet数据集上能持平甚至优于先前的自动数据增广方法性能。在ImageNet数据集上,Baseline采用EfficientNet-B7结构的精度为84%,而AutoAugment+Baseline的精度为84.4%,本文的RandAugment+Baseline则达到了85.0%的准确率,分别提升了1和0.6个百分点。在目标检测方面,Baseline采用ResNet结构,添加RandAugment的效果较Baseline和其他增广方法提高了1.0~1.3个百分点。在COCO数据集上的表现也有0~0.3%mAP的效果提升。最后,由于本文超参数的可解释性,RandAugment可以用来研究数据作用与模型、数据集大小之间的关系。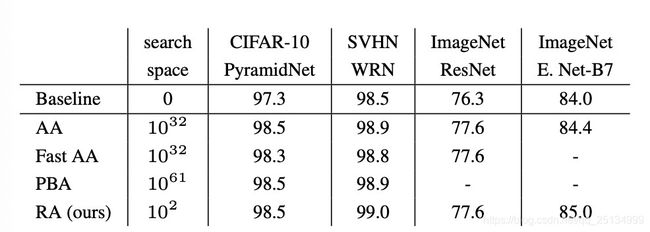
数据增广常在图像分类、目标检测等任务中广泛用于生成额外数据以达到扩充数据集的目的。不过,传统的增广方法需要专业的图像处理知识结合手动计算来完成,并且要有一定的先验知识基础。因此,这使得传统增广变得困难。
当下为了减少手工+先验的复杂过程,学者们正尝试探索一系列自动增广(AutoAugment)策略的方法。一个好的增广手段不仅可以提升图像分类的精度,增强训练机器学习模型的半监督性,同时也可以使得模型更具鲁棒性。尽管采用MixUp等策略进行数据增广可以提升模型性能,但归根结底仍然是两阶段的:先增广,后训练。同时也将造成较多的计算资源损耗。后续研究工作重点在于加速训练效率和程序的有效性,使得增广性能可以在反向传播中得以共同迭代更新。而AutoAugment通过对原始公式假定对一个小的代理任务进行单独的搜索,最后将其整合到更大的目标任务中。本文证明了这种两阶段式的策略并非最优的,因为增广的强度与模型和数据集大小之间具有很强的关联性。RandAugment无需单独搜索,其关键点在于大大减小了增广数据空间的大小。
解读
Google Brain团队出品,采用与基本数据增广方式相同的一系列方法如:identity、rotate…具体的增广手段如下表所示共K=14种。但本文并非目的是为了让CNN网络学习如何对针对不同的数据集进行增广,而是随机选择数据增广的方式。即随机选择一种手段对原始数据进行变换,并调整它们的大小。

以往数据增强方法都包含30多个参数,为减少参数空间的同时保持数据(图像)的多样性,研究人员用无参数过程替代了学习的策略和概率。这些策略和概率适用于每次变换(transformation),该过程始终选择均匀概率为1/K的变换。
即给定某个训练图像的N种变换形式,RandAugment就能表示 K N K^N KN个潜在策略。最后,需要考虑到的一组参数是每个增强结果所造成的失真程度。
研究人员采用线性标度来表示每个转换的强度。简单来说,就是每次变换都在0到10的整数范围内,其中,10表示给定变换的最大范围。
为了进一步缩小参数空间,团队观察到每个转换的学习幅度(learned magnitude)在训练期间遵循类似的表。不同颜色代表不同的增广方式,横坐标为epoch迭代次数:

显然,随着epoch增加,早期的幅度并不大,说明生成的数据量并不多,且针对不同输入数据的分布,所采用的增广手段也不同。
假设一个单一的全局失真M(global distortion M)可能就足以对所有转换进行参数化。那么生成的算法便包含两个参数N(变换形式个数)和M,还可以用两行Python代码简单表示:
# 用于生成全局失真数据
# 参数:
# N:将被选择出的操作数
# M:失真级数
transforms = ['Identity', 'AutoContrast','Equalize',
'rotate', 'Solarize', 'Color',
'Posterize', 'Contrast', 'Brightness',
'Sharpness', 'ShearX', 'ShearY',
'TranslateX', 'TranslateY']
def randaugment(N, M):
# 从transforms方法中随机选取N种操作,eg:N=2,则可能选择出['Color', 'Contrast']
sampled_ops = np.random.choice(transforms, N)
return [(op, M) for op in sampled_ops]
显然,N和M的值越大,代表对增广强度的正则化程度越大。考虑到采用该方法后造成搜索空间略小,团队人员发现采用朴素网格搜索(Naive Grid Search)在此是有效的。
作者团队还比较了不同网络大小和数据集大小与增广强度、最终精度之间的关系,具体请详见论文。