scikit-learn学习之特征提取,常用模型,交叉验证
目录
一、scikit-learn中fit_transform()与transform()的区别
二、sklearn中predict_proba用法(注意和predict的区别)
三、scikit-learn使用总结
1 scikit-learn基础介绍
1.1 估计器(Estimator)
1.2 转换器(Transformer)
1.3 流水线(Pipeline)
1.4 预处理
1.5 特征
1.6 降维
1.7 组合
1.8 模型评估(度量)
1.9 交叉验证
1.10 网格搜索
1.11 多分类、多标签分类
2 具体模型
2.1 朴素贝叶斯(Naive Bayes)
3.scikit-learn扩展
3.1 概览
3.2 创建自己的转换器
四. scikit-learn实战
4.1 特征提取
PCA(主成分分析)
LDA(线性评价分析)
4.2 常用模型
线性回归
逻辑回归
朴素贝叶斯
决策树
SVM(支持向量机)
神经网络
KNN(K-近邻算法)
交叉验证
模型的保存和载入
小结
一、scikit-learn中fit_transform()与transform()的区别
通俗地讲清楚fit_transform()和transform()的区别fit_transform是fit和transform的组合。
问题:
scikit-learn中fit_transform()与transform()到底有什么区别,能不能混用?
- 二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
- fit_transform(partData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该partData进行转换transform,从而实现数据的标准化、归一化等等。。
- 根据对之前部分fit的整体指标,对剩余的数据(restData)使用同样的均值、方差、最大最小值等指标进行转换transform(restData),从而保证part、rest处理方式相同。
- 必须先用fit_transform(partData),之后再transform(restData)
- 如果直接transform(partData),程序会报错
- 如果fit_transfrom(partData)后,使用fit_transform(restData)而不用transform(restData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。
实验:
使用preprocessing.MinMaxScaler()对象对数据进行归一化。原理是:(x-xMin)/(xMax - xMin),从而将所有数据映射到【0,1】区间。
import numpy as np
from sklearn.preprocessing import MinMaxScaler
data = np.array(np.random.randint(-100,100,24).reshape(6,4))
data
Out[55]:
array([[ 68, -63, -31, -10],
[ 49, -49, 73, 18],
[ 46, 65, 75, -78],
[-72, 30, 90, -80],
[ 95, -88, 79, -49],
[ 34, -81, 57, 83]])
train = data[:4]
test = data[4:]
train
Out[58]:
array([[ 68, -63, -31, -10],
[ 49, -49, 73, 18],
[ 46, 65, 75, -78],
[-72, 30, 90, -80]])
test
Out[59]:
array([[ 95, -88, 79, -49],
[ 34, -81, 57, 83]])
minmaxTransformer = MinMaxScaler(feature_range=(0,1))
#先对train用fit_transformer(),包括拟合fit找到xMin,xMax,再transform归一化
train_transformer = minmaxTransformer.fit_transform(train)
#根据train集合的xMin,xMax,对test集合进行归一化transform.
#(如果test中的某个值比之前的xMin还要小,依然用原来的xMin;同理如果test中的某个值比之前的xMax还要大,依然用原来的xMax.
#所以,对test集合用同样的xMin和xMax,**有可能不再映射到【0,1】**)
test_transformer = minmaxTransformer.transform(test)
train_transformer
Out[64]:
array([[ 1. , 0. , 0. , 0.71428571],
[ 0.86428571, 0.109375 , 0.85950413, 1. ],
[ 0.84285714, 1. , 0.87603306, 0.02040816],
[ 0. , 0.7265625 , 1. , 0. ]])
test_transformer
Out[65]:
array([[ 1.19285714, -0.1953125 , 0.90909091, 0.31632653],
[ 0.75714286, -0.140625 , 0.72727273, 1.66326531]])
#如果少了fit环节,直接transform(partData),则会报错
minmaxTransformer = MinMaxScaler(feature_range=(0,1))
train_transformer2 = minmaxTransformer.transform(train)
Traceback (most recent call last):
File "", line 1, in
train_transformer2 = minmaxTransformer.transform(train)
File "D:\Program Files\Anaconda3\lib\site-packages\sklearn\preprocessing\data.py", line 352, in transform
check_is_fitted(self, 'scale_')
File "D:\Program Files\Anaconda3\lib\site-packages\sklearn\utils\validation.py", line 690, in check_is_fitted
raise _NotFittedError(msg % {'name': type(estimator).__name__})
NotFittedError: This MinMaxScaler instance is not fitted yet. Call 'fit' with appropriate arguments before using this method.
#如果对test也用fit_transform(),则结果跟之前不一样。对于许多机器学习算法来说,对于train和test的处理应该统一。
test_transformer2 = minmaxTransformer.fit_transform(test)
test_transformer2
Out[71]:
array([[ 1., 0., 1., 0.],
[ 0., 1., 0., 1.]])
test_transformer
Out[72]:
array([[ 1.19285714, -0.1953125 , 0.90909091, 0.31632653],
[ 0.75714286, -0.140625 , 0.72727273, 1.66326531]]) 参考:
https://www.jianshu.com/p/ddfe1909b8db
http://blog.csdn.net/appleyuchi/article/details/73503282
http://blog.csdn.net/anecdotegyb/article/details/74857055
二、sklearn中predict_proba用法(注意和predict的区别)
predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
predict返回对应的分类
# conding :utf-8
from sklearn.linear_model import LogisticRegression
import numpy as np
x_train = np.array([[1,2,3],
[1,3,4],
[2,1,2],
[4,5,6],
[3,5,3],
[1,7,2]])
y_train = np.array([3, 3, 3, 2, 2, 2])
x_test = np.array([[2,2,2],
[3,2,6],
[1,7,4]])
clf = LogisticRegression()
clf.fit(x_train, y_train)
# 返回预测标签
print(clf.predict(x_test))
# 返回预测属于某标签的概率
print(clf.predict_proba(x_test))
# [2 3 2]
# [[0.56651809 0.43348191]
# [0.15598162 0.84401838]
# [0.86852502 0.13147498]]
# 分析结果:
# 预测[2,2,2]的标签是2的概率为0.56651809,3的概率为0.43348191
#
# 预测[3,2,6]的标签是2的概率为0.15598162,3的概率为0.84401838
#
# 预测[1,7,4]的标签是2的概率为0.86852502,3的概率为0.13147498 三、scikit-learn使用总结
原文出处:Scikit-learn使用总结
在机器学习和数据挖掘的应用中,scikit-learn是一个功能强大的python包。在数据量不是过大的情况下,可以解决大部分问题。学习使用scikit-learn的过程中,我自己也在补充着机器学习和数据挖掘的知识。这里根据自己学习sklearn的经验,我做一个总结的笔记。另外,我也想把这篇笔记一直更新下去。
1 scikit-learn基础介绍
1.1 估计器(Estimator)
估计器,很多时候可以直接理解成分类器,主要包含两个函数:
- fit():训练算法,设置内部参数。接收训练集和类别两个参数。
- predict():预测测试集类别,参数为测试集。
大多数scikit-learn估计器接收和输出的数据格式均为numpy数组或类似格式。
1.2 转换器(Transformer)
转换器用于数据预处理和数据转换,主要是三个方法:
- fit():训练算法,设置内部参数。
- transform():数据转换。
- fit_transform():合并fit和transform两个方法。
1.3 流水线(Pipeline)
sklearn.pipeline包
流水线的功能:
- 跟踪记录各步骤的操作(以方便地重现实验结果)
- 对各步骤进行一个封装
- 确保代码的复杂程度不至于超出掌控范围
基本使用方法
流水线的输入为一连串的数据挖掘步骤,其中最后一步必须是估计器,前几步是转换器。输入的数据集经过转换器的处理后,输出的结果作为下一步的输入。最后,用位于流水线最后一步的估计器对数据进行分类。
每一步都用元组( ‘名称’,步骤)来表示。现在来创建流水线。
-
scaling_pipeline = Pipeline([ -
('scale', MinMaxScaler()), -
('predict', KNeighborsClassifier()) -
])
1.4 预处理
主要在sklearn.preprcessing包下。
规范化:
- MinMaxScaler :最大最小值规范化
- Normalizer :使每条数据各特征值的和为1
- StandardScaler :为使各特征的均值为0,方差为1
编码:
- LabelEncoder :把字符串类型的数据转化为整型
- OneHotEncoder :特征用一个二进制数字来表示
- Binarizer :为将数值型特征的二值化
- MultiLabelBinarizer:多标签二值化
1.5 特征
1.5.1 特征抽取
包:sklearn.feature_extraction
特征抽取是数据挖掘任务最为重要的一个环节,一般而言,它对最终结果的影响要高过数据挖掘算法本身。只有先把现实用特征表示出来,才能借助数据挖掘的力量找到问题的答案。特征选择的另一个优点在于:降低真实世界的复杂度,模型比现实更容易操纵。
一般最常使用的特征抽取技术都是高度针对具体领域的,对于特定的领域,如图像处理,在过去一段时间已经开发了各种特征抽取的技术,但这些技术在其他领域的应用却非常有限。
- DictVectorizer: 将dict类型的list数据,转换成numpy array
- FeatureHasher : 特征哈希,相当于一种降维技巧
- image:图像相关的特征抽取
- text: 文本相关的特征抽取
- text.CountVectorizer:将文本转换为每个词出现的个数的向量
- text.TfidfVectorizer:将文本转换为tfidf值的向量
- text.HashingVectorizer:文本的特征哈希
示例

data.png
CountVectorize只数出现个数

count.png

hash.png
TfidfVectorizer:个数+归一化(不包括idf)
tfidf(without idf).png
1.5.2 特征选择
包:sklearn.feature_selection
特征选择的原因如下:
(1)降低复杂度
(2)降低噪音
(3)增加模型可读性
- VarianceThreshold: 删除特征值的方差达不到最低标准的特征
- SelectKBest: 返回k个最佳特征
- SelectPercentile: 返回表现最佳的前r%个特征
单个特征和某一类别之间相关性的计算方法有很多。最常用的有卡方检验(χ2)。其他方法还有互信息和信息熵。
- chi2: 卡方检验(χ2)
1.6 降维
包:sklearn.decomposition
- 主成分分析算法(Principal Component Analysis, PCA)的目的是找到能用较少信息描述数据集的特征组合。它意在发现彼此之间没有相关性、能够描述数据集的特征,确切说这些特征的方差跟整体方差没有多大差距,这样的特征也被称为主成分。这也就意味着,借助这种方法,就能通过更少的特征捕获到数据集的大部分信息。
1.7 组合
包:sklearn.ensemble
组合技术即通过聚集多个分类器的预测来提高分类准确率。
常用的组合分类器方法:
(1)通过处理训练数据集。即通过某种抽样分布,对原始数据进行再抽样,得到多个训练集。常用的方法有装袋(bagging)和提升(boosting)。
(2)通过处理输入特征。即通过选择输入特征的子集形成每个训练集。适用于有大量冗余特征的数据集。随机森林(Random forest)就是一种处理输入特征的组合方法。
(3)通过处理类标号。适用于多分类的情况,将类标号随机划分成两个不相交的子集,再把问题变为二分类问题,重复构建多次模型,进行分类投票。
- BaggingClassifier: Bagging分类器组合
- BaggingRegressor: Bagging回归器组合
- AdaBoostClassifier: AdaBoost分类器组合
- AdaBoostRegressor: AdaBoost回归器组合
- GradientBoostingClassifier:GradientBoosting分类器组合
- GradientBoostingRegressor: GradientBoosting回归器组合
- ExtraTreeClassifier:ExtraTree分类器组合
- ExtraTreeRegressor: ExtraTree回归器组合
- RandomTreeClassifier:随机森林分类器组合
- RandomTreeRegressor: 随机森林回归器组合
使用举例
-
AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), -
algorithm="SAMME", -
n_estimators=200)
解释
装袋(bagging):根据均匀概率分布从数据集中重复抽样(有放回),每个自助样本集和原数据集一样大,每个自助样本集含有原数据集大约63%的数据。训练k个分类器,测试样本被指派到得票最高的类。
提升(boosting):通过给样本设置不同的权值,每轮迭代调整权值。不同的提升算法之间的差别,一般是(1)如何更新样本的权值,(2)如何组合每个分类器的预测。其中Adaboost中,样本权值是增加那些被错误分类的样本的权值,分类器C_i的重要性依赖于它的错误率。
Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
1.8 模型评估(度量)
包:sklearn.metrics
sklearn.metrics包含评分方法、性能度量、成对度量和距离计算。
分类结果度量
参数大多是y_true和y_pred。
- accuracy_score:分类准确度
- condusion_matrix :分类混淆矩阵
- classification_report:分类报告
- precision_recall_fscore_support:计算精确度、召回率、f、支持率
- jaccard_similarity_score:计算jcaard相似度
- hamming_loss:计算汉明损失
- zero_one_loss:0-1损失
- hinge_loss:计算hinge损失
- log_loss:计算log损失
其中,F1是以每个类别为基础进行定义的,包括两个概念:准确率(precision)和召回率(recall)。准确率是指预测结果属于某一类的个体,实际属于该类的比例。召回率是被正确预测为某类的个体,与数据集中该类个体总数的比例。F1是准确率和召回率的调和平均数。
回归结果度量
- explained_varicance_score:可解释方差的回归评分函数
- mean_absolute_error:平均绝对误差
- mean_squared_error:平均平方误差
多标签的度量
- coverage_error:涵盖误差
- label_ranking_average_precision_score:计算基于排名的平均误差Label ranking average precision (LRAP)
聚类的度量
- adjusted_mutual_info_score:调整的互信息评分
- silhouette_score:所有样本的轮廓系数的平均值
- silhouette_sample:所有样本的轮廓系数
1.9 交叉验证
包:sklearn.cross_validation
- KFold:K-Fold交叉验证迭代器。接收元素个数、fold数、是否清洗
- LeaveOneOut:LeaveOneOut交叉验证迭代器
- LeavePOut:LeavePOut交叉验证迭代器
- LeaveOneLableOut:LeaveOneLableOut交叉验证迭代器
- LeavePLabelOut:LeavePLabelOut交叉验证迭代器
LeaveOneOut(n) 相当于 KFold(n, n_folds=n) 相当于LeavePOut(n, p=1)。
LeaveP和LeaveOne差别在于leave的个数,也就是测试集的尺寸。LeavePLabel和LeaveOneLabel差别在于leave的Label的种类的个数。
LeavePLabel这种设计是针对可能存在第三方的Label,比如我们的数据是一些季度的数据。那么很自然的一个想法就是把1,2,3个季度的数据当做训练集,第4个季度的数据当做测试集。这个时候只要输入每个样本对应的季度Label,就可以实现这样的功能。
以下是实验代码,尽量自己多实验去理解。
-
#coding=utf-8 -
import numpy as np -
import sklearnfrom sklearn -
import cross_validation -
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8],[9, 10]]) -
y = np.array([1, 2, 1, 2, 3]) -
def show_cross_val(method): -
if method == "lolo": -
labels = np.array(["summer", "winter", "summer", "winter", "spring"]) -
cv = cross_validation.LeaveOneLabelOut(labels) -
elif method == 'lplo': -
labels = np.array(["summer", "winter", "summer", "winter", "spring"]) -
cv = cross_validation.LeavePLabelOut(labels,p=2) -
elif method == 'loo': -
cv = cross_validation.LeaveOneOut(n=len(y)) -
elif method == 'lpo': -
cv = cross_validation.LeavePOut(n=len(y),p=3) -
for train_index, test_index in cv: -
print("TRAIN:", train_index, "TEST:", test_index) -
X_train, X_test = X[train_index], X[test_index] -
y_train, y_test = y[train_index], y[test_index] -
print "X_train: ",X_train -
print "y_train: ", y_train -
print "X_test: ",X_test -
print "y_test: ",y_test -
if __name__ == '__main__': -
show_cross_val("lpo")
常用方法
- train_test_split:分离训练集和测试集(不是K-Fold)
- cross_val_score:交叉验证评分,可以指认cv为上面的类的实例
- cross_val_predict:交叉验证的预测。
1.10 网格搜索
包:sklearn.grid_search
网格搜索最佳参数
- GridSearchCV:搜索指定参数网格中的最佳参数
- ParameterGrid:参数网格
- ParameterSampler:用给定分布生成参数的生成器
- RandomizedSearchCV:超参的随机搜索
通过best_estimator_.get_params()方法,获取最佳参数。
1.11 多分类、多标签分类
包:sklearn.multiclass
- OneVsRestClassifier:1-rest多分类(多标签)策略
- OneVsOneClassifier:1-1多分类策略
- OutputCodeClassifier:1个类用一个二进制码表示
示例代码-
#coding=utf-8 -
from sklearn import metrics -
from sklearn import cross_validation -
from sklearn.svm import SVC -
from sklearn.multiclass import OneVsRestClassifier -
from sklearn.preprocessing import MultiLabelBinarizer -
import numpy as np -
from numpy import random -
X=np.arange(15).reshape(5,3) -
y=np.arange(5) -
Y_1 = np.arange(5) -
random.shuffle(Y_1) -
Y_2 = np.arange(5) -
random.shuffle(Y_2) -
Y = np.c_[Y_1,Y_2] -
def multiclassSVM(): -
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2,random_state=0) -
model = OneVsRestClassifier(SVC()) -
model.fit(X_train, y_train) -
predicted = model.predict(X_test) -
print predicted -
def multilabelSVM(): -
Y_enc = MultiLabelBinarizer().fit_transform(Y) -
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split(X, Y_enc, test_size=0.2, random_state=0) -
model = OneVsRestClassifier(SVC()) -
model.fit(X_train, Y_train) -
predicted = model.predict(X_test) -
print predicted -
if __name__ == '__main__': -
multiclassSVM() -
# multilabelSVM()
-
2 具体模型
2.1 朴素贝叶斯(Naive Bayes)
包:sklearn.cross_validation
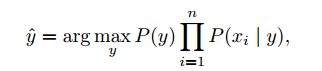
朴素贝叶斯.png
朴素贝叶斯的特点是分类速度快,分类效果不一定是最好的。
- GasussianNB:高斯分布的朴素贝叶斯
- MultinomialNB:多项式分布的朴素贝叶斯
- BernoulliNB:伯努利分布的朴素贝叶斯
所谓使用什么分布的朴素贝叶斯,就是假设P(x_i|y)是符合哪一种分布,比如可以假设其服从高斯分布,然后用最大似然法估计高斯分布的参数。
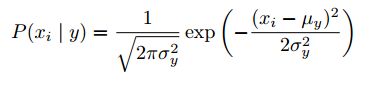
高斯分布.png
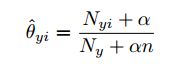
多项式分布.png
![]()
伯努利分布.png
3.scikit-learn扩展
3.1 概览
具体的扩展,通常要继承sklearn.base包下的类。
- BaseEstimator: 估计器的基类
- ClassifierMixin :分类器的混合类
- ClusterMixin:聚类器的混合类
- RegressorMixin :回归器的混合类
- TransformerMixin :转换器的混合类
关于什么是Mixin(混合类),具体可以看这个知乎链接。简单地理解,就是带有实现方法的接口,可以将其看做是组合模式的一种实现。举个例子,比如说常用的TfidfTransformer,继承了BaseEstimator, TransformerMixin,因此它的基本功能就是单一职责的估计器和转换器的组合。
3.2 创建自己的转换器
在特征抽取的时候,经常会发现自己的一些数据预处理的方法,sklearn里可能没有实现,但若直接在数据上改,又容易将代码弄得混乱,难以重现实验。这个时候最好自己创建一个转换器,在后面将这个转换器放到pipeline里,统一管理。
例如《Python数据挖掘入门与实战》书中的例子,我们想接收一个numpy数组,根据其均值将其离散化,任何高于均值的特征值替换为1,小于或等于均值的替换为0。
代码实现:
from sklearn.base import TransformerMixin
from sklearn.utils import as_float_array
class MeanDiscrete(TransformerMixin):
#计算出数据集的均值,用内部变量保存该值。
def fit(self, X, y=None):
X = as_float_array(X)
self.mean = np.mean(X, axis=0)
#返回self,确保在转换器中能够进行链式调用(例如调用
transformer.fit(X).transform(X))
return self
def transform(self, X):
X = as_float_array(X)
assert X.shape[1] == self.mean.shape[0]
return X > self.mean四. scikit-learn实战
4.1 特征提取
我们获取的数据中很多数据往往有很多维度,但并不是所有的维度都是有用的,有意义的,所以我们要将对结果影响较小的维度舍去,保留对结果影响较大的维度。
PCA(主成分分析)与LDA(线性评价分析)是特征提取的两种经典算法。PCA与LDA本质上都是学习一个投影矩阵,使样本在新的坐标系上的表示具有相应的特性,样本在新坐标系的坐标相当于新的特征,保留下的新特征应当是对结果有较大影响的特征。
PCA(主成分分析)
最大方差理论:信号具有较大的方差,噪声具有较小的方差
PCA的目标:新坐标系上数据的方差越大越好
PCA是无监督的学习方法
PCA实现起来并不复杂(过几天写一篇使用NumPy实现的PCA),但是在sklearn就更为简单了,直接食用skleran.decomposition即可
import sklearn.decomposition as sk_decomposition
pca = sk_decomposition.PCA(n_components='mle',whiten=False,svd_solver='auto')
pca.fit(iris_X)
reduced_X = pca.transform(iris_X) #reduced_X为降维后的数据
print('PCA:')
print ('降维后的各主成分的方差值占总方差值的比例',pca.explained_variance_ratio_)
print ('降维后的各主成分的方差值',pca.explained_variance_)
print ('降维后的特征数',pca.n_components_)
参数说明:
n_components:指定希望PCA降维后的特征维度数目(>1), 指定主成分的方差和所占的最小比例阈值(0-1),'mle'用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维
whiten: 判断是否进行白化。白化:降维后的数据的每个特征进行归一化,让方差都为1
svd_solver:奇异值分解SVD的方法{‘auto’, ‘full’, ‘arpack’, ‘randomized’}
打印结果:
下面打印的内容只是帮助大家理解pca的参数,就不打印降维后的数据了,打印出来并没有什么意义。
PCA:
降维后的各主成分的方差值占总方差值的比例 [ 0.92461621 0.05301557 0.01718514]
降维后的各主成分的方差值 [ 4.22484077 0.24224357 0.07852391]
降维后的特征数 3
LDA(线性评价分析)
LDA基于费舍尔准则,即同一类样本尽可能聚合在一起,不同类样本应该尽量扩散;或者说,同雷洋被具有较好的聚合度,类别间具有较好的扩散度。
既然涉及到了类别,那么LDA肯定是一个有监督算法,其实LDA既可以做特征提取液可以做分类。
LDA具体的实现流程这里就不再赘述了,直接看skleran如何实现LDA。
import sklearn.discriminant_analysis as sk_discriminant_analysis
lda = sk_discriminant_analysis.LinearDiscriminantAnalysis(n_components=2)
lda.fit(iris_X,iris_y)
reduced_X = lda.transform(iris_X) #reduced_X为降维后的数据
print('LDA:')
print ('LDA的数据中心点:',lda.means_) #中心点
print ('LDA做分类时的正确率:',lda.score(X_test, y_test)) #score是指分类的正确率
print ('LDA降维后特征空间的类中心:',lda.scalings_) #降维后特征空间的类中心
参数说明:
n_components:指定希望PCA降维后的特征维度数目(>1)
svd_solver:奇异值分解SVD的方法{‘auto’, ‘full’, ‘arpack’, ‘randomized’}
打印结果:
下面打印的内容只是帮助大家理解lda的参数,就不打印降维后的数据了,打印出来并没有什么意义。
LDA:
LDA的数据中心点:
[[ 5.006 3.418 1.464 0.244]
[ 5.936 2.77 4.26 1.326]
[ 6.588 2.974 5.552 2.026]]
LDA做分类时的正确率: 0.980952380952
LDA降维后特征空间的类中心:
[[-0.81926852 0.03285975]
[-1.5478732 2.15471106]
[ 2.18494056 -0.93024679]
[ 2.85385002 2.8060046 ]]
4.2 常用模型
首先sklearn中所有的模型都有四个固定且常用的方法,其实在PCA与LDA中我们已经用到了这些方法中的fit方法。
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
model.predict(X_test)
# 获得这个模型的参数
model.get_params()
# 为模型进行打分
model.score(data_X, data_y) # 回归问题:以R2参数为标准 分类问题:以准确率为标准
线性回归
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
其实,说白了,就是用一条直线去拟合一大堆数据,最后把系数w和截距b算出来,直线也就算出来了, 就可以拿去做预测了。
sklearn中线性回归使用最小二乘法实现,使用起来非常简单。
线性回归是回归问题,score使用R2系数做为评价标准。
import sklearn.linear_model as sk_linear
model = sk_linear.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #返回预测的确定系数R2
print('线性回归:')
print('截距:',model.intercept_) #输出截距
print('系数:',model.coef_) #输出系数
print('线性回归模型评价:',acc)
参数说明:
fit_intercept:是否计算截距。False-模型没有截距
normalize: 当fit_intercept设置为False时,该参数将被忽略。 如果为真,则回归前的回归系数X将通过减去平均值并除以l2-范数而归一化。
copy_X:是否对X数组进行复制,默认为True
n_jobs:指定线程数
打印结果:
线性回归:
截距: -0.379953866745
系数: [-0.02744885 0.01662843 0.17780211 0.65838886]
线性回归模型评价: 0.913431360638
逻辑回归
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w‘x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y =w‘x+b,而logistic回归则通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b),然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
说人话:线性回归是回归,逻辑回归是分类。逻辑回归通过logistic函数算概率,然后算出来一个样本属于一个类别的概率,概率越大越可能是这个类的样本。
sklearn对于逻辑回归的实现也非常简单,直接上代码了。
逻辑回归是分类问题,score使用准确率做为评价标准。
import sklearn.linear_model as sk_linear
model = sk_linear.LogisticRegression(penalty='l2',dual=False,C=1.0,n_jobs=1,random_state=20,fit_intercept=True)
model.fit(X_train,y_train) #对模型进行训练
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print('逻辑回归模型评价:',acc)
参数说明:
penalty:使用指定正则化项(默认:l2)
dual: n_samples > n_features取False(默认)
C:正则化强度的反,值越小正则化强度越大
n_jobs: 指定线程数
random_state:随机数生成器
fit_intercept: 是否需要常量
打印结果:
逻辑回归模型评价: 0.8
朴素贝叶斯
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法
首先根据样本中心定理,概率等于频率,所以下文的P是可以统计出来的
朴素贝叶斯的核心便是贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A) 即在A条件下,B发生的概率
换个角度:P(类别|特征)=P(特征|类别)P(类别)/P(特征)
而我们最后要求解的就是P(类别|特征)
举一个生活中的例子:

贝叶斯
最后一个公式中的所有概率都是可以统计出来的,所以P(B|A)可以计算!
那么!我感觉我都写偏题了,这明明是机器学习算法概述嘛
那么sklearn中怎么实现呢?
import sklearn.naive_bayes as sk_bayes
model = sk_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None) #多项式分布的朴素贝叶斯
model = sk_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None) #伯努利分布的朴素贝叶斯
model = sk_bayes.GaussianNB()#高斯分布的朴素贝叶斯
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print(n朴素贝叶斯(高斯分布)模型评价:',acc)
参数说明:
alpha:平滑参数
fit_prior:是否要学习类的先验概率;false-使用统一的先验概率
class_prior: 是否指定类的先验概率;若指定则不能根据参数调整
binarize: 二值化的阈值,若为None,则假设输入由二进制向量组成
打印结果:
朴素贝叶斯(高斯分布)模型评价: 0.92380952381
决策树
决策树是解决分类问题
算法描述请见我之前的帖子(写的很详细了):http://blackblog.tech/2018/01/29/决策树——ID3算法实现/
这里我们直接上代码
import sklearn.tree as sk_tree
model = sk_tree.DecisionTreeClassifier(criterion='entropy',max_depth=None,min_samples_split=2,min_samples_leaf=1,max_features=None,max_leaf_nodes=None,min_impurity_decrease=0)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print('决策树模型评价:',acc)
参数说明:
criterion :特征选择准则gini/entropy
max_depth:树的最大深度,None-尽量下分
min_samples_split:分裂内部节点,所需要的最小样本树
min_samples_leaf:叶子节点所需要的最小样本数
max_features: 寻找最优分割点时的最大特征数
max_leaf_nodes:优先增长到最大叶子节点数
min_impurity_decrease:如果这种分离导致杂质的减少大于或等于这个值,则节点将被拆分。
打印结果:
决策树模型评价: 0.942857142857
SVM(支持向量机)
支持向量机是解决分类问题
目的:求解最大化间隔
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。
SVM的关键在于核函数
一句话讲懂核函数:低维无法线性划分的问题放到高维就可以线性划分,一般用高斯,因为效果绝对不会变差!
SVM算法思路很清晰,但是实现起来很复杂,最近就在实现SVM,写好了就发上来,在这里就不赘述这么多了,我们直接用skleran解决问题。
import sklearn.svm as sk_svm
model = sk_svm.SVC(C=1.0,kernel='rbf',gamma='auto')
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print('SVM模型评价:',acc)
参数说明:
C:误差项的惩罚参数C
kernel:核函数选择 默认:rbf(高斯核函数),可选:‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
gamma: 核相关系数。浮点数,If gamma is ‘auto’ then 1/n_features will be used instead.点将被拆分。
打印结果:
SVM模型评价: 0.961904761905
神经网络
还在感慨因为不会tensorflow而无法使用神经网络?还在羡慕神经网络的惊人效果?不需要tf,不需要caffe,不需要pytorch!只要一句话,便可以实现多层神经网络!!!
在这里还是简单说一下M-P神经元的原理:
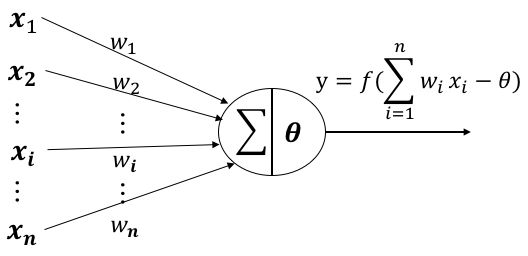
神经元
?? 来自第?个神经元的输入
?? 第?个神经元的连接权重
? 阈值(threshold)或称为偏置(bias)
? 为激活函数,常用:sigmoid,relu,tanh等等
对于一个神经元来说,有i个输入,每一个输入都对应一个权重(w),神经元具有一个偏置(阈值),将所有的i*w求和后减去阈值得到一个值,这个值就是激活函数的参数,激活函数将根据这个参数来判定这个神经元是否被激活。
本质上, M-P神经元=线性二分类器
那么什么是多层神经网络?
线性不可分:一个超平面没法解决问题,就用两个超平面来解决,什么?还不行!那就再增加超平面直到解决问题为止。 ——多层神经网络
没错,多层神经元就是用来解决线性不可分问题的。
那么,sklearn中如何实现呢?
import sklearn.neural_network as sk_nn
model = sk_nn.MLPClassifier(activation='tanh',solver='adam',alpha=0.0001,learning_rate='adaptive',learning_rate_init=0.001,max_iter=200)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print('神经网络模型评价:',acc)
参数说明:
hidden_layer_sizes: 元祖
activation:激活函数 {‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认 ‘relu’
solver :优化算法{‘lbfgs’, ‘sgd’, ‘Adam’}
alpha:L2惩罚(正则化项)参数
learning_rate:学习率 {‘constant’, ‘invscaling’, ‘adaptive’}
learning_rate_init:初始学习率,默认0.001
max_iter:最大迭代次数 默认200
特别:
学习率中参数:
constant: 有‘learning_rate_init’给定的恒定学习率
incscaling:随着时间t使用’power_t’的逆标度指数不断降低学习率
adaptive:只要训练损耗在下降,就保持学习率为’learning_rate_init’不变
优化算法参数:
lbfgs:quasi-Newton方法的优化器
sgd:随机梯度下降
adam: Kingma, Diederik, and Jimmy Ba提出的机遇随机梯度的优化器
打印结果:(神经网络的确牛逼)
神经网络模型评价: 0.980952380952
KNN(K-近邻算法)
KNN可以说是非常好用,也非常常用的分类算法了,也是最简单易懂的机器学习算法,没有之一。由于算法先天优势,KNN甚至不需要训练就可以得到非常好的分类效果了。
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
其算法的描述为:
1.计算测试数据与各个训练数据之间的距离;
2.按照距离的递增关系进行排序;
3.选取距离最小的K个点;
4.确定前K个点所在类别的出现频率;
5.返回前K个点中出现频率最高的类别作为测试数据的预测分类。
(感觉又说多了...... - -!)
其实这个算法自己实现起来也就只有几行代码,这里我们还是使用sklearn来实现。
sklearn中的KNN可以做分类也可以做回归
import sklearn.neighbors as sk_neighbors
#KNN分类
model = sk_neighbors.KNeighborsClassifier(n_neighbors=5,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值
print('KNN模型(分类)评价:',acc)
#KNN回归
model = sk_neighbors.KNeighborsRegressor(n_neighbors=5,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #返回预测的确定系数R2
print('KNN模型(回归)评价:',acc)
参数说明:
n_neighbors: 使用邻居的数目
n_jobs:并行任务数
打印结果:
KNN模型(分类)评价: 0.942857142857
KNN模型(回归)评价: 0.926060606061
交叉验证
好的,终于说完了常用模型,感觉完全是一个算法概述啊hhhhh
既然我们现在已经完成了数据的获取,模型的建立,那么最后一步便是验证我们的模型
其实交叉验证应该放在数据集的划分那里,但是他又与模型的验证紧密相关,所以我就按照编写代码的顺序进行讲解了。
首先,什么是交叉验证?
这里完全引用西瓜书,因为我觉得书上写的非常清楚!!!
交叉验证法先将数据集D划分为k个大小相似的互斥子集,每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后每次用k-1个子集的并集做为训练集,余下的子集做为测试集,这样就可以获得K组训练/测试集,从而可以进行k次训练和测试,最终返回的是这个k个测试结果的均值。k通常的取值是10,其他常用取值为2,5,20等。
这里使用KNN做为训练模型,采用十折交叉验证。
model = sk_neighbors.KNeighborsClassifier(n_neighbors=5,n_jobs=1) #KNN分类
import sklearn.model_selection as sk_model_selection
accs=sk_model_selection.cross_val_score(model, iris_X, y=iris_y, scoring=None,cv=10, n_jobs=1)
print('交叉验证结果:',accs)
参数说明:
model:拟合数据的模型
cv : 子集个数 就是k
scoring: 打分参数 默认‘accuracy’、可选‘f1’、‘precision’、‘recall’ 、‘roc_auc’、'neg_log_loss'
打印结果:
交叉验证结果:
[ 1. 0.93333333 1. 1. 0.86666667 0.93333333
0.93333333 1. 1. 1. ]
模型的保存和载入
模型的保存和载入方便我们将训练好的模型保存在本地或发送在网上,载入模型方便我们在不同的环境下进行测试。
使用pickle可以进行保存与载入
也可以使用sklearn自带的函数
import sklearn.externals as sk_externals
sk_externals.joblib.dump(model,'model.pickle') #保存
model = sk_externals.joblib.load('model.pickle') #载入
小结
两篇帖子基本完成了对于sklearn的基础讲解,看似内容虽多,但是使用起来其实非常简单。不小心写成一个算法概述,也没什么太大的问题,相信我不写,大家也会去百度这些算法的含义,我就当这是为大家省时间了吧哈哈哈。
sklearn是一个非常好用的机器学习工具包,掌握好它会在机器学习的道路上祝我们一臂之力的!
与君共勉!