主流的深度学习推理架构有哪些呢?
简介
以深度学习为主的人工智能算法模型在日常AI应用中逐渐占据主流方向,相关的各类产品也是层出不穷。我们平时所看到的AI产品,像刷脸支付、智能语音、银行的客服机器人等,都是AI算法的具体落地应用。AI技术在具体落地应用方面,和其他软件技术一样,也需要具体的部署和实施的。既然要做部署,那就会有不同平台设备上的各种不同的部署方法和相关的部署架构工具,目前在人工智能的落地部署方面,各大平台机构也都是大展身手,纷纷推出自家的部署平台。
目前市场上应用最广泛的部署工具主要有以下几种:腾讯公司开发的移动端平台部署工具——NCNN;Intel公司针对自家设备开开发的部署工具——OpenVino;NVIDIA公司针对自家GPU开发的部署工具——TensorRT;Google针对自家硬件设备和深度学习框架开发的部署工具——MediaPipe;由微软、亚马逊 、Facebook 和 IBM 等公司共同开发的开放神经网络交换格式——ONNX(Open Neural Network Exchange)。除此之外,还有一些深度学习框架有自己的专用部署服务:比如TensorFlow自己提供的部署服务:TensorFlow Serving、TensorFlow Lite,pytorch自己提供的部署服务:libtorch。

本文主要是针对这些不同的部署工具做一个简单的分析,对比一下各家不同的部署工具到底有哪些优势和不足之处,方便大家在做部署的时候能够找到适合自己的项目的部署方法。具体的各种不同的部署工具的下载安装和使用方法会在后续的文章中做出详细的教程,关注深度人工智能学院,了解最实用的人工智能干货知识。
NCNN
NCNN是腾讯优图实验室首个开源项目,是一个为手机端极致优化的高性能神经网络前向计算框架。并在2017年7月正式开源。NCNN做为腾讯优图最“火”的开源项目之一,是一个为手机端极致优化的高性能神经网络前向计算框架,在设计之初便将手机端的特殊场景融入核心理念,是业界首个为移动端优化的开源神经网络推断库。能实现无第三方依赖,跨平台操作,在手机端CPU运算速度在开源框架中处于领先水平。基于该平台,开发者能够轻松将深度学习算法移植到手机端,输出高效的执行,进而产出人工智能APP,将AI技术带到用户指尖。
NCNN从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 CPU的速度快于目前所有已知的开源框架。基于 NCNN,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,将 AI 带到你的指尖。NCNN目前已在腾讯多款应用中使用,如 QQ,Qzone,微信,天天P图等。
下面是NCNN在各大系统平台的应用发展状态情况:

从NCNN的发展矩阵可以看出,NCNN覆盖了几乎所有常用的系统平台,尤其是在移动平台上的适用性更好,在Linux、Windows和Android、以及iOS、macOS平台上都可以使用GPU来部署模型。
根据官方的功能描述,NCNN在各方面的性能都比较优良:
l 支持卷积神经网络,支持多输入和多分支结构,可计算部分分支
l 无任何第三方库依赖,不依赖 BLAS/NNPACK 等计算框架
l 纯 C++ 实现,跨平台,支持 android ios 等
l ARM NEON 汇编级良心优化,计算速度极快
l 精细的内存管理和数据结构设计,内存占用极低
l 支持多核并行计算加速,ARM big.LITTLE cpu 调度优化
l 支持基于全新低消耗的 vulkan api GPU 加速
l 整体库体积小于 700K,并可轻松精简到小于 300K
l 可扩展的模型设计,支持 8bit 量化 和半精度浮点存储,可导入 caffe/pytorch/mxnet/onnx/darknet/keras/tensorflow(mlir) 模型
l 支持直接内存零拷贝引用加载网络模型
l 可注册自定义层实现并扩展
l 恩,很强就是了,不怕被塞卷 QvQ
除此之外,NCNN在对各种硬件设备的支持上也非常给力:

NCNN的官方代码地址:https://github.com/Tencent/ncnn
移动端的部署工具除了NCNN,还有华盛顿大学的TVM、阿里的MNN、小米的MACE、腾讯优图基于NCNN开发的TNN等推理部署工具。
OpenVino
OpenVINO工具套件全称是Open Visual Inference & Neural Network Optimization,是Intel于2018年发布的,开源、商用免费、主要应用于计算机视觉、实现神经网络模型优化和推理计算(Inference)加速的软件工具套件。由于其商用免费,且可以把深度学习模型部署在英尔特CPU和集成GPU上,大大节约了显卡费用,所以越来越多的深度学习应用都使用OpenVINO工具套件做深度学习模型部署。
OpenVINO是一个Pipeline工具集,同时可以兼容各种开源框架训练好的模型,拥有算法模型上线部署的各种能力,只要掌握了该工具,你可以轻松的将预训练模型在Intel的CPU上快速部署起来。
对于AI工作负载来说,OpenVINO提供了深度学习推理套件(DLDT),该套件可以将各种开源框架训练好的模型进行线上部署,除此之外,还包含了图片处理工具包OpenCV,视频处理工具包Media SDK,用于处理图像视频解码,前处理和推理结果后处理等。
在做推理的时候,大多数情况需要前处理和后处理,前处理如通道变换,取均值,归一化,Resize等,后处理是推理后,需要将检测框等特征叠加至原图等,都可以使用OpenVINO工具套件里的API接口完成。
OpenVino目前支持Linux、Windows、macOS、Raspbian等系统平台。

OpenVINO工具套件主要包括:Model Optimizer(模型优化器)——用于优化神经网络模型的工具,Inference Engine(推理引擎)——用于加速推理计算的软件包。
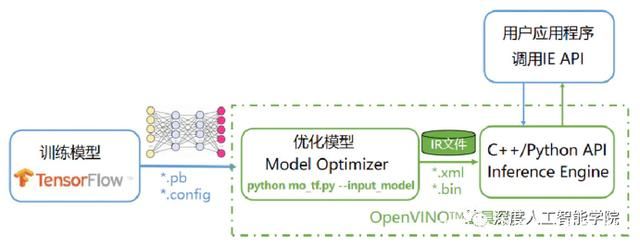
模型优化器是一个python脚本工具,用于将开源框架训练好的模型转化为推理引擎可以识别的中间表达,其实就是两个文件,xml和bin文件,前者是网络结构的描述,后者是权重文件。模型优化器的作用包括压缩模型和加速,比如,去掉推理无用的操作(Dropout),层的融合(Conv + BN + Relu),以及内存优化。
推理引擎是一个支持C\C++和python的一套API接口,需要开发人员自己实现推理过程的开发,开发流程其实非常的简单,核心流程如下:
l 装载处理器的插件库
l 读取网络结构和权重
l 配置输入和输出参数
l 装载模型
l 创建推理请求
l 准备输入Data
l 推理
l 结果处理
OpenVino工具套件的工作流程图:
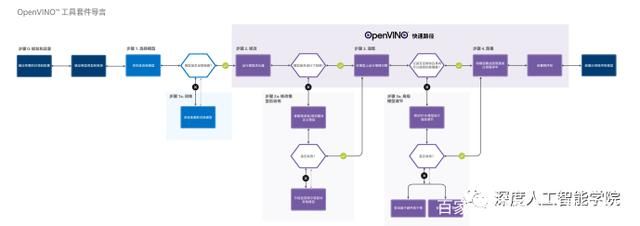
OpenVino的官方地址:https://docs.openvinotoolkit.org/latest/index.html
提醒一下,大家不要去下面这个网站,因为这个网站是一个酿酒厂的网站:
https://openvino.org/
TensorRT
TensorRT是NVIDIA开发的一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行高性能推理(Inference)加速,它可为深度学习推理应用提供低延迟和高吞吐量。在推理期间,基于 TensorRT 的应用比仅 CPU 平台的执行速度快 40 倍。
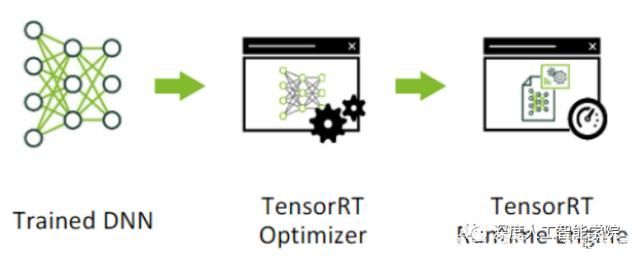
一般的深度学习项目,训练时为了加快速度,会使用多 GPU 分布式训练。但在部署推理时,为了降低成本,往往使用单个 GPU 机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如 caffe,TensorFlow 等。由于训练的网络模型可能会很大(比如,inception,resnet 等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如 squeezenet,mobilenet,shufflenet 等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而 TensorRT 则是对训练好的模型进行优化。TensorRT 就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进 TensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow 等)
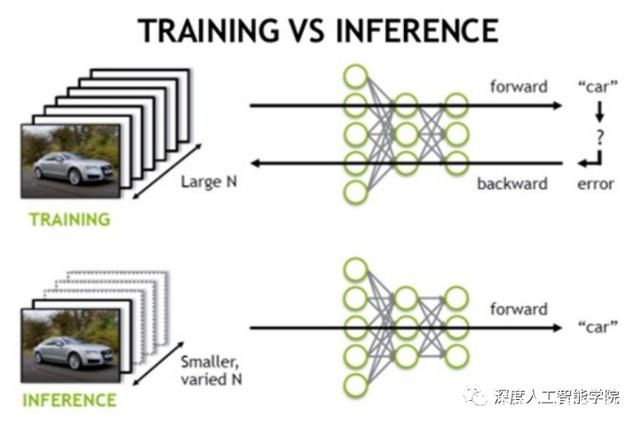
可以认为 TensorRT 是一个只有前向传播的深度学习推理框架,这个框架可以将Caffe,TensorFlow,PyTorch 等网络模型解析,然后与 TensorRT 中对应的层进行一一映射,把其他框架的模型统一全部转换到 TensorRT 中,然后在 TensorRT 中可以针对 NVIDIA 自家 GPU 实施优化策略,并进行部署加速。

TensorRT依赖于Nvidia的深度学习硬件环境,可以是GPU也可以是DLA,如果没有的话则无法使用。TensorRT支持目前大部分的神经网络Layer的定义,同时提供了API让开发者自己实现特殊Layer的操作。
TensorRT 基于 CUDA,NVIDIA 的并行编程模型,能够利用 CUDA-X AI 中的库、开发工具和技术,为人工智能、自动机器、高性能计算和图形优化所有深度学习框架的推理。
TensorRT的部署分为两个部分:
1. 优化训练好的模型并生成计算流图
2. 使用TensorRT Runtime部署计算流图
TensorRT的部署流程:

TensorRT的模型导入流程:

TensorRT的优化过程:
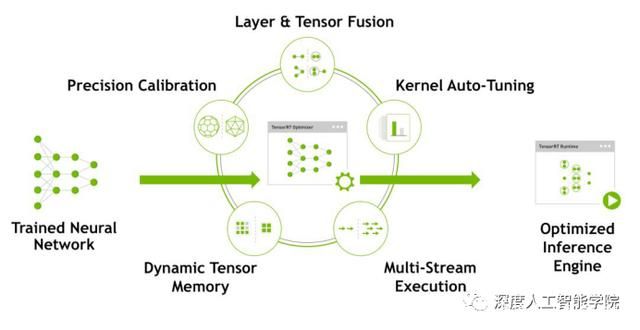
网络模型在导入至TensorRT后会进行一系列的优化,主要优化内容如下图所示
TensorRT官网下载地址:https://developer.nvidia.com/zh-cn/tensorrt
开发者指南:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html
Github地址:https://github.com/NVIDIA/TensorRT
MediaPipe
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 MediaPipe。
MediaPipe 是一个基于图形的跨平台框架,用于构建多模式(视频,音频和传感器)应用的机器学习管道。MediaPipe 可在移动设备、工作站和服务器上跨平台运行,并支持移动 GPU 加速。使用 MediaPipe,可以将应用的机器学习管道构建为模块化组件的图形。MediaPipe 不仅可以被部署在服务器端,更可以在多个移动端 (安卓和苹果 iOS)和嵌入式平台(Google Coral 和树莓派)中作为设备端机器学习推理 (On-device Machine Learning Inference)框架。
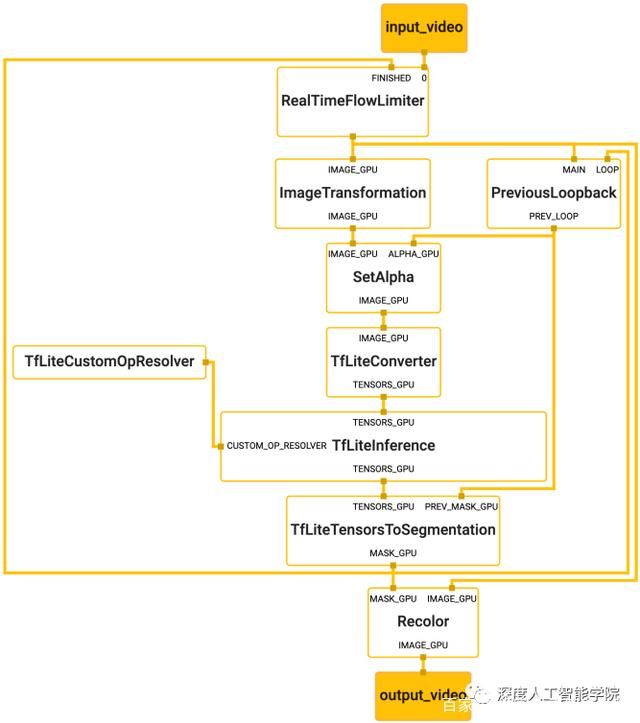
一款多媒体机器学习应用的成败除了依赖于模型本身的好坏,还取决于设备资源的有效调配、多个输入流之间的高效同步、跨平台部署上的便捷程度、以及应用搭建的快速与否。
基于这些需求,谷歌开发并开源了 MediaPipe 项目。除了上述的特性,MediaPipe 还支持 TensorFlow 和 TF Lite 的推理引擎(Inference Engine),任何 TensorFlow 和 TF Lite 的模型都可以在 MediaPipe 上使用。同时,在移动端和嵌入式平台,MediaPipe 也支持设备本身的 GPU 加速。
MediaPipe 专为机器学习(ML)从业者而设计,包括研究人员,学生和软件开发人员,他们实施生产就绪的 ML 应用程序,发布伴随研究工作的代码,以及构建技术原型。MediaPipe 的主要用例是使用推理模型和其他可重用组件对应用机器学习管道进行快速原型设计。MediaPipe 还有助于将机器学习技术部署到各种不同硬件平台上的演示和应用程序中。
MediaPipe 的核心框架由 C++ 实现,并提供 Java 以及 Objective C 等语言的支持。MediaPipe 的主要概念包括数据包(Packet)、数据流(Stream)、计算单元(Calculator)、图(Graph)以及子图(Subgraph)。数据包是最基础的数据单位,一个数据包代表了在某一特定时间节点的数据,例如一帧图像或一小段音频信号;数据流是由按时间顺序升序排列的多个数据包组成,一个数据流的某一特定时间戳(Timestamp)只允许至多一个数据包的存在;而数据流则是在多个计算单元构成的图中流动。MediaPipe 的图是有向的——数据包从数据源(Source Calculator或者 Graph Input Stream)流入图直至在汇聚结点(Sink Calculator 或者 Graph Output Stream) 离开。
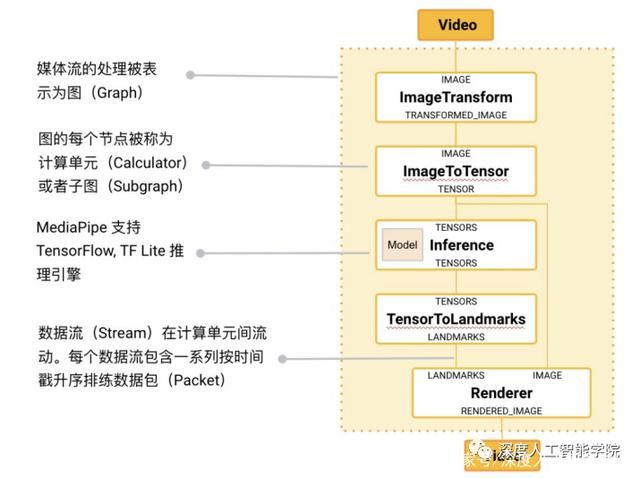
MediaPipe 在开源了多个由谷歌内部团队实现的计算单元(Calculator)的同时,也向用户提供定制新计算单元的接口。创建一个新的 Calculator,需要用户实现 Open(),Process(),Close() 去分别定义 Calculator 的初始化,针对数据流的处理方法,以及 Calculator 在完成所有运算后的关闭步骤。为了方便用户在多个图中复用已有的通用组件,例如图像数据的预处理、模型的推理以及图像的渲染等, MediaPipe 引入了子图(Subgraph)的概念。因此,一个 MediaPipe 图中的节点既可以是计算单元,亦可以是子图。子图在不同图内的复用,方便了大规模模块化的应用搭建。
MediaPipe不支持除了tensorflow之外的其他深度学习框架,但是对各种系统平台和语言的支持非常友好:

MediaPipe的官方地址:https://google.github.io/mediapipe/
GitHub地址:https://github.com/google/mediapipe
ONNX
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有:Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。
比方说现在某组织因为主要开发用TensorFlow为基础的框架,现在有一个深度算法,需要将其部署在移动设备上,以观测变现。传统地我们需要用caffe2重新将模型写好,然后再训练参数;试想下这将是一个多么耗时耗力的过程。
此时,ONNX便应运而生,Caffe2,PyTorch,Microsoft Cognitive Toolkit,Apache MXNet等主流框架都对ONNX有着不同程度的支持。这就便于了我们的算法及模型在不同的框架之间的迁移。无论你使用何种训练框架训练模型(比如TensorFlow/Pytorch/OneFlow/Paddle),在训练完毕后你都可以将这些框架的模型统一转换为ONNX这种统一的格式进行存储。
开放式神经网络交换(ONNX)是迈向开放式生态系统的第一步,它使AI开发人员能够随着项目的发展选择合适的工具。ONNX为AI模型提供开源格式。它定义了可扩展的计算图模型,以及内置运算符和标准数据类型的定义。最初的ONNX专注于推理(评估)所需的功能。ONNX解释计算图的可移植,它使用graph的序列化格式。它不一定是框架选择在内部使用和操作计算的形式。例如,如果在优化过程中操作更有效,则实现可以在存储器中以不同方式表示模型。
在获得ONNX模型之后,模型部署人员自然就可以将这个模型部署到兼容ONNX的运行环境中去。这里一般还会设计到额外的模型转换工作,典型的比如在Android端利用NCNN部署ONNX格式模型,那么就需要将ONNX利用NCNN的转换工具转换到NCNN所支持的bin和param格式。
ONNX作为一个文件格式,我们自然需要一定的规则去读取我们想要的信息或者是写入我们需要保存信息。ONNX使用的是Protobuf这个序列化数据结构去存储神经网络的权重信息。熟悉Caffe或者Caffe2的同学应该知道,它们的模型存储数据结构协议也是Protobuf。
Protobuf是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API(摘自官方介绍)。
Protobuf协议是一个以*.proto后缀文件为基础的,这个文件描述了用户自定义的数据结构。如果需要了解更多细节请参考0x7节的资料3,这里只是想表达ONNX是基于Protobuf来做数据存储和传输,那么自然onnx.proto就是ONNX格式文件了。
ONNX作为框架共用的一种模型交换格式,使用 protobuf 二进制格式来序列化模型,可以提供更好的传输性能我们可能会在某一任务中将 Pytorch 或者 TensorFlow 模型转化为 ONNX 模型(ONNX 模型一般用于中间部署阶段),然后再拿转化后的 ONNX模型进而转化为我们使用不同框架部署需要的类型,ONNX 相当于一个翻译的作用。

ONNX将每一个网络的每一层或者说是每一个算子当作节点Node,再由这些Node去构建一个Graph,相当于是一个网络。最后将Graph和这个onnx模型的其他信息结合在一起,生成一个model,也就是最终的.onnx的模型。
构建一个简单的onnx模型,实质上,只要构建好每一个node,然后将它们和输入输出超参数一起塞到graph,最后转成model就可以了。
在计算方面,虽然更高级的表达不同,但不同框架产生的最终结果都是非常接近。因此实时跟踪某一个神经网络是如何在这些框架上生成的,接着使用这些信息创建一个通用的计算图,即符合ONNX标准的计算图。
ONNX为可扩展的计算图模型、内部运算器(Operator)以及标准数据类型提供了定义。在初始阶段,每个计算数据流图以节点列表的形式组织起来,构成一个非循环的图。节点有一个或多个的输入与输出。每个节点都是对一个运算器的调用。图还会包含协助记录其目的、作者等信息的元数据。运算器在图的外部实现,但那些内置的运算器可移植到不同的框架上,每个支持ONNX的框架将在匹配的数据类型上提供这些运算器的实现。
Microsoft 和合作伙伴社区创建了 ONNX 作为表示机器学习模型的开放标准。 许多框架(包括 TensorFlow、PyTorch、SciKit-Learn、Keras、Chainer、MXNet、MATLAB 和 SparkML)中的模型都可以导出或转换为标准 ONNX 格式。模型采用 ONNX 格式后,可在各种平台和设备上运行。
ONNX 运行时是一种用于将 ONNX 模型部署到生产环境的高性能推理引擎。它针对云和 Edge 进行了优化,适用于 Linux、Windows 和 Mac。它使用 C++ 编写,还包含 C、Python、C#、Java 和 Javascript (Node.js) API,可在各种环境中使用。ONNX 运行时同时支持 DNN 和传统 ML 模型,并与不同硬件上的加速器(例如,NVidia GPU 上的 TensorRT、Intel 处理器上的 OpenVINO、Windows 上的 DirectML 等)集成。通过使用 ONNX 运行时,可以从大量的生产级优化、测试和不断改进中受益。
ONNX 运行时用于大规模 Microsoft 服务,如必应、Office 和 Azure 认知服务。性能提升取决于许多因素,但这些 Microsoft 服务的 CPU 平均起来可实现 2 倍的性能提升。除了 Azure 机器学习服务外,ONNX 运行时还在支持机器学习工作负荷的其他产品中运行,包括:
l Windows:该运行时作为 Windows 机器学习的一部分内置于 Windows 中,在数亿台设备上运行。
l Azure SQL 产品系列:针对 Azure SQL Edge 和 Azure SQL 托管实例中的数据运行本机评分。
l ML.NET:在 ML.NET 中运行 ONNX 模型。

ONNX的官方网站:https://onnx.ai/
ONXX的GitHub地址:https://github.com/onnx/onnx