MindSpore 环境搭建操作手册
目录
1.准备工作
2.服务器的购买(华为云)
3.ssh远程连接服务器
4.关于cuda的安装及配置
5.关于cudnn的安装及配置
6.关于anaconda的配置
7.关于GMP的配置
8.验证配置是否成功
9.关于pycharm的远程连接
10.Mindinsight安装与使用
参考链接
1.准备工作
1.完成pycharm专业版的安装
2.windows系统下可通过cmd进行ssh连接,mac下可通过终端进行ssh连接
2.服务器的购买(华为云)
注意:本教程为了适配后期神经网络的训练,只梳理了华为云GPU的服务器购买流程,旨在为入门小白提供服务器购买的范例,您可根据需要选择符合您实际需要的服务器规格。
1.官网完成账户的登陆 https://www.huaweicloud.com/ 进入首页后如下图所示
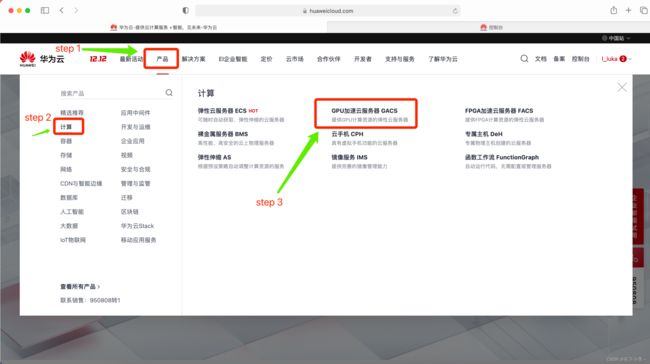
2.点击进入后如下图所示,下滑页面找到推荐配置,根据下图点击立即购买
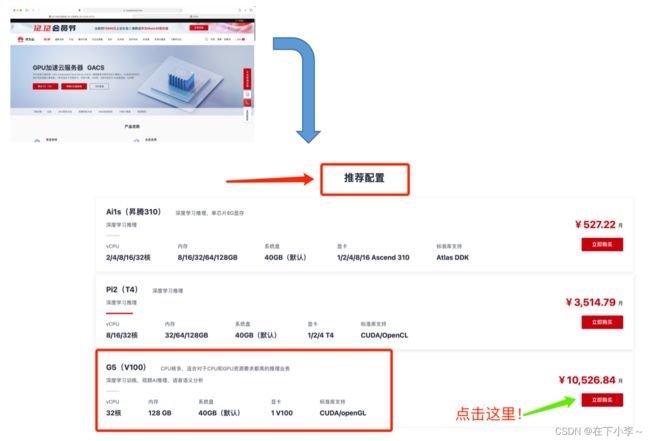
3.待页面跳转后,选择按需付费,华北-北京四,选择如下所示服务器
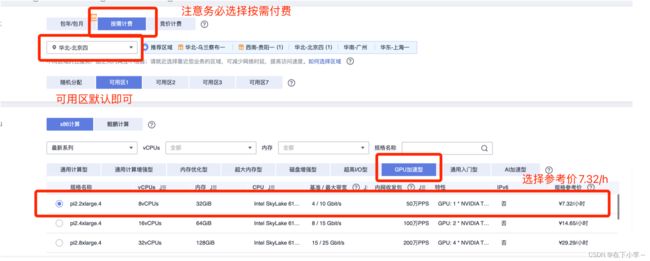
4.继续下拉页面,确认规格,选择镜像,系统盘规格选择通用型,100GiB 点击下一步
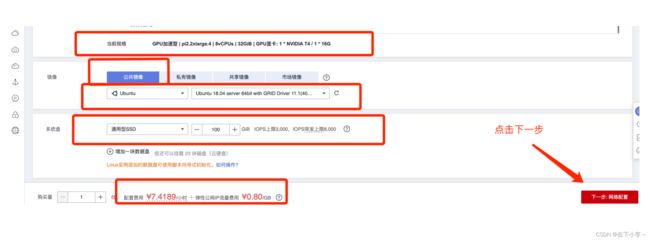
5.进入网络配置,网络和安全组均选择默认配置即可 然后选择下一步,进入高级配置
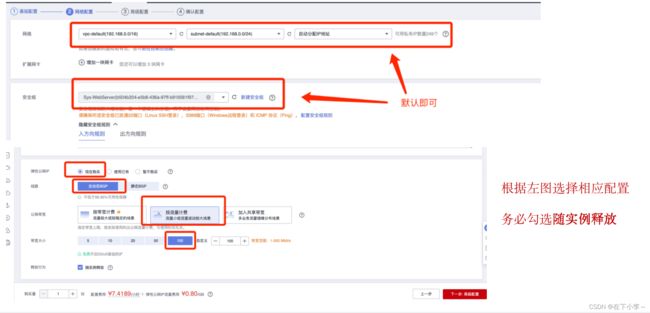
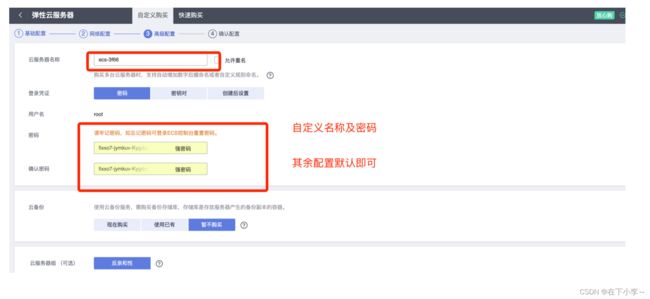
6.进入高级配置,云服务名称和密码自定义 其余配置默认即可
7.进入确认配置中,与下图核对配置,勾选协议并选择立即购买即可完成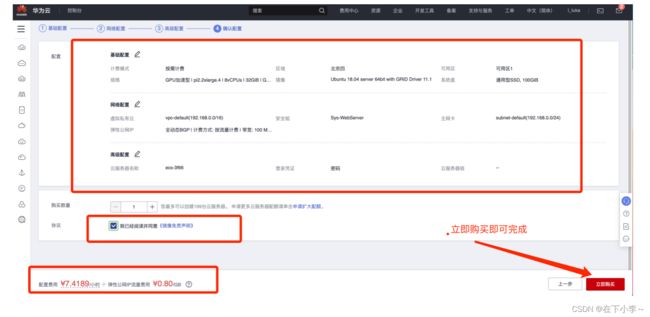
注意:当您购买按需付费的服务器时,在实验或项目结束后,切记及时关闭服务器,以免造成数据资源的浪费。
3.ssh远程连接服务器
1.登陆服务器,查看驱动程序是否正常
ssh root@公网IP #(这里的IP对应购买的服务器的ip)
输入密码 #(对应购买服务器的时候设置的root密码)
nvidia-smi #表示驱动程序正常(若正常的话显示如下图)
2.下载mindspore所需环境
我们已将mindspore所需的配置文件整理并上传,您可通过以下途径自行下载:
亿方云链接: https://v2.fangcloud.com/share/fc4dfe5c7a01e32c8cba54c182 访问密码:bistu
百度网盘链接: https://pan.baidu.com/s/15AwkAA0fzlVwkt4eYzQ83w 提取码: 63c8
上述下载好的mindspore环境配置文件需要上传至服务器中。
3.然后依次执行下述命令:
apt update
tar -xvf mindspore_env.tar #解压上述下载的环境包
ls #确认文件信息如下

4.关于CUDA的安装及配置
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。当我们在进行深度学习任务时,我们有时需要使用GPU版本的框架,比如tensorflow-gpu或者mindspore-gpu版本就需要安装CUDA和CUDNN进行GPU加速支持。
1.执行下述操作
sh cuda_10.1.105_418.39_linux.run #执行cuda安装程序 等待大约30s执行结果如下图所示:
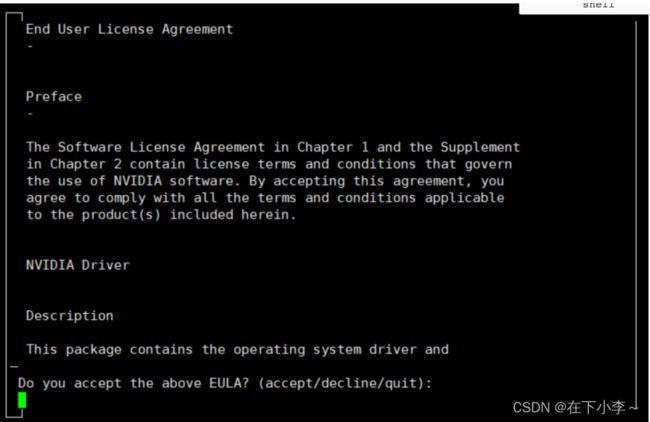
接下来输入: accept 回车
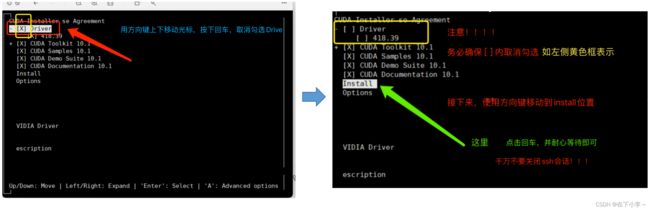
2.接下来显示页面如下图所示,取消勾选Driver,并按下述右图所示完成安装(Install)
3.执行成功如下图所示
4.执行下述操作,在配置文件中加入支持cuda的配置语句
#第一步 用vim打开环境配置文件
vim /etc/profile #配置环境变量
#第二步 将光标移至最后文章末尾,并按i进入编辑模式
#第三步 在文本的末尾添加如下文本
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64"
#第四步 编辑完成后,按esc退出编辑模式,输入 :wq 保存并退出即可source /etc/profile #更新环境变量
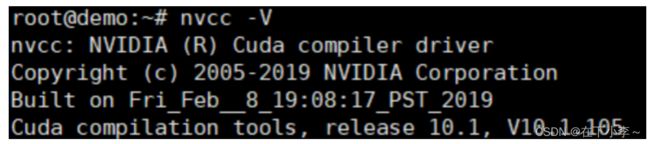
nvcc -V # 验证cuda的安装结果如下图所示
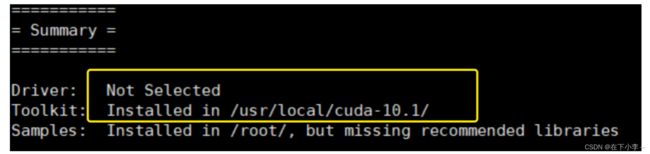
5.若结果如下图所示,则cuda配置已完成
5.关于cudnn的安装及配置
1.执行下述操作
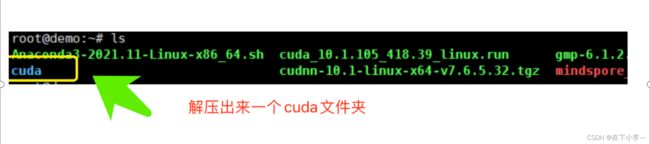
tar -xzvf cudnn-10.1-linux-x64-v7.6.5.32.tgz #解压关于cudnn的配置文件
ls #查看目录,确认是否完成解压
2. 继续执行下述操作
cd cuda #进入解压出来的cuda文件夹
ls #查看当前目录文件结构
cp ./include/* /usr/local/cuda/include/ #拷贝
cp ./lib64/* /usr/local/cuda/lib64/
chmod a+r /usr/local/cuda/include/cudnn* /usr/local/cuda/lib64/libcudnn* #修改文件权限
cd # 返回home目录即可进行下一步配置
6.关于Anaconda的配置
Conda是一个包管理器;Anaconda是一个发行包。 Conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。包管理与pip的使用类似,环境管理则允许用户方便地安装不同版本的python并可以快速切换 。Anaconda是一个打包的集合器皿,里面预装好了Conda、某个版本的python、众多packages、科学计算工具等等,所以也称为Python的一种发行版。
1.执行下述操作
sh Anaconda3-2021.11-Linux-x86_64.sh #执行Anaconda的安装命令
2.如出现下图,直接按回车即可

连续按enter键,直到出现命令(Please answer 'yes' or 'no'),输入yes
3.若出现下图,输入yes即可

4.当出现以下结果,断开ssh连接(输入exit后回车),然后再通过ssh连接到服务器
5.重新连接后,如下图所示,左侧出现(base),表示成功
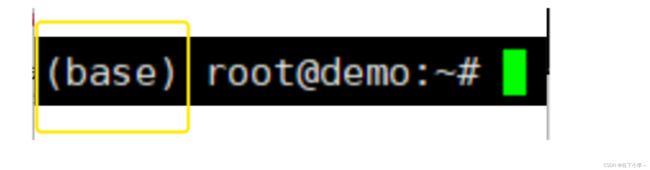
6.执行下述操作
conda create -n mindspore_py39 -c conda-forge python=3.9.0 #利用conda命令创建python3.9.0的虚环境
当出现如下结果后,输入y
7.出现以下画面,表示安装成功

8.执行下述操作,执行结果如下图所示:
conda activate mindspore_py39 
9.安装mindspore框架
conda install mindspore-gpu=1.5.0 cudatoolkit=10.1 -c mindspore -c conda-forge
#出现结果如下图所示:
10.输入 y ,等待片刻,结果如下图则成功

7.关于GMP的配置
关于Gmp:Gmp 是一个mindspore 框架需要的数学计算库
1.执行下述操作
apt install m4 #安装GMP需要的工具
tar -xPvf gmp-6.1.2.tar.xz #gmp后自动补全
解压出来的目录如下所示

2.依次执行下述操作
cd gmp-6.1.2/
./configure --enable-cxx #安装成功后,如下图所示
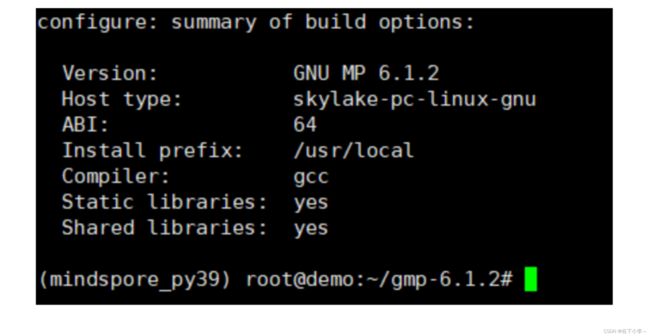
3.执行下述操作
make #等待片刻
make check
make install
cd #回到home目录
到此,GMP的配置已完成,接下来,我们来验证上述的配置是否成功
8.验证配置是否成功
1.执行下述操作
python -c "import mindspore;mindspore.run_check()"
#出现以下结果
2.执行下述操作
cd #回到home目录
python mindspore_test.py
#出现以下结果则表示成功
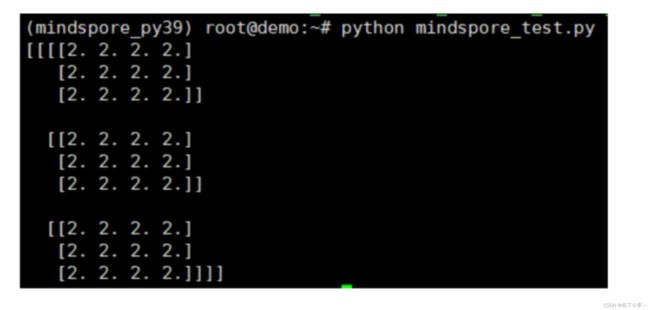
注意:上述mindspore_test.py文件内容如下,您也可以自行复制执行,完成测试:
import numpy as np
import mindspore
from mindspore import nn, Model
from mindspore.dataset import GeneratorDataset
from mindspore.train.callback import LossMonitor, TimeMonitor
class DatasetGenerator:
def __init__(self, inputs, targets):
self.inputs = inputs
self.targets = targets
def __getitem__(self, item):
return np.array([self.inputs[item]]), np.array([self.targets[item]])
def __len__(self):
return len(self.inputs)
def main():
inputs = np.linspace(-50000, 50000, 100000, dtype=np.float32)
targets = inputs * 3 + 2
dataset_generator = DatasetGenerator(inputs, targets)
dataset = GeneratorDataset(source=dataset_generator, column_names=['inputs', 'targets'],
column_types=[mindspore.float32, mindspore.float32])
dataset = dataset.batch(batch_size=100)
linear = nn.Dense(in_channels=1, out_channels=1)
loss_fn = nn.MSELoss()
optimizer = nn.Adam(linear.trainable_params(), learning_rate=0.01)
model = Model(network=linear, loss_fn=loss_fn, optimizer=optimizer)
model.train(epoch=15, train_dataset=dataset, callbacks=[LossMonitor(), TimeMonitor()])
print('线性回归样例:y=3x+2, x = {1, 2, 3}')
outputs = model.predict(mindspore.Tensor([[1], [2], [3]], dtype=mindspore.float32))
print(outputs.asnumpy())
if __name__ == '__main__':
main()
9.关于pycharm的远程连接
接下来我们介绍如何在pycharm中实现服务器的远程连接,具体的配置操作如下:
1.首先打开pycharm,找到python Interpreter
2.如下图,点击齿轮⚙️,选择add

3.选择SSH Interpreter,并输入您的服务器公网IP地址以及Username,选择Next
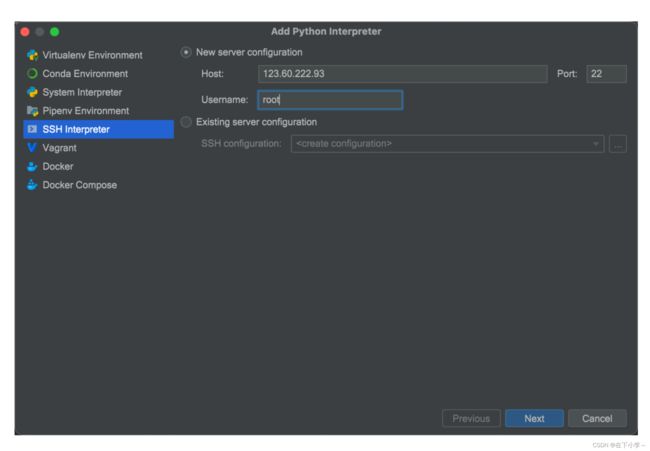
4.接下来输入root密码,点击next
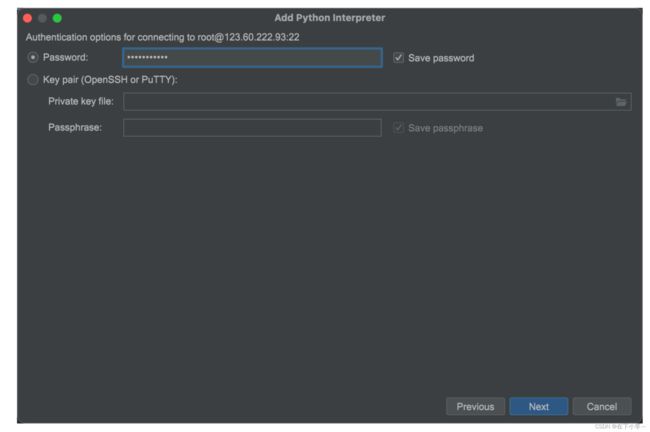
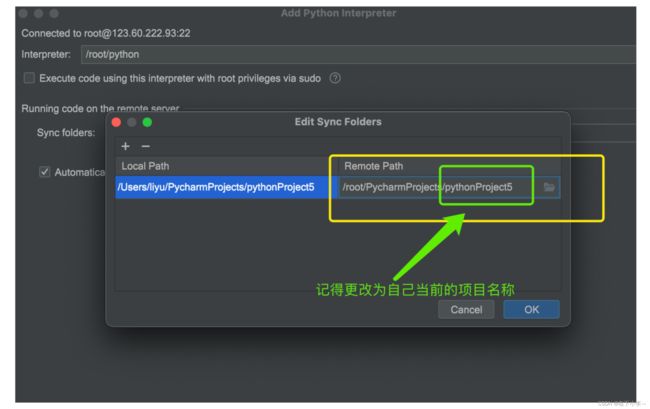
5.更改路径地址,选择/root/python

6.如下图所示编辑Remote Path即可,绿色框中的地址为您当前项目的路径
7.配置完成后显示如下图所示,点击Apply完成远程连接
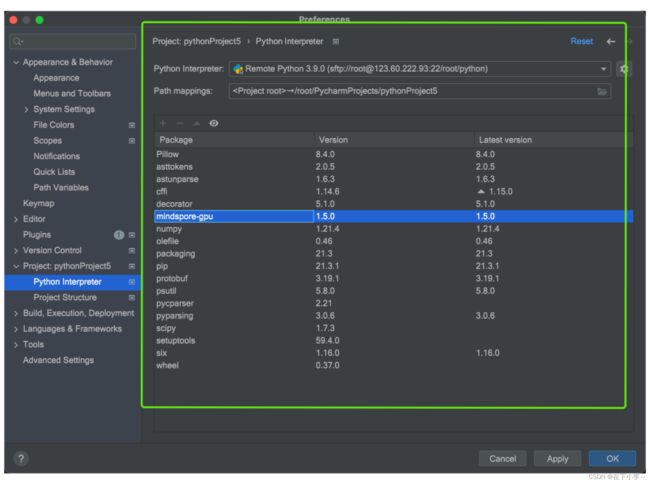
8.测试样例如下,执行下图所示demo,输出结果如红色区域所示,则表示远程连接成功

10.Mindinsight安装与使用
在深度学习或者其他参数优化领域中,对于结果的可视化以及中间网络结构的可视化,是一个非常重要的工作。一个好的可视化工具,可以更加直观的展示计算结果,可以帮助人们更快的发掘大量的数据中最有用的信息。接下来我们介绍MindSpore框架下的可视化工具MindInsigh的基本配置及使用方法。
1.首先安装MindInsigh需要在mindspore的conda环境下,执行下述操作
conda activate mindspore_py39
2.通过官网找到对应的下载命令
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.5.0/MindInsight/any/mindinsight-1.5.0-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple3.更改配置文件,使允许被外网访问
cd /root/anaconda3/envs/mindspore_py39/lib/python3.9/site-packages/mindinsight/conf/
vim constants.py #将文件中的HOST改为0.0.0.0如果mindspore的conda环境名不是mindspore_py39,则自行替换路径中的环境名 将文件中的HOST从127.0.0.1改为0.0.0.0
4.启动Mindinsight
mindinsight start –summary-base-dir /root/summary5.关闭Mindinsight
mindinsight stop6.可视化的网页地址为—公网IP地址:8080(例如:123.60.222.93:8080)
您需要先在您购买的服务器上,打开8080端口的服务
您在浏览器中输入http://123.60.222.93:8080即可打开训练数据的可视化面板。
7.最后,您可以执行下述demo文件查看您的配置是否成功
import numpy as np
import mindspore
from mindspore import nn, Model
from mindspore.dataset import GeneratorDataset
from mindspore.train.callback import LossMonitor, TimeMonitor, SummaryCollector
class DatasetGenerator:
def __init__(self, inputs, targets):
self.inputs = inputs
self.targets = targets
def __getitem__(self, item):
return np.array([self.inputs[item]]), np.array([self.targets[item]])
def __len__(self):
return len(self.inputs)
def main():
inputs = np.linspace(-5000, 5000, 10000, dtype=np.float32)
targets = inputs * 3 + 2
dataset_generator = DatasetGenerator(inputs, targets)
dataset = GeneratorDataset(source=dataset_generator, column_names=['inputs', 'targets'],
column_types=[mindspore.float32, mindspore.float32])
dataset = dataset.batch(batch_size=50)
linear = nn.Dense(in_channels=1, out_channels=1)
loss_fn = nn.MSELoss()
optimizer = nn.Adam(linear.trainable_params(), learning_rate=0.05)
model = Model(network=linear, loss_fn=loss_fn, optimizer=optimizer)
# model.train(epoch=20, train_dataset=dataset, callbacks=[LossMonitor(), TimeMonitor()])
model.train(epoch=15, train_dataset=dataset, callbacks=[LossMonitor(), TimeMonitor(),
SummaryCollector(summary_dir='/root/summary/',
collect_freq=1)])
print('线性回归:y=3x+2, x = {1, 2, 3}, y = {5, 8, 11}')
outputs = model.predict(mindspore.Tensor([[1], [2], [3]], dtype=mindspore.float32))
print(outputs.asnumpy())
if __name__ == '__main__':
main()
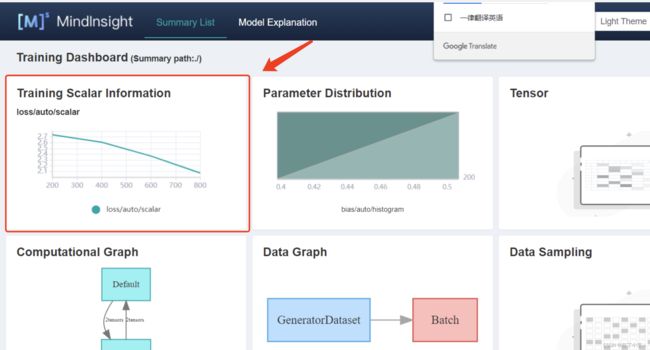
8.若上述配置成功,可视化面板中所展示的结果如下图所示
参考链接
1.https://www.cnblogs.com/dechinphy/p/nonlinear.html
2.https://www.huaweicloud.com
3.https://www.mindspore.cn
4.https://www.cnblogs.com/dechinphy/p/msinsight.html