【论文笔记】当Bert炼丹不是玄学而是哲学:Mengzi模型
论文标题:Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
论文链接:https://arxiv.org/pdf/2110.06696.pdf
论文代码:https://github.com/Langboat/Mengzi
论文作者:{Zhuosheng Zhang etc.}
今年七月,澜舟科技推出的孟子模型以十亿参数刷新了此前百亿、千亿级别参数模型轮番霸榜的中文语言理解权威评测基准 CLUE 榜单。为了促进自然语言处理技术在更广泛实际场景中的应用,澜舟科技近日开源了轻量级中文预训练语言模型——孟子模型。孟子模型基于轻量级、高效训练研究路线,有利于快速、低成本地落地现实业务场景。
Using force to suppress others leads to superficial compromise. Genuine power only comes from practicality. (以力服人者, 非心服也,力不赡也。权,然后知轻重;度,然后知长短。) — Mencius (372 BC - 289 BC)
论文摘要
近些年预训练模型(PLM)在各种NLP任务中取得了显著的效果,提升了之前传统深度序列模型的性能,众所周知预训练模型的训练在时间和资源方面是“昂贵的”,没有几十张3090或者A100就别提Sota了。所以这就要求我们使用更少的计算资源训练更有效的模型,同时保证PLM模型的强大性能。本文作者不在追求更大规模的训练模式,而是致力于轻量级且更强性能的模型开发,提出了中文预训练模型Mengzi,与其他中文语言模型相比,孟子模型最大的特点就是 小而精,只用 10亿参数就杀进中文自然语言理解 CLUE榜单前三。它采用轻量化训练策略,致力于构建十亿参数级别的小模型,充分发挥已有参数下的模型潜力,有利于快速、低成本的落地现实业务场景。
模型简介
在预训练模型(PLMs)越来越火、性能越来越强并且实际落地场景越来越丰富的背景下,预训练模型逐渐呈现为以下几种趋势:
(1)bigger Model、more Data:模型更大、数据更多
(2)more efficient architecture、 pre-training methodology:更强大的模型结构与预训练方法
(3) domain- and task-aware pre-training:领域和任务启发式预训练任务
(4)unification of vision and language modeling:视觉与文本的多模态模型
尽管使用方便,但目前plm需要消耗昂贵的资源和时间,这阻碍了广泛的预训练模型实际应用。因此,鉴于资源和开发成本,规模适中但功能强大的模型成为业界迫切需要。从技术的角度来看,关于轻量级语言模型的主要问题在于两个方面:
(1)有效的训练目标,能够快速捕获语义知识
(2)有效的策略,能够快速训练语言模型。
其次PLMs模型性能非常强大高效,能够捕获语法和语义信息,但是也面临一些问题,比如模型难以收敛,训练代价大等。设计有效语言模型目标是训练预训练模型的核心主题之一,这可以决定模型如何能够从大规模未标注数据中获取知识。目前出现了denoising strategies(去噪策略)、模型结构(比如XLNET)和辅助目标,用来提高预训练模型的能力。但是这些前沿技术主要集中英语,类似中文等语言的模型却很少,随着财务分析、多模态等特定领域的应用需求,进一步推动了中文预训练模型的研发。
最后回归到模型效率,根据以往研究预训练模型加速方法主要为知识蒸馏和模型压缩,然而它们对于现实世界的应用程序并不是最佳的方案。知识蒸馏方法在大规模教师模型的指导下训练一个学生模型,这需要两个阶段的训练,而教师模型的训练仍然消耗大量的计算资源。同样,模型压缩的目的是训练一个简单的和优化的模型,而不显著降低精度,其广泛使用的技术包括参数共享、模块替换、剪枝和量化。这样的方法线仍然需要大量的培训。此外,这些方法在模型架构上发生了巨大的变化,因此很难在现实世界中轻松实现,与transformers工具包等通常部署的框架不兼容。(看来本文作者在实现上对抱抱脸兼容上花了心思)。
本文的目标不是追求更大的模型规模,而是轻量级但更强大,同时对部署和工业落地更友好的模型。基于语言学信息融入和训练加速等方法,研发了 Mengzi 系列模型。由于与 BERT 保持一致的模型结构,Mengzi 模型可以快速替换现有的预训练模型。这项工作的主要贡献有三个方面:
- 1)研究了各种预训练策略来训练轻量级语言模型,表明精心设计良好的目标可以进一步显著提高模型的容量,而不需要扩大模型的大小。
- 2发布了Mengzi模型,包括判别式、生成式、金融和多模态模型变体,能够胜任广泛的语言和视觉任务。这些模型中的文本编码器只包含1.03亿个参数,我们希望这能够促进学术界和工业界的相关研究。
- 3)通过大量基准任务测试表明,孟子模型在一系列语言理解和生成任务上取得了很强的性能。
文本编码器

如图所示Mengzi模型家族包括:
- Mengzi-BERT-base
- Mengzi-BERT-base-fin
- Mengzi-T5-base
- Mengzi-Oscar-base
从应用场景的角度来看,它们的范围从纯文本语言模型到多模态变体,从通用训练到特定领域的适应。具体特点如下:

从技术角度来看,后三个可以看作是Mengzi-BERT-base的衍生,因为它们的文本编码器遵循与Mengzi-BERT-base相同的结构,并由Mengzi-BERT-base的预训练参数初始化。因此,在下面的实验部分中,文章只关注基本的仅文本编码器方面,以及相关有效的优化技术。
模型设置
- 数据预处理:训练前的语料库来源于中文维基百科、中文新闻和爬虫语料,总数据大小为300GB。通过使用探索性的数据分析技术来清理数据,删除HTML标签、url、电子邮件、表情符号等。由于在原始语料库中有简体标记和传统的中文标记,使用OpenCC将传统标记转换为简体形式,重复的文章也会被删除。
- 模型结构:RoBERTa被选做为 Mengzi预训练的骨干模型,12层transformers,hidden size为768,12个attention heads,预训练任务为MLM。
- 预训练细节:(1)词汇表包含21,128个字符,看了下与Bert大小保持一致。句子长度限制在512个字符,batch size为128。(2)在训练前,每个序列中有15%的单词被随机屏蔽以进行MLM预测。(3)使用LAMB优化器的mixed-batch训练方式,它涉及两个阶段:总epoch的前9/10使用序列长度为128,总epoch的最后1/10使用序列长度为512。这两个阶段的批次规模分别为16384和32768。采用PostgreSQL对训练示例进行全局抽样,以避免两阶段训练中样本权重的不平衡。整个培训前的过程需要100万步。使用32个3090 24G,使用FP16和深度4进行训练加速(只能说土豪)。
模型实验
对于模型评价的下游任务,文本使用中文语言理解评价(CLUE)基准,包括六种不同的自然语言理解任务:蚂蚁金融问题匹配(AFQMC)、新闻标题文本分类(TNEWS)、中文文本(CO,2019)、中文翻译多基因自然语言推理(CMNLI)、中文机器智能测试(WSC)、中文科学文献(CSL)和三个机器阅读理解(MRC)任务:中国机器阅读理解(CMRC)、中文语言完形填空(CHID)和中文多项选择阅读理解(C3)。
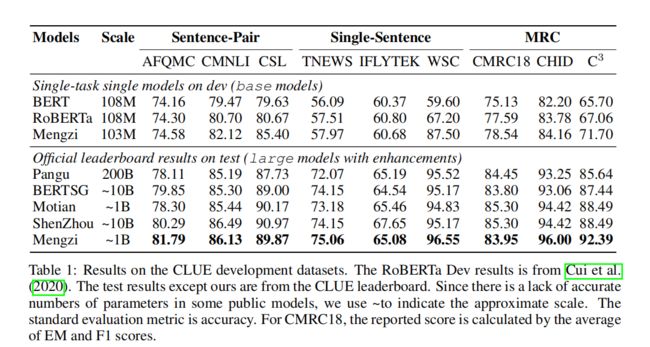
从上表可以看出Mengzi模型相比其他中文预训练模型取了性能提升。
微调细节
在微调实验中,论文使用Adam作为优化器,初始学习率为{8e-6、1e-5、2e-5、3e-5},预热率为0.1,L2权重衰减为0.01。批处理大小将在{16、24、32}中进行选择。根据任务,最大epochs在[2,5]中设置。对于文本最大长度:MRC的最大长度为384,其他任务为256。
PLM进阶
文本进一步研究了预训练和微调技术,来进一步提高Menzi模型的能力。
预训练技术
-
Linguistic-motivated Objectives:语义信息已被证明对语言建模是有效的。受LIMIT-Bert的启发,在训练前使用了词性(POS)和命名实体(NE)序列标记任务,并结合了原始的MLM和NSP目标。原始文本中的POS和NE标签由spaCy标注。
-
Sequence Relationship Objectives:为了更好地对句子间的句子对信息进行建模,Mengzi在模型预训练中添加了句子顺序预测(SOP)任务。
-
Dynamic Gradient Correction:广泛使用的MLM会引起原始句子结构的干扰,导致语义丢失,增加了模型预测的难度,不可避免地导致训练不足和效率低下。为了缓解这一问题,本文提出了一系列的动态梯度校正技术来提高模型的性能和鲁棒性。
微调策略
-
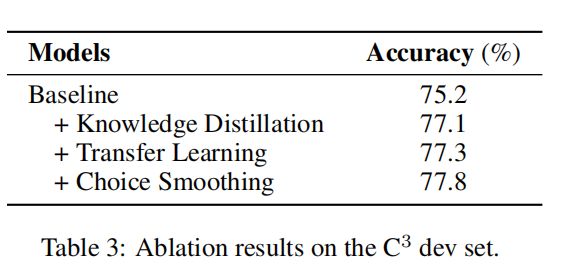
Knowledge Distillation:文本训练了一个教师模型,并采用教师模型来指导学生模型的训练。详细地,分别计算了相同输入序列的上下文隐藏状态的Kullback-leibler(KL)散度。差异度量了教师和学生模型的表示之间的相似度,在微调过程中与原始下游任务目标一起最小化。

-
Transfer Learning:不同任务的迁移学习,比如利用CMNLI数据集上训练模型的参数来初始化C3等相关数据集的模型训练
-
Choice Smoothing:对于多项选择或分类任务,结合不同类型的训练目标会带来更好的表现。对于每个输入示例,我们应用交叉熵和二进制交叉熵作为损失函数,并结合双方的损失,帮助模型从不同的粒度学习特征。
-
Adversarial Training:应用了一种由平滑诱导的对抗性正则化技术:SMART,以支持当向输入注入一个小的扰动时,模型的输出没有太大的变化。
-
数据增强
实战任务
# 使用 Huggingface transformers 加载
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("Langboat/mengzi-bert-base")
model = BertModel.from_pretrained("Langboat/mengzi-bert-base")
营销文案生成
图2比较了基于Monno-T5基础模型和GPT生成的营销文案文本的质量。给定输入的标题和关键字,模型需要生成相应的描述性段落。根据生成的例子,可以观察到monno-t5基础模型生成的文本包含更多的细节,同时保持流畅性,这表明使用Mengzi模型生成文本将受益于令人满意的多样性流畅性和连贯性。

金融任务
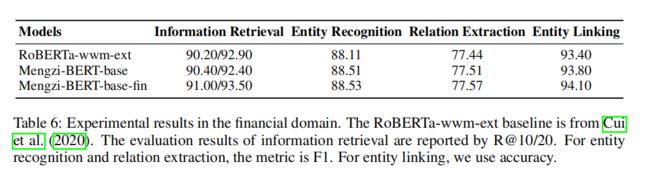
论文在信息检索、实体识别和实体链接等金融任务中进行了评估,如信息检索、实体识别、关系提取和实体链接。从LUGE中提取实体(例如,事件),用于实体识别任务。对于对其他任务的评估,使用自收集的数据集。表6的结果表明,本文的方法能够完成特定于金融领域的任务,特别是Mengzi-BERT-base-fin产生了最好的性能。
图像描述
论文比较了Mengzi-Oscar-base的图像标题性能和广泛使用的自动自动文本技术。图3显示了基于AIC-ICCVal集中随机选择的例子的案例研究。可以观察到,与基线相比,我们的模型生成了更流畅和信息更丰富的字幕

总结
基于以下算法策略,实现从语料中高效学习涵盖词级、句子级和语篇级知识,大幅提升语言模型提炼语言结构和语义信息能力,以及良好的领域迁移能力,适应广泛的产品应用场景。

同时关于微调方面,从数据增强、知识蒸馏、迁移训练、训练优化等方面展开了一些探索,进一步提升语言模型的性能:
- 数据增强:使用领域相关数据;
- 知识蒸馏:基于Teacher-Student自蒸馏提升训练效率;
- 迁移训练:结合课程学习的思想,由易到难训练下游模型;
- 训练优化:使用多种训练目标,多角度提升模型能力;