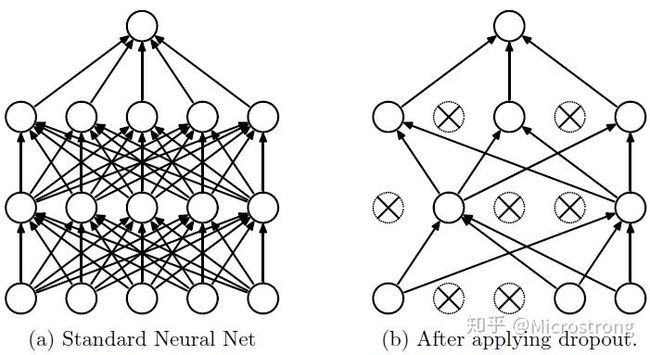
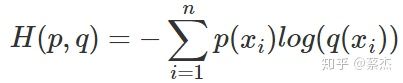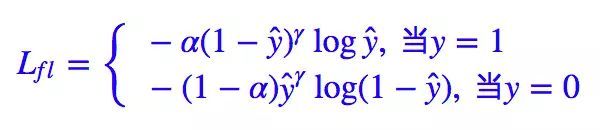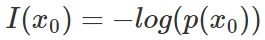| 基础知识点 |
记忆点 |
备注 |
| 图像基础知识 |
数字图像 |
数字图像又称数码图像或者数位图像,是二维图像用有限数字数值像素的表示,由数组或者矩阵表示。数字图像可以理解为一个二维函数f(x, y),其中x,y是空间的坐标,而任意位置的幅值f称为图像在该点的强度或者灰度。 |
| 常见的电磁波成像特点 (按照频率从高到低) |
- γ射线成像:波长最短,频率最高,是由原子核内发射出来的电磁波。放射性物质或者原子核反应中常有这种辐射。γ射线穿透力强,对生物破坏性大。
- x射线成像:CT就是用x射线照射物体。由于生物组织或者工程组件的不同部位对x射线的吸收率不同,从而得到不同的衰减以成像(密度越高,吸收的越多)。
- 紫外线成像:具备化学效应和荧光效应,常用于生物医学。
- 可见光波段成像
- 红外线成像:一切物体都可以辐射出红外线,可利用探测仪测量目标本身与背景间的红外线差得到红外图像。
- 微波成像:用于雷达以及生成地表情报图。
- 射频成像:电视、无线电、手机的波段。也可以用于医学,比如磁共振。
|
| 常见的图像格式 |
 |
| 读取图像 |
# cv2读取 & 直接呈现
img = cv2.imread("../test.jpg", flags=1)
print(img.shape)
cv2.imshow("test.jpg", img)
key = cv2.waitKey(0)
if key == ord('q'):
cv2.destroyAllWindows()
elif key == ord('s'):
cv2.imwrite("test_bak.jpg", img)
# cv2读取后需转换为RGB,再由matplotlib呈现
img = cv2.imread("../test.jpg", flags=1)
print(img.shape)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print(img.shape)
plt.figure(figsize=(12, 6))
plt.imshow(img)
plt.show()
# PIL 读取
img = Image.open("../test.jpg")
print(img)
print(np.asarray(img).shape)
# matlpotlib读取
img = plt.imread("../test.jpg")
print(img.shape)
- flags=0代表灰度图,flages=1代表彩图,默认是三通道彩图。
- cv2.imread()、PIL.Image.open()、matplotlib.imread()读取的默认shape都是【H,W,C】,与pytorch的默认顺序不同,需要转换为【C, H, W】。
- opencv读取是默认的BGR,直接用opencv呈现是没问题的。但是后面处理或者用matplotlib呈现就需要转换为RGB。
- 灰度 = B * 0.114 + G * 0.587 + R * 0.299
|
| 图像直方图 |
图像直方图是以表示数字图像中亮度分布的直方图,表达了图像亮度的整体分布。常用来二值化。 img = cv2.imread("../test.jpg", flags=1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hist = cv2.calcHist(img, channels=[0], mask=None, histSize=[256], ranges=[0, 256])
plt.figure(figsize=(12, 6))
plt.plot(hist)
plt.xlabel("bins")
plt.ylabel("num of pixels")
plt.title("histgram of grayscale")
plt.show()

|
| 颜色空间 |
- RGB:依据人眼的颜色空间。有RGB三通道,范围都是0-255。
- HSV:H(色调),代表色彩;S(饱和度),取值是0-100%,值越大,颜色越饱和;V(明度),从0%(黑)到100%(白)。
- HSI:H(色调),S(饱和度),I(强度)。
- CMYK:C(青)、M(品红)、Y(黄),常用于印刷行业。
opencv中颜色空间的改变也是cv2.cvtcolor() |
| 图像基础处理 |
opencv绘图 |
# 1,绘制线段
if show_control == 1:
img = np.zeros((512, 512, 3))
cv2.imshow("origin photo", img)
cv2.waitKey(2000)
cv2.line(img, (0, 0), (250, 250), color=(0, 0, 255), thickness=1)
cv2.imshow("photo with a line", img)
cv2.waitKey(2000)
cv2.destroyAllWindows()
#2. 绘制矩形 需要左上角 右下角的坐标
if show_control == 2:
img = cv2.imread("../test.jpg", flags=1)
cv2.rectangle(img, (251, 402), (373, 464), color=(0, 0, 255), thickness=2)
cv2.putText(img, "bobbies", (253, 400), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(25, 0, 0), thickness=2)
cv2.imshow("rectangle photo", img)
cv2.waitKey(2000)
cv2.destroyAllWindows()
#3. 绘制圆形 需要圆心和半径
if show_control == 3:
img = np.zeros((512, 512, 3))
cv2.circle(img, (100,100), 20, color=(0, 0, 255))
cv2.imshow("circle", img)
cv2.waitKey(2000)
cv2.destroyAllWindows()
|
| 图像平移 |
img = cv2.imread("../test.jpg")
# x方向移动多少, y方向移动多少
H = np.float32([[1, 0, 50], [0, 1, 25]])
rows, cols = img.shape[: 2]
# 注意这里rows和cols需要反置,先列后行
res = cv2.warpAffine(img, M=H, dsize=(cols, rows))
cv2.imshow("origin pic", img)
cv2.imshow("affine pic", res)
cv2.waitKey(0)
|
| 图像缩放 |

常见的插值方法:
- 最近邻插值:效果不好,放大后有严重的马赛克,缩小后的图像有严重的失真。


|
| 图像旋转 |
# 旋转
if control == 2:
img = cv2.imread("../test.jpg")
h, w = img.shape[:2]
# scale >0 逆时针旋转 scale<0 顺时针旋转 angle旋转角度
H = cv2.getRotationMatrix2D(center=(h/2, w/2), angle=45, scale=0.5)
res = cv2.warpAffine(img, M=H, dsize=(w, h))
cv2.imshow("rotation", res)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
| 仿射变换 |
if control == 3:
img = cv2.imread("../test.jpg")
h, w = img.shape[:2]
# 用三个点来确定仿射变换
pos1 = np.float32([[50, 50], [200, 50], [50, 200]])
pos2 = np.float32([[10, 100], [200, 50], [100, 250]])
H = cv2.getAffineTransform(pos1, pos2)
res = cv2.warpAffine(img, M=H, dsize=(w, h))
cv2.imshow("affine", res)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
| 透视变换 |
img = cv2.imread("../test.jpg")
h, w = img.shape[:2]
pos1 = np.float32([[114, 82],[287, 156], [8, 100], [143, 177]])
pos2 = np.float32([[0, 0], [188, 0], [0, 262], [188, 262]])
H = cv2.getPerspectiveTransform(pos1, pos2)
#图像透视变换
result = cv2.warpPerspective(img, H, dsize=(w, h))
cv2.imshow("origin pic", img)
cv2.imshow("warp pic", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
| 图像滤波操作 |
滤波基本原理 |
- 基本原理:图像可以看作是二维的信号,像素点的灰度值代表着信号的强弱。图像中变化强烈的部分称为高频部分,图像中变化缓慢的部分称为低频部分。可以根据图像的高低频,设置高通或者低通滤波器。高通可以检测变化尖锐明显的部分,低通可以让图像变得平滑,消除噪声。高通滤波器常用于边缘检测,低通滤波器常用于图像平滑去噪。
|
| 方框滤波 |
img = cv2.imread("../test.jpg", flags=1)
# 不加normalize会使得很多pixel超过255 导致全图变白
filter = cv2.boxFilter(img, ddepth=-1, ksize=(3, 3), normalize=True)
cv2.imshow("original", img)
cv2.imshow("box filter", filter)
cv2.waitKey(0)
cv2.destroyAllWindows()
kernel内元素全部是1。 注意进行normalize,否则图像会因为超过255,变白,另外kernel越大,模糊的效果越明显。 |
| 均值滤波(平均模糊) |
if control == 2:
img = cv2.imread("../test.jpg", flags=1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.blur(img, ksize=(3, 3))
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(blur)
plt.show()
kernel内元素全部是1。 等同于加了normalize的方框滤波。 |
| 高斯滤波 |
if control == 3:
img = cv2.imread("../cat.jpg", flags=1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.GaussianBlur(img, ksize=(3, 3), sigmaX=0)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(blur)
plt.show()
高斯滤波卷积核内参数并不相同,而是呈现高斯分布的,中间高,两边低。高斯滤波可有效去除高斯噪声,保留更多的图像细节。 |
| 中值滤波 |
中值滤波是一种非线性滤波,是用像素点邻域灰度的中值代替该点的灰度值。,中值滤波可以取出椒盐噪声和斑点噪声。 if control == 4:
img = cv2.imread("../luna.jpg", flags=1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.medianBlur(img, ksize=3)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(blur)
plt.show()
|
| 双边滤波 |
双边滤波是一种非线性滤波,是结合像素的空间邻近度和像素值相似度的一种折中处理。同时考虑空间信息和灰度的相似性,达到保边去噪的目的。具有简单、非迭代、局部处理的特点。双边滤波可以有效保证边缘信息。 # 双边滤波
if control == 5:
img = cv2.imread("../luna.jpg", flags=1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.bilateralFilter(img, d=-1, sigmaColor=15, sigmaSpace=10)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(blur)
plt.show()
|
| 图像增强 |
灰度直方图均匀化 |
直方图均匀化就是将原图像经过某种变化,得到一副灰度直方图均匀的图像。直方图均匀化的思想就是对图像中像素个数较多的灰度级进行展宽,从而对像素较少的灰度级进行缩减。从而达到清晰图像的目的。工业上常用来解决过曝的情况。 img = cv2.imread("../dark_girl.jpg",flags=0)
print(img.shape)
img_equal = cv2.equalizeHist(img)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.title("origin")
plt.imshow(img)
plt.subplot(122)
plt.title("equalize")
plt.imshow(img_equal)
plt.show()
|
| 彩色直方图均匀化 |
if control == 2:
img = cv2.imread("../dark_girl.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
r, g, b = cv2.split(img)
equal_r = cv2.equalizeHist(r)
equal_g = cv2.equalizeHist(g)
equal_b = cv2.equalizeHist(b)
img_equal = cv2.merge((equal_r, equal_g, equal_b))
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.title("origin")
plt.imshow(img)
plt.subplot(122)
plt.title("equalize")
plt.imshow(img_equal)
plt.show()
|
| Gamma变化 |
Gamma变化是对输入图像灰度值进行的非线性操作。使输出图像的灰度值和输入图像的灰度值呈现指数的关系。 Gamma变化用来进行图像增强,让图像从曝光强度的线性响应变得更接近人眼感受的响应。既对相机曝光或者光照不足的情况进行调节。 img = cv2.imread("../guobao.jpg")
def adjust_gamma(image, gamma=1.0):
invGamma = 1.0 / gamma
table = []
for i in range(256):
table.append(((i / 255) ** invGamma) * 255)
table = np.array(table).astype("uint8")
return cv2.LUT(image, table)
def equalize(img):
b, g, r = cv2.split(img)
equal_r = cv2.equalizeHist(r)
equal_g = cv2.equalizeHist(g)
equal_b = cv2.equalizeHist(b)
img_equal = cv2.merge((equal_b, equal_g, equal_r))
return img_equal
img_gamma = adjust_gamma(image=img, gamma=0.35)
img_equalize = equalize(img=img)
cv2.imshow("original", img)
cv2.imshow("gamma", img_gamma)
cv2.imshow("equalize", img_equalize)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
| 形态学操作 |
什么是形态学? |
形态学是最为常见的图像技术,主要从图像中提取对表达和描绘区域形状有意义的图像分量,使后续的识别工作能够抓住目标对象最为本质的形状特征,如边界和连通区域。 |
| 腐蚀 |
针对图像的白色部分,膨胀进行扩张,白色区域变大,腐蚀进行收缩,白色区域变小。 腐蚀:用模板B来腐蚀A就是用B来逐步卷积A,模板B有一个锚点和锚框,如果锚点落在前景内,且锚框都落在前景内,则保留锚点像素。如果锚点落在前景内,锚框没有完全包含在前景内,则去除锚点像素改为背景。 
img = cv2.imread("../erode.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_erode = cv2.erode(img, kernel=(3, 3))
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
|
| 膨胀 |
腐蚀的对偶运算。 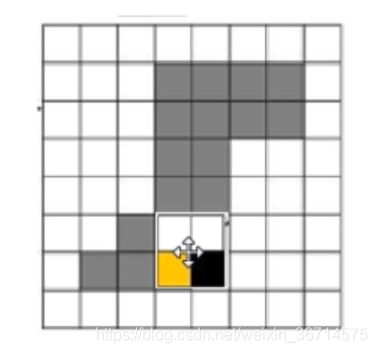
同样使用模板B来卷积A,模板内包含锚点和锚框。如果锚框和前景有交集,如果此时锚点对应着背景,那么就把背景膨胀为前景。 |
| 开运算 |
先腐蚀后膨胀,把细微连在一起的物体分开,把物体的表面进行平滑。 换句话说开运算能够去除孤立的小点,毛刺和小桥,但总的位置和形状不变。 if control == 3:
img = cv2.imread("../mor-open.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(5, 5))
img_erode = cv2.morphologyEx(img, op=cv2.MORPH_OPEN, kernel=kernel, iterations=1)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
|
| 闭运算 |
先膨胀运算再腐蚀运算。 闭运算能够将两个细微连接的图封闭到一起,可以去除孔洞和弥补小裂缝,并且保持整体的位置形状不变。 if control == 4:
img = cv2.imread("../mor-close.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(7, 7))
img_erode = cv2.morphologyEx(img, op=cv2.MORPH_CLOSE, kernel=kernel, iterations=3)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
|
| 形态学梯度 |
 |
| 顶帽和黑帽 |
- 顶帽:原图像与开运算的插值,突出原图像中比周围亮的区域。
- 黑帽:闭运算与原图像差值,突出原图像比周围暗的区域。
# 形态学梯度 膨胀-腐蚀
if control == 5:
img = cv2.imread("../haizei.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(7, 7))
img_erode = cv2.morphologyEx(img, op=cv2.MORPH_GRADIENT, kernel=kernel, iterations=1)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
# 顶帽 原图-开运算 突出原图中亮的地方
if control == 6:
img = cv2.imread("../haizei.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(9, 9))
img_erode = cv2.morphologyEx(img, op=cv2.MORPH_TOPHAT, kernel=kernel, iterations=2)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
# 黑帽 闭运算-原图 突出原图中暗的地方
if control == 7:
img = cv2.imread("../haizei.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(9, 9))
img_erode = cv2.morphologyEx(img, op=cv2.MORPH_BLACKHAT, kernel=kernel, iterations=3)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(img_erode)
plt.show()
|
| 图像分割 |
分割原则 |
分割的原则就是使划分后的子图在内部保持相似度最大,而子图之间的相似度保持最小。 |
| 固定阈值分割 |

if control == 1:
img = cv2.imread("../2bin.jpg", flags=0)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 大于thresh 置为maxval; 小于thresh,置为0
ret1, th1 = cv2.threshold(img, thresh=100, maxval=255, type=cv2.THRESH_BINARY)
# 小于thresh 置为maxval; 大于thresh,置为0
ret2, th2 = cv2.threshold(img, thresh=127, maxval=255, type=cv2.THRESH_BINARY_INV)
# 大于thresh 置为thresh, 小于thresh,不处理
ret3, th3 = cv2.threshold(img, thresh=127, maxval=255, type=cv2.THRESH_TRUNC)
# 大于thresh 不做处理, 小于thresh,置为0
ret4, th4 = cv2.threshold(img, thresh=127, maxval=255, type=cv2.THRESH_TOZERO)
ret5, th5 = cv2.threshold(img, thresh=127, maxval=255, type=cv2.THRESH_TOZERO_INV)
ths = [img, th1, th2, th3, th4, th5]
plt.figure(figsize=(12, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
plt.imshow(ths[i])
plt.show()
|
| 自适应阈值分割 |
自适应阈值法会每次取出图像的一小部分计算阈值,这样不同区域的阈值就不尽相同,适用于明暗分布不均的图片。 # 自适应阈值分割
if control == 2:
img = cv2.imread("../black_white.jpg", flags=0)
print(img.shape)
# 分成blockSize的小区域,其中使用均值来计算阈值
th1 = cv2.adaptiveThreshold(
img, maxValue=255, adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C,
thresholdType=cv2.THRESH_BINARY, blockSize=11, C=4)
# 分成blockSize的小区域,其中使用高斯加权来计算阈值
th2 = cv2.adaptiveThreshold(
img, maxValue=255, adaptiveMethod=cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
thresholdType=cv2.THRESH_BINARY, blockSize=17, C=6)
ths = [img, th1, th2]
plt.figure(figsize=(12, 6))
for i in range(3):
plt.subplot(1, 3, i+1)
plt.imshow(ths[i], cmap=plt.get_cmap("gray"))
plt.show()
|
| 迭代法阈值分割 |
- 求出图像的最大灰度和最小灰度值,分别记为Zmax和Zmin,令初始阈值T0 = 1/2(Zmax + Zmin)。
- 根据阈值Tk,将图像分为前景和背景,分别求出两者的平均灰度值ZO和ZB。
- 求出新阈值Tk+1 = 1/2(ZO + ZB)。
- 若TK = TK + 1,则得到最终阈值,否则继续迭代2。
- 使用最后的阈值。
|
| 大津阈值分割法 |

# 大津法阈值分割
if control == 3:
img = cv2.imread("../dark_girl.jpg", flags=0)
print(type(img))
# 阈值法
_, th1 = cv2.threshold(img, 100, maxval=255, type=cv2.THRESH_BINARY)
# 大津法
_, th2 = cv2.threshold(img, 0, maxval=255, type=cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 高斯滤波 + 大津法(常用套路)
blur = cv2.GaussianBlur(img, ksize=(7, 7), sigmaX=0)
_, th3 = cv2.threshold(blur, 0, maxval=255, type=cv2.THRESH_BINARY + cv2.THRESH_OTSU)
plt.figure(figsize=(12, 6))
plt.subplot(221)
plt.title("origin")
plt.imshow(img, cmap=plt.get_cmap("gray"))
plt.subplot(222)
plt.title("thresh")
plt.imshow(th1, cmap=plt.get_cmap("gray"))
plt.subplot(223)
plt.title("otsu")
plt.imshow(th2, cmap=plt.get_cmap("gray"))
plt.subplot(224)
plt.title("gussian + otsu")
plt.imshow(th3, cmap=plt.get_cmap("gray"))
plt.show()
|
| 边缘检测 |
- 梯度:梯度是一个向量,梯度方向指向函数变化最快的方向,梯度的大小是最大的变化率。
- 边缘:边缘就是梯度变化很快的点的集合。
- 梯度算子:梯度算子是一阶导数的算子,是水平梯度模板和竖直梯度模板的组合,也有对角线的方向。
- 常见的梯度算子:

优点:边缘定位较为准确,适用于边缘明显且噪声少的图像。 缺点:没有描述水平和竖直方向的灰度变化,只关注了对角线方向,容易造成边缘的遗漏;鲁棒性差,因为点本身参与梯度的计算,不能有效抑制噪声的干扰。


Prewitt算子引入了类似局部平均的运算,对噪声更有平滑作用,可以抑制噪声。


|
|


if control == 2:
img = cv2.imread("../road.png", 0)
img_mask = cv2.imread("../road_mask.png", 0)
img_mask = 1 - img_mask
#print(img_mask)
v1 = cv2.Canny(img, threshold1=60, threshold2=150, edges=(5, 5))
v1_ = v1 * img_mask
v2 = cv2.Canny(img, threshold1=50, threshold2=100, edges=(5, 5))
v2_ = v2 * img_mask
v_mask = cv2.Canny(img_mask, threshold1=0, threshold2=1, edges=(3, 3))
plt.figure(figsize=(9, 18))
plt.subplot(321)
plt.title("origin")
plt.imshow(img, cmap=plt.get_cmap("gray"))
plt.subplot(322)
plt.title("mask")
plt.imshow(img_mask, cmap=plt.get_cmap("gray"))
plt.subplot(323)
plt.title("v1")
plt.imshow(v1, cmap=plt.get_cmap("gray"))
plt.subplot(324)
plt.title("v2")
plt.imshow(v2, cmap=plt.get_cmap("gray"))
plt.subplot(325)
plt.title("v1_")
plt.imshow(v1_, cmap=plt.get_cmap("gray"))
plt.subplot(326)
plt.title("v_mask")
plt.imshow(v_mask, cmap=plt.get_cmap("gray"))
plt.show()
|
| 连通区域 |
连通区域:一般指图像中具有相同像素值且位置相邻的前景像素点组成的图像区域。连通区域分析是将图像中各自联通区域找到并且标记。 Two-pass算法: 

|
| 区域生长 |
区域生长:是一种串行区域分割的方法。从某个像素出发,按照一定的准则,逐步加入邻近像素。当满足一定的条件的时候,区域停止生长。 
|
| 分水岭算法 |
原理:任意的灰度图像。高亮度的是山峰,低亮度的是山谷。 |