YOLOv5 实践之PCB缺陷检测
前言
YOLO模型思想简述:YOLO (You Only Look Once) 是属于目标检测中的one-stage方法,主要的思想是通过将原始的图像划分为 p p p × \times × p p p 大小的网格grid,每个网格假设为目标的中心,后面再通过偏置回归进行学习调整。每个目标中心设定有2(YOLOv1)或9个(YOLOv2后)一定长宽比例的先验框根据中心位置对目标进行整体的定位。最后输出的特征一般大小为 p p p × \times × p p p,深度信息(channels)包含了对目标的回归坐标 (w, h, x, y)、预测类别和置信度 (confident)
(例如:在coco数据集中输出预测的9个比例的回归框的情况下,每个grid输出的特征数为:80 + (4 + 1) × \times × 9 = 125个)。
本博文主要使用YOLOv5算法对PCB版上的缺陷进行检测。
1 环境配置
首先使用git clone的方式或者直接访问网址下载项目文件夹的方式对项目文件进行下载解,YOLOv5项目对应网址如下:
git clone https://github.com/ultralytics/yolov5.git
然后在yolov5-master文件夹下,运行配置环境命令:
cd yolov5-master
pip install -r requirements.txt # pip方式安装(任选其一)
conda install --yes --file requirements.txt # conda方式安装(任选其一)
如果没有安装必要的包,在后面训练的时候会报错并提示。
2 数据集(根据VOC数据集格式)设置
假设在根目录的abc文件夹(/abc/)下配置以下文件目录:
|--datasets
|--PCBDatasets
| |--Annotations(数据集所有的xml格式标签)
| | --xxx.xml
| | ......
| |--images(数据集所有的jpg格式图像)
| | --xxx.jpg
| | ......
| |--ImageSets
| | |--Main
| | |--trian.txt
| | |--trianval.txt
| | |--val.txt
| | |--test.txt
| |--labels(数据集所有由xml转换为yolo格式的标签文件,需生成)
| | --xxx.txt
| | ......
| |--trian.txt(含训练集样本路径,需生成)
| |--val.txt(含验证集样本路径,需生成)
| |--test.txt(含测试集样本路径,需生成)
|
|--yolov5-master
数据集文件目录图如下:
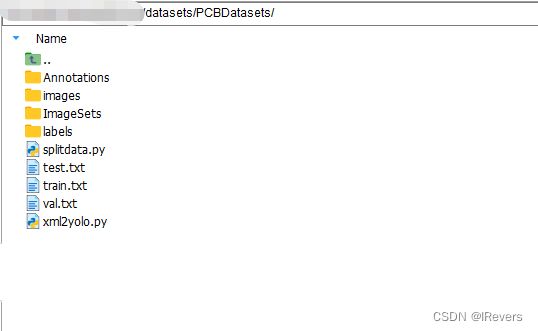
在该文件夹下,需先运行xml2yolo.py将xml格式的标签文件转换为在labels路径下的yolo格式的标签文件,然后,运行split_data.py划分数据集,生成对应训练集、验证集和测试集对应的路径txt文件,至此,数据集的制作过程完毕,接下来对项目的文件进行配置。
xml2yolo.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ["train", "val", "test"]
classes = ["open", "short", "mousebite", "spur", "copper", "pin-hole"]
# normalize
def convert(size, box):
# size: (w, h), box: (xmin, xmax, ymin, ymax)
dw = 1. / size[0] # 1/w
dh = 1. / size[1] # 1/h
x = (box[0] + box[1]) / 2.0 # 获取物体在图中心点的x坐标
y = (box[2] + box[3]) / 2.0 # 获取物体在图中心点的y坐标
w = box[1] - box[0] # 获取物体实际像素的宽度
h = box[3] - box[2] # 获取物体实际像素的高度
x = x * dw # 获取物体中心点x的坐标比(x / w)
w = w * dw # 获取物体宽度的宽度比(w / w)
y = y * dh # 获取物体中心点y的坐标比(y / h)
h = h * dh # 获取物体高度的高度比(h / h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
def convert_annotation(img_id):
"""
将xml文件转换为对应的yolo文件格式 对xml文件进行解析和归一化操作 保存到yolo格式的txt文件
文件格式: class x y w h 一个图像可能对应多个类别 一张图像的bounding框至少有一个
"""
in_file = open("./Annotations/%s.xml" % img_id, encoding="utf-8")
out_file = open("./labels/%s.txt" % img_id, "w", encoding="utf-8")
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获取图片的尺寸大小
size = root.find("size")
# 如果xml内的标记为空 增加判断条件
if size != None:
# get width
w = int(size.find("width").text)
# get height
h = int(size.find("height").text)
# 遍历object
for obj in root.iter("object"):
difficult = obj.find("difficult").text
cls = obj.find("name").text
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id string -> index
cls_id = classes.index(cls)
# 找到bndbox对象
xmlbox = obj.find("bndbox")
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find("xmin").text), float(xmlbox.find("xmax").text),
float(xmlbox.find("ymin").text), float(xmlbox.find("ymax").text))
print(img_id, cls, b)
# 带入进行归一化操作
# w = width, h = heighr, b = bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x, y, w, h)
# 生成 cls x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + "\n")
# 返回当前工作目录
wd = getcwd()
print(wd)
# 对所有文件数据进行遍历 将全路径写入到对应的txt文件中
# 对所有的图片文件进行解析和转化 将其对应的boundingbox和类别信息全都写入label文件夹下
for img_set in sets:
if not os.path.exists("./labels/"):
os.makedirs("./labels/")
# 读取imageSets/Main中trian, test 等文件内容 包含对应文件名称
img_ids = open("./ImageSets/Main/%s.txt" % img_set).read().strip().split()
list_file = open("./%s.txt" % img_set, "w")
# 写入文件对应的id以及全路径+换行
for img_id in img_ids:
list_file.write(wd + "/images/%s.jpg\n"% img_id)
convert_annotation(img_id)
list_file.close()
split_data.py
import os
import random
ROOT = "/abc/datasets/PCBDatasets/data/image/" # 注意要改
trainval_percent = 0.9
train_percent = 0.9
xml_filepath = "./Annotations/"
total_xml = os.listdir(xml_filepath)
num = len(total_xml)
lis = range(num)
tv_num = int(num * trainval_percent)
tr_num = int(tv_num * train_percent)
trainval = random.sample(lis, tv_num)
train = random.sample(trainval, tr_num)
root = "./ImageSets/Main/"
ftrainval = open(root + "trainval.txt", "w")
ftest = open(root + "test.txt", "w")
ftrain = open(root + "train.txt", "w")
fval = open(root + "val.txt", "w")
for i in lis:
name = total_xml[i][:-4] + "\n"
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
3 训练PCB数据集
在/Evern/yolov5-master/data/文件夹下添加PCB数据集对应的yaml文件,这里取名为PCBDetect.yaml,文件中包含内容如下:
train: /abc/datasets/PCBDatasets/train.txt
val: /abc/datasets/PCBDatasets/val.txt
test: /abc/datasets/PCBDatasets/test.txt
nc: 6
names: ['copper', 'mousebite', 'open', 'pin-hole', 'short', 'spur']
修改模型对应的yaml文件,文件路径为:/abc/yolov5-master/models/yolov5x.yaml,在这个文件中主要修改nc这个值,改为任务对应的类别数量。
# Parameters
nc: 6 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
运行代码:
python train.py --data PCBDetect.yaml --weights "yolov5x.pt" --cfg yolov5x.yaml --img 640 --epochs 300
如果需要下载对应的权重,可以在以下几个链接中下载对应的权重文件:
yolov5n: https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5n.pt
yolov5s: https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
yolov5m: https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5m.pt
yolov5l: https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5l.pt
yolov5x: https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5x.pt
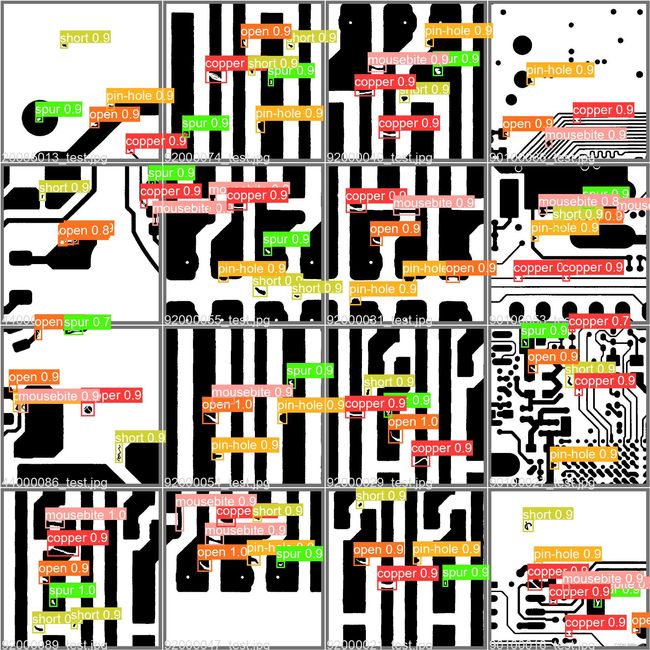
4 测试
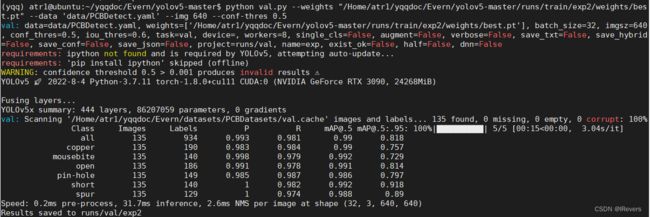
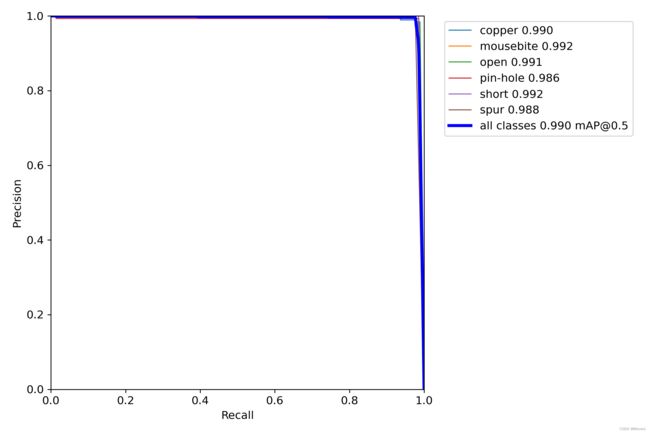
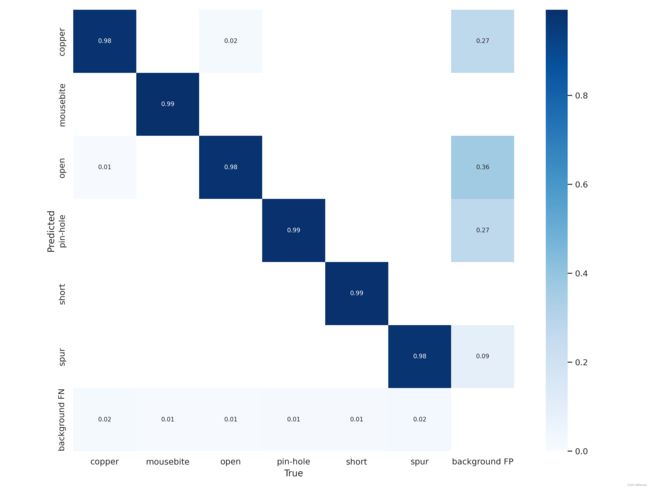
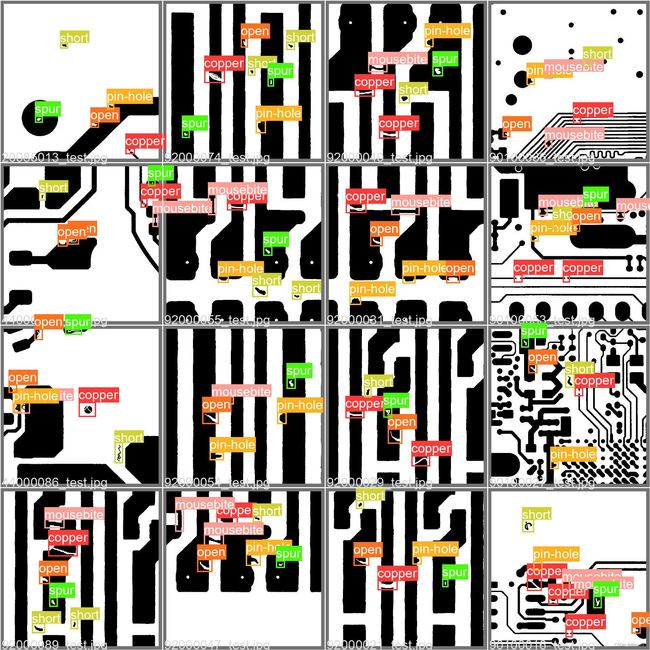
测试结果展示
在YOLOv5x上测试的结果如下: