深度学习:循环神经网络(RNN)
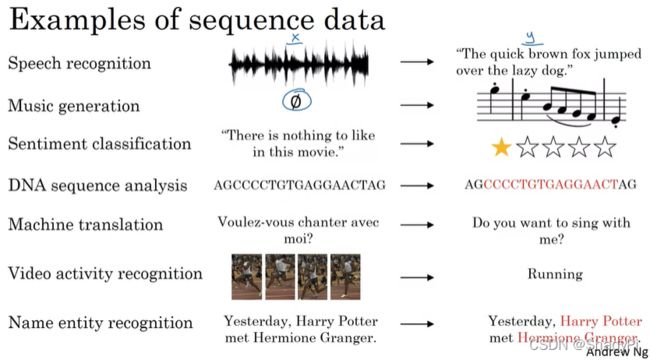
循环神经网络主要用于呈序列形式的数据,如文字、音频,可以实现语音识别、自然语言处理、动作识别等功能。
文章目录
- 符号约定
- 建立RNN模型
-
- 向前传播
- 向后传播
- 更多RNN模型
-
- 多对多
- 多对一
- 一对多
- 不等长多对多
- 语言模型
-
- 文本训练
- 文本生成
- 门控循环单元(Gated Recurrent Unit)
- 长短期记忆(Long Short Term Memory)
- 双向循环神经网络(Bidirectional RNN)
- 深度RNN
符号约定
因为数据都是序列形式,所以输入输出我们用尖括号上标表示其在序列中的位置, x < t > x^{

在自然语言处理(NLP)问题中,我们还经常用到一个词汇表,其中是可能用到的词汇,通常按字典序排列,规模在一万至几十万不等。通过该词典,我们可以将序列中的每个数据表示成一位热键(one-hot),每个单词都被一个列向量表示,这个向量中只有单词在词典中对应的索引为1,其余元素均为0。
当遇到不在词典中的词,则打一个未知标记。
建立RNN模型
以文本中的人名识别问题为例,一个朴素的神经网络可能是输入层的每个节点都输入一个序列中的词汇,而输出层每个节点输出0或1表示该位置的单词是否是人名。这就会有两个问题,其一是文本的长度变化很大,输入输出的节点很可能不够用或者多余;其次模型从文本中学习到的内容不能共享,如果人名的出现位置变了,那些学习了如何识别人名的节点就无法发挥作用。
那么RNN是如何解决这些问题的呢?首先,我们设置网络的初始激活值 a < 0 > a^{<0>} a<0>(一般是全0向量),之后输入序列第一个数据 x < 1 > x^{<1>} x<1>,得到第一个预测输出 y ^ < 1 > \hat{y}^{<1>} y^<1>,然后将这一步得到的参数传给序列下一个位置的计算,如此循环直到计算到序列的最后一位,这样就实现了参数共享,且不受序列长度的限制。
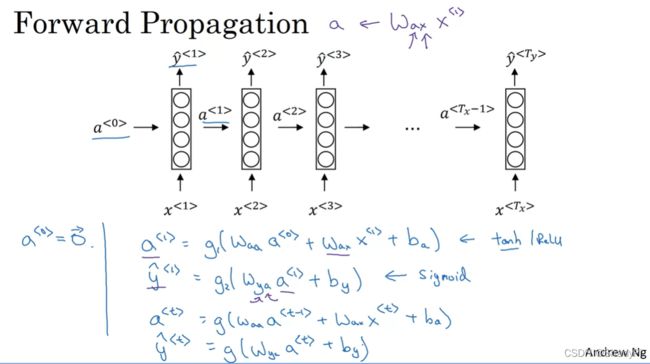
向前传播
首先,设置初始激活值 a < 0 > = 0 ⃗ a^{<0>}=\vec{0} a<0>=0,然后进行第一个数据的计算,激活值和输入都乘以权重再加上偏置经过激活函数得到激活值,激活值再计算经过(可能是另一个)激活函数得到一个输出 y < 1 > y^{<1>} y<1>,即
a < 1 > = g 1 ( W a a a < 0 > + W a x x < 1 > + b a ) y ^ < 1 > = g 2 ( W y a a < 1 > + b y ) \begin{aligned} &a^{<1>}=g_1(W_{aa}a^{<0>}+W_{ax}x^{<1>}+b_a)\\ &\hat{y}^{<1>}=g_2(W_{ya}a^{<1>}+b_y) \end{aligned} a<1>=g1(Waaa<0>+Waxx<1>+ba)y^<1>=g2(Wyaa<1>+by)
这里 g 1 g_1 g1一般是 tanh \tanh tanh函数(我们用其他方法避免梯度消失问题), g 2 g_2 g2则根据需要的输出选择,人名识别是一个二元分类问题,所以 g 2 g_2 g2选择逻辑函数。
更一般的传递过程就是每一次激活层都从上一次循环的激活值基础上进行运算,然后本次的激活值一通运算之后得到本次的输出。
a < t > = g 1 ( W a a a < t − 1 > + W a x x < t > + b a ) y ^ < t > = g 2 ( W y a a < t > + b y ) \begin{aligned} &a^{
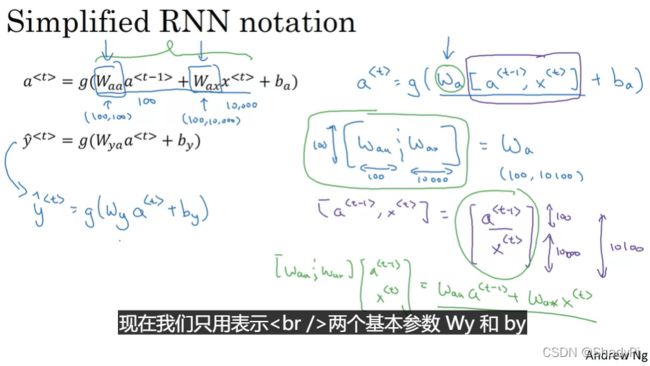
我们还可以简化一下表达式,将 W a a W_{aa} Waa和 W a x W_{ax} Wax矩阵按列(左右)堆叠一起,将 a < t − 1 > a^{
a < t > = g 1 ( W a [ a < t − 1 > , x < t > ] + b a ) y ^ < t > = g 2 ( W y a < t > + b y ) \begin{aligned} &a^{
其中
W a = [ W a a W a x ] , [ a < t − 1 > , x < t > ] = [ a < t − 1 > x < t > ] W_a=\left[\begin{matrix} W_{aa}&W_{ax} \end{matrix}\right], [a^{
向后传播
当我们用机器学习框架实现神经网络是,一般编程框架可以自动处理反向传播,我们简单了解一下如何向后传播即可。
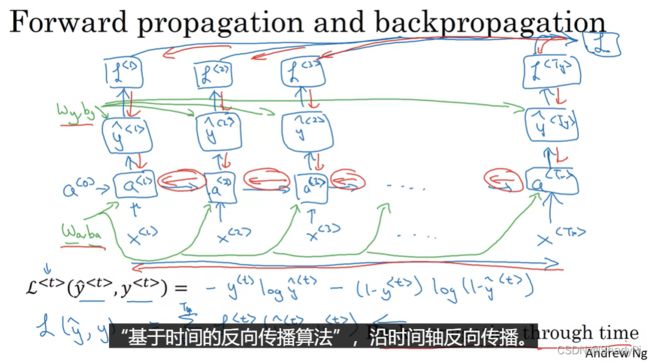
由于这是一个二元分类问题,其损失函数按照逻辑回归的损失定义即可,对于序列的每个位置,有
L < t > ( y ^ < t > , y < t > ) = − y < t > log y ^ < t > − ( 1 − y < t > ) log ( 1 − y ^ < t > ) \mathcal{L}^{
整个样本的损失就是在序列上求和,即
L ( y ^ , y ) = ∑ t = 1 T y L < t > ( y ^ < t > , y < t > ) \mathcal{L}(\hat{y},y)=\sum_{t=1}^{T_y}\mathcal{L}^{
所以反向传播就是求 W y , b y , W a , b a W_y,b_y,W_a,b_a Wy,by,Wa,ba对该损失函数的导数,且要在时间轴上反向计算,按照下图红色箭头从右到左依次运算:
更多RNN模型
上面介绍的模型算是比较基础的,输入输出的序列长度是一样的,下面介绍一些其他的RNN模型。
多对多
就是上面介绍的模型,每个输入序列每个元素都可以对应一个输出序列。
多对一
只在遍历完整个序列以后输出,比如说对一段文字打分。
一对多
只有一个输入或输入是空集,输出一段序列,比如自动写作/谱曲。
不等长多对多
输入和输出都是序列,但是长度不一样,比如文本翻译。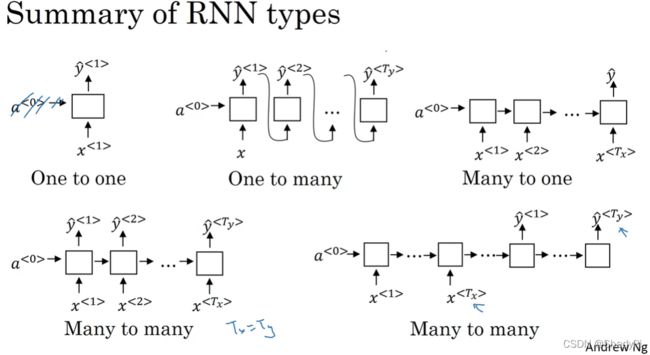
语言模型
语言建模是自然语言处理中最基本、最重要的任务之一,在这一领域RNN的表现也非常不错。
文本训练
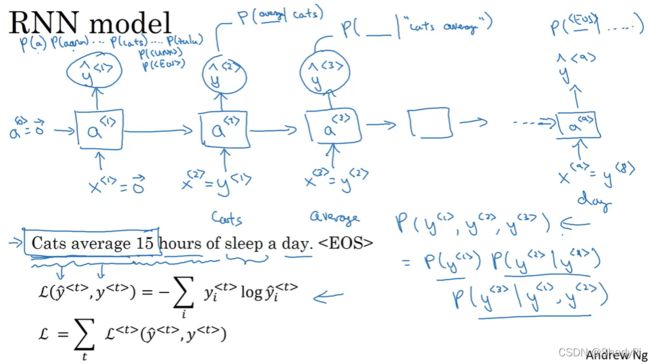
对于一个样例文本,如"Cats average 15 hours of sleep a day.",我们先将序列中的每个单词都映射为一个与我们的词典对应的列向量,然后将这些向量作为网络的输入,词典中没有的词用
损失函数也与softmax的多元分类问题一致,将期望的输出列向量与预测得到的列向量取log按位相乘再求和,如下图。
文本生成
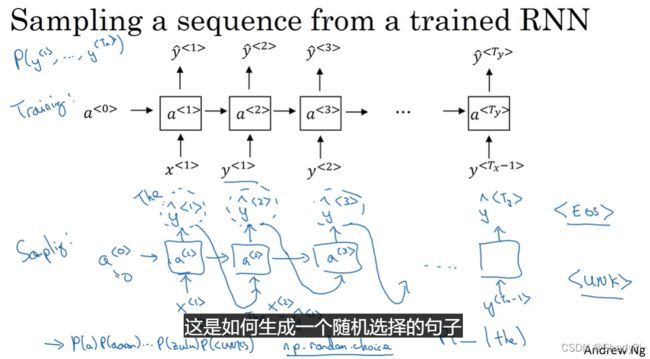
给定一个初始值(比如零向量),然后模型生成第一个预测向量,再将该预测向量传给下一次循环作为输入,得到序列下一个位置的预测向量……如此循环直到我们想要的长度或者有句尾标记。然后我们从一系列预测向量中采样(比如选择预测概率最大的那个或者随机采样等等)就能得到一个完整的句子。
除了以单词为基本单位的,还有以字母为基本单位的模型。大多数情况下,我们都使用单词级语言模型,但是随着计算机速度的加快,单词级的应用越来越多。但它们往往需要大量的硬件和更复杂的计算训练, 因此今天还没有被广泛使用。除非需要特殊处理很多未知单词或其他词汇词的程序。它们也被用于更专业的应用程序中,这些程序需要更专业词汇。
在训练好的模型中采样,就可以得到下图这样的生成文本:

门控循环单元(Gated Recurrent Unit)
对于一些长文本,相隔遥远的两个单词之间的联系会因为通过了多个激活函数变得微弱,有时候还会因为连续累乘造成数字过大,这就是深度网络中的梯度消失/爆炸问题。
为了解决梯度消失/爆炸问题,我们向网络中添加门控循环单元(GRU),这是一个类似于记忆模块的东西,通过控制权值来着重记忆一些内容,这样长文本中的关联词(如人称,时态)就不会断了联系。
新增记忆单元 c c c、门控单元 Γ u \Gamma_u Γu和计算 c c c和 Γ u \Gamma_u Γu的权值矩阵 W c , b c , W u , b u W_c,b_c,W_u,b_u Wc,bc,Wu,bu,新的向前传播公式变为
c < t − 1 > = a < t − 1 > c ~ < t > = tanh ( W c [ c < t − 1 > , x < t > ] + b c ) Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) c < t > = a < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > \begin{aligned} &c^{
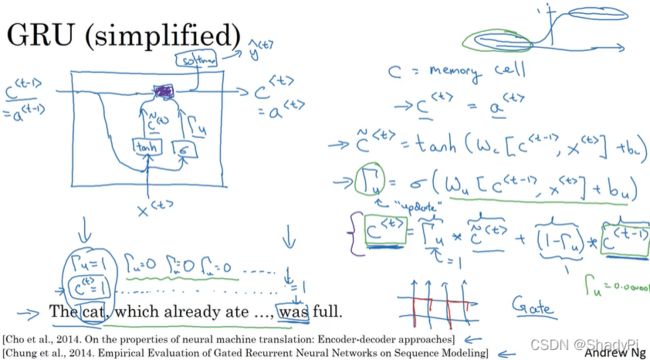
上面还只是简化版GRU,完整版还有一个门控 Γ r \Gamma_r Γr用来控制 c < t − 1 > c^{
c < t − 1 > = a < t − 1 > c ~ < t > = tanh ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c ) Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b r ) c < t > = a < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > \begin{aligned} &c^{
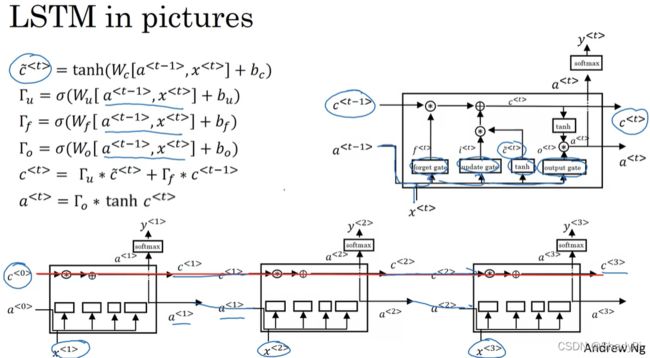
长短期记忆(Long Short Term Memory)
比GRU更强的记忆方法,将设置了更新 Γ u \Gamma_u Γu、遗忘 Γ f \Gamma_f Γf、输出 Γ o \Gamma_o Γo三个参数来控制之前的信息对现在输出的影响。
c ~ < t > = tanh ( W c [ a < t − 1 > , x < t > ] + b c ) Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u ) Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f ) Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o ) c < t > = Γ u ∗ c ~ < t > + Γ f ∗ c < t − 1 > a < t > = Γ o ∗ tanh c < t > \begin{aligned} &\tilde{c}^{
双向循环神经网络(Bidirectional RNN)
普通RNN的一个缺点是我们按照序列顺序输入数据的时候,网络只能接收之前位置的信息,而有时候我们还需要网络接收序列位置在其之后的数据的信息,由此双向RNN应运而生。
实现很简单,建立一个反向的网络就可以了,然后输出预测值的时候综合考虑正向的激活值和反向的激活值,加没加GRU或LSTM都无所谓。
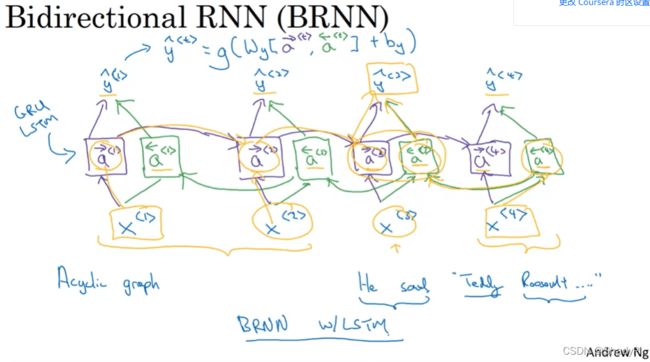
获取整个序列的信息既是优点也是缺点,这意味着我们必须要得到完整的一个序列的信息才能开始运算,对于一些实时场景BRNN就没有那么实用。
深度RNN
普通的RNN激活层只有一层,我们可以多加几层,每个激活层同时接收来自上一个循环的同一激活层和来自本次循环的上一个激活层的信息。这种加深操作同样不受GRU和LSTM的限制。

DRNN可以完成更复杂的计算,这同样意味着其耗费的训练成本和要求的运算性能更高。