tensorflow激活函数原理和代码
在神经元中引⼊了激活函数,它的本质是向神经⽹络中引⼊⾮线性因素 的,通过激活函数,神经⽹络就可以拟合各种曲线。如果不⽤激活函数, 每⼀层输出都是上层输⼊的线性函数,⽆论神经⽹络有多少层,输出都是 一手资源尽在 深度学习 47 输⼊的线性组合,引⼊⾮线性函数作为激活函数,那输出不再是输⼊的线 性组合,可以逼近任意函数。常⽤的激活函数有:
1.Sigmoid/logistics函数
数学表达式为:
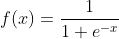
sigmoid 在定义域内处处可导,且两侧导数逐渐趋近于0。如果X的值很⼤ 或者很⼩的时候,那么函数的梯度(函数的斜率)会⾮常⼩,在反向传播 的过程中,导致了向低层传递的梯度也变得⾮常⼩。此时,⽹络参数很难 得到有效训练。这种现象被称为梯度消失。⼀般来说, sigmoid ⽹络在 5 层之内就会产⽣梯度消失现象。⽽且,该激活函数并不是以0为中⼼的, 所以在实践中这种激活函数使⽤的很少。sigmoid函数⼀般只⽤于⼆分类 的输出层。 实现⽅法:
# 导⼊相应的⼯具包
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-10, 10, 100)
y = tf.sigmoid(x)
plt.plot(x,y)
plt.grid()
2.tanh(双曲正切曲线)
数学表达式如下:
![]()
tanh也是⼀种⾮常常⻅的激活函数。与sigmoid相⽐,它是以0为中⼼的, 使得其收敛速度要⽐sigmoid快,减少迭代次数。然⽽,从图中可以看 出,tanh两侧的导数也为0,同样会造成梯度消失。 若使⽤时可在隐藏层使⽤tanh函数,在输出层使⽤sigmoid函数。
# 导⼊相应的⼯具包
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-10, 10, 100)
y = tf.tanh(x)
# 绘图
plt.plot(x,y)
plt.grid() 
3.RELU
数学表达式如下:
![]()
ReLU是⽬前最常⽤的激活函数。 从图中可以看到,当x0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度 不衰减,从⽽缓解梯度消失问题。然⽽,随着训练的推进,部分输⼊会落 ⼊⼩于0区域,导致对应权重⽆法更新。这种现象被称为“神经元死亡”。 与sigmoid相⽐,RELU的优势是:
采⽤sigmoid函数,计算量⼤(指数运算),反向传播求误差梯度 时,求导涉及除法,计算量相对⼤,⽽采⽤Relu激活函数,整个过程 的计算量节省很多。
sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从⽽⽆ 法完成深层⽹络的训练。
Relu会使⼀部分神经元的输出为0,这样就造成了⽹络的稀疏性,并 且减少了参数的相互依存关系,缓解了过拟合问题的发⽣。
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-10, 10, 100)
y = tf.nn.relu(x)
# 绘图
plt.plot(x,y)
plt.grid() 
4.LeakReLu
该激活函数是对RELU的改进,数学表达式为:
![]()
# 导⼊相应的⼯具包
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-10, 10, 100)
# 直接使⽤tensorflow实现
y = tf.nn.leaky_relu(x)
# 绘图
plt.plot(x,y)
plt.grid() 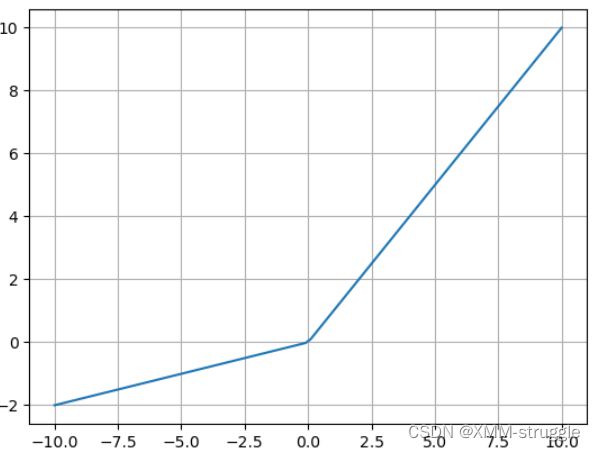
5. SoftMax
softmax⽤于多分类过程中,它是⼆分类函数sigmoid在多分类上的推⼴, ⽬的是将多分类的结果以概率的形式展现出来。 计算⽅数学表达式为:
![]()
softmax直⽩来说就是将⽹络输出的logits通过softmax函数,就映射成 为(0,1)的值,⽽这些值的累和为1(满⾜概率的性质),那么我们将它理 解成概率,选取概率最⼤(也就是值对应最⼤的)接点,作为我们的预测 ⽬标类别。
# 导⼊相应的⼯具包
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# 数字中的score
x = tf.constant([0.2,0.02,0.15,1.3,0.5,0.06,1.1,0.05,3.75])
# 将其送⼊到softmax中计算分类结果
y = tf.nn.softmax(x)
# 将结果进⾏打印
print(y)
# 绘图
plt.plot(x,y)
plt.grid()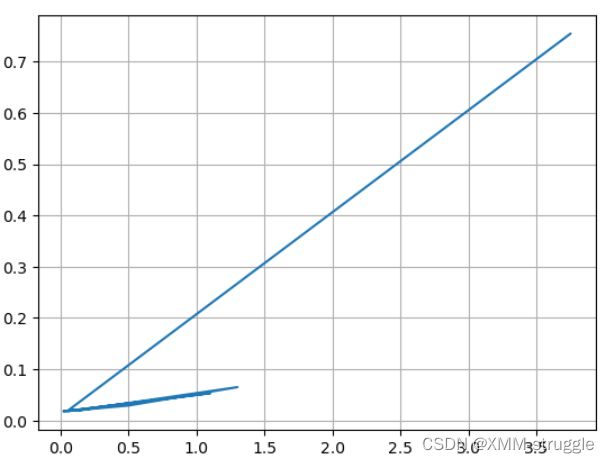
6. 其他激活函数

7.如何选择激活函数
隐藏层
优先选择RELU激活函数
如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
如果你使⽤了Relu, 需要注意⼀下Dead Relu问题, 避免出现⼤的 梯度从⽽导致过多的神经元死亡。
不要使⽤sigmoid激活函数,可以尝试使⽤tanh激活函数。
输出层
⼆分类问题选择sigmoid激活函数。
多分类问题选择softmax激活函数。
回归问题选择identity激活函数。