Neural Architectures for Named Entity Recognition: BiLSTM+CRF模型还原
文章目录
-
- 1. 论文总结
- 2. BiLSTM+CRF模型还原
-
- 2.1 数据集
- 2.2 预处理
- 2.3 padding
- 2.4 model
- 3. 问题
-
- 3.1 seq2seq的损失函数问题
- 3.2 tfa.layers.CRF问题
1. 论文总结
Neural Architectures for Named Entity Recognition
Bidirectional LSTM-CRF Models for Sequence Tagging
Stack-LSTM论文地址
文章提出了两种用于NER任务的方法,一种是BiLSTM+CRF,另外一种借助原Stack-LSTM方法新增chunking块算法。
- 数据:选取英语,西班牙语,德语和荷兰语四种语言
- 预处理:使用每种语言预训练的embedding,没有加入任何辅助性的地名索引资料,仅将英语的数字全部替换成0。
- 优化策略:
– 采用IOBES标注格式;
– 增加对字母的embedding;
– 在embedding层之后加入0.5概率的dropout。
BiLSTM+CRF:第二节模型还原展开
chunking 算法:通过shift、reduce和out操作对句子分块打同一个标,不再是逐字打标
2. BiLSTM+CRF模型还原
2.1 数据集
- MSRA的简体中文NER语料
- 下载地址
2.2 预处理
- 原始语料长这个样子,一句话一行,切分好的词后面采用IOB标注格式进行标注,需要自己整理成每个字都打标的格式,整理好的逐字打标数据以及word2id地址,非常感谢博主@Determined22 的整理。
当/o 希望工程/o 救助/o 的/o 百万/o 儿童/o 成长/o 起来/o ,/o 科教/o 兴/o 国/o 蔚然成风/o 时/o ,/o 今天/o 有/o 收藏/o 价值/o 的/o 书/o 你/o 没/o 买/o ,/o 明日/o 就/o 叫/o 你/o 悔不当初/o !/o
- 拿到整理好的数据之后,需要根据进行
sentence2id步骤,部分代码依旧参考@Determined22博主
import pickle
## _config里面是配置的地址信息
def load_resource(file_name:str):
'''
加载word2id文件
Arguments:
file_name: 文件名
Returns:
obj: word2id
'''
obj = []
read_file = _config.data_path + '/{}'.format(file_name)
with open(read_file, 'rb') as f:
obj = pickle.load(f)
return obj
def load_data():
'''
加载数据, 按行'\n'读取
Return:
data:tuple-list格式
example >>> [(['当','希', ..],[0, 0, ...]),()]
'''
tag2label = {
'O':0,
'B-PER':1, 'I-PER':2,
'B-LOC':3, 'I-LOC':4,
'B-ORG':5, 'I-ORG':6
}
data = []
_seq, _tag = [], []
with open(_config.data_path + 'train_data', 'r') as f:
for line in f.readlines():
if line != '\n':
[word, tag] = line.strip().split()
_seq.append(word)
_tag.append(tag2label[tag])
else:
data.append((_seq, _tag))
_seq, _tag = [], []
return data
def seq2vec(data, vocab):
'''
句子变成id-vector
Arguments:
data: tuple-list格式的数据
vocab: word2id文件
Return:
ret:tuple list
example >>> [([1, 2, ..],[0, 0, ...]),()]
'''
ret = []
for seq, label in data:
seq2id = []
for word in seq:
if word.isdigit():
word = ''
elif ('\u0041' <= word <= '\u005a') or ('\u0061' <= word <= '\u007a'):
word = ''
if word not in vocab:
word = ''
seq2id.append(vocab[word])
ret.append((seq2id, label))
return ret
2.3 padding
放入模型之前,需要对数据进行padding操作
import pandas as pd
def padding(data, pad_mark = 0):
'''
Arguments:
data: tuple-list格式的数据
Returns:
array格式的x和y
max_len: padding完之后的句子长度
seq_lens: 句子的实际长度
'''
ret_x = []
ret_y = []
max_len = max(map(lambda x: len(x), [seq for seq, _ in data]))
seq_lens = list(map(lambda x: len(x), [seq for seq, _ in data]))
for seq, label in data:
seq = seq + [pad_mark] * max(max_len - len(seq), 0)
label = label + [pad_mark] * max(max_len - len(label), 0)
ret_x.append(np.array(seq))
ret_y.append(np.array(label))
return np.array(ret_x), np.array(ret_y), max_len, seq_lens
2.4 model
部分参考github作者Timaos123的项目代码,非常感谢!!
由于新版本tensorflow_addons里面的CRF层不再含有loss和accuracy函数,所以采用官方给出的包含loss和accuracy的crf文件,需要将crf.py文件拷贝到个人项目地址下。代码地址
from crf import CRF
import tensorflow as tf
class BiLSTM_CRF():
'''
模型:
第一层是embedding (确定inputs)
第二层是双向LSTM层 (先得到正向和反向传播拼接得到的embedding)
第三层是CRF层
'''
def __init__(self, vocab_size, embedding_dim, max_len, seq_lens):
self.vocab_size = vocab_size # 词表大小
self.embedding_dim = embedding_dim # embedding维度
self.max_len = max_len # padding完的长度
self.tagNum = 7 # 标签类别
self.build_model() #作用:找到self.myModel
self.seq_lens = seq_lens # 句子的实际长度
def build_model(self):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=self.vocab_size, # 词向量大小
output_dim=self.embedding_dim, # embedding维度
embeddings_initializer='uniform', # 随机初始化embedding矩阵
input_length=self.max_len))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(self.tagNum, activation='softmax'))
crf = CRF(self.tagNum, name = 'crf_layer')
model.add(crf)
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss={'crf_layer':crf.get_loss},
metrics = [{'crf_layer':crf.get_accuracy}]
)
self.myModel = model
def train_test_data(vocab):
'''
划分train_val_test数据集,比例0.6 : 0.2 : 0.2
'''
data = load_data()
data = seq2vec(data, vocab)
data_x, data_y, max_len, seq_lens = padding(data)
train_x, test_x, train_y, test_y = train_test_split(data_x,data_y,
test_size = 0.4,
random_state = 10086,
shuffle = True)
val_x, test_x, val_y, test_y = train_test_split(test_x, test_y,
test_size = 0.5,
random_state = 10000)
return train_x, val_x, test_x, train_y, val_y, test_y, len(vocab), max_len, seq_lens
def get_acc(pre_y, true_y, seq_lens):
count = 0
acc = 0
count_0 = 0
acc_0 = 0
for i in range(len(pre_y)):
for j in range(seq_lens[i]):
acc += 1
if pre_y[i][j] == true_y[i][j]:
count += 1
if true_y[i][j] != 0:
acc_0 += 1
if pre_y[i][j] == true_y[i][j]:
count_0 += 1
return round(count / acc, 4), round(count_0 / acc_0, 4 )
def tagging_model():
'''
训练BiLSTM_CRF模型
'''
vocab = load_resource('word2id.pkl')
embedding_size = 200
train_x, val_x, test_x, train_y, val_y, test_y, vocab_size, max_len, seq_lens = train_test_data(vocab)
tag_model = BiLSTM_CRF(vocab_size, embedding_size, max_len, seq_lens)
tag_model.myModel.summary()
es = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=4)
tag_model.myModel.fit(train_x, train_y,
epochs=1,
callbacks = [es],
batch_size=64,
validation_data=(val_x, val_y))
tag_model.myModel.save(os.getcwd() + '/my_model.h5')
# 调用模型需要加custom_objects参数,不然会报错
# model = tf.keras.models.load_model(os.getcwd() + '/my_model.h5',
# custom_objects={'CRF': CRF, 'get_loss': CRF.get_loss,
# 'get_accuracy': CRF.get_accuracy})
pre_y = tag_model.myModel.predict(test_x)
acc, acc_0 = get_acc(pre_y, test_y, test_seq_lens)
print('全部正确率为{},非0标记正确率为{}'.format(acc, acc_0))
# 全部正确率为0.9864,非0标记正确率为0.8886
if __name__ == '__main__':
tagging_model()
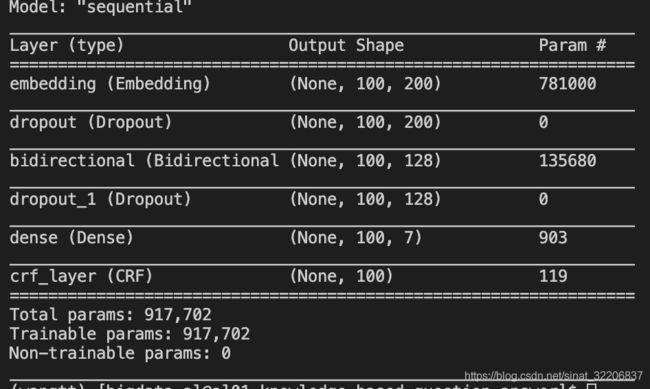
具体模型如下图
3. 问题
第一次尝试去还原论文的方法,中间也踩了很多坑,总结在这里,希望各位大佬路过可以解答一下,谢谢~
3.1 seq2seq的损失函数问题
tfa里面有专门计算seq2seq损失的方法tfa.seq2seq.sequence_loss
tfa.seq2seq.sequence_loss(
logits: tfa.types.TensorLike, # [batch_size, sequence_length, num_decoder_symbols]
targets: tfa.types.TensorLike, # [batch_size, sequence_length]
weights: tfa.types.TensorLike, # [batch_size, sequence_length]
average_across_timesteps: bool = True,
average_across_batch: bool = True,
sum_over_timesteps: bool = False,
sum_over_batch: bool = False,
softmax_loss_function: Optional[Callable] = None,
name: Optional[str] = None
) -> tf.Tensor
需要传前三个参数,但是不知道怎么传,emmm
- 第一个参数应该是BiLSTM的输出;
- 第二个参数是真是的标签,也即
y_true; - 第三个参数是序列预测的权重(貌似是通过转移矩阵得到的?)
3.2 tfa.layers.CRF问题
官方example
>>> layer = tfa.layers.CRF(4)
>>> inputs = np.random.rand(2, 4, 8).astype(np.float32)
>>> decoded_sequence, potentials, sequence_length, chain_kernel = layer(inputs)
>>> decoded_sequence.shape
[2, 4]
>>> potentials.shape
[2, 4, 4]
>>> chain_kernel.shape
[4, 4]
这个层里面是没有损失函数和评估函数的,需要自己添加,在tfa里面注意到这个函数tfa.text.crf_log_likelihood,专门用来计算文本CRF之后的对数似然函数,但问题依旧在于参数如何传递的问题。
tfa.text.crf_log_likelihood(
inputs: tfa.types.TensorLike, # [batch_size, max_seq_len, num_tags]
tag_indices: tfa.types.TensorLike, # [batch_size, max_seq_len]
sequence_lengths: tfa.types.TensorLike, # [batch_size]
transition_params: Optional[TensorLike] = None
) -> tf.Tensor
- 第一个参数应该是BiLSTM的输出;
- 第二个参数是真是的标签,也即
y_true; - 第三个参数是序列的真实长度。