Is Space-Time Attention All You Need for Video Understanding?
TimeSformer
- Abstract
- 1 Introduction
- 3 The TimeSformer Model
- Experiments
-
- 4.1. Analysis of Self-Attention Schemes
- 4.2. Varying the Number of Tokens in Space and Time
- 4.3. The Importance of Pretraining and Dataset Scale
- 4.4. Comparison to the State-of-the-Art
- 4.5. Long-Term Video Modeling
- Conclusion
备注: 如有侵权,立即删除
code: https://github.com/lucidrains/TimeSformer-pytorch
source: 2021
Abstract
我们提出了一种无卷积的视频分类方法,专门建立在空间和时间上的自注意力机制之上。我们的方法名为“时空转换器”(TimeSformer),通过允许直接从一系列框架级的补丁序列中进行时空特征学习,从而将标准的Transformer体系结构适应于视频。我们的实验研究比较了不同的自注意力方案,并建议“分散注意力”,即分别应用时间注意力和空间注意力,在考虑的设计选择中具有最佳的视频分类精度。尽管与视频的3D卷积架构的设计截然不同,但TimeSformer在几个主要的动作识别基准数据集上取得了最先进的效果,包括 Kinetics-400和 Kinetics-600的最佳报告精度。此外,与相互竞争的架构相比,我们的模型的训练速度更快,并具有更高的测试时间效率。代码和预先训练的模型未来将公开。
1 Introduction
在过去几年中,基于自我关注的方法的出现,彻底革新了自然语言处理领域(NLP)(瓦斯瓦尼等人,2017a)。由于其捕捉单词之间远程依赖关系的卓越能力以及训练可伸扩展性,诸如变压器模型代表了广泛语言任务的先进技术,包括机器翻译(奥特等,2018;陈等,2018a)、问题回答(德夫林等,2019;戴等,2019)和自回归单词生成(雷德福等,2019;布朗等,2020)。
视频理解与NLP有几个高级相似之处。首先,视频和句子从本质上都是顺序的。此外,确切地说,一个词的含义往往只能通过与句子中的其他词联系起来来理解,因此可以认为,短期片段中的原子行为需要与视频的其余部分结合起来,以便完全消除歧义。因此,人们期望NLP中的长距离自我注意模型对于视频建模是非常有效的,不仅能够捕获跨时间的依赖性,而且能够通过对不同空间位置的特征进行成对比较来揭示每一帧中的上下文信息。然而,在视频领域,2D或3D卷积仍然是跨不同视频任务时空特征学习的核心算子(Feichtenhofer et al.,2019a;Teed&Deng,2020;Bertasius&Torresani,2020)。虽然自我注意在卷积层上应用时显示出优势(Wang等人,2018a),但据我们所知,没有尝试将自我注意作为视频模型的唯一构建块的报道。
在这项工作中,我们提出了一个问题,即是否可以通过用自注意力机制完全替换卷积算符来构建一个无卷积视频结构。我们认为,这样的这种设计有潜力克服卷积视频分析模型的一些固有限制。首先,虽然它们的强感应偏差(例如,局部连通性和翻译等方差)无疑对小的训练集有益,但在有足够的数据可用性的设置下,它们可能会过度限制模型的表达性,并且可以从例子中学习“所有”的表达性。与卷积神经网络相比,Transformer施加的限制性较小。这扩大了它们可以代表的函数族(科隆尼耶等,2020;赵等,2020),并使它们更适合现代无需强归纳先验的大数据体系。其次,虽然卷积内核是专门设计用来捕获短程时空信息的,但它们不能建模超出接受域的依赖关系。深度卷积堆(西蒙扬和齐泽尔曼,2015;齐格迪等,2015;卡雷拉和泽瑟曼,2017)自然扩展了接受范围,但这些通过聚合短距离信息捕获远程依赖的策略天生有限。相反,自注意力机制可以通过直接比较所有时空位置的特征激活来捕获局部和全局的长程依赖,远远超出了传统卷积滤波器的感受野。最后,尽管在GPU硬件加速方面取得了进步,但训练深度cnn仍然非常昂贵,尤其是在应用于高分辨率和长视频时。静止图像领域的最新工作(Dosovitskiy等人,2020;Carion等人,2020;Zhao等人(2020年)已经证明,与CNN相比,Transformers具有更快的训练和推理速度,这使得在相同的计算预算下构建具有更大学习能力的模型成为可能。
基于这些观察,我们提出了一个完全基于自我关注的视频架构。我们将图像模型“视觉变换器”(ViT)(Dosovitskiy et al.,2020)应用于视频,将自注意机制从图像空间扩展到时空三维体。我们提出的模型名为“时间成型器”(来自Time Space Transformer)将视频视为从各个帧中提取的一系列面片。在ViT中,每个面片被线性映射成一个嵌入,并增加了位置信息。这使得将得到的向量序列解释为令牌嵌入成为可能,令牌嵌入可以被馈送到转换器编码器,类似于从NLP中的字计算出的令牌特征。
标准变压器中自注意操作符的一个缺点是,它需要计算所有对令牌的相似度度量。在我们的设置中,由于视频中有大量的补丁,这使计算成本高。此外,它还忽略了视频的时空结构。为了解决这些挑战,我们提出了几种在时空体积上的可伸缩的自注意设计,并在大规模的动作分类数据集上对它们进行了经验评估。在所提出的方案中,我们发现最佳的设计是由一个“分散注意力的”体系结构来表示的,它在网络的每个块内分别应用时间注意和空间注意。与已建立的基于卷积的视频架构范式相比,时间转换器遵循了一个截然不同的设计。然而,它在精度方面可与这一领域的最先进技术相比,而且在某些情况下更先进,同时也更有效率。此外,我们还证明,我们的模型可以有效地用于跨越许多分钟的视频的远程建模。
3 The TimeSformer Model
Input clip. TimeSformer 从原始视频中采样的大小为H×W的F个RGB帧组成的剪辑X∈R H×W×3×F作为输入.
Decomposition into patches. 按照ViT方法(多索维茨基等人,2020),我们将每一帧分解为N个不重叠的块,每个大小为P×P,这样N个块跨越整个帧,即N个=HW/P2。我们将这些补丁扁平为矢量x(p,t)∈R3p2与p=1,…,N表示空间位置,t=1,…,F表示帧上的索引。
Linear embedding. 我们通过一个可学习的矩阵E∈RD×3p2,线性地将每个补丁x(p、t)映射到一个嵌入的向量z(0)(p、t)∈路中:

其中e pos (p,t)∈路道代表添加了一个可学习的位置嵌入来编码每个补丁的时空位置。p=1的嵌入向量z(0)(p,t),n和t=1,…,F表示变压器的输入,并发挥类似于馈给NLP中文本变压器的嵌入字/标记序列的作用。在最初的BERT变压器(德夫林等人,2018),我们在序列的第一个位置添加了一个特殊的可学习向量z(0),(0,0),∈RD路表示分类令牌的嵌入。
Query-Key-Value computation. 我们的变压器由L个编码块组成。在每个块,从前一个块编码的表示z(L−1)(p,t)计算每个补丁的查询/密钥/值向量:
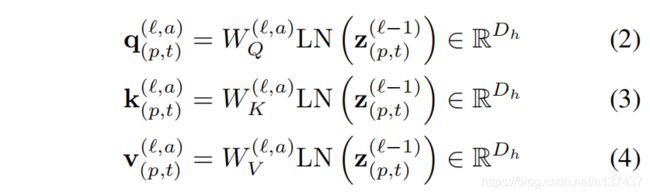
其中LN()表示层规范(Ba等人,2016),=1,…,A是多个注意力头上的索引,A表示注意力头的总数。每个注意头的潜在维数设置为Dh=D/A.
Self-attention computation. 自我注意的权重是通过点乘积来计算出来的。对于查询补丁(p,t)的自我注意权重α(`,a)(p,t)∈和NF1是由:
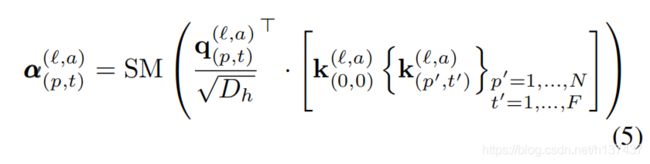
其中,SM表示软最大激活功能。注意,当注意力仅在一维上计算(例如仅空间或时间)时,计算显著减少。例如,在空间注意的情况下,仅使用与查询来自同一帧的密钥进行N1帧查询密钥比较:

Encoding. 通过首先使用每个注意头的自注意系数计算值向量的加权和,得到块处的编码z(`)(p,t):

然后,来自所有头的这些向量的连接被投影并通过一个MLP,使用每次操作后的剩余连接:
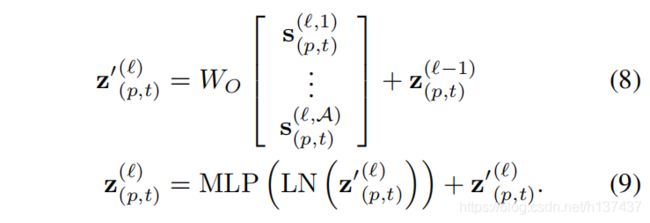
Classification embedding. 最终分类嵌入来自分类令牌的最后块:
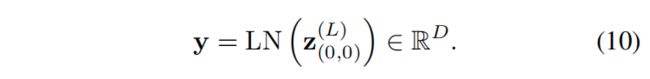

Space-Time Self-Attention Models. 如前所述,我们可以通过取代等式的时空注意力来降低计算成本5只在每一帧内都有空间注意(等式6).然而,这样的模型忽略了捕获跨帧的时间依赖关系。正如我们的实验所示,与完全时空关注相比,这种方法会导致分类精度下降,特别是在需要强时间建模的基准测试上。
我们提出了一种替代的、更有效的时空注意结构,名为“划分时空注意力”(用TS表示),其中时间注意和空间注意分别被单独应用。将该体系结构与图中的空间和联合时空注意的体系结构进行了比较。1.通过视频示例给出了不同注意力模型的可视化图。2.对于分割注意,在每个块中,我们首先通过比较每个补丁(p、t)与其他帧中相同空间位置的所有补丁来计算时间注意:
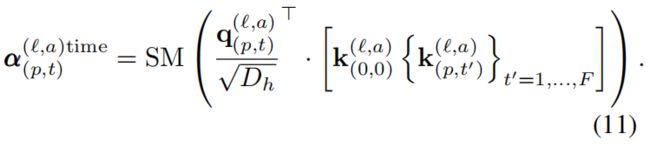
应用等式所产生的编码z0()时间(p、t)然后,使用时间注意力的8被反馈给空间注意力计算,而不是传递给MLP。换句话说,从z0()时间(p、t)获得新的密钥/查询/值向量,然后使用等式计算空间注意力6.最后,将得到的向量z0()空间(p、t)传递给等式的MLP9来计算在块处的补丁的最终编码z()(p,t)。对于注意力分散的模型,我们学习了时间和空间维度上不同的查询/键/值矩阵(W(、a)Q时间、W(、a)k时间、W(、a)V时间}和{W(、a)Q空间、W(、a)k空间、W(、a)V空间)。请注意,与等式的联合时空注意模型所需的每个补丁的(NF1)比较相比5,分散注意力在每个补丁中只执行(NF2)比较。实验表明,这种时空分解效率不仅有效,而且提高了分类精度。
我们还实验了一个“稀疏局部全局”注意力模型和一个“轴向”注意力模型。它们的体系结构如图所示。1,,而是附图。2显示了这些模型考虑注意的补丁。对于每个块(p、t),(LG)首先通过考虑邻近的F×H/2×W/2块来计算局部注意力,然后使用沿时间维和2空间维的2步块来计算整个片段的稀疏全局注意力。因此,它可以被看作是使用局部全局分解和稀疏模式的全时空注意力近似,类似于(儿童等人,2019)。最后,“轴向”注意力将注意力计算分解为三个不同的步骤:随着时间的推移、宽度和高度。提出了图像两个空间轴的分解注意模式(Ho等,2019;黄等,2019;王等,2020b)和我们(TWH)为视频情况增加了三维(时间)。所有这些模型都是通过学习每个注意步骤的不同的查询/键/值矩阵来实现的。
Experiments
我们现在在四个流行的动作识别数据集上评估TimeSformer:Kinetics-400 (Carreira & Zisserman, 2017), Kinetics-600 (Carreira et al., 2018), Something-Something-V2 (Goyal et al., 2017), and Diving-48 (Li et al., 2018).
对于所有实验,我们采用“基础”ViT模型架构(多索维特斯基等人,2020)预训练(鲁萨科夫斯基等人,2014)。除非有不同的规格,否则我们使用大小为8×224×224的剪辑,帧采样速率为1/16。补丁大小被设置为16×16像素。在推理过程中,除非另有说明,否则我们在视频中间采样一个时间片段。我们使用3种空间作物(左上角、中角、右下角),以便整个视频剪辑被空间覆盖。最终的预测是通过平均这3个预测的最小分数得到的。
4.1. Analysis of Self-Attention Schemes
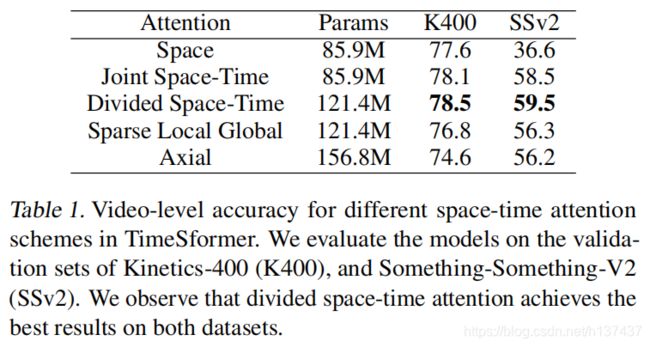
在表1中,我们使用动力学400(K400)和某物V2(SSv2)作为基准,提出了在时间变换器中提出的五种时空注意方案的结果。从这些结果中,我们首先可以注意到,只有空间注意的时间变换器在K400上表现良好。这是一个有趣的发现。事实上,塞维利亚-劳拉等人。(2021)发现,在K400上,空间信息的使用比利用时间动力学的准确性更重要。在这里,我们证明了完全没有任何时间建模即可在K400上获得可靠的精度。但是,请注意,只空间关注在SSv2上的表现非常差。这就强调了对后一个数据集进行时间建模的重要性。
此外,我们观察到分裂的时空注意力在K400和SSv2上都取得了最好的精度。这是有意义的,因为与联合时空注意力相比,分割的时空注意力具有更大的学习能力(见表1),因为它包含了时间注意力和空间注意力的不同学习参数。

在图3中,我们还比较了在使用更高空间分辨率(左)和更长时间(右)的视频时,联合时空注意力和分割时空注意力的计算成本。我们注意到,在这两种情况下,划分时空的方案都能很好地伸缩。相比之下,当分辨率或视频长度增加时,联合时空注意方案会导致显著更高的成本。在实践中,一旦空间帧分辨率达到448像素,或者一旦帧数增加到32像素,联合时空注意就会导致GPU内存溢出,因此它有效上不适用于大型帧或长视频。因此,尽管有更多的参数,但当在更高的空间分辨率或更长的视频上操作时,分割的时空注意力比联合的时空注意力更有效。因此,对于随后的所有实验,我们使用了一个由分割的时空自注意块构造的时间变换器。
4.2. Varying the Number of Tokens in Space and Time
如上所述,与大多数3D网络网络相比,我们的模型的可伸缩性允许它在更高的空间分辨率和更长的视频上运行。我们注意到,这两个方面都会影响馈送给变压器的令牌序列的长度。具体来说,增加空间分辨率会导致每帧有更多的补丁N)。当使用更多的帧时,输入标记的数量也会增加。为了研究其好处,我们进行了实证研究,分别增加沿这两个轴的标记数量。
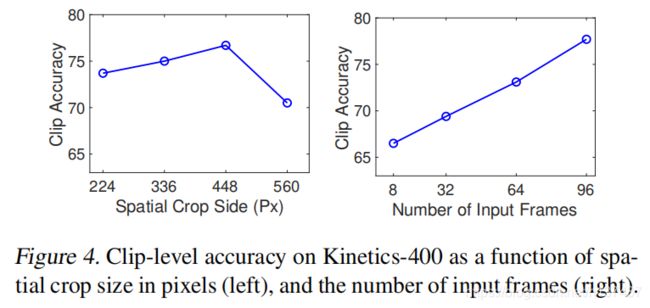
我们在图4中报告了调查结果。我们看到,提高空间分辨率(达到某个点)会导致性能的显著提高。同样地,我们观察到,增加输入剪辑的长度会导致一致的精度增益。由于GPU内存限制,我们无法在超过96帧的剪辑上测试我们的模型。尽管如此,我们还是想指出,使用96帧的剪辑与当前的卷积模型明显不同,当前的卷积模型通常仅限于处理8−32帧的输入。
4.3. The Importance of Pretraining and Dataset Scale
在他们最近的工作中,多索维茨基等人的(2020)证明了ViT在在非常大规模的数据集上训练时是最有效的。在本节中,我们将研究我们的时间变形器模型是否存在同样的趋势。
首先,我们试图直接在视频数据集上训练时间转换器,而不需要图像网络预训练。在这些实验中,我们遵循了图夫龙等人的从头开始的训练的协议。(2020)和我们也评估了它的一些变体。然而,该模型未能学习到有意义的特征。我们怀疑,为了训练视频数据上的时间转换器从头开始,可能需要一种新的优化策略或不同的超参数值。
因此,对于随后的所有研究,我们继续使用图像网预训练。为了理解视频数据规模对性能的影响,我们对我们的模型进行了对K400和完整数据集的{25%、50%、75%、100%}的不同数据集的训练。我们在图5中展示了这些结果,其中我们还将我们的方法与慢速度R50(费希滕霍夫等人,2019b)和在同一子集上训练的I3DR50(卡雷拉和齐瑟曼,2017)进行了比较。我们注意到所有3个架构都在图像网上进行了预训练(鲁萨科夫斯基等人,2014)。

图5的结果表明,在K400上,时间转换器对所有训练子集的性能都优于其他模型。然而,我们在SSv2上观察到一个不同的趋势,其中只有在75%或100%的完整数据上训练时,时间转换是最强的模型。这可以解释为与K400相比,SSv2需要学习更复杂的时间模式,因此时间转换器可能需要更多的例子来有效地学习这些模式。
4.4. Comparison to the State-of-the-Art
现在我们比较时间转换器和最先进的在几个流行的动作识别数据集。我们使用模型的三个变体:(1)时间传感器,模型的默认版本操作8×224×224视频剪辑,(2)时间转换,高空间分辨率变异运行16×448×448视频剪辑,最后(3)时间转换,模型的长期配置运行96×224×224视频剪辑帧采样以1/4。
Kinetics-400. 在表2中,我们报告了关于K400验证集的结果。除了精度指标之外,我们还包括在TFLOP中给出的推理成本。我们发现以往的大多数方法在推理过程中使用10个包含3个空间作物的时间片段(总共30个时空视图),我们证明TimeSformer只有3个视图(3个空间作物)实现了可靠的精度,从而降低了推理成本。我们的远程变体,时间转换器-l,达到了80.7%的前1个精度,优于所有之前的方法。此外,我们的默认时间变换器在最近最先进的模型中的推理成本是最低的。然而,它仍然提供了78%的可靠精度,优于许多成本更多的模型。

在图6中,我们研究了在推理过程中使用多个时间剪辑(每个剪辑具有单一空间作物)的影响。我们使用K∈{1、3、5、10}时间剪辑绘制精度进行测试。我们将我们的模型与X3D(费希滕霍弗,2020)和慢速(费希滕霍弗等,2019b)进行比较。X3D和慢速快速需要多个(≥5)剪辑来接近它们的最高精度。相反,我们的远程变体,TimeSformer-L,根本不适用于使用多个剪辑。这是有意义的,因为它能够跨越大约12秒的动力学视频与一个单一的剪辑。
我们还注意到,即使这两种模型都是经过成像集的预训练,时间转换器的训练速度也要快得多。例如,在K4PU上训练SlowFast 8×8R50的64GPU需要54.3小时,而在32GPU的类似设置下训练I3DR50则需要45小时。相比之下,时间转换器可以使用32个GPU在14.3小时内进行训练。与这两个3D中枢神经网络相比,这将使训练时间减少了3倍。
Kinetics-600. 在表3中,我们还展示了我们关于Kinetics-600的结果。就像在Kinetics-400上一样,我们观察到我们的方法在这个基准上优于之前的工作。有趣的是,我们注意到,在这种情况下,我们的模型中性能最好的变体是TimeSformer-HR。

Something-Something-V2. 在表4中,我们还在SSv2上验证了我们的模型。我们的结果表明,时间变换器比该数据集上的最佳模型获得了较低的精度。然而,考虑到我们的模型使用了一个完全不同的设计,我们认为这些结果表明,即使对于挑战时间较重的数据集,如SSv2,时间转换器也是一种很有前途的方法。
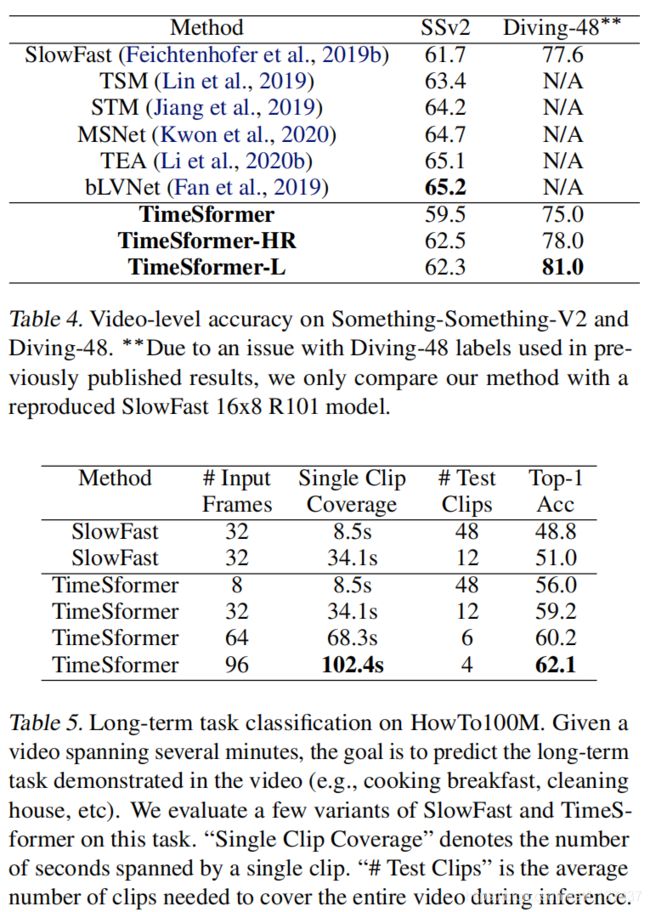
Diving-48. 最后,在表4中,我们在另一个“时间重”数据集潜水48上提出了我们的方法。由于最近发现的以前版本的潜水-48标签的问题,在这里,我们只将我们的方法与复制的SlowFast 16×8R101模型进行比较。我们的结果表明,TimeSformer的执行速度大大超过了SlowFast。
4.5. Long-Term Video Modeling
在本小节中,我们使用如何到100M数据集来评估长期视频建模的任务(米奇等人,2019年)。如何达到1亿美元是一个大型的教学视频数据集。它包含了大约100万段教学网络视频,显示人类执行超过23K个不同的任务,如烹饪、修理、编织和制作艺术。这些视频的平均持续时间约为7分钟,比标准动作识别基准中的视频持续时间长一个数量级。每个HowTo100M视频都有一个标签,指示视频中演示的任务(23K类中的一个),可用于监督培训。因此,它是一个很好的基准来评估一个模型识别在很长时间范围内显示的活动的能力。
对于这个评估,我们只考虑有至少100个视频例子的类别。这给出了如何处理100M的1个子集,对应于120K视频,跨越1059个任务类别。我们将这个集合随机划分为85K训练视频和35K测试视频。
我们将研究结果列入表5。作为我们的基线,我们使用了两种变体的慢快速R50,这两种变量都运行在32帧的输入上。然而,第一变体使用1/8的采样率,因此它使用长度约8秒的剪辑(假定30FPS),而第二变体采用较低的1/32的采样率,因此它的长度跨越30秒。对于时间转换器,我们测试了四种变体,所有的变量都在以1/32的帧率采样的视频剪辑上操作,但有不同的帧数:8、32、64和96。在推理过程中,对于每种方法,我们根据需要采样尽可能多的不重叠的时间片段来覆盖输入视频的完整时间范围,例如,如果单个片段跨越8.5秒,我们将采样48个测试片段以覆盖410秒的视频。视频级别分类是通过平均剪辑预测来完成的。

从表5的结果中,我们首先注意到,对于相同的单个片段覆盖范围,时间转换器的性能大大高于7−8%。其次,我们观察到更长距离的时间信号转换器做得更好,我们的最长距离的变体达到了最好的视频级分类精度。这些结果表明,我们的模型非常适合于需要长期视频建模的任务。最后,我们注意到TimeSformer的远程建模方法正交于设计在视频主干上操作的长期方案(Wu等人,2019;格尔达尔等人,2017),因此,它们的组合可能会有进一步的收益。
Conclusion
在这项工作中,我们引入了时间转换器,这是一种根本不同的视频建模方法,与已建立的基于卷积的视频网络的范式相比。我们证明了设计一种完全建立在时空自我基础上的有效、可伸缩的视频架构是可能的。我们的方法(1)在概念上很简单,(2)在主要的动作识别基准上取得了最先进的结果,(3)的推理成本较低,而(4)适用于长期的视频建模。在未来,我们计划将我们的方法扩展到其他视频分析任务,如动作定位、视频字幕和问答。