TimeSformer泛读【Is Space-Time Attention All You Need for Video Understanding?】
目录
0、前沿
1、标题
2、摘要
3、结论
4、重要图表
5、解决了什么问题
6、采用了什么方法
7、达到了什么效果
0、前沿
泛读我们主要读文章标题,摘要、结论和图表数据四个部分。需要回答用什么方法,解决什么问题,达到什么效果这三个问题。 需要了解更多视频理解相关文章可以关注视频理解系列目录了解当前更新情况。
论文原文下载:https://arxiv.org/pdf/2102.05095.pdf https://arxiv.org/pdf/2102.05095.pdf
https://arxiv.org/pdf/2102.05095.pdf
1、标题
Is Space-Time Attention All You Need for Video Understanding?
视频理解是否只需要时空注意力(题目是套用Transformer:Attention is All You Need格式)
2、摘要
We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named “TimeSformer,” adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches.Our experimental study compares different self-attention schemes and suggests that “divided attention,” where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600.Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long). Code and models are available at: https://github.com/ facebookresearch/TimeSformer
我们提出了一种基于时空的自注意力机制的视频理解方法,它完全不使用卷积网络。我们把它叫“TimeSformer”,它通过帧级别的patches序列来学习时空特征,让标准Transformer架构应用到视频中。我们的实验比较了不同的自注意力方案,结果表明,在所有的设计中,时间注意力和空间注意力分别应用于每个块的“分散注意力”获得了视频分类的最好性能。尽管采用了全新的设计,TimeSformer还是在几个动作识别基准上取得了最好的结果,包括在Kinetics-400和Kinetics-600上报告了最佳精确度。最后,与3D卷积网络相比,我们的模型训练速度更快,测试效率显著提高(如果精度下降一点),同时它也可以用在更长的视频片段上(1分钟以上)。代码和模型放在:
https://github.com/facebookresearch/TimeSformer
3、结论
In this work, we introduced TimeSformer, a fundamentally different approach to video modeling compared to the established paradigm of convolution-based video networks. We showed that it is possible to design an effective, and scalable video architecture built exclusively on space-time self-attention. Our method (1) is conceptually simple, (2) achieves state-of-the-art results on major action recognition benchmarks, (3) has low training and inference cost, and (4) can be applied to clips of over one minute, thus enabling long-term video modeling. In the future, we plan to extend our method to other video analysis tasks such as action localization, video captioning and question-answering.
本文我们介绍了TimeSformer,与现有的基于卷积的视频网络模型相比,它是一种完全不同的视频建模方法。我们展示了完全基于时空自注意力设计一个有效的、可伸缩的视频架构是可以的。
我们的方法总结为4点:
(1)概念简单
(2)在主要的动作识别基准上获得SOTA
(3)较低的训练和推理成本
(4)能用在超过一分钟的视频上,从而使长视频建模成为可能
未来,我们准备把这个方法应用到视频的其他task上。
4、重要图表

图1:文章中的视频自注意力块。每个自注意力层在相邻的帧级patches时空间实现。我们使用残差链接来聚合不同注意力层的每个块的信息。每个块最后使用1层隐藏层的MLP。最终模型通过重复堆叠这些块来实现。

图2:本文所研究的5种时空自注意力的可视化。
每个视频clip被视为大小为16X16像素的帧级patches序列。在图中,我们用蓝色表示查询patch,在每个方案中用非蓝色表示其邻域时的空注意力。没有颜色的块不参与蓝色块注意力计算。一个方案中有多个颜色,表示时空注意力被应用到不同的维度。
需要注意的是,视频的clip中每个patch的自注意力是单独计算的,每个path都会被当成一个query。还需要注意的是,图中标的是相邻的帧间的注意力,实际上它以相同的方式存在于所有帧的clip中。

表1:TimeSformer中不同的时空注意力的视频级精度。
我们在K400和SSv2上评估我们的模型。我们发现,在5个注意力方案中,divided space-time attention在两个数据集上表现最好。

图3:我们比较了联合与分散的时空注意力成本。
左边是空间裁剪的TFLOPs数量函数
右边是输入帧数量的TFLOPs数量函数
当我们增加空间分辨率(左)或视频长度(右)时,分散时空注意方案比联合时空注意方案节省了很大的计算量。

表2:TimeSformer与SlowFast和I3D比较。
我们观察到,尽管TimeSformer具有更大的参数量,但缺具有较低的推理成本。另外,即使在在ImageNet-1K上预训练,TimeSformer在视频数据上的训练成本的也比SlowFast和I3D低得多。
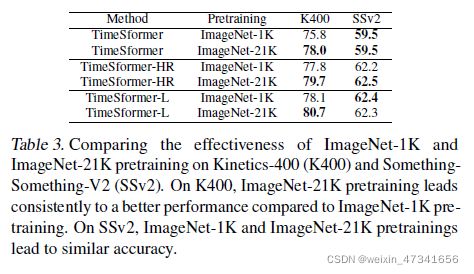
表3:比较在ImageNet-1K和ImageNet-21K上预训练,在K400和SSv2上的效果。
在K400上,用ImageNet-21K的预训练始终比ImageNet-1K的预训练具有更好的性能。
在SSv2上,ImageNet-1K和ImageNet-21K预训练的精度相近。

图4:K400和SSv2不同预训练视频数量的精度。
所有的模型都在ImageNet-1K上预训练。
在K400上,所有的数量,TimeSformer都表现最好。
在SSv2(需要更复杂的时间推理)上,只有在使用足够的训练视频时,TimeSformer才会优于其他模型。

图5:在K400上不同维度Clip级别精度。左边是空间裁剪的像素尺寸,右边是帧的数量。
表4:位置编码嵌入的消融实验。使用时空嵌入的TimeSformer在K400和SSv2上都具有最高的精度。
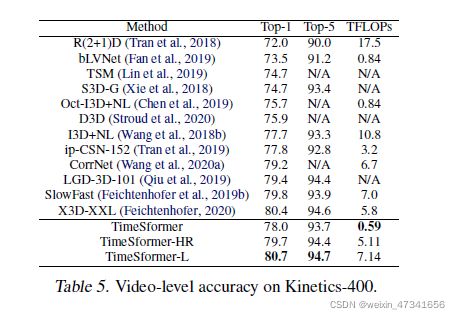
表5:K400上,视频级精度

表6:K600上,视频级精度

图6:K400上的精度与推理中使用的时间剪辑数量的关系。
TimeSformer-L使用少量的剪辑获得了出色的精度,这标明其具有低推断成本下的强大性能。

表7:在SSv2和Diving-48上的精度。由于之前发布的结果,Diving-48标签存在问题,我们只与复现的Slow Fast比较。所有的模型都在ImageNet-1K上预训练。

表8:HowTo100M上Long-term任务。
给一段几分钟的视频,目标是预测视频中展示的Long-term任务(比如煮饭,扫地)。我们用了SlowFast和TimeSformer的几个变体做实验。“Single Clip Coverage”表示单个剪辑所跨越的秒数。“# Test Clips”是在推断期间覆盖整个视频所需的平均剪辑数。所有模型在K400上预训练。

图7:从输出标记到输入空间在SSv2上的时空注意力的可视化。我们的模型关注到了视频中相关的部分,以便进行时空推理。

图8:SSv2上t-SNE特征可视化。每个视频被可视化为一个点。相同分类的的视频具有相同的颜色。分散时空的TimeSformer。分散的时空注意力imeSformer比仅具有空间注意的imeSformer和ViT学习到了更多可分离的语义特征。
5、解决了什么问题
表现好的视频理解网络都是基于3D卷积,Transformer这么火,能不能很好的用到视频中。
6、采用了什么方法
基于时空注意力分别应用到网络上构建了TimeSfomer
7、达到了什么效果
K400K600达到SOTA