深度学习论文随记(一)---AlexNet模型解读
作者:teeyohuang
邮箱:[email protected]
本文系原创,供交流学习使用,转载请注明出处,谢谢
深度学习论文随记(一)---AlexNet模型解读
ImageNet classification with deep convolutional neural networks
Author: A Krizhevsky, I Sutskever , GE Hinton
Year:2012
1、导引
其实这篇论文按道理讲,并不是第一个把卷积神经网络应用到深度学习中的工作,往前其实有个LeNet,是深度学习三驾马车之一的Yann Lecun在1998年就设计出来了。
但是一般深度学习入门要看的第一篇论文,还是会推荐这篇,我个人认为,这篇论文的意义在于,它是使得Deep Learning这种机器学习的方法征服计算机视觉领域的开山之作。
2012年,深度学习三驾马车中的另一位 Geoffrey Hinton为了证明自己的研究工作是有用的,他和他的学生Alex Krizhevsky 在ILSVRC竞赛中出手,刷新了classification的记录,一战封神!!!所以,这篇文章所述的网络结构也就被称为AlexNet。至此之后,无数的学者投入到Deep Learning的研究中去。
2、AlexNet模型解读
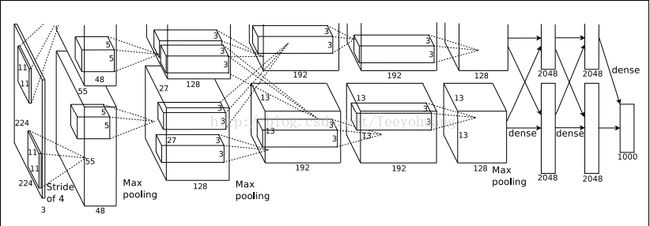
这张图片本来上半部分就没有,论文中就是给的这个图。
然后之所以用的上下两半一样的结构,是因为他们当时用的GPU计算力有限,所以用了两块GPU:GTX 580。现在都是2017年了,你笔记本上的GPU估计都是GTX970了,所以下面讲的时候就当作是只用的一个GPU来分析。
AlexNet共有八层,有60M以上的参数量。
前五层为卷积层:convolutional layer;
后三层为全连接层,fully connected layer。
最后一个全连接层输出具有1000个输出的softmax。(这个不懂什么意思的参考机器学习理论中的softmax regression,就是一个多类的logistic regression)
大致的分层结构如下:

注:觉得看不清图片的同志请在新标签页打开图像,查看原图即可~
●第一层:
①输入图片为224x 224 x3, 表示长宽是224个像素,RGB彩色图通道为3通道,所以还要乘以3.(学界普遍认为论文中说的224不太合适,讲道理应该是227的大小才对,这也成为一个悬案),
②然后采用了96个11 x 11 x 3 的filter。在stride为4的设置下,对输入图像进行了卷积操作。所以经过这一卷积后的操作,输出就变成了55 x 55 x96 的data map。这三个数字的由来:(227-11)/ 4 + 1 = 55,96就是滤波器的个数。
③然后经过激活函数ReLu,再进行池化操作-pooling:滤波器的大小为3 x 3,步长stride为2. 所以池化后的输出为27x 27 x 96
(55-3)/ 2 + 1 =27. 96仍为原来的深度。
④LRN,局部响应归一化。后来大家都认为这个操作没有什么太大的作用,所以后面的网络几乎都没有这个操作,我也就不提了。
●其他第2、3、4、5层的计算过程类似。
●第六层:本层的输入为6 x 6 x 256,全连接层其实就是一个矩阵运算,它完成一个空间上的映射。所以把输入看成一个列向量X,维度为9216(6 x 6 x 256),也就是你可以把输入看成一个9216 x 1的矩阵。
然后和参数矩阵W相乘,参数矩阵W你此时设置为4096 x 9216
所以最后本全连接层的输出就是 矩阵相乘Y = W·X得 4096 x 1的矩阵
●第八层:第八层的输出就为1000 x 1的矩阵,即1000维度的一个列向量,对应softmax regression的1000个标签
3、一些创新点分析
①ReLU
RectifiedLinear Uints,修正线性单元即f(x)=max(0,x)。是一种非饱和非线性激活函数。相较于f(x)=tanh(x)和sigmoid函数:f(x)=(1+e^-x)^-1,这两种饱和非线性激活函数而言,SGD梯度下降的时间更快。
②Dropout
它做的就是以0.5的概率将每个隐层神经元的输出设置为零。以这种方式”droppedout”的神经元既不参与前向传播,也不参与反向传播。所以每次提出一个输入,该神经网络就尝试一个不同的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。前两个全连接层使用dropout。如果没有dropout,我们的网络会表现出大量的过拟合。dropout使收敛所需的迭代次数大致增加了一倍。
③数据扩充
一般的观点认为神经网络是靠足够多的数据训练出来的。增加海量的数据,在一定程度上能提升算法准确率。当数据有限时,可以通过已有的数据做一定的变换生成新的数据,进而扩充数据量。
本篇论文用到了三种数据变换方式:
A 平移变换(crop) 从256×256的图像中提取随机的224×224的小块:
四个边角和中心区域共5个
B反射变换(flip) 把A中的5张图进行水平反转
C光照和彩色变换
我们在遍及整个ImageNet训练集的RGB像素值集合中执行PCA。对于每个训练图像,我们成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0,标准差为0.1的高斯分布中提取的随机变量。这样一来,对于每个RGB图像像素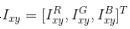 ,我们增加下面这项:
,我们增加下面这项: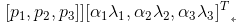
其中与分别是RGB像素值的3×3协方差矩阵的第i个特征向量与特征值,是前面提到的随机变量。每个对于特定训练图像的全部像素只提取一次,直到那个图像再次被用于训练,在那时它被重新提取。这个方案大致抓住了自然图像的一个重要属性,即,光照强度与颜色是变化的,而对象识别是不变的。
④重叠池化
一个pooling层可以被认为是由间隔s像素的pooling单元网格组成,每个网格总结出一个z×z大小的邻近关系,都位于pooling单元的中心位置。若设s=z,我们得到传统的局部pooling,正如常用于CNN中的那样。若设s
⑤LRN局部响应归一化
后来加入到DL研究工作中的大佬们说这个LRN设计有点搞笑,而且用处其实不大,所以我直接就忽略。
4、图片预处理
①大小归一化
将所有图片都归一化为256x256大小,至于为什么直接不归一化到224(227),请参考上文说的扩充数据集的操作。
②减去像素平均值
所有图片的每个像素值都减去所有训练集图片的平均值。