深度学习分布式方案(个人笔记)
深度学习分布式方案
【 关注三个问题】
1、将程序改为分布式,需要改动多少代码
2、分布式程序/任务要启动,程序是否复杂?
3、分布式模式提升了多少运行效率?
【分布式并行架构】
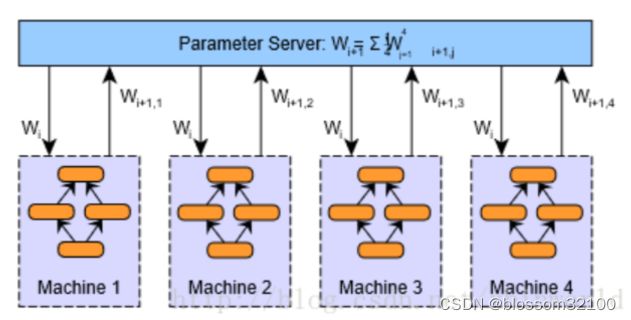
(一)PS架构(parameter server)
在Parameter server架构(PS架构)中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。
PS架构是深度学习最常采用的分布式训练架构。采用参数平均的数据并行模型的PS架构如下图所示:
(二)Ring-allreduce架构
1、算法论文
Bandwidth optimal all-reduce algorithms for clusters of workstations(Redirecting,17年,Baidu)
2、说明
在Ring-allreduce架构中,各个设备都是worker,并且形成一个环,如下图所示,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。其实这个过程需要两个部分:scatter-reduce和allgather,百度的教程对这个过程给出了详细的图文解释。百度开发了自己的allreduce框架,并将其用在了深度学习的分布式训练中。
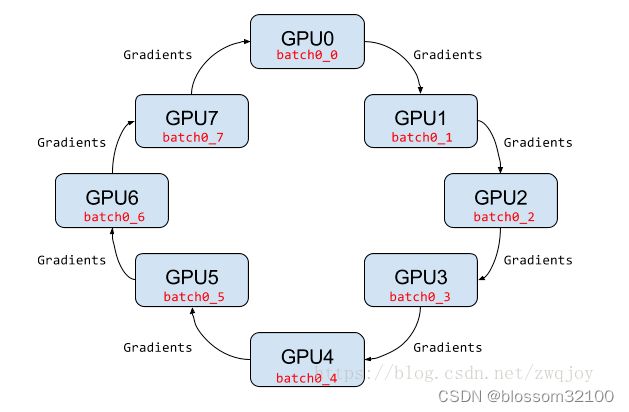
相比PS架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于GPUs数目(worker数)。
一般的多卡gpu训练有一个很大的缺陷,就是因为每次都需要一个gpu(cpu)从其他gpu上收集训练的梯度,然后将新的模型分发到其他gpu上。这样的模型最大的缺陷是gpu 0的通信时间是随着gpu卡数的增长而线性增长的。
所以就有了ring-allreduce,如下图:

该算法的基本思想是取消Reducer,让数据在gpu形成的环内流动,整个ring-allreduce的过程分为两大步,第一步是scatter-reduce,第二步是allgather。
先说第一步:首先我们有n块gpu,那么我们把每个gpu上的数据(均等的)划分成n块,并给每个gpu指定它的左右邻居(图中0号gpu的左邻居是4号,右邻居是1号,1号gpu的左邻居是0号,右邻居是2号……),然后开始执行n-1次操作,在第i次操作时,gpu j会将自己的第(j - i)%n块数据发送给gpu j+1,并接受gpu j-1的(j - i - 1)%n块数据。并将接受来的数据进行reduce操作,示意图如下:

当n-1次操作完成后,ring-allreduce的第一大步scatter-reduce就已经完成了,此时,第i块gpu的第(i + 1) % n块数据已经收集到了所有n块gpu的第(i + 1) % n块数据,那么,再进行一次allgather就可以完成算法了。
第二步allgather做的事情很简单,就是通过n-1次传递,把第i块gpu的第(i + 1) % n块数据传递给其他gpu,同样也是在i次传递时,gpu j把自己的第(j - i - 1)%n块数据发送给右邻居,接受左邻居的第(j - i - 2) % n数据,但是接受来的数据不需要像第一步那样做reduce,而是直接用接受来的数据代替自己的数据就好了。
最后每个gpu的数据就变成了这样:

首先是第一步,scatter-reduce:

然后是allgather的例子:

【分布式并行模型】
(一)数据并行(data parallelism)
1、概要
深度学习模型最常采用的分布式训练策略是数据并行,因为训练费时的一个重要原因是训练数据量很大。
不同的机器有同一个模型的多个副本,每个机器分配到不同的数据,然后将所有机器的计算结果按照某种方式合并。
数据并行化式的分布式训练在每个工作节点上都存储一个模型的备份,在各台机器上处理数据集的不同部分。数据并行化式训练方法需要组合各个工作节点的结果,并且在节点之间同步模型参数。
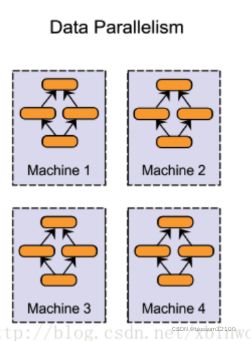
2、同步模型参数的方法
(1)参数平均(model averaging)
(1.1)权重更新方程:
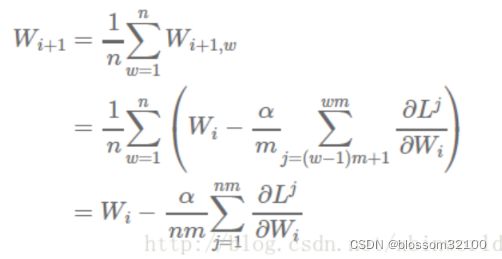
(1.2)训练过程:参数平均是最简单的一种数据并行化。若采用参数平均法,训练的过程如下所示:
-
基于模型的配置随机初始化网络模型参数
-
将当前这组参数分发到各个工作节点
-
在每个工作节点,用数据集的一部分数据进行训练
-
将各个工作节点的参数的均值作为全局参数值
-
若还有训练数据没有参与训练,则继续从第二步开始(所以一般是每个周期都执行step 2-4,直到所有周期完成)

(1.3)优点
(1.4)缺点
-
需要等所有节点的参数都更新完后,由server求更新后的参数均值,再广播给各个节点,各个节点才能做下一轮的计算。节点可能需要花比较多时间等待server的参数更新。
-
平均周期的设置可能不太好把控。最简单的办法就是简单地将每轮迭代之后的参数进行平均。一旦这样实现了,我们会发现此方法在计算之外的额外开销非常巨大;网络通信和同步的开销也许就能抵消额外机器带来的效率收益。因此,参数平均法通常有一个大于1的平均周期averaging period(就每个节点的minibatch而言)。如果求均值周期太长,那么每个节点得到的局部参数更多样化,求均值之后的模型效果非常差。随着平均的周期延长,模型的准确率则随之下降。
-
网络的开销会比较大,因为每个周期都需要在server和worker中间交换两次参数。进行两次全参数的数据传输。
(2)异步随机梯度下降(Asynchronous SGD)
(2.1)权重更新方程:
(2.2)训练过程
每个节点计算完梯度后,就发给server进行梯度更新。所以server的梯度更新不需要等所有节点都计算完。
(2.3)优点
相比参数平均的方案,各个worker减少了等待server更新参数的时间
(2.4)缺点:
出现梯度过时的情况。计算梯度(更新量)需要消耗时间。当某个节点算完了梯度值并且将其与全局参数向量合并时,全局参数可能已经被刷新了多次。严重的梯度值过时会明显减慢网络模型的收敛速度,甚至完全停止了收敛。
(2.5)变种
异步随机梯度下降方法还有多种形式的变种,但采取了各种策略来减弱梯度过时所造成的影响,同时保持集群的高可用率。解决梯度值过时的方法包括以下几种:
-
基于梯度值的过时量,对每次更新?Wi,j 分别缩放λ的值
-
采用‘软’的同步策略soft synchronization([19])
-
使用同步策略来限制过时量。例如,[20]提到的系统在必要时会延迟速度较快的节点,以保证最大的过时量控制在某个阈值以下。事实上一般现在采用bounded delay策略更多,见[1],给定一个t参数,要求t轮之前旧的参数更新必须全完成才能开始当前轮次的参数更新。
所有这些方法相比简单的异步SGD算法都本证明能提升收敛的性能。尤其是前两条方法效果更为显著。
(二)模型并行(model parallelism)
1、概要
所谓模型并行指的是将模型部署到很多设备上(设备可能分布在不同机器上,下同)运行,比如多个机器的GPUs。当神经网络模型很大时,由于显存限制,它是难以在跑在单个GPU上,这个时候就需要模型并行。比如Google的神经机器翻译系统,其可能采用深度LSTM模型,如下图所示,此时模型的不同部分需要分散到许多设备上进行并行训练。深度学习模型一般包含很多层,如果要采用模型并行策略,一般需要将不同的层运行在不同的设备上,但是实际上层与层之间的运行是存在约束的:前向运算时,后面的层需要等待前面层的输出作为输入,而在反向传播时,前面的层又要受限于后面层的计算结果。所以除非模型本身很大,一般不会采用模型并行,因为模型层与层之间存在串行逻辑。但是如果模型本身存在一些可以并行的单元,那么也是可以利用模型并行来提升训练速度,比如GoogLeNet的Inception模块。

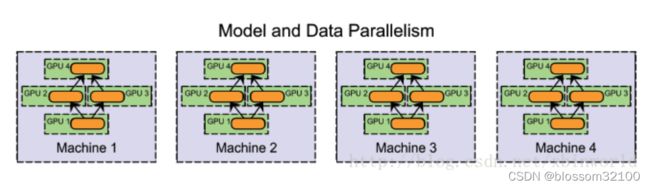
(三)混合并行(hybrid parallelism)
1、说明:在一个集群中,既有模型并行,又有数据并行,例如,可以在同一台机器上采用模型并行化(在GPU之间切分模型),在机器之间采用数据并行化。
【pytorch特有的分布式方案】
方案对比
(一)torch.nn.DataParallel(仅GPU)
1、并行方案:数据并行
2、使用说明:
DataParallel 可以帮助我们(使用单进程控)将模型和数据加载到多个 GPU 中,控制数据在 GPU 之间的流动,协同不同 GPU 上的模型进行并行训练(细粒度的方法有 scatter,gather 等等)。
更建议用torch.nn.parallel.DistributedDataParallel。
DataParallel 使用起来非常方便,我们只需要用 DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总:
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
值得注意的是,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理。DataParallel 并行训练部分主要与如下代码段有关:
# main.py
import torch
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()在使用时,使用 python 执行即可:
python main.py
在 ImageNet 上的完整训练代码,请点击Github。
(二)torch.nn.parallel.DistributedDataParallel(仅GPU)
(三)torch.distributed (应该CPU和GPU都支持)
※ CPU方案详见:https://github.com/huochaitiantang/pytorch-distribute/blob/master/train_mnist.py
1、概要:在 pytorch 1.0 之后,官方终于对分布式的常用方法进行了封装,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了.
torch.distributed 并行训练部分主要与如下代码段有关:
# main.py
import torch
import argparse
import torch.distributed as dist
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()在使用时,调用 torch.distributed.launch 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
在 ImageNet 上的完整训练代码,请点击Github。
(四)torch.distributed+torch.multiprocessing
添加 multiprocessing 后并行训练部分主要与如下代码段有关:
# main.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
mp.spawn(main_worker, nprocs=4, args=(4, myargs))
def main_worker(proc, nprocs, args):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()在使用时,直接使用 python 运行就可以了:
python main.py
在 ImageNet 上的完整训练代码,请点击Github。
(五)Apex
Apex 是 NVIDIA 开源的用于混合精度训练和分布式训练库。Apex 对混合精度训练的过程进行了封装,改两三行配置就可以进行混合精度的训练,从而大幅度降低显存占用,节约运算时间。此外,Apex 也提供了对分布式训练的封装,针对 NVIDIA 的 NCCL 通信库进行了优化。
在混合精度训练上,Apex 的封装十分优雅。直接使用 amp.initialize 包装模型和优化器,apex 就会自动帮助我们管理模型参数和优化器的精度了,根据精度需求不同可以传入其他配置参数。
from apex import amp model, optimizer = amp.initialize(model, optimizer)
在分布式训练的封装上,Apex 在胶水层的改动并不大,主要是优化了 NCCL 的通信。因此,大部分代码仍与 torch.distributed 保持一致。使用的时候只需要将 torch.nn.parallel.DistributedDataParallel 替换为 apex.parallel.DistributedDataParallel 用于包装模型。在 API 层面,相对于 torch.distributed ,它可以自动管理一些参数(可以少传一点):
from apex.parallel import DistributedDataParallel model = DistributedDataParallel(model) # # torch.distributed # model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank]) # model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)
在正向传播计算 loss 时,Apex 需要使用 amp.scale_loss 包装,用于根据 loss 值自动对精度进行缩放:
with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward()
汇总一下,Apex 的并行训练部分主要与如下代码段有关:
# main.py
import torch
import argparse
import torch.distributed as dist
from apex.parallel import DistributedDataParallel
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model, optimizer = amp.initialize(model, optimizer)
model = DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()在使用时,调用 torch.distributed.launch 启动器启动:
UDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
在 ImageNet 上的完整训练代码,请点击Github。
(七)Slurm
(八)分布式Slurm
【TensorFlow特有的分布式方案】
一、TensorFlow自带(好像官方文档提及的分布式方案都是基于GPU集群的)
(一)概要
1、官方文档:https://www.tensorflow.org/guide/distributed_training
2、开发单位:Google
3、分布式架构:PS架构(parameter server)
4、支持的计算方式:单机单卡(GPU)、单机多卡(GPU)、多机多卡(GPU)
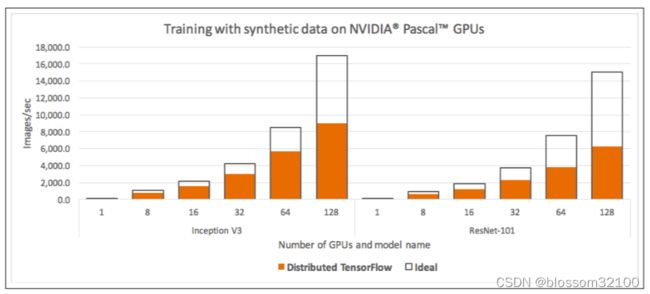
5、效率:
不同模型的效率提升不同,这与模型结构有关。Inception V3 与ResNet-101提升了90%,而VGG-16提升了68%。
Horovod achieves 90% scaling efficiency for both Inception V3 and ResNet-101, and 68% scaling efficiency for VGG-16.
4、分布式模式
(1)MirroredStrategy:支持单机多卡,仅支持GPU。
(2)TPUStrategy:支持多TPU计算(Tensor Processing Units,谷歌为神经网络构建一个专用集成电路(ASIC))——张量处理器,支持谷歌云(对TPU并不熟悉)
(3)MultiWorkerMirroredStrategy:支持多机多卡,仅支持GPU。
(4)ParameterServerStrategy:通用的数据并行分布式方案,多机,ps架构,支持CPU(不确定是否支持GPU)。异步并行。
(5)CentralStorageStrategy:异步并行,仅支持GPU?
(6)Default Strategy:实际上等同于无分布式操作的状态
(7)OneDeviceStrategy:单机单卡,仅支持GPU。
(二)优缺点
1、优点
TensorFlow本身自带的,无需另外安装配置其他框架/工具。
2、缺点
(1)概念多,学习曲线陡峭
tensorflow的集群采用的是parameter server架构,因此引入了比较多复杂概念,罗列如下
-
server
-
client
-
master
-
cluster
-
parameter server
-
worker
-
job
-
task
-
replica_device_setter
-
master service
-
worker service
-
clone
涉及到的函数
-
tf.train.Server
-
tf.train.Supervisor
-
tf.train.SessionManager
-
tf.train.ClusterSpec
-
tf.train.replica_device_setter
-
tf.train.MonitoredTrainingSession
-
tf.train.MonitoredSession
-
tf.train.SingularMonitoredSession
-
tf.train.Scaffold
-
tf.train.SessionCreator
-
tf.train.ChiefSessionCreator
-
tf.train.WorkerSessionCreator
server,client,master,master service,worker service,clone,session之间的关系也较为复杂。 大致是,在client中创建server实例,session与server一一对应,server内含master service和worker service两个服务,master service负责与外界通讯,比如sess.run一般都是告诉server的master service要开始工作了,server的master service通知同一个server的worker service去干活,worker service调动GPU运算,完成后,返回结果给master service,做权值更新,如果是多机多卡的分布式,parameter server与master service之间做梯度传递和权值同步。 stackoverflow.com/questions/3…
(2)修改的代码量大
如果想把单机单卡的模型,移植到多机多卡,涉及的代码量是以天记的,慢的话甚至需要一周。
(3) 需要多台机子跑不同的脚本
tensorflow集群是采用parameter server架构的,要想跑多机多卡的集群,每个机子都要启动一个client,即跑一个脚本,来启动训练,机子多了工作量就变得很大。
需要用户在客户端显示指定集群信息,另外需要手动拉起ps, worker等task. 对资源管理和使用上有诸多不便。
(4)ps和worker的比例不好选取
tensorflow集群要将服务器分为ps和worker两种job类型,ps设置多少性能最近并没有确定的计算公式。
(5)性能损失较多
3、方案优缺点:
【支持多种深度学习框架的分布式方案】
一、Horovod(支持GPU与CPU集群)
(一)概要
1、官方文档:https://github.com/horovod/horovod;论文:https://arxiv.org/abs/1802.05799
2、开发单位:Uber
3、分布式架构:ring-allreduce(同步模型参数的方法: allreduce + allgather)
4、分布式并行模型:数据并行(同步更新)
5、支持的深度学习框架:TensorFlow, Keras, PyTorch, Apache MXNet
6、集群的处理器要求:GPU集群、CPU集群
7、对其他工具的支持:支持spark、docker
8、支持的网络类型:RDMA (RoCE、InfiniBand)、TCP
Horovod 是 Uber 开源的深度学习工具,它的发展吸取了 Facebook "Training ImageNet In 1 Hour" 与百度 "Ring Allreduce" 的优点,可以无缝与 PyTorch/Tensorflow 等深度学习框架结合,实现并行训练。
(二)horovod with pytorch
(官方给出的案例都是基于GPU)
1、官方文档:https://github.com/horovod/horovod/blob/master/docs/pytorch.rst
2、示例
在 API 层面,Horovod 和 torch.distributed 十分相似。在 mpirun 的基础上,Horovod 提供了自己封装的 horovodrun 作为启动器。
与 torch.distributed.launch 相似,我们只需要编写一份代码,horovodrun 启动器就会自动将其分配给 ![[公式]](https://camo.githubusercontent.com/35075d8337bbd8a196eadad28b23ecb9bb873544cb2158a55dad73484585a161/68747470733a2f2f7777772e7a686968752e636f6d2f6571756174696f6e3f7465783d6e) 个进程,分别在 ![[公式]](https://camo.githubusercontent.com/35075d8337bbd8a196eadad28b23ecb9bb873544cb2158a55dad73484585a161/68747470733a2f2f7777772e7a686968752e636f6d2f6571756174696f6e3f7465783d6e) 个 GPU 上运行。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 注入 hvd,我们可以这样获得当前进程的 index:
import horovod.torch as hvd hvd.local_rank()
与 init_process_group 相似,Horovod 使用 init 设置GPU 之间通信使用的后端和端口:
hvd.init()
接着,使用 DistributedSampler 对数据集进行划分。如此前我们介绍的那样,它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
之后,使用 broadcast_parameters 包装模型参数,将模型参数从编号为 root_rank 的 GPU 复制到所有其他 GPU 中:
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
然后,使用 DistributedOptimizer 包装优化器。它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值:
hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=hvd.Compression.fp16)
最后,把数据加载到当前 GPU 中。在编写代码时,我们只需要关注正常进行正向传播和反向传播:
torch.cuda.set_device(args.local_rank)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()汇总一下,Horovod 的并行训练部分主要与如下代码段有关:
# main.py
import torch
import horovod.torch as hvd
hvd.init()
torch.cuda.set_device(hvd.local_rank())
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
# 使用 DistributedOptimizer 包装优化器。它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# 使用 broadcast_parameters 包装模型参数,将模型参数从编号为 root_rank 的 GPU 复制到所有其他 GPU 中
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()在使用时,调用 horovodrun 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 horovodrun -np 4 -H localhost:4 --verbose python main.py
在 ImageNet 上的完整训练代码,请点击Github。
(三)horovod with TensorFlow
(官方给出的案例都是基于GPU)
1、官方文档:https://github.com/horovod/horovod/blob/master/docs/tensorflow.rst
2、示例
TensorFlow v1 Example (see the examples directory for full training examples):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)TensorFlow v2 Example (from the MNIST example):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if gpus:
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
# Build model and dataset
dataset = ...
model = ...
loss = tf.losses.SparseCategoricalCrossentropy()
opt = tf.optimizers.Adam(0.001 * hvd.size())
checkpoint_dir = './checkpoints'
checkpoint = tf.train.Checkpoint(model=model, optimizer=opt)
@tf.function
def training_step(images, labels, first_batch):
with tf.GradientTape() as tape:
probs = mnist_model(images, training=True)
loss_value = loss(labels, probs)
# Horovod: add Horovod Distributed GradientTape.
tape = hvd.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, mnist_model.trainable_variables)
opt.apply_gradients(zip(grads, mnist_model.trainable_variables))
# Horovod: broadcast initial variable states from rank 0 to all other processes.
# This is necessary to ensure consistent initialization of all workers when
# training is started with random weights or restored from a checkpoint.
#
# Note: broadcast should be done after the first gradient step to ensure optimizer
# initialization.
if first_batch:
hvd.broadcast_variables(mnist_model.variables, root_rank=0)
hvd.broadcast_variables(opt.variables(), root_rank=0)
return loss_value
# Horovod: adjust number of steps based on number of GPUs.
for batch, (images, labels) in enumerate(dataset.take(10000 // hvd.size())):
loss_value = training_step(images, labels, batch == 0)
if batch % 10 == 0 and hvd.local_rank() == 0:
print('Step #%d\tLoss: %.6f' % (batch, loss_value))
# Horovod: save checkpoints only on worker 0 to prevent other workers from
# corrupting it.
if hvd.rank() == 0:
checkpoint.save(checkpoint_dir)(四)运行horovod(GPU集群)
-
To run on a machine with 4 GPUs:
$ horovodrun -np 4 -H localhost:4 python train.py
-
To run on 4 machines with 4 GPUs each:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
-
run training with 8 GPUs on two machines (4 GPUs each)
$ horovodrun -np 8 -H hostname1:4,hostname2:4 python train.py
(五)horovod with MPI(CPU集群)
1、官方文档:https://github.com/horovod/horovod/blob/master/docs/mpi.rst
2、相关说明:MPI(Message Passing Interface) 是一种可以支持点对点和广播的通信协议,具体实现的库有很多,使用比较流行的包括 Open Mpi, Intel MPI 等等。这里的MPI指的是Open Mpi(官网:Open MPI: Open Source High Performance Computing)。horovod通过mpi,可以实现在CPU集群的分布式计算。
3、通过MPI执行horovod脚本(建议用RDMA网络协议,官方文档中提到TCP协议下性能较差。)
(1)Run on a machine with 4 CPUs
mpirun -np 4 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
python train.py
(2)Run on 4 machines with 4 CPUs
mpirun -np 16 \
-H server1:4,server2:4,server3:4,server4:4 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
python train.py
(六)优缺点
1、优点(主要与ps架构进行对比)
(1)训练时间将与集群中的GPU数量无关。
相比常用的Parameter Server 架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。训练时间将与集群中的GPU数量无关。
(2)不存在PS和worker的比例选取的问题。
因为Ring-allreduce架构各个节点之间只与相邻的两个节点通信,并不需要参数服务器,所有节点都参与计算也参与存储。所以,也不存在PS和worker的比例选取的问题。
(3)单机版本到多机版本的代码量修改不大。
Horovod把训练脚本从单机版本改到多机版本,涉及修改的代码量也不大,大概只需要添加10行左右的代码。并且,horovod只是需要改动必要改动的,不涉及parameter server架构的device设置等,繁琐的操作。
以下是将一个只支持单机单卡的训练脚本修改为支持多机多卡的训练脚本的示例(以tensorflow为例,只需添加10行左右的代码),主要分为6步:
# 初始化horovod hvd.init() # 一个GPU与一个进程绑定 config = tf.ConfigProto() config.gpu_options.visible_device_list = str(hvd.local_rank()) # 根据总GPU数量放大学习率,因为BatchSize会根据GPU数量放大,所以学习率也应该放大 opt = tf.train.AdagradOptimizer(0.01 * hvd.size()) # 使用hvd.DistributedOptimizer封装原有的optimizer。分布式训练涉及到梯度同步,每一个GPU的梯度计算仍然由原有的optimizer 计算,只是梯度同步由hvd.DistributedOptimizer负责。 opt = hvd.DistributedOptimizer(opt) # 广播初始变量值到所有进程,主要为了确保所有进程变量初始值相同 hooks = [hvd.BroadcastGlobalVariablesHook(0)] # 只在worker 0上保存checkpoint,防止checkpoint保存错乱。 checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
(4)只需要在一台机上执行启动训练的命令。
无论是单机多卡,还是多机多卡,只需要在一台机子上执行一次启动训练的命令即可,其他机horovod会用MPI启动进程和传递数据。
在单机4卡的机上起训练,只需执行以下命令:
horovodrun -np 4 -H localhost:4 python train.py
在4机,每机4卡的机子上起训练,只需在一个机子上执行以下命令即可:
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
注意无论是单机多卡,还是多机多卡,都只需在一个机子上执行一次命令即可,其他机horovod会启动相关进程进行数据传递。
(4)可支持常用的深度学习框架。
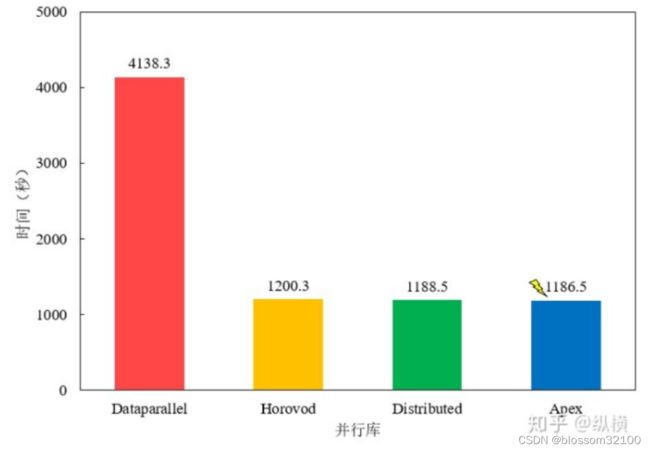
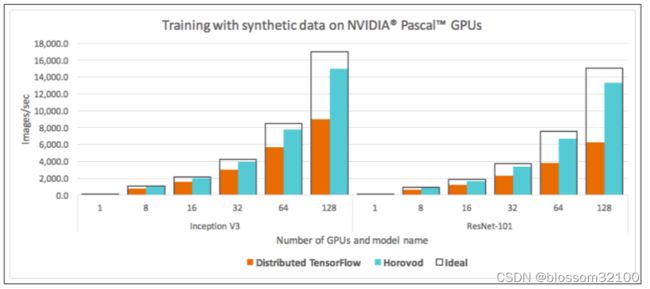
(5)相比于TensorFlow自身的分布式方案,horovod性能更好。
2、缺点
(待补充)
二、BytePS
(一)概要
1、官方文档:https://github.com/bytedance/byteps
2、开发单位:字节跳动
3、支持的深度学习框架:TensorFlow, Keras, PyTorch, MXNet
4、集群的处理器要求:目前仅支持GPU集群(依赖CUDA和NCCL)
BytePS does not support pure CPU training for now. One reason is that the cheap PS assumption of BytePS do not hold for CPU training. Consequently, you need CUDA and NCCL to build and run BytePS.
5、分布式架构:详见“A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters:https://www.usenix.org/system/files/osdi20-jiang.pdf”。
支持的网络类型:RDMA 、TCP
6、调用方式与horovod接近,都很简便。
If your tasks only rely on Horovod's allreduce and broadcast, you should be able to switch to BytePS in 1 minute. Simply replace
import horovod.tensorflow as hvdbyimport byteps.tensorflow as bps, and then replace allhvdin your code bybps. If your code invokeshvd.allreducedirectly, you should also replace it bybps.push_pull
7、官方给的性能数据
BERT-large training, BytePS can achieve ~90% scaling efficiency with 256 GPUs (see below), which is much higher than Horovod+NCCL. In certain scenarios, BytePS can double the training speed compared with Horovod+NCCL.

(二)bytePS with TensorFlow
1、示例(github地址:https://github.com/bytedance/byteps/blob/master/example/tensorflow/tensorflow_mnist.py)
import os
import errno
import byteps.tensorflow as bps
import numpy as np
from tensorflow import keras
import tensorflow as tf
layers = tf.layers
tf.logging.set_verbosity(tf.logging.INFO)
# model define
def conv_model(feature, target, mode):
"""2-layer convolution model."""
...
logits = layers.dense(h_fc1, 10, activation=None)
loss = tf.losses.softmax_cross_entropy(target, logits)
return tf.argmax(logits, 1), loss
def train_input_generator(x_train, y_train, batch_size=64):
# ....
def main(_):
# BytePS: initialize BytePS.
bps.init()
# Keras automatically creates a cache directory in ~/.keras/datasets for
# storing the downloaded MNIST data. This creates a race
# condition among the workers that share the same filesystem. If the
# directory already exists by the time this worker gets around to creating
# it, ignore the resulting exception and continue.
cache_dir = os.path.join(os.path.expanduser('~'), '.keras', 'datasets')
.....
# Download and load MNIST dataset.
(x_train, y_train), (x_test, y_test) = \
keras.datasets.mnist.load_data('MNIST-data-%d' % bps.rank())
x_train = np.reshape(x_train, (-1, 784)) / 255.0
x_test = np.reshape(x_test, (-1, 784)) / 255.0
# Build model...
with tf.name_scope('input'):
image = tf.placeholder(tf.float32, [None, 784], name='image')
label = tf.placeholder(tf.float32, [None], name='label')
predict, loss = conv_model(image, label, tf.estimator.ModeKeys.TRAIN)
# BytePS: adjust learning rate based on number of GPUs.
opt = tf.train.RMSPropOptimizer(0.001 * bps.size())
# BytePS: add BytePS Distributed Optimizer.
opt = bps.DistributedOptimizer(opt)
global_step = tf.train.get_or_create_global_step()
train_op = opt.minimize(loss, global_step=global_step)
hooks = [
# BytePS: BroadcastGlobalVariablesHook broadcasts initial variable states
# from rank 0 to all other processes. This is necessary to ensure consistent
# initialization of all workers when training is started with random weights
# or restored from a checkpoint.
bps.BroadcastGlobalVariablesHook(0),
# BytePS: adjust number of steps based on number of GPUs.
tf.train.StopAtStepHook(last_step=200000 // bps.size()),
tf.train.LoggingTensorHook(tensors={'step': global_step, 'loss': loss},
every_n_iter=10),
]
# BytePS: pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(bps.local_rank())
# BytePS: save checkpoints only on worker 0 to prevent other workers from
# corrupting them.
checkpoint_dir = './checkpoints' if bps.rank() == 0 else None
training_batch_generator = train_input_generator(x_train,
y_train, batch_size=100)
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
hooks=hooks,
config=config) as mon_sess:
while not mon_sess.should_stop():
# Run a training step synchronously.
image_, label_ = next(training_batch_generator)
mon_sess.run(train_op, feed_dict={image: image_, label: label_})
if __name__ == "__main__":
tf.app.run()【深度学习框架+spark】
(一)sparktorch+pyspark(pytorch+spark)
1、官方文档:https://github.com/dmmiller612/sparktorch
2、开发单位:Yahoo
2、方案特点:模型定义用pytorch,相比不用spark的方案,模型定义不变,但数据处理以及模型调用的方式不同。
3、调用说明
(1)数据输入
A. InputMode.TENSORFLOW - leverages TensorFlow's built-in APIs to read data files directly from HDFS.
B. InputMode.SPARK - sends Spark RDD data to the TensorFlow nodes via a TFNode.DataFeed class. Note that we leverage the Hadoop Input/Output Format to access TFRecords on HDFS.
(二)TensorFlowOnSpark(TensorFlow+spark)
1、官方文档:https://github.com/yahoo/TensorFlowOnSpark
2、分布式方案:既可支持CPU集群,也可以支持GPU集群。
【传统机器学习分布式方案】
(一)spark-sklearn(sklearn+spark)
1、官方文档:spark-sklearn · PyPI
2、分布式方案:因为绝大多数传统机器学习算法的模型计算量都比较小,所以一般即使单机CPU也不会有太大的性能问题。如果确实要考虑分布式方案,可以考虑建议通过spark-sklearn的Python库,打通python的sklearn与spark。
3、示例
from sklearn import svm, datasets
from spark_sklearn import GridSearchCV
iris = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svr = svm.SVC(gamma='auto')
clf = GridSearchCV(sc, svr, parameters)
clf.fit(iris.data, iris.target)
(二)Spark MLlib
1、官方文档:Clustering - RDD-based API - Spark 3.2.0 Documentation
2、分布式方案:直接用Spark MLlib(支持Scala、Java、Python),但MLlib的模型可能没那么丰富,造成模型可选范围变小。
3、示例
from numpy import array
from math import sqrt
from pyspark.mllib.clustering import KMeans, KMeansModel
# Load and parse the data
data = sc.textFile("data/mllib/kmeans_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 2, maxIterations=10, initializationMode="random")
# Evaluate clustering by computing Within Set Sum of Squared Errors
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
WSSSE = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x + y)
print("Within Set Sum of Squared Error = " + str(WSSSE))
# Save and load model
clusters.save(sc, "target/org/apache/spark/PythonKMeansExample/KMeansModel")
sameModel = KMeansModel.load(sc, "target/org/apache/spark/PythonKMeansExample/KMeansModel")【参考】
[1] 分布式机器学习系统笔记:分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD_Bin 的专栏-CSDN博客_模型并行
[2] https://github.com/tczhangzhi/pytorch-distributed
[3] A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters:https://www.usenix.org/system/files/osdi20-jiang.pdf