【推荐算法】双塔模型介绍
双塔模型的结构不仅在推荐领域的召回和粗排环节中被广泛采用;而且在其它领域,如文档检索、问答系统等都有它的应用场景。
我们常说的双塔模型的结构,并不是一个固定不变的网络,而是一种模型构造思路:即把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。
一、双塔模型结构
双塔模型的结构如下图所示:这种 “物品侧模型 + 用户侧模型 + 互操作层” 的模型结构,我们可以把它们统称为“双塔模型”结构。
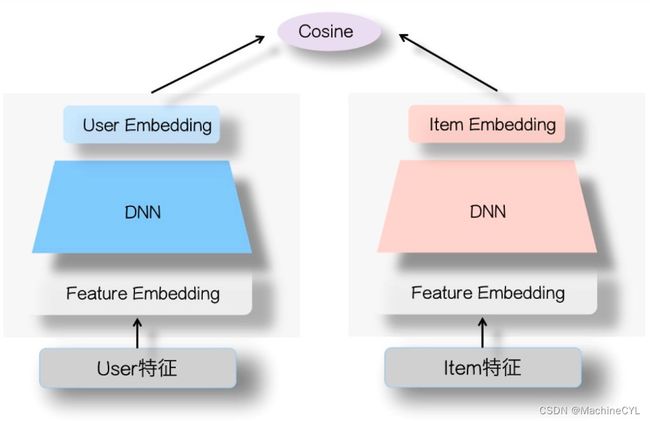
双塔模型最大的特点就是 “User和Item是独立的两个子网络”,左侧是User塔,右侧是Item塔。这两个塔的参数不共享,他们分别输出User Embedding 和 Item Embedding。然后将2个 Embedding 作为互操作层的输入,计算它们的相似度。
计算相识度的方式也有多种方案,如用简单的点积操作、Cosine相似度计算,或者是用比较复杂的 MLP 结构。
二、双塔模型的优缺点
-
优点一:容易部署上线、服务实时性高
因为 User 和 Item 的 Embedding 我们可以在离线训练的时候获取到,并且会提前存入到数据库中。所以使用双塔模型时,我们不用把整个模型都部署上线,只需要从数据库中检索对应的Embedding,在线上进行互操作就可以了。如果这个互操作是点积操作,那么这个实现可以说没有任何难度。实际应用中非常容易落地,这也正是双塔模型在业界巨大的优势所在。
-
缺点一:模型使用的特征缺少交叉组合类特征
一般在做推荐模型的时候,会有些特征工程方面的工作,比如设计一些User侧特征和Item侧特征的组合特征,一般而言,这种来自User和Item两侧的组合特征是非常有效的判断信号。但是,如果我们采用双塔结构,这种人工筛选的,来自两侧的特征组合就不能用了,因为它既不能放在User侧,也不能放在Item侧,这是特征工程方面带来的效果损失。当然,我个人认为,这个问题不是最突出的,应该有办法绕过去,或者模型能力强,把组合特征拆成两个分离的特征,各自放在对应的两侧,可以让模型去捕获这种组合特征。
-
缺点二:User 和 Item 发生特征交叉的时机太晚,可能会丢失一些细节特征
如果是精排阶段的DNN模型,来自User侧和Item侧的特征,在很早的阶段,比如第一层MLP隐层,两者之间就可以做细粒度的特征交互。但是,对于双塔模型,两侧特征什么时候才能发生交互?只有在User Embedding和Item Embedding发生内积的时候,两者才发生交互,而此时的User Embedding和Item Embedding,已经是两侧特征经过多次非线性变换,糅合出的一个表征用户或者Item的整体Embedding了,细粒度的特征此时估计已经面目模糊了,就是说,两侧特征交互的时机太晚了。我们知道,User侧和Item侧特征之间的交互,是非常有效的判断信号。而很多领域的实验已经证明,双塔这种过晚的两侧特征交互,相对在网络结构浅层就进行特征交互,会带来效果的损失。这个问题比较严重。
三、双塔模型训练负例如何选择
我们训练精排模型的时候(假设是优化点击目标),一般会用“用户点击”实例做为正例,“曝光未点击”实例做为负例,来训练模型,基本都是这么做的。现在,模型召回以及粗排,也需要训练模型,需要定义正例和负例。一般正例,也都是用“用户点击”实例做为正例;但是怎么选择负例,这里面有不少学问。

如上图,如果我们仍然用“曝光未点击”实例做为召回和粗排的负例训练数据,会发现这个训练集合,只是全局物料库的一小部分,它的分布和全局物料库以及各路召回结果数据,这两个召回和粗排模型面临的实际输入数据,分布差异比较大,所以根据这种负例训练召回和粗排模型,效果如何就带有疑问。
为了解决这个问题,在召回或者粗排模型训练的时候,应该调整下负例的选择策略,使得它尽量能够和模型输入的数据分布保持一致。这里总结下可能的做法:
- 选择1:曝光未点击数据
这就是上面说的导致Sample Selection Bias问题的原因。我们的经验是,这个数据还是需要的,只是要和其它类型的负例选择方法,按照一定比例进行混合,来缓解Sample Selection Bias问题。当然,有些结论貌似是不用这个数据,所以用还是不用,可能跟应用场景有关。
- 选择2:全局随机选择负例
就是说在原始的全局物料库里,随机抽取做为召回或者粗排的负例。这也是一种做法,Youtube DNN双塔模型就是这么做的。从道理上讲,这个肯定是完全符合输入数据的分布一致性的,但是,一般这么选择的负例,因为和正例差异太大,导致模型太好区分正例和负例,所以模型能学到多少知识是成问题的。
- 选择3:Batch内随机选择负例
就是说只包含正例,训练的时候,在Batch内,选择除了正例之外的其它Item,做为负例。这个本质上是:给定用户,在所有其它用户的正例里进行随机选择,构造负例。它在一定程度上,也可以解决Sample Selection Bias问题。比如Google的双塔召回模型,就是用的这种负例方法。
- 选择4:曝光数据随机选择负例
就是说,在给所有用户曝光的数据里,随机选择做为负例。这个我们测试过,在某些场景下是有效的。
- 选择5:基于Popularity随机选择负例
这种方法的做法是:全局随机选择,但是越是流行的Item,越大概率会被选择作为负例。目前不少研究证明了,负例采取Popularity-based方法,对于效果有明显的正面影响。它隐含的假设是:如果一个例子越流行,那么它没有被用户点过看过,说明更大概率,对当前的用户来说,它是一个真实的负例。同时,这种方法还会打压流行Item,增加模型个性化程度。
- 选择6:基于Hard选择负例
它是选择那些比较难的例子,做为负例。因为难区分的例子,很明显给模型带来的loss和信息含量比价多,所以从道理上讲是很合理的。但是怎样算是难的例子,可能有不同的做法,有些还跟应用有关。比如Airbnb,还有不少工作,都是在想办法筛选Hard负例上。
这边是借鉴大佬的文章提到的方法: SENet双塔模型:在推荐领域召回粗排的应用及其它 - 知乎
他们在模型召回阶段的经验是:比如在19年年中左右,我们尝试过选择1+选择3的混合方法,就是一定比例的“曝光未点击”和一定比例的类似Batch内随机的方法构造负例,当时在FM召回取得了明显的效果提升。
双塔模型原理到这里就介绍完了,想看代码可以访问我的另外一篇文章:
【推荐算法】双塔模型代码实现_MachineCYL的博客-CSDN博客
参考链接
SENet双塔模型:在推荐领域召回粗排的应用及其它 - 知乎
深度盘点:基于双塔结构的推荐模型总结 - 知乎