图片补全《Globally and locally consistent image completion》
图像补全 – Globally and Locally Consistent Image Completion
-
文章来源:SIGGRAPH 2017
-
下载链接:http://iizuka.cs.tsukuba.ac.jp/projects/completion/en/
-
应用场景: 图像补全(Image completion),目标移除(Object remove)
-
数据集: CelebA人脸数据集
-
目标: 进行图像填充,填充任意形状的缺失区域来完成任意分辨率的图像。
-
网络构造:
补全网络: 完成网络是完全卷积的,用来修复图像。
全局上下文鉴别器: 以完整的图像作为输入,识别场景的全局一致性。
局部上下文鉴别器: 只关注完成区域周围的一个小区域,以判断更详细的外观质量。
对图像完成网络进行训练,以欺骗两个上下文鉴别器网络,这要求它生成在总体一致性和细节方面与真实图像无法区分的图像。 -
项目代码 GitHub 地址:https://github.com/otenim/GLCIC-PyTorch
-
网络架构:
此网络由一个完成网络和两个辅助上下文鉴别器网络组成,这两个鉴别器网络只用于训练完成网络,在测试过程中不使用。全局鉴别器网络以整个图像为输入,而局部鉴别器网络仅以完成区域周围的一小块区域作为输入。训练两个鉴别器网络以确定图像是真实的还是由完成网络完成的,而生成网络被训练来欺骗两个鉴别器网络,使生成的图像达到真实图像的水平。

-
补全网络结构
补全网络先利用卷积降低图片的分辨率然后利用去卷积增大图片的分辨率得到修复结果。为了保证生成区域尽量不模糊,文中降低分辨率的操作是使用strided convolution 的方式进行的,而且只用了两次,将图片的size 变为原来的四分之一。同时在中间层还使用了空洞卷积来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
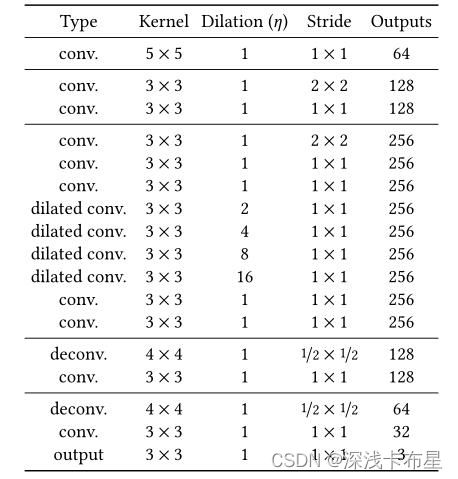
-
内容鉴别器
这些网络基于卷积神经网络,将图像压缩成小特征向量。 网络的输出通过连接层融合在一起,连接层预测出图像是真实的概率的一个连续值。网络结构如下:
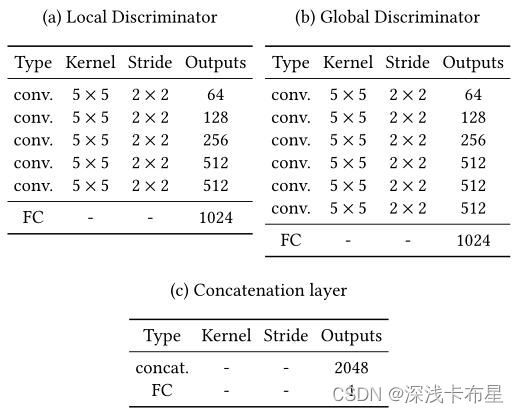
-
优点:
复原能力强,且可以生成眼睛、鼻子等细节结构,但是需要在相关数据集上进行fine-tuning -
不足之处:
- 如果缺失面积较大,则难以补全。
- 如果缺失区域在图像的边界,则处理不好。
- 不能生成复杂性的结构性纹理。
- 模型性能依赖于训练集素材,如果训练集中有一张和测试集相似图片,则效果会好一些
-
部分代码注释:
train.py:
import json
import os
import argparse
from torch.utils.data import DataLoader
from torch.optim import Adadelta, Adam
from torch.nn import BCELoss, DataParallel
from torchvision.utils import save_image
from PIL import Image
import torchvision.transforms as transforms
import torch
import numpy as np
from tqdm import tqdm
from models import CompletionNetwork, ContextDiscriminator
from datasets import ImageDataset
from losses import completion_network_loss
from utils import (
gen_input_mask,
gen_hole_area,
crop,
sample_random_batch,
poisson_blend,
)
parser = argparse.ArgumentParser()
parser.add_argument('data_dir')
parser.add_argument('result_dir')
parser.add_argument('--data_parallel', action='store_true') # 启用此标志后,模型将以数据并行方式进行训练。如果N个 GPU 可用,则在训练期间使用 N 个 GPU
parser.add_argument('--recursive_search', action='store_true', default=False)
parser.add_argument('--init_model_cn', type=str, default=None) # 预训练生成器的路径,用作其初始权重
parser.add_argument('--init_model_cd', type=str, default=None) # 预训练判别器的路径,用作其初始权重
parser.add_argument('--steps_1', type=int, default=90000) # 第 1 阶段的训练步数(默认值:90,000)
parser.add_argument('--steps_2', type=int, default=10000)
parser.add_argument('--steps_3', type=int, default=400000)
parser.add_argument('--snaperiod_1', type=int, default=10000) # 第 1 阶段的快照周期(默认值:10,000)
parser.add_argument('--snaperiod_2', type=int, default=2000)
parser.add_argument('--snaperiod_3', type=int, default=10000)
parser.add_argument('--max_holes', type=int, default=1) # 随机生成并应用于每个输入图像的最大孔数(默认值:1)
parser.add_argument('--hole_min_w', type=int, default=48) # 孔的最小宽度(默认值:48)
parser.add_argument('--hole_max_w', type=int, default=96)
parser.add_argument('--hole_min_h', type=int, default=48) # 孔的最小高度(默认值:48)
parser.add_argument('--hole_max_h', type=int, default=96)
parser.add_argument('--cn_input_size', type=int, default=160) # 生成器(完成网络)的输入大小
parser.add_argument('--ld_input_size', type=int, default=96) # local判别器的输入大小
parser.add_argument('--bsize', type=int, default=16) # 批量大小(默认值:16)。强烈建议 bsize >= 96
parser.add_argument('--bdivs', type=int, default=1) # 将单个 batch size = bsize 的训练步骤分成bdivs个batch size = bsize / bdivs的步骤
parser.add_argument('--num_test_completions', type=int, default=16)
parser.add_argument('--mpv', nargs=3, type=float, default=None)
parser.add_argument('--alpha', type=float, default=4e-4)
parser.add_argument('--arc', type=str, choices=['celeba', 'places2'], default='celeba')
def main(args):
# ================================================
# Preparation
# ================================================
if not torch.cuda.is_available(): # 判断GPU是否可用
raise Exception('At least one gpu must be available.')
gpu = torch.device('cuda:0') # 通过torch.device("cuda:0)指定cuda:0设备
# create result directory (if necessary)
# 常用os方式,如果没有某个文件夹,直接创建这个文件夹
if not os.path.exists(args.result_dir):
os.makedirs(args.result_dir) # 如果不存在,需要递归创建的目录
for phase in ['phase_1', 'phase_2', 'phase_3']:
if not os.path.exists(os.path.join(args.result_dir, phase)): # args.result_dir\phase是否存在
os.makedirs(os.path.join(args.result_dir, phase))
# load dataset
trnsfm = transforms.Compose([ # torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起
transforms.Resize(args.cn_input_size),
transforms.RandomCrop((args.cn_input_size, args.cn_input_size)), # 在一个随机的位置进行裁剪
transforms.ToTensor(), # ToTensor()把灰度范围从(0,255)变换到(0,1)【将数据除以255,Normalize()把(0,1)变换到(-1,1)
])
print('loading dataset... (it may take a few minutes)')
train_dset = ImageDataset(
os.path.join(args.data_dir, 'train'),
trnsfm,
recursive_search=args.recursive_search)
test_dset = ImageDataset(
os.path.join(args.data_dir, 'test'),
trnsfm,
recursive_search=args.recursive_search)
train_loader = DataLoader(
train_dset,
batch_size=(args.bsize // args.bdivs),
shuffle=True)
# compute mpv (mean pixel value) of training dataset
if args.mpv is None:
mpv = np.zeros(shape=(3,))
pbar = tqdm( # tqdm: Python的进度条库
total=len(train_dset.imgpaths),
desc='computing mean pixel value of training dataset...')
for imgpath in train_dset.imgpaths:
img = Image.open(imgpath) # 读取图片
x = np.array(img) / 255. # image格式转换成array格式
mpv += x.mean(axis=(0, 1)) # 先按照1,再按照0求平均
pbar.update()
mpv /= len(train_dset.imgpaths)
pbar.close()
else:
mpv = np.array(args.mpv)
# save training config
mpv_json = []
for i in range(3):
mpv_json.append(float(mpv[i]))
args_dict = vars(args)
args_dict['mpv'] = mpv_json
with open(os.path.join(
args.result_dir, 'config.json'),
mode='w') as f:
json.dump(args_dict, f)
# make mpv & alpha tensors
mpv = torch.tensor(
mpv.reshape(1, 3, 1, 1),
dtype=torch.float32).to(gpu)
alpha = torch.tensor(
args.alpha,
dtype=torch.float32).to(gpu)
# ================================================
# Training Phase 1
# ================================================
# load completion network
model_cn = CompletionNetwork()
if args.init_model_cn is not None:
model_cn.load_state_dict(torch.load(
args.init_model_cn,
map_location='cpu'))
if args.data_parallel:
model_cn = DataParallel(model_cn) # 对于多GPU训练,需要一种在不同GPU之间对模型和数据进行切分和调度的方法
model_cn = model_cn.to(gpu) # 移动到gpu上
opt_cn = Adadelta(model_cn.parameters()) # 优化算法Adadelta一种自适应学习率方法,旨在减少其过激的、单调递减的学习率。
# training
cnt_bdivs = 0
pbar = tqdm(total=args.steps_1)
while pbar.n < args.steps_1:
for x in train_loader:
# forward
x = x.to(gpu)
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2])),
max_holes=args.max_holes,
).to(gpu)
x_mask = x - x * mask + mpv * mask # x * (1 - mask) 去除mask的区域
input = torch.cat((x_mask, mask), dim=1)
output = model_cn(input)
loss = completion_network_loss(x, output, mask)
# backward
loss.backward()
cnt_bdivs += 1
if cnt_bdivs >= args.bdivs:
cnt_bdivs = 0
# optimize
opt_cn.step() # 梯度优化
opt_cn.zero_grad() # 梯度清零
pbar.set_description('phase 1 | train loss: %.5f' % loss.cpu())
pbar.update()
# test
if pbar.n % args.snaperiod_1 == 0:
model_cn.eval()
with torch.no_grad():
x = sample_random_batch(
test_dset,
batch_size=args.num_test_completions).to(gpu)
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2])),
max_holes=args.max_holes).to(gpu)
x_mask = x - x * mask + mpv * mask
input = torch.cat((x_mask, mask), dim=1)
output = model_cn(input)
completed = poisson_blend(x_mask, output, mask)
imgs = torch.cat((
x.cpu(),
x_mask.cpu(),
completed.cpu()), dim=0)
imgpath = os.path.join(
args.result_dir,
'phase_1',
'step%d.png' % pbar.n)
model_cn_path = os.path.join(
args.result_dir,
'phase_1',
'model_cn_step%d' % pbar.n)
save_image(imgs, imgpath, nrow=len(x))
if args.data_parallel:
torch.save(
model_cn.module.state_dict(),
model_cn_path)
else:
torch.save(
model_cn.state_dict(),
model_cn_path)
model_cn.train()
if pbar.n >= args.steps_1:
break
pbar.close()
# ================================================
# Training Phase 2
# ================================================
# load context discriminator
model_cd = ContextDiscriminator(
local_input_shape=(3, args.ld_input_size, args.ld_input_size),
global_input_shape=(3, args.cn_input_size, args.cn_input_size),
arc=args.arc)
if args.init_model_cd is not None:
model_cd.load_state_dict(torch.load(
args.init_model_cd,
map_location='cpu'))
if args.data_parallel:
model_cd = DataParallel(model_cd)
model_cd = model_cd.to(gpu)
opt_cd = Adadelta(model_cd.parameters())
bceloss = BCELoss()
# training
cnt_bdivs = 0
pbar = tqdm(total=args.steps_2)
while pbar.n < args.steps_2:
for x in train_loader:
# fake forward
x = x.to(gpu)
hole_area_fake = gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2]))
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=hole_area_fake,
max_holes=args.max_holes).to(gpu)
fake = torch.zeros((len(x), 1)).to(gpu) # 创建张量并将它们移动到GPU
x_mask = x - x * mask + mpv * mask
input_cn = torch.cat((x_mask, mask), dim=1)
output_cn = model_cn(input_cn) # 补全网络生成的全局图像
input_gd_fake = output_cn.detach() # detach():bp的时候,只更新B中参数的值,而不更新A中的参数值,【A网络的输出被喂给B网络作为输入
input_ld_fake = crop(input_gd_fake, hole_area_fake) # 补全网络生成的局部图像
output_fake = model_cd((
input_ld_fake.to(gpu),
input_gd_fake.to(gpu))) # 判别器输出的对补全图片的评分
loss_fake = bceloss(output_fake, fake)
# real forward
hole_area_real = gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2]))
real = torch.ones((len(x), 1)).to(gpu)
input_gd_real = x # 原始图像
input_ld_real = crop(input_gd_real, hole_area_real) # 去掉mask的原始图像
output_real = model_cd((input_ld_real, input_gd_real)) # 判别器输出的对原始图像的评分
loss_real = bceloss(output_real, real)
# reduce
loss = (loss_fake + loss_real) / 2.
# backward
loss.backward()
cnt_bdivs += 1
if cnt_bdivs >= args.bdivs:
cnt_bdivs = 0
# optimize
opt_cd.step()
opt_cd.zero_grad()
pbar.set_description('phase 2 | train loss: %.5f' % loss.cpu())
pbar.update()
# test
if pbar.n % args.snaperiod_2 == 0:
model_cn.eval()
with torch.no_grad():
x = sample_random_batch(
test_dset,
batch_size=args.num_test_completions).to(gpu)
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2])),
max_holes=args.max_holes).to(gpu)
x_mask = x - x * mask + mpv * mask
input = torch.cat((x_mask, mask), dim=1)
output = model_cn(input)
completed = poisson_blend(x_mask, output, mask)
imgs = torch.cat((
x.cpu(),
x_mask.cpu(),
completed.cpu()), dim=0)
imgpath = os.path.join(
args.result_dir,
'phase_2',
'step%d.png' % pbar.n)
model_cd_path = os.path.join(
args.result_dir,
'phase_2',
'model_cd_step%d' % pbar.n)
save_image(imgs, imgpath, nrow=len(x))
if args.data_parallel:
torch.save(
model_cd.module.state_dict(),
model_cd_path)
else:
torch.save(
model_cd.state_dict(),
model_cd_path)
model_cn.train()
if pbar.n >= args.steps_2:
break
pbar.close()
# ================================================
# Training Phase 3
# ================================================
cnt_bdivs = 0
pbar = tqdm(total=args.steps_3)
while pbar.n < args.steps_3:
for x in train_loader:
# forward model_cd
x = x.to(gpu)
hole_area_fake = gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2]))
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=hole_area_fake,
max_holes=args.max_holes).to(gpu)
# fake forward
fake = torch.zeros((len(x), 1)).to(gpu)
x_mask = x - x * mask + mpv * mask
input_cn = torch.cat((x_mask, mask), dim=1)
output_cn = model_cn(input_cn) # 补全网络生成的全局图像
input_gd_fake = output_cn.detach()
input_ld_fake = crop(input_gd_fake, hole_area_fake) # 补全网络生成的局部图像
output_fake = model_cd((input_ld_fake, input_gd_fake)) # 判别器输出的对补全图像的评分
loss_cd_fake = bceloss(output_fake, fake) # 训练判别器
# real forward
hole_area_real = gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2]))
real = torch.ones((len(x), 1)).to(gpu)
input_gd_real = x
input_ld_real = crop(input_gd_real, hole_area_real)
output_real = model_cd((input_ld_real, input_gd_real))
loss_cd_real = bceloss(output_real, real) # 训练判别器
# reduce
loss_cd = (loss_cd_fake + loss_cd_real) * alpha / 2.
# backward model_cd
loss_cd.backward()
cnt_bdivs += 1
if cnt_bdivs >= args.bdivs:
# optimize
opt_cd.step()
opt_cd.zero_grad()
# forward model_cn
loss_cn_1 = completion_network_loss(x, output_cn, mask)
input_gd_fake = output_cn
input_ld_fake = crop(input_gd_fake, hole_area_fake)
output_fake = model_cd((input_ld_fake, (input_gd_fake)))
loss_cn_2 = bceloss(output_fake, real) # 训练生成器,使之生成的结果接近 1
# reduce
loss_cn = (loss_cn_1 + alpha * loss_cn_2) / 2.
# backward model_cn
loss_cn.backward()
if cnt_bdivs >= args.bdivs:
cnt_bdivs = 0
# optimize
opt_cn.step()
opt_cn.zero_grad()
pbar.set_description(
'phase 3 | train loss (cd): %.5f (cn): %.5f' % (
loss_cd.cpu(),
loss_cn.cpu()))
pbar.update()
# test
if pbar.n % args.snaperiod_3 == 0:
model_cn.eval()
with torch.no_grad():
x = sample_random_batch(
test_dset,
batch_size=args.num_test_completions).to(gpu)
mask = gen_input_mask(
shape=(x.shape[0], 1, x.shape[2], x.shape[3]),
hole_size=(
(args.hole_min_w, args.hole_max_w),
(args.hole_min_h, args.hole_max_h)),
hole_area=gen_hole_area(
(args.ld_input_size, args.ld_input_size),
(x.shape[3], x.shape[2])),
max_holes=args.max_holes).to(gpu)
x_mask = x - x * mask + mpv * mask
input = torch.cat((x_mask, mask), dim=1)
output = model_cn(input)
completed = poisson_blend(x_mask, output, mask)
imgs = torch.cat((
x.cpu(),
x_mask.cpu(),
completed.cpu()), dim=0)
imgpath = os.path.join(
args.result_dir,
'phase_3',
'step%d.png' % pbar.n)
model_cn_path = os.path.join(
args.result_dir,
'phase_3',
'model_cn_step%d' % pbar.n)
model_cd_path = os.path.join(
args.result_dir,
'phase_3',
'model_cd_step%d' % pbar.n)
save_image(imgs, imgpath, nrow=len(x))
if args.data_parallel:
torch.save(
model_cn.module.state_dict(),
model_cn_path)
torch.save(
model_cd.module.state_dict(),
model_cd_path)
else:
torch.save(
model_cn.state_dict(),
model_cn_path)
torch.save(
model_cd.state_dict(),
model_cd_path)
model_cn.train()
if pbar.n >= args.steps_3:
break
pbar.close()
if __name__ == '__main__':
args = parser.parse_args()
args.data_dir = os.path.expanduser(args.data_dir)
args.result_dir = os.path.expanduser(args.result_dir)
if args.init_model_cn is not None: # 预训练生成器的路径
args.init_model_cn = os.path.expanduser(args.init_model_cn)
if args.init_model_cd is not None: # 预训练鉴别器的路径
args.init_model_cd = os.path.expanduser(args.init_model_cd)
main(args)
参考链接:
https://www.jianshu.com/p/12da271c8bf8
https://blog.csdn.net/m0_56937307/article/details/123736653
https://www.sohu.com/a/163252003_775742
https://www.jianshu.com/p/a736feb0a6ef