卷积神经网络系列以及代码实现继往开来的backbone(Lenet,AlexNet,ZFNet,VggNet,gooleNet,DenseNet,DPN双路网络)
继往开来的backbone(卷积神经网络系列)
(Lenet,AlexNet,ZFNet,VggNet,gooleNet,DenseNet,DPN双路网络)
LeNet
首先看一下网络图
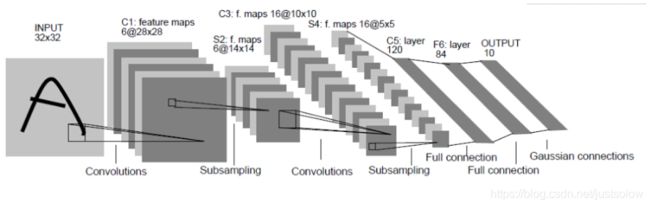

这时候的卷积神经网络是没有padding的。

keras实现代码
def LeNet():
model = Sequential()
model.add(Conv2D(32,(5,5),strides=(1,1),input_shape=(28,28,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(5,5),strides=(1,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(100,activation='relu'))
model.add(Dense(10,activation='softmax'))
return model
可以看得出来leNet的网络比较简单,所以也不算是真正意义上的卷积神经网络。
AlexNet
AlexNet算是真正意义上的卷积神经网络。

首先输入图像统一为256x256,经过随机裁剪以后得到尺寸224x224x3的图像,然后经过padding得到227x227的图像才算是最终的输入。

最后再提醒一下,这是一个分支的示例,最终的通道数需要倍增才是AlexNet的输入。
激活函数同意采用了Relu作为激活函数。
Local Response Normalization(局部响应归一化)也就是一个类似BN层的归一化操作,我感觉没必要掌握,知道BN就好。
还有最后一点就是引进了Dropout。
代码
def AlexNet(self):
model = Sequential()
# input_shape = (64,64, self.config.channles)
input_shape = (self.config.normal_size, self.config.normal_size, self.config.channles)
model.add(Convolution2D(96, (11, 11), input_shape=input_shape,strides=(4, 4), padding='valid',activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))#26*26
model.add(Convolution2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Convolution2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(Convolution2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(Convolution2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(self.config.classNumber, activation='softmax'))
# model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
ZFNet
总的来说ZFNet就是在AlexNet的基础上对卷积层进行可视化,然后修改了一点网路参数而已。
因此作者针对第一个问题将AlexNet的第一层的卷积核大小从11改成7。同时针对第二个问题将第一个卷积层的卷积核滑动步长从4改成2。
同时,ZFNet将AlexNet的第3,4,5卷积层变为384,384,256。然后就完了,可以看到ZFNet并没有特别出彩的地方,因此这一年的ImageNet分类竞赛算是比较平静的一届。
def ZF_Net():
model = Sequential()
model.add(Conv2D(96,(7,7),strides=(2,2),input_shape=(224,224,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(2,2),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
VGGNet

因为当时VGG使用的是与训练的方式,即先训练一部分小网络,然后确保这部分网络收敛之后再在这个基础上逐渐加深。并且当网络在D阶段(VGG-16)效果是最好的,E阶段(VGG-19)次之。VGG-16指的是网络的卷积层和全连接层的层数为16。接下来我们仔细看一下VGG-16的结构图:
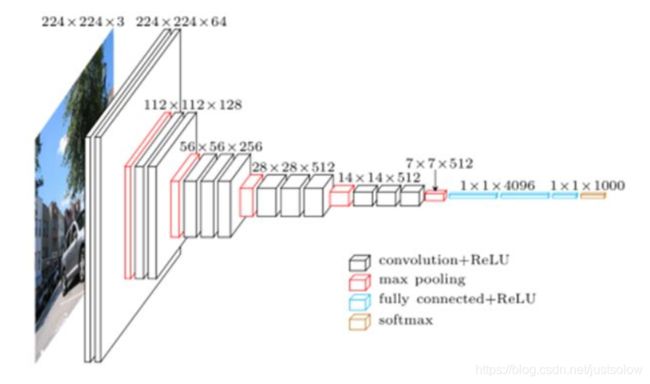

感受野的计算公式两种方式,计算出来的结果都是一样的。
代码
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
goolenet
1、提出Inception模块。
2、使用辅助Loss。
3、全连接层用简单的平均池化代替。
网络太复杂就不贴了,有兴趣的自己去查查看,不过我感觉没什么必要。
其实GooleNet又叫做Inceptionv1,所以我们另起一篇博客介绍一下Inception系列。
ResNet
见我的这篇博客
讲的很详细,从另一个角度分析resnet为什么有作用。
DenseNet
作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入。由于网络中存在着大量密集的连接,作者将这种网络结构称为DenseNet。
具体见我的这篇博客
Resnext
其实就是在resnet的基础上实现了inception+resnet。
详见我的这篇博文
DPN双路网络

DPN实际是ResNeXt 和DenseNet 的合体,在图d中,左边为DenseNet,右边为ResNeXt (看上去更像ResNet,但实际是经过group操作的)。在图d中,左右两边进行相加操作,然后进行33卷积,11维度变换,然后进行通道分裂,左边与左边的原输入进行合并操作,右边与右边的原输入进行相加操作,如此,就形成了一个block。(原输入可以是一开始进入网络的输入,也可以是上一个阶段的输入。)
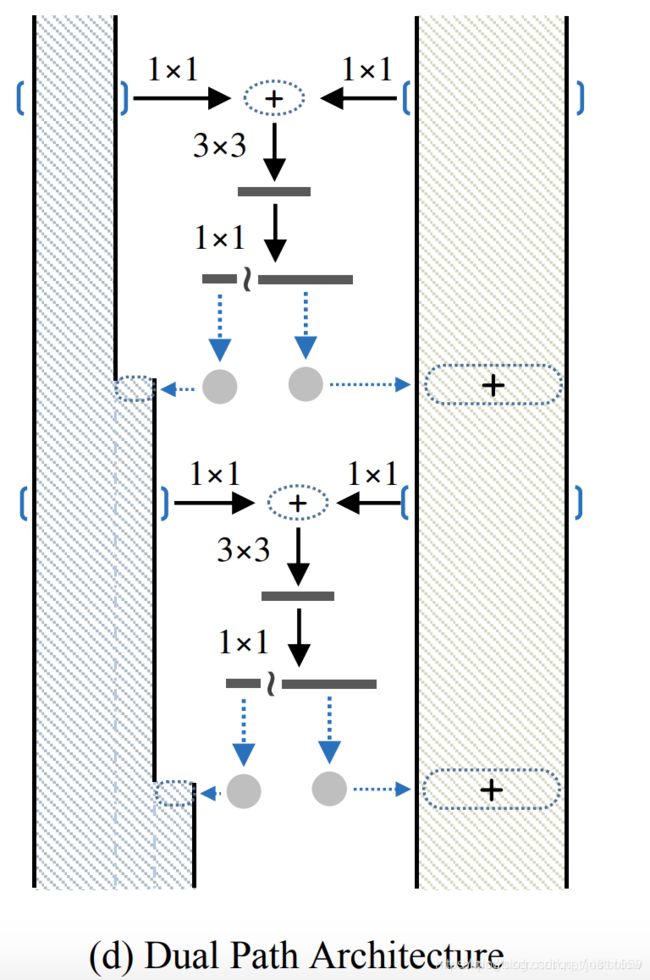
由于DPN比较复杂,所以工程意义不大,就不详细介绍了。