【论文阅读】PointNet++论文解读以及代码分析(超全)
PointNet系列
第一章 【论文阅读】PointNet论文解读
第二章 【论文阅读】PointNet++论文解读以及代码分析(超全)
文章目录
- PointNet系列
- 前言
- 1. PointNet的不足与PointNet++的解决方法
-
- 1.1 PointNet存在的问题
- 1.2 PointNet++采用的解决方法
- 2. PointNet++网络结构详解
-
- 2.1 改进特征提取方法
- 2.2 对于非均匀点云的处理方法
- 2.3 分类网络
- 2.4 分割网络
- 3. PointNet++代码分析
-
- 3.1 分类网络
- 3.2 分割网络
- 3.3 FP层代码
- 3.4 SA层代码
- 3.5 采样和分组代码
- 4. 总结
前言
上一篇文章主要介绍了点云处理的经典之作PointNet的整体思想和框架,本篇文章将介绍其团队基于PointNet改进的PointNet++。文章核心的一点就是提出了多层次特征提取结构。具体而言就是在输入点集中利用farthest point sampling选择一些点作为中心点,然后围绕每个中心点选择周围的点组成一个区域,将每个区域作为PointNet的一个输入样本,这样就得到了一组该区域的特征。之后中心点不变,扩大区域,把上一步得到的那些特征作为输入再送入PointNet,循环反复,不断提取局部特征,扩大局部范围,最后得到一组全局的特征,然后进行分类或者分割。文章还提出了多尺度方法解决样本中点云密度不均匀的问题,增加模型的鲁棒性。
PointNet++代码
1. PointNet的不足与PointNet++的解决方法
1.1 PointNet存在的问题
PointNet存在的一个缺点就是无法获取局部特征。在PointNet中,要不就是对单个点进行 1 × 1 1×1 1×1卷积操作,要不就是对所有点进行最大池化获得全局特征,虽然每个点都映射到了高维空间中,但还是丢失了很多局部信息,如下图:

从很多实验结果可以看出,PointNet对于场景的分割效果十分一般,所以提取局部区域特征就成了改进的一个方向。为了解决这一问题,PointNet++提出了首先选取一些比较重要的点作为每个局部区域的中心点,然后再中心点的周围选取k个近邻点,再将k个近邻点作为一个局部点云丢入PointNet中提取特征。
1.2 PointNet++采用的解决方法
为了解决PointNet网络无法提取局部特征的问题,在PointNet++中,作者借鉴了CNN的多层感受野的思想。首先,在整个点云的局部采样并划分为具有重叠的局部区域,在局部区域中通过PointNet提取局部特征,然后扩大范围,在这些局部特征的基础行提取更高层次的特征,直到提取整个点云集的全局特征,整个过程和CNN网络提取特征的过程类似。
2. PointNet++网络结构详解

2.1 改进特征提取方法
PointNet++在PointNet的基础上加入了多层次结构,使得网络能够在越来越大的区域上提供更高级别的特征,每一次提取就称为set abstraction,主要包括3个部分:Sampling layer, Grouping layer and PointNet layer。
- Sample layer:使用最远点采样法(FPS)对输入点进行采样,选出若干个中心点。FPS算法是随机选取一个点,然后选择离这个点最远的点加入到结果集中,迭代这个过程,直到结果集中点的数量达到某个给定值。
- Grouping layer :在上一层提取出的中心点的某个范围内寻找最近的k近邻点组成一个group。
- PointNet layer:将k个区域通过小型PointNet网络得到的特征作为k个中心点的特征。

上图展示了set abstraction的过程。每一组set abstraction得到的中心点的特征向量集,会作为下一组set abstration的子集,随着层数加深,中心点的个数会越来越少,但是每一个中心点包含的信息会越来越多。在msg中,第一层set abstraction取中心点512个,半径分别为0.1、0.2、0.4,每个圈内的最大点数为16,32,128。
每一组SA的输入是 N × ( d × C ) N×(d×C) N×(d×C),其中 N N N是输入点数量, d d d是坐标维度, C C C是特征维度;输出是 N ′ × ( d × C ′ ) N^{'}×(d×C^{'}) N′×(d×C′),其中 N ′ N^{'} N′是输出点数量, d d d是坐标维度不变, C ′ C^{'} C′是新的特征维度。下面介绍每一层的具体实现过程。
1. Sample layer 使用farhest point sampling选择 N ′ N^{'} N′个点,相较于随机采样,该方法能够更好的覆盖整个点集,具体选择多少个中心点由人来指定。
2. Grouping layer 该层使用Ball query方法生成 N ′ N^{'} N′个局部区域,论文中这里有两个变量,一个是每个区域中点的数量K,另一个是球的半径。算法会在某个半径的球中找点,数量上限是K,球的半径和每个区域中点的数量都是人指定的。这一步也可以使用KNN方法,对结果影响不大。

3. PointNet layer 该层是对 N ′ N^{'} N′个局部区域提取到 N ′ N^{'} N′个局部特征,输入为 N ′ × K × ( d × C ) N^{'}×K×(d×C) N′×K×(d×C),输出是 N ′ × ( d × C ′ ) N^{'}×(d×C^{'}) N′×(d×C′)。需要注意,在输入到网络之前,会把区域中的点变成围绕中心点的相对坐标,作者认为这样可以获取点与点之间的关系(更类似于Batch Norm)。

SA网络解释:输入为 2 × 16384 × 3 2×16384×3 2×16384×3,表示BatchSize为2,16384个点,维度为3。 - SA1:输入为xyz,输出new_xyz, feature
- 对输入的xyz做permutation,然后使用farthest point sampling(FPS)寻找4096个中心点,这4096个 点就是new_xyz,作为下一层的输入。
- 对于new_xyz中的每个点,在给定的距离内寻找点(BallQuery),得到grouped_xyz,给定的距离不同,寻找到的点的数量不同,从而分成两条支路。
- 按照grouped_xyz的id对feature进行选取,在SA1中feature就是xyz,所以没有变化。
- 使用MLP对feature提取特征并做maxpooling得到高级特征。
- 对在BallQuery中不同距离下得到的高级特征进行concatenate操作,得到SA1的feature输出。
- SA2:输入SA1.new_xyz,SA1.feature,输出new_xyz,feature
- SA2的MLP的输入是由SA1.new_xyz和SA1.feature进行concatenate得到的。
- 所以不同于SA1的第四步,按照grouped_xyz的id选取的时concatenate后的feature,而不是xyz。
2.2 对于非均匀点云的处理方法
通过使用多层次结构提取局部特征,在点云的分类和分割效果有了一定的提升,但是其在点云缺失的鲁棒性上变得更差了。其原因在于激光收集点云数据的时候总是在近的地方密集,在远的地方稀疏。因此一旦缺失部分点云数据,网络的性能就会受到极大影响,见下图。

在论文中,作者给出了对比实验,可以看出当点云缺失个数达到20%时,PointNet++的性能还不如PointNet。因此,通过固定范围选取的固定个数的近邻点是不合适的,pointnet++提出了两个解决方案,多尺度分组(MSG)和多分辨率分组(MRG)。

1. Multi-scale grouping (MSG)
MSG方法如上图左,就是在每一个分组层都通过多个尺度(设置多个半径值)来确定每一个中心点的领域范围,每一个范围都经过PointNet提取特征,再将得到的多个范围的特征concatenate起来,得到一个多尺度的新特征。
2. Multi-resolution grouping (MRG)
在MSG方法中,每一个中心点都需要多个patch的选取和卷积,计算量大,所以提出了MRG方法。如上图右所示,新特征由两部分concatenate得到,左边特征向量是通过较低层即 L i − 1 L_{i-1} Li−1层经过PointNet提取得到,右边特征向量是对当前层中心点对应的patch进行PointNet得到。当点云密度不均时,可以通过判断当前patch的点云密度给予左右两个特征向量不同的权重。例如,当patch中密度过小,左边特征向量中包含的点更稀疏,容易受到抽样不足的影响,因此提高右边特征向量的权重。

作者在论文中给出了分类实验结果对比图(见上图),可以看出多尺度(MSG, MRG)和单一尺度(SSG)相比分类准确率没有什么提升,但当点云很稀疏的时候,使用MSG可以保持很好的robustness。random input dropout(DP)对于robustness也很大。
2.3 分类网络
分类网络比较简单,对于经过两次SA后得到的特征图经过一个PointNet提取全局特征然后通过全连接网络得到分类结果,见下图。
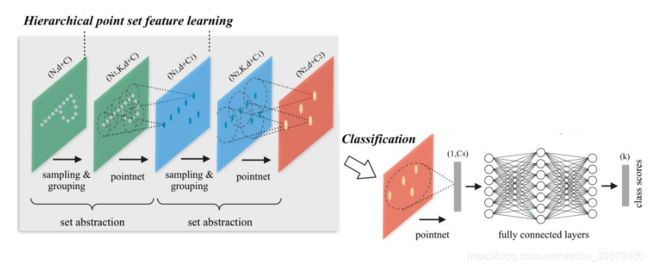
2.4 分割网络
分割网络较为复杂,需要获得所有原始点的点特征,作者采用基于距离插值的分层传播策略和跨层跳跃链接来实现。在某一层的特征传播过程中,从 N l × ( d + C ) N_{l}×(d + C) Nl×(d+C)向 N l − 1 N_{l-1} Nl−1个点传播特性,这里 N l − 1 N_{l-1} Nl−1和 N l N_{l} Nl是点集抽象层 l l l的输入和输出的点集数量,并且 N l ≤ N l − 1 N_{l} ≤ N_{l-1} Nl≤Nl−1。
这里大概可以这么理解,输入xyz和feature经过一个SA后得到了输出new_xyz和new_feature。在上采样过程(FP)中,要将得到的new_xyz和new_feature再反过来加在输入上,也就是下图所示的 N 1 × ( d + C 1 ) → S A → N 2 × ( d + C 2 ) → i n t e r p o l a t e → N 1 × ( d + C 2 + C 1 ) → u n i t p o i n t n e t → N 1 × ( d + C 3 ) N_{1}×(d + C_{1}) →SA→N_{2}×(d + C_{2})→interpolate→N_{1}×(d + C_{2}+C_{1})→unit pointnet→N_{1}×(d + C_{3}) N1×(d+C1)→SA→N2×(d+C2)→interpolate→N1×(d+C2+C1)→unitpointnet→N1×(d+C3)。

文章中通过k近邻法(KNN,默认p=2,k=3)来反向加权求平均实现特征传播,具体公式如下:

简单来说就是距离越远的点权重越小,下面给出Upsampling操作的计算过程,由几个FP子网络构成。
- FP1:输入SA2.new_xzy, SA2.feature, SA1.new_xzy, SA1.feature,输出feature。
- 对于SA1.new_xzy中每个点,寻找SA2.new_xzy中最近的3个点;
- 对于这3个点,记录id,计算距离,然后通过距离的倒数计算3个点各自的权重;
- 对这3个点的特征进行加权平均求取SA1.new_xyz中对应点的feaure;
- 得到的feature与SA1.feature进行concatenate操作;
- 通过MLP和MaxPooling得到FP1的输出feature,SA1.new_xyz中每个点都对应了一个新的feature。
- FP2
这样就得到了每个原始点的点特征,最后通过计算得到每个原始点对应的分类。
3. PointNet++代码分析
3.1 分类网络
首先来看分类网络的整体网络结构,以pointnet2_cls_msg为例。
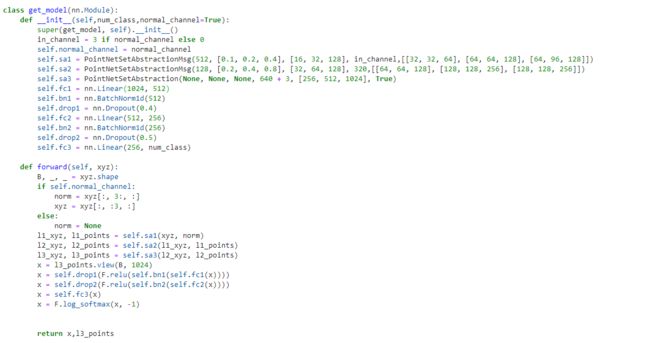
分类网络比较简单,首先是3个SA,前两个SA规定中心点分别为512和128,最后一个SA提取全局特征,得到结果为 ( B × 1024 ) (B×1024) (B×1024),其中B为batch size,然后使用4层全连接网络 ( 1024 → 512 → 256 → n u m c l a s s ) (1024→512→256→num_class) (1024→512→256→numclass)得到分类结果,这里要注意中间隐层采用了dropout增加robustness,最后通过log_softmax()计算出每个样本的预测值。
3.2 分割网络
分割网络的整体网络也是非常规整,以pointnet2_sem_seg_msg为例。
来反向加权求平均实现上采样特征传播。

3.4 SA层代码
下图展示了使用了MSG方法的SA层代码。

3.5 采样和分组代码

4. 总结
本文详细阐述了PointNet++的设计思路、网络结构以及对部分代码进行了解析。PointNet系列是近些年来所有点云分割网络的baseline,希望本篇文章能够对你理解PointNet++有所帮助。欢迎各位小伙伴一起交流学习!
Reference
PointNet++ 论文及代码解读
【3D计算机视觉】从PointNet到PointNet++理论及pytorch代码
论文笔记:PointNet++论文代码讨论
3D点云数据分析:pointNet++论文分析及阅读笔记
【代码阅读】PointNet++具体实现详解