灵魂三问:因果推断
■ 数万年前,人类意识到某些事情的变化,会导致另外一些事情的发生,这开启了人们对因果的直觉性思考,使人类创造出了有组织的社会,直至我们今天的科技文明。
■ 2000多年前,哲学家亚里士多德提出四因说,他认为:只有理解了事物产生的原因,即事物的本原,才能真正了解这个事物,开启了人们对因果的哲学辩论。
■ 500多年前,现代科学诞生,科学界开始了对因果观念的逻辑分析。
只是近一个世纪以来,科学家们信奉“相关关系不等于因果关系”这句统计论断,统计学的传统教育逐渐形成了讳忌讨论因果的局面。
直到图灵奖得主、推动机器进行概率推理的“贝叶斯网络之父” Judea Pearl打破禁忌。他对AI深陷概率关联泥潭进行尖锐批评,放弃了概率推理,转而支持因果推断理论,认为实现强AI的突破口就在于因果推断理论。
2021年瑞典皇家科学院将诺贝尔经济学奖颁发给了三位对因果推断理论做出杰出贡献的科学家,因果推断一时炙手可热。

本文和后续的系列文章,将通过回答在科学史和思想史中的灵魂三问:什么是因果推断?为什么研究因果推断?怎么进行因果推断研究?由浅入深解读因果推断。
01 什么是因果推断?
关于因果关系,在《牛津哲学词典》的定义是,“当一个事件的出现导致、产生或决定了另一个事件的出现,这两个事件之间的关系就被称为因果关系。例如,外面正在下雨,不带雨具出门会被淋湿衣服。下雨和淋湿衣服之间就是因果关系, 下雨是原因,淋湿衣服是结果。
因果推断是统计学和数据科学的核心问题之一,在一种现象已经发生的情况下,推出因果关系结论的过程,就是因果推断。它在生物医学、经济管理和社会科学中有都有广泛应用,可以揭示变量之间的因果关系,发现现象背后的深层原因,比如:吸烟是否致癌?社会招聘是否存在性别歧视?也可以估计定量的因果效应,分析当原因改变时结果变量的响应,以帮助人们更科学的做决策干预,比如:教育水平如何影响一个人未来的收入?比如一种药物会使得病人生存期延长多少?等等。
因果推断也被认为是人工智能领域的一次范式革命,是近年来该领域的研究热点之一。未来,能否让AI像人一样思考?强人工智能是否能实现?为AI模型赋予因果关系思维似乎成了解答这些问题的必要因素和必经之路。
02 为什么研究因果推断?
当前的机器学习主要利用数据中的统计相关性进行建模。相关性的主要来源有:因果(causation)、混淆(confounding)、样本选择偏差(selection bias),三类分别对应以下三种结构:

上图:相关性的三个来源。其中,T表示原因;Y表示结果;X表示混淆变量;S表示选择偏差。黑色实心箭头表示直接因果关系,灰色虚线箭头表示假性相关关系。
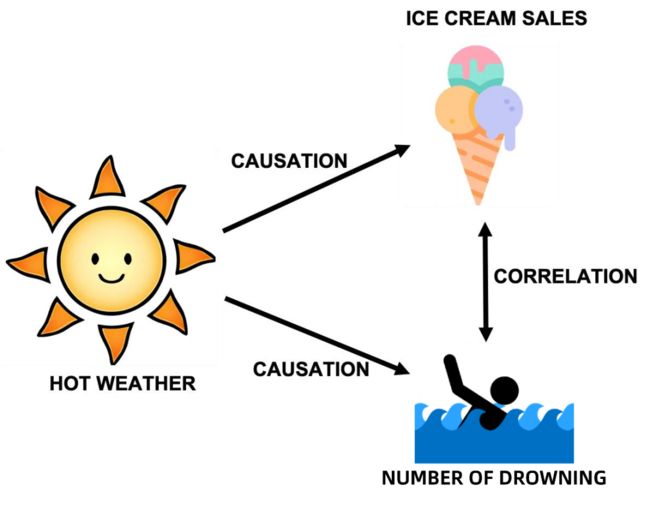
其中,只有由因果(causation)产生的相关,即因果关系,是一种稳定的机制,不随环境变化而变化;也只有这种稳定的结构是可解释的。例如,无论是在哪个国家,夏天时候天气变热(原因:T),会导致冰淇淋的数量(结果:Y)上升。
混淆(confounding)是指存在一个变量X,该变量构成了T和Y的共同原因,如果忽略了X的影响,那么T和Y之间存在假性相关关系:即T并非产生Y的直接原因。如果我们在夏天时候发现游泳溺水的人数增加,如果忽略了气温的影响,仅凭冰淇淋销量与溺水人数呈现出来的正向相关关系,则可能得出吃冰淇淋会导致游泳溺水的错误结论。
样本选择偏差(selection bias)也会产生相关性。当两个相互独立的变量T和Y产生了一个共同结果变量S,引入S则为T和Y之间打开了一条通路,从而误以为T和Y之间存在关联关系。例如,有些非常勤奋的人去参加了就业培训,同时因为他们的勤奋得到了非常好的工作,此时,如果只考虑这部分勤奋的人群,那么在样本选择偏差的背景下,会产生参加就业培训帮助人们得到了更好的工作;而现实的情况可能是就业培训对找工作并没有什么帮助。
大量研究表明:过于依赖统计相关的建模方式,存在着严重的理论缺陷:缺乏因果关系考虑,仅从数据中学习到的相关性可能是错误的。首先,利用相关性学习的模型,泛化能力和稳定性差,极易受到场景变化或数据中异常值的影响;再者,过度依赖数据拟合的机器学习模型就像是一个黑盒子,缺乏可解释性。
随着人工智能的应用从互联网领域向工业、医疗、金融等领域的拓展,人工智能技术的优化方向也逐渐开始从「性能驱动」转向「风险敏感」。在这样的背景下,缺乏稳定性和可解释性极大地限制了AI模型的落地。在机器学习模型中加入因果机制,似乎已经成为弥补机器学习理论缺陷,进一步发展人工智能技术的必经道路。因果关系的稳定性和可解释性,强大到可以让人们有足够的信心去做科学且安全的决策,进而提高效率、降低成本、防止损失。

工业界和学术界存在大量使用因果推断改进人工智能模型的研究和应用案例。例如,在传统的网络营销中,为了研究网页上【了解更多】按钮还是【获取方案】按钮更促进转化,我们需要进行严格的控制实验,通过A/B测试去测量各个元素的转化效果。这种方法往往受到很多现实因素的限制,且成本昂贵。然而,我们可以通过在现有数据上使用因果推断来实现该目标。
03 怎么进行因果推断研究?
当前有关因果推断的研究主要包括两个方向:一是因果发现(Causal Discovery),二是因果效应的估计(Causal Effect Estimation)。因果发现旨在从纷繁的数据中,挖掘出变量之间的因果关系,其本质是要找到用于描述变量间因果关系的图网络结构。因果效应估计主要研究原因变量对结果变量的影响程度,其本质是建立因果模型并输出对增量的预测值。
以电商平台中对商品进行动态调价的应用为例。平台上商品价格往往不是一成不变的,需要随产品生命周期和市场需求波动等动态变化,准确的定价往往对于完成销售及盈利目标等具有关键意义。
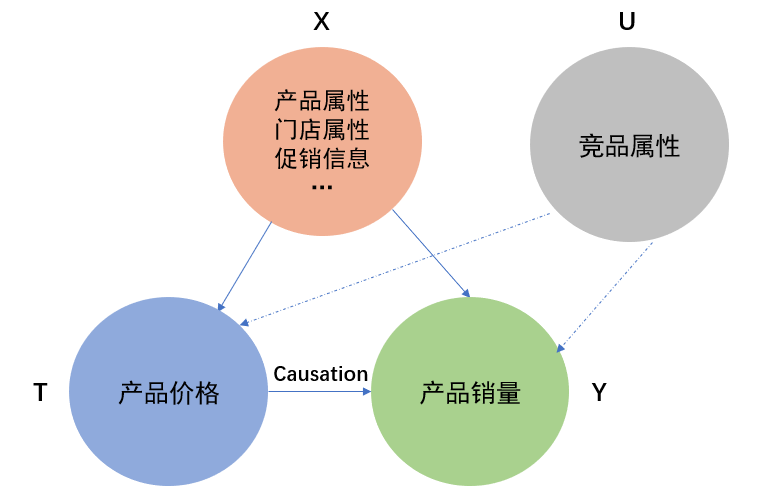
基于因果发现方法,可以从大量产品属性、店铺属性、促销日、商品价格、商品销量数据中挖掘出它们内在的因果关系。通过构建一张完备的因果图,定性地刻画不同变量之间的作用关系,从数据中挖掘出的本质规律,会帮助提供合理的定价决策方向。
为了进一步研究商品价格与销量之间的关系,我们以因果图为指导,使用因果效应估计方法,定量地确定出每家店铺中每一种商品的价格对销量的影响程度,用于制定精准的价格调整策略。
在现实生活中,人们通过行为干预(Intervention)认知因果。以冰淇淋的销量为例,虽然我们不能直接干预天气变化,但是我们可以通过选择在干旱地区,即那些即使在夏天也无人游泳的区域,比较冬天和夏天冰淇淋的销量,得出冰淇淋的销量会随着气温上升而增加的结论;同样,我们可以选择比较干旱地区和湿润地区的冰淇淋销量,得知冰淇淋销量的增加与溺水人数并无因果关系。这样的行为干预,直接表现为控制实验(Controlled Experiment)。严格的控制实验,已经成为了研究因果关系的经典方法。然而,因果革命还带来了另一个重要成果,即允许我们在不实际实施控制实验的情况下,仅仅从观测数据中进行因果发现,并对因果效应进行估计。
我们将在后续文章中,对如何利用观测数据进行因果发现和因果效应估计的工具和经典方法作出详细介绍。欢迎持续关注。
(本文首发于微信公众号:ML OR 智能决策。分享更多干货,欢迎交流~)