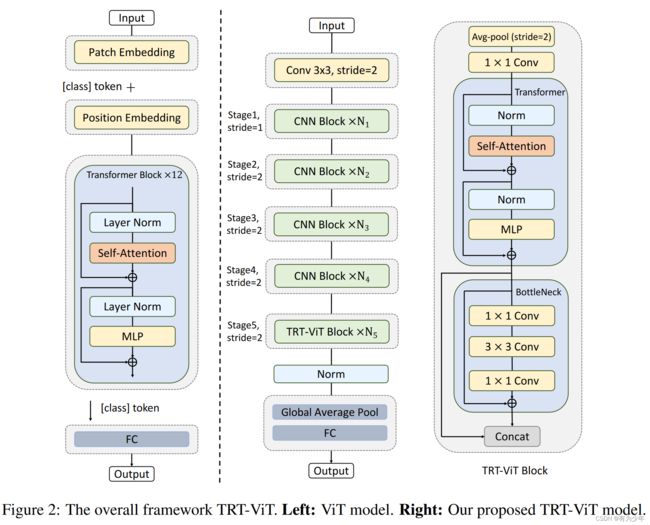
Vision Transformer | Arxiv 2205 - TRT-ViT 面向 TensorRT 的 Vision Transformer
Arxiv 2205 - TRT-ViT 面向 TensorRT 的 Vision Transformer

- 论文:https://arxiv.org/abs/2205.09579
- 原始文档:https://www.yuque.com/lart/papers/pghqxg
主要内容
这篇文章从Vision Transformer的实际应用的角度进行了回顾和探索。
现有的Vision Transformer虽然精度很高,但是却并不像ResNet那样高效,且逐渐偏离了实际部署场景的需求。作者们认为这可能是因为当前对于模型计算效率的评估方式决定的,例如FLOPs或者参数量都仅仅是片面的、次优的,而且对于具体的硬件并不敏感。实际上,模型必须应对部署过程中的环境不确定性,其中涉及硬件特性,例如内存访问成本和I/O吞吐量。
由于TensorRT在实践中已经成为一个通用且部署友好的解决方案,它能够提供方便的硬件导向的指导,所以本文将模型设计考虑的重点放到了更具针对性的效率指标的优化上,即特定硬件设备上的TensorRT延时,这可以提供涉及计算能力、内存消耗和带宽的全面反馈。这也随之引出了本文主要围绕的问题:如何设计一个模型,能有 Transformer 那样的高性能,又可以有像 ResNet 那样快的预测速度?
针对这一问题,文章系统的探索了CNN和Transformer的混合设计。通过一系列实验,整理出了四条针对TesnorTR导向和部署友好型的模型设计指导,其中包含两条stage级别的,领条block级别的:
- stage-level:Transformer block适合放置到模型的后期,这可以最大化效率和性能的权衡。
- stage-level:先浅后深的stage设计模式可以提升性能。
- block-level:Transformer和BottleNeck的混合block要比单独的Transformer更有效。
- block-level:先全局再局部的block设计模式有助于弥补性能问题。
基于这些原则,作者们设计了一系列TensorrtTR-oriented Transformers,即TRT-ViT,这些模型都是CNN与Transformer的混合体。提出的TRT-ViT在视觉分类任务中,关于时延和准确率的权衡上,超过了现有的卷积网络和Vision Transformer。并且在下游任务上的时延和准确率上,也展现出了更显著的提升。
在TensorRT上高效网络设计的实践准则

这里的运行时分析主要基于卷积网络和视觉Transformer的各自的典型代表ResNet和ViT:
- 他们性能良好且被广泛应用;
- 他们的核心组件BottleNeck和Transformer块也是其他更先进网络的重要组件。
针对性能的分析,这里引入了数个针对模型效率的分析指标:
- Params:模型参数量
- FLOPs:模型的浮点计算量
- Lantency:推理时延
- TeraParams:以T为单位的,参数量与时延的比值。用于反映操作或者block的参数密度。
- TeraFLOPS:以T为单位的,浮点计算量与时延的比值。即每秒中以T为单位的浮点操作数(FLOPs),用于表示操作或者模型block的计算密度,从而反映硬件上的计算效率。这延续了RepLKNet的设定。
Transformer block放到模型后期更合适

通过分析对现有的Transformer、BottleNeck模块本身在分类任务中典型的四个特征图尺寸的情况下计算密度(表1),以及对应典型模型的分类性能和时延情况(图1),可以看到:
- Transformer确实可以带来良好的性能。
- 当输入尺寸较大时,Transformer Blcok计算密度会很小;而当其输入变小时,计算密度可以达到与BottleNeck的近似水平。
所以Transformer Block适合放到模型后期阶段中,以便于平衡性能和效率。
基于此作者设计了第一版模型,即使用使用Transformer Block替换卷积网络深层的BottleNeck。命名为MixNetV。这比Transformer要快,还比ResNet性能好(表3)。
浅层stage要浅一些,深层stage要深一些
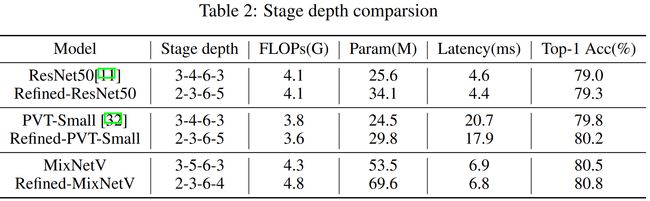
一种广泛认可的观点是参数越多模型容量越高(过参数化)。为了尽可能提升模型的参数但是却不损害效率,这里对参数密度定义为参数量和时延的比值,并以此作为分析的依据。
在Transformer和BottleNeck模块在不同尺寸特征输入时参数密度的对比中可以看到:
- 随着特征尺寸对应的stage的加深,两种模块的参数密度都在增加。
- 深层特征中,BottleNeck具有更大的参数密度。
这意味着,我们应该让深层更深,浅层更浅。同时,深层堆叠BottleNeck可以更有效地扩充模型的容量而且不会影响模型的效率。
在对ResNet和PVT按照这一观察进行修改后的实验(表2)对比中看到,虽然增加了FLOPs和Params,但是提升了性能的同时还提升了时延。
基于此,对MixNetV做出了同样的改动,减少了浅层block的数量,加深了最深层的数量。得到了Refined-MixNetV,进一步提升了性能,并维持了时延。但是当前的时延仍然要不ResNet50高一些。
Transformer与BottleNeck混合结构更有效
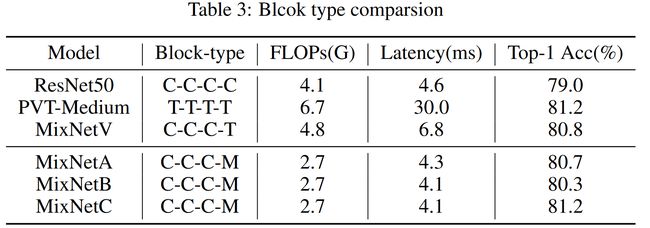
为了进一步压缩时延,并同时提升性能,作者们针对结构中的Transformer进行了重新的设计。
设计了Transformer与BottleNeck的三种混合结构,分别是并行式结构的MixBlockA和串行式结构的MixBlockB以及MixBlockC。本部分仅讨论A和B型结构。
这样的结构获得了比Transformer更高的计算密度和参数密度,更有效率和潜力。所以作者用它们替换MixNetV中的Transformer结构。

实验(表3)对比可以看到,虽然替换后的结构MixNetA和MixNetB获得了更好的时延的提升,但是仍然没有超过MixNetV,并且和现有的纯Transformer结构PVT-Medium仍有差距。
先全局再局部还可以再提升性能
考虑到Transformer的全局交互特性与Convolution的局部挖掘特性,相较于“先提取局部信息再在全局细化”,“先获取全局信息再在本地细化”要更加合理。
基于这一规则,对MixBlockB中的Transformer和Convolution位置进行了交换,得到了MixBlockC。而且计算密度不会变化。表3实验结果中证实了这种改进更加有效,获得了和PVT-Medium相同的精度,但是却具有更低的推理延时。
由此,MixBlockC被当做本文模型设计的基础单元。
实验对比
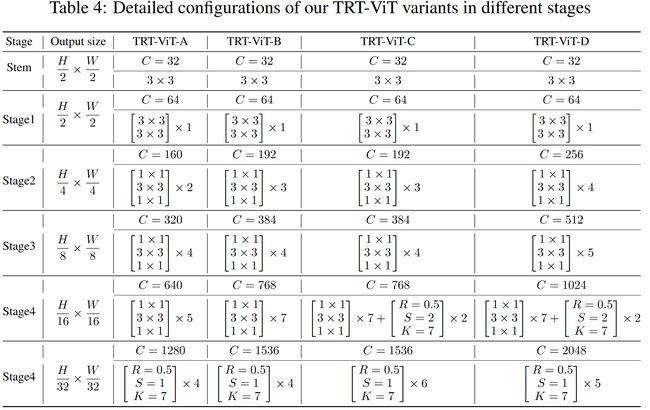
延续ResNet的基本配置,作者们构建了TRT-ViT的四个变体,仍然延续金字塔结构。模型的构建同样遵循了这四条原则,MixBlockC仅被用在模型最后一个阶段中。模型中的Transformer部分,MLP扩张率设为3,头的维度设为32,使用LN和GeLU,而BottleNeck中使用BN和ReLU。
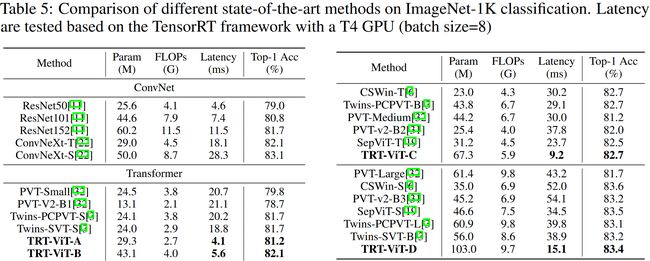
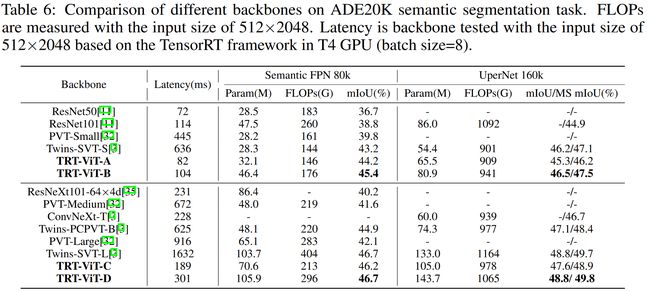
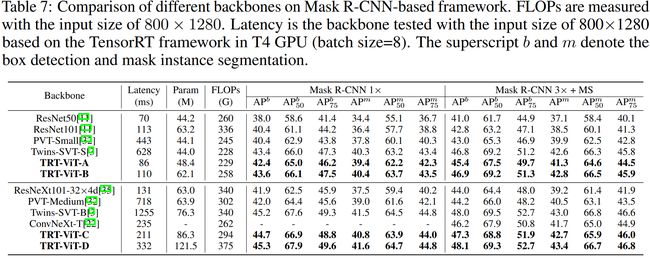
从下面的三组与一众SOTA的对比中可以看到,在推理时延和性能的权衡上具有着明显的优势。
ImageNet-1K
ADE20K
COCO
模块的消融实验
这里对不同stage中的结构逐步替换为MixBlock,以及MixBlock中的通道收缩参数R分别进行了针对性的消融实验。但是在前面与SOTA的对比中选用的是“C-C-C-M”和“R=0.5”的配置。
