NLP入门--Seq2Seq英汉翻译实战
大家好,我是CuddleSabe,目前大四在读,深圳准入职算法工程师,研究主要方向为多模态(VQA、ImageCaptioning等),欢迎各位佬来讨论!
我最近在有序地计划整理CV入门实战系列及NLP入门实战系列。在这两个专栏中,我将会带领大家一步步进行经典网络算法的实现,欢迎各位读者(da lao)订阅
Seq2Seq
- 一、模型介绍
-
- 1.1 Seq2Seq介绍
- 1.2 Encoder-Decoder结构
- 二、 代码编写
-
- 1. 获取数据集的字典等相关数据
-
- 1.1 **获取中文字典**
- 1.3 **分析句子长度分布**
- 2. 方法集成至数据集
- 3. 编写模型
- 4.编写带mask的损失函数
- 5.训练
- 三、应用
- 四、数据集及代码下载
一、模型介绍
1.1 Seq2Seq介绍
seq2seq是序列到序列,是从一个序列生成另外一个序列。 它涉及两个过程:一个是理解前一个序列,另一个是用理解到的内容来生成新的序列。至于序列所采用的模型可以是RNN,LSTM,GRU,其它序列模型等。本教程中使用GRU。
1.2 Encoder-Decoder结构
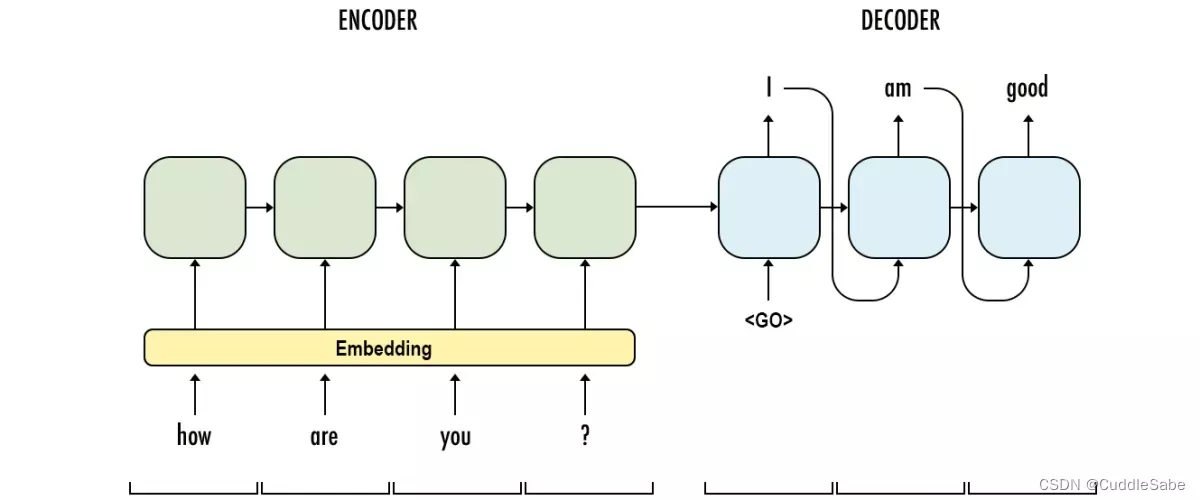
Seq2Seq模型如上图所示分为Encoder编码器与Decoder解码器两个部分。在训练阶段,解码器的输入是原句前加开始符的句子向量(即ground truth)与编码器最后一层的隐含状态;而在预测阶段,解码器的输入是上一个时间步自身预测的单词向量与编码器的隐含状态。代码说明即如下图:
训练阶段
# 获得编码器中rnn最后一层的隐含状态
h = self.encoder(x)
# 将句子末尾的去掉,在前面加上
sos = torch.LongTensor([2]*x.shape[0]).reshape(-1, 1).to(device)
dec_input = torch.cat([sos, y[:, :-1]], 1).to(device)
# 将ground-truth及编码器的隐含状态作为解码器输入
pred, _ = self.decoder(dec_input, h)
return pred
测试阶段
out_seq = []
for _ in range(num_step):
pred, state = model.decoder(decoder_input, state)
decoder_input = torch.argmax(pred, dim=2)
pred_words = decoder_input.squeeze()
word_id = int(pred_words.cpu().numpy())
pred_words = id2word[word_id]
if pred_words == '' :
break
out_seq.append(pred_words)
return ' '.join(out_seq)
二、 代码编写
1. 获取数据集的字典等相关数据
import os
import re
import numpy as np
import torch
import jieba
jieba.setLogLevel(jieba.logging.INFO)
from collections import Counter
from tqdm.notebook import tqdm
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_dir = './En2Zh_Data'
data_nums = 50000 # 读取多少条数据
embed_dim = 128 #词向量维度
min_count = 1 #频数少于min_count的词将会被抛弃,低频词类似于噪声,可以抛弃掉
nb_epoch = 70 #迭代次数
batch_size = 512
lr = 0.005
STOP_WORDS = '??.。,,\、@!!#¥$^……&*(())——+=;;【][】\n'
1.1 获取中文字典
cn_words, cn_corpus = [], []
with open(os.path.join(data_dir, 'train.zh'), 'r') as f:
for i, line in enumerate(tqdm(f)):
if data_nums != -1:
if i == data_nums:
break
for s in STOP_WORDS:
line = line.replace(s, '')
line = line.replace(' ', '')
cut = jieba.lcut(line)
cn_words+=cut
cn_corpus.append(cut)
cn_words = dict(Counter(cn_words))
words_cn_dict = cn_words
cn_words = {i:j for i,j in cn_words.items() if (i not in STOP_WORDS)}
cn_id2word = {i+5:j for i,j in enumerate(cn_words)}
cn_id2word[0] = ''
cn_id2word[1] = ''
cn_id2word[2] = ''
cn_id2word[3] = ''
cn_id2word[4] = ''
cn_word2id = {j:i for i,j in cn_id2word.items()}
en_words, en_corpus = [], []
with open(os.path.join(data_dir, 'train.en'), 'r') as f:
for i, line in enumerate(tqdm(f)):
if data_nums != -1:
if i == data_nums:
break
line = line.lower()
for s in STOP_WORDS:
line = line.replace(s, '')
cut = re.split("[' ?. ,?\n]", line)
en_words+=cut
en_corpus.append(cut)
en_words = dict(Counter(en_words))
words_en_dict = en_words
en_words = {i:j for i,j in en_words.items() if (i not in STOP_WORDS and i != '\n')}
en_id2word = {i+5:j for i,j in enumerate(en_words)}
en_id2word[0] = ''
en_id2word[1] = ''
en_id2word[2] = ''
en_id2word[3] = ''
en_id2word[4] = ''
en_word2id = {j:i for i,j in en_id2word.items()}
print('英文词典共{}单词,中文词典共{}单词'.format(len(en_words), len(cn_words)))

1.3 分析句子长度分布
import numpy as np
import matplotlib.pyplot as plt
en_sentence_len = [len(s) for s in en_corpus]
cn_sentence_len = [len(s) for s in cn_corpus]
def count_len(data):
times, length = [], []
add_sum = 0
for i in range(1, 50):
tmp = 0
for d in data:
if d ==i:
tmp += 1
add_sum += tmp
times.append(add_sum/len(data))
length.append(i)
return times, length
en_times, en_length = count_len(en_sentence_len)
cn_times, cn_length = count_len(cn_sentence_len)
plt.subplot(1, 2, 1)
plt.bar(en_length, en_times, label='en', color='red')
plt.legend()
plt.subplot(1, 2, 2)
plt.bar(cn_length, cn_times, label='cn', color='blue')
plt.legend()
plt.show()
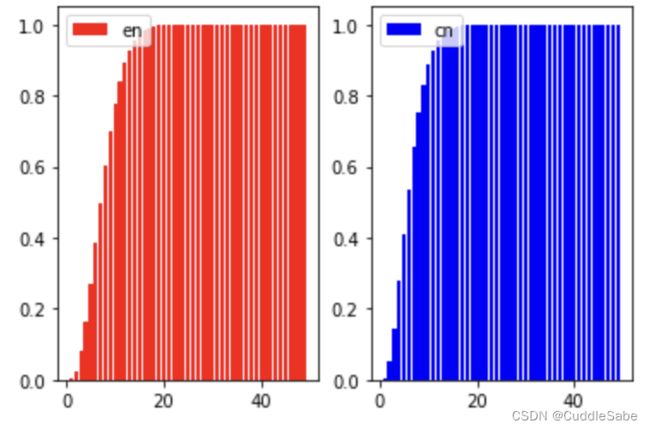
可以看到,无论中英文,97%多的数据长度都在15个单词以内。因此我们选取15为数据的固定长度:高于15的我们抛弃,少于15的我们使用PAD进行填充
2. 方法集成至数据集
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
class En2Zh_Dataset(Dataset):
def __init__(self, en_data, cn_data, max_len=15, min_count=15, data_nums=100, drop=False):
super(En2Zh_Dataset, self).__init__()
self.min_count = min_count
self.max_len = max_len
self.drop = drop
self.STOP_WORDS = '??.。,,\、@!!#¥$^……&*(())——+=;;【][】\n'
self.en_corpus, self.en_word2id, self.en_id2word = self._build_en_dic(en_data, data_nums)
self.cn_corpus, self.cn_word2id, self.cn_id2word = self._build_cn_dic(cn_data, data_nums)
print('英文词典共{}单词,中文词典共{}单词'.format(len(self.en_word2id), len(self.cn_word2id)))
self.en_corpus_data, self.cn_corpus_data, self.cn_valid_len = self._build_data()
def __getitem__(self, index):
return torch.LongTensor(self.en_corpus_data[index]), torch.LongTensor(self.cn_corpus_data[index]), torch.LongTensor([self.cn_valid_len[index]]).squeeze(0)
def __len__(self):
return len(self.en_corpus)
def _pre_process(self, sentence):
sentence.append('' )
return sentence
def _build_data(self):
en_corpus_data, cn_corpus_data = [], []
cn_valid_len = []
print('建立张量数据中...')
en_sentence_len = [len(s) for s in self.en_corpus]
cn_sentence_len = [len(s) for s in self.cn_corpus]
for index, sentence in enumerate(tqdm(self.en_corpus)):
if self.drop == True:
if en_sentence_len[index] > self.max_len-1 or cn_sentence_len[index] > self.max_len-1:
continue
else:
if en_sentence_len[index] > self.max_len-1:
sentence = sentence[:self.max_len-1]
sentence = self._pre_process(sentence)
for i in range(self.max_len - len(sentence)):
sentence.append('' )
tmp = []
for w in sentence:
tmp.append(self.en_word2id[w] if w in self.en_word2id else int(1))
en_corpus_data.append(tmp)
for index, sentence in enumerate(tqdm(self.cn_corpus)):
if self.drop == True:
if cn_sentence_len[index] > self.max_len-1 or cn_sentence_len[index] > self.max_len-1:
continue
else:
if cn_sentence_len[index] > self.max_len-1:
sentence = sentence[:self.max_len-1]
sentence = self._pre_process(sentence)
cn_valid_len.append(len(sentence))
for i in range(self.max_len - len(sentence)):
sentence.append('' )
tmp = []
for w in sentence:
tmp.append(self.cn_word2id[w] if w in self.cn_word2id else int(1))
cn_corpus_data.append(tmp)
return en_corpus_data, cn_corpus_data, cn_valid_len
def _build_dic_tool(self, data, data_nums, lang):
words, corpus = [], []
with open(data, 'r') as f:
for i, line in enumerate(tqdm(f)):
if data_nums != -1:
if i == data_nums:
break
for s in self.STOP_WORDS:
line = line.replace(s, '')
if lang == 'cn':
line = line.replace(' ', '')
cut = jieba.lcut(line)
words+=cut
corpus.append(cut)
elif lang == 'en':
line = line.lower()
cut = re.split("[' ?. ,?\n]", line)
words+=cut
corpus.append(cut)
words = dict(Counter(words))
words = {i:j for i,j in words.items() if (j >= self.min_count and i not in self.STOP_WORDS)}
id2word = {i+5:j for i,j in enumerate(words)}
id2word[0] = ''
id2word[1] = ''
id2word[2] = ''
id2word[3] = ''
id2word[4] = ''
word2id = {j:i for i,j in id2word.items()}
return corpus, word2id, id2word
def _build_cn_dic(self, cn_data, data_nums):
return self._build_dic_tool(cn_data, lang='cn', data_nums=data_nums)
def _build_en_dic(self, en_data, data_nums):
return self._build_dic_tool(en_data, lang='en', data_nums=data_nums)
def get_en_dic(self):
return self.en_word2id, self.en_id2word
def get_cn_dic(self):
return self.cn_word2id, self.cn_word2id
en_data = os.path.join(data_dir, 'train.en')
cn_data = os.path.join(data_dir, 'train.zh')
dataset = En2Zh_Dataset(en_data, cn_data, min_count=min_count, data_nums=data_nums, drop=False)

3. 编写模型
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, vocab_num, embed_dim=256, hidden_dim=512, num_layers=2, dropout=0.5):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_num+1, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_dim, num_layers, batch_first=True)
def forward(self, x):
x = self.embedding(x) # [batch, len, embed]
_, h = self.rnn(x) # _:[batch, len, hidden]
return h # h:[num_layers, batch, hidden]
class Decoder(nn.Module):
def __init__(self, vocab_num, embed_dim=256, hidden_dim=512, num_layers=2, dropout=0.5):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_num+1, embed_dim)
self.rnn = nn.GRU(embed_dim+hidden_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_dim, vocab_num)
def forward(self, x, h):
x = self.embedding(x) # [batch, seq_len] -> [batch, seq_len, embed_dim]
context = h[-1].repeat(x.shape[1], 1, 1).permute(1, 0, 2).to(device) # [batch, seq_len, hidden]
x_and_context = torch.cat((x, context), 2).to(device)
out, h = self.rnn(x_and_context, h)
pred = self.fc(out)
return pred, h
class Seq2Seq(nn.Module):
def __init__(self, src_vocab_num, trg_vocab_num, embed_dim=256, hidden_dim=512, num_layers=2, max_len=15, dropout=0.5, encoder=None, decoder=None):
super(Seq2Seq, self).__init__()
self.encoder = Encoder(src_vocab_num, embed_dim, hidden_dim, num_layers, dropout=dropout)
self.decoder = Decoder(trg_vocab_num, embed_dim, hidden_dim, num_layers, dropout=dropout)
if encoder:
self.encoder = encoder
if decoder:
self.decoder = decoder
def forward(self, x, y):
# 获得编码器中rnn最后一层的隐含状态
h = self.encoder(x)
# 将句子末尾的去掉,在前面加上
sos = torch.LongTensor([2]*x.shape[0]).reshape(-1, 1).to(device)
dec_input = torch.cat([sos, y[:, :-1]], 1).to(device)
# 将ground-truth及编码器的隐含状态作为解码器输入
pred, _ = self.decoder(dec_input, h)
return pred
en_vacab, en_id2word = dataset.get_en_dic()
cn_vacab, cn_id2word = dataset.get_cn_dic()
model = Seq2Seq(len(en_vacab), len(cn_vacab), dropout=0.5).to(device)
for en_s, cn_s, valid_len in data_loader:
out = model(en_s.to(device), cn_s.to(device))
print(out.shape)
break
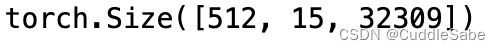
4.编写带mask的损失函数
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
def sequence_mask(self, x, valid_len, value=0):
max_len = x.shape[1]
mask = torch.arange((max_len), dtype=torch.float32).to(device)[None, :] < valid_len[:, None]
x[~mask] = value
return x
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = self.sequence_mask(weights, valid_len).to(device)
self.reduction = 'none'
unweighted_loss = super().forward(pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1).to(device)
return weighted_loss
因为数据中有很多是pad填充的占位符,因此它们不参与损失计算,我们只需计算有效单词的交叉熵即可。
5.训练
model = Seq2Seq(len(en_vacab), len(cn_vacab)).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_fn = MaskedSoftmaxCELoss()
loss_stack = []
min_loss = 100000
for epoch in tqdm(range(nb_epoch)):
epoch = len(loss_stack) + 1
total = 0
loss_data = 0
model.train()
for en_s, cn_s, valid_len in data_loader:
total += en_s.shape[0]
out = model(en_s.to(device), cn_s.to(device))
loss = loss_fn(out.to(device), cn_s.to(device), valid_len.to(device))
optimizer.zero_grad()
loss.sum().backward()
optimizer.step()
loss_data += loss.sum().detach().cpu().numpy()
loss_data /= total
loss_stack.append(loss_data)
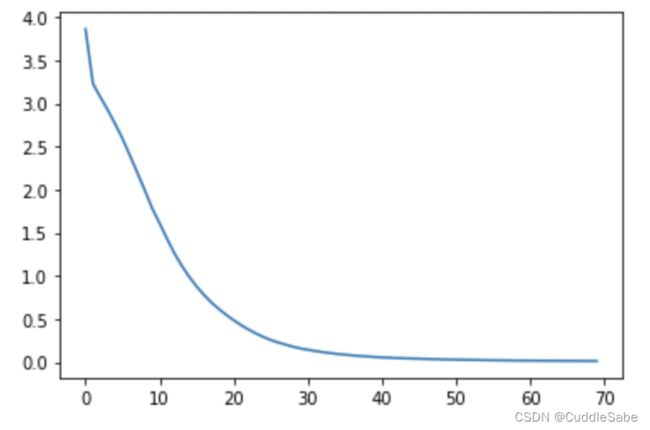
![]()
import matplotlib.pyplot as plt
plt.plot(loss_stack)
plt.show()
三、应用
def translate(model, src_sentence, src_vocab, trg_vocab, num_step):
model.eval()
id2word = {i+5:j for i,j in enumerate(cn_vacab)}
id2word[0] = ''
id2word[1] = ''
id2word[2] = ''
id2word[3] = ''
id2word[4] = ''
sentence = re.split("[' ?. ,?\n]", src_sentence.lower()) + ['' ]
for i in range(num_step - len(sentence)):
sentence.append('' )
print(sentence)
encoder_input = []
for w in sentence:
encoder_input.append(src_vocab[w] if w in src_vocab else int(1))
encoder_input = torch.LongTensor(encoder_input).unsqueeze(0).to(device)
state = model.encoder(encoder_input)
decoder_input = torch.LongTensor([2]*1).reshape(-1, 1).to(device)
out_seq = []
for _ in range(num_step):
pred, state = model.decoder(decoder_input, state)
decoder_input = torch.argmax(pred, dim=2)
pred_words = decoder_input.squeeze()
word_id = int(pred_words.cpu().numpy())
pred_words = id2word[word_id]
if pred_words == '' :
break
out_seq.append(pred_words)
return ' '.join(out_seq)
translate(model, "a red card", en_vacab, cn_vacab, 15)

四、数据集及代码下载
因为本教程使用的数据集为AI Challenge竞赛中数据集,数据量过大(千万级别),因此本教程设置参数data_nums来设定读取多少数据。各位读者在实践时可根据自身硬件条件来更改参数。数据集及代码链接如下:
https://pan.baidu.com/s/11NNX0J9asJD2EROQk_xvZw
提取码: wt21