AI生成藝術(No.2):從 UNet 到 Pix2Pix 彩繪 GAN 範例程式
邁向元宇宙, AI 生成藝術之路 ( N o .2 )
《從 UNet 到 Pix2Pix 彩繪 GAN 範例程式 》
<使用 Paddle 開發、可運行於 OpenVINO >
2.0 前言:介紹 Pix2Pix 和 UNet
Pix2Pix 模型
⚫ Pix2Pix GAN 已經在一系列圖像到圖像的轉換任務中得到了證明, 例如將地圖轉換為衛星照片、將黑白照片轉換為彩色照片以及將產品草圖轉換為產品照片。
⚫ Pix2Pix 是一種 cGAN。以輸入圖像作為條件來生成圖像。
⚫ cGAN 在輸入 G 網路的時候不光會輸入噪音,還會輸入一個條件 ( condition ),G 網路生成的 fake images 會受到具體的 condition 的影響。那麼如果把一副圖像作為 condition,則生成的 fake images 就與這個 condition images 有對應關係,從而實現了 一個 Image-to-Image Translation 的過程。
⚫ pix2pix 主要做了 G 網路結構的優化:Encoder-decoder 結構和 Unet 結構,圖像 patch 的操作。實質還是用 CGAN 來做圖像轉換工 作。
⚫ 從功能實現上來看,網路需要學會“根據圖元預測圖元”(predict pixels from pixels)。
⚫ Pix2Pix 的生成器采用的是类似 U-Net 的结构。
⚫ 整体架构使用 Unet。原因在于很多图像转换任务(比如图像上色) 不只是需要语义信息,还需要网络保留一些低级信息,如颜色、轮廓 等。故采用 Unet 对称的跳跃连接结构将低层信息直接复制到高层特 征图上。Unet 实际上就是加了跳跃连接的 AutoEncoder 结构。
UNet 模型
⚫ 從 2015 年,全卷積網路(FCN)誕生,圖像分割在深度學習領域掀起 旋風。
⚫ 同年(2015)稍晚也誕生了 Unet,號稱可用極少數據獲取優質的結 果,在資料可貴的醫療影像領域稱王稱霸。
⚫ Unet 的特性:使用更少的訓練圖像並產生更精確的分割。在現代 GPU 上分割 512 × 512 圖像只需不到一秒的時間。在上採樣部分有 大量的特徵通道,這允許網絡將上下文信息傳播到更高分辨率的層。
⚫ 該網絡僅使用每個卷積的有效部分,沒有任何完全連接的層。[2]為 了預測圖像邊界區域的像素,通過鏡像輸入圖像來推斷缺失的上下 文。這種平鋪策略對於將網絡應用於大圖像很重要,因為否則分辨率 將受到 GPU 內存的限制。

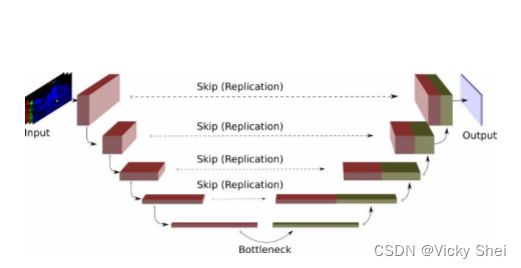
⚫ Unet 網路結構如其名呈現一個 U 字形,即由卷積和池化單元構成, 左半邊為編碼器即如傳統的分類網路是“下採樣階段”,右半邊為解 碼器是“上採樣階段”,中間的灰色箭頭為跳躍連接,將淺層的特徵 與深層的特徵拼接,因為淺層通常可以抓取圖像的一些簡單的特徵, 比如邊界,顏色。深層經過的卷積操作多抓取到圖像的一些說不清道 不明的抽象特徵,將淺深同時利用起來為上上策,同時允許解碼器學 習在編碼器池化下採樣中丟失的相關特徵。縱觀整個網路 Unet 其實 有點帶有殘差(residual)結構的思想。
⚫ 在 Unet 之前,則是更老的 FCN 網路,FCN 是 Fully Convolutional Netowkrs 的簡寫,不過這個 基本上是一個框架,到現在的分割網 路,誰敢說用不到卷積層呢。
⚫ 不過 FCN 網路的準確度較低,不比 Unet 好用。現在還有 Segnet, Mask RCNN,Segnet,DeepLabv3+等網路。
⚫ Unet 是由一條收縮路徑和一條擴展路徑組成,這使其具有 u 形架 構。收縮路徑是一個典型的捲積網絡,由重複應用的捲積組成,每個 卷積後面都有一個整流線性單元 (ReLU) 和一個最大池化操作。在收 縮過程中,空間信息減少,而特徵信息增加。擴展路徑通過一系列上 卷積和連接將特徵和空間信息與收縮路徑中的高分辨率特徵相結合。
⚫ Unet 的好處是:網路層越深得到的特徵圖,有著更大的視野域,淺 層卷積關注紋理特徵,深層網路關注本質的那種特徵,所以深層淺層 特徵都是有格子的意義的;另外一點是通過反捲積得到的更大的尺寸 的特徵圖的邊緣,是缺少資訊的,畢竟每一次下采樣提煉特徵的同 時,也必然會損失一些邊緣特徵,而失去的特徵並不能從上取樣中找 回,因此通過特徵的拼接,來實現邊緣特徵的一個找回。
⚫ 醫療影像語義較為簡單、結構固定。因此語義資訊相比自動駕駛等較 為單一,因此並不需要去篩選過濾無用的資訊。醫療影像的所有特徵 都很重要,因此低階特徵和高階語義特徵都很重要,所以 U 型結構 的 skip connection 結構(特徵拼接)更好派上用場
⚫ 醫學影像的資料較少,獲取難度大,資料量可能只有幾百甚至不到 1 00,因此如果使用大型的網路例如 DeepLabv3+等模型,很容易過 擬合。大型網路的優點是更強的影象表述能力,而較為簡單、數量少 的醫學影像並沒有那麼多的內容需要表述。
⚫ 醫學影像往往是多模態的。因此 醫學影像任務中,往往需要自己設 計網路去提取不同的模態特徵,因此輕量結構簡單的 Unet 可以有更 大的操作空間。
⚫ 圖像語義較為簡單、結構較為固定。我們做腦的,就用腦 CT 和腦 MRI,做胸片的只用胸片 CT,做眼底的只用眼底 OCT,都是一個固 定的器官的成像,而不是全身的。由於器官本身結構固定和語義資訊 沒有特別豐富,所以高級語義資訊和低級特徵都顯得很重要(UNet 的 skip connection 和 U 型結構就派上了用場)。
⚫ 醫學數據量少。醫學影像的資料獲取相對難一些,很多比賽只提供不 到 100 例資料。所以我們設計的模型不宜多大,參數過多,很容易 導致過擬合。
⚫ 原始 UNet 的參數量在 28M 左右(上採樣帶轉置卷積的 UNet 參數量 在 31M 左右),而如果把 channel 數成倍縮小,模型可以更小。縮 小兩倍後,UNet 參數量在 7.75M。縮小四倍,可以把模型參數量縮 小至 2M 以內,非常輕量。個人嘗試過使用 Deeplab v3+和 DRN 等自然圖像語義分割的 SOTA 網路在自己的專案上,發現效果和 UNet 差不多,但是參數量會大很多。
⚫ 可解釋性重要。由於醫療影像最終是輔助醫生的臨床診斷,所以網路 告訴醫生一個 3D 的 CT 有沒有病是遠遠不夠的,醫生還要進一步的 想知道,病灶在哪一層,在哪一層的哪個位置,分割出來了嗎,能求 體積嘛?
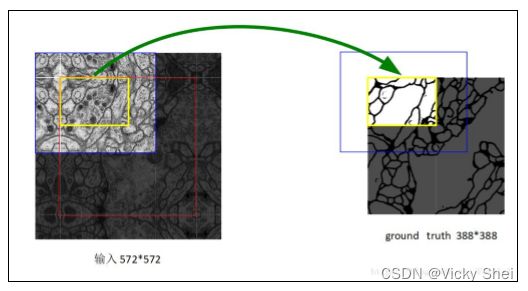
⚫ 醫學圖像是一般相當大,但是分割時候不可能將原圖太小輸入網路, 所以必須切成一張一張的小 patch,在切成小 patch 的時候,Unet 由於網路結構原因適合有 overlap 的切圖,可以看圖,紅框是要分 割區域,但是在切圖時要包含周圍區域,overlap 另一個重要原因是 周圍 overlap 部分可以為分割區域邊緣部分提供文理等資訊。可以 看黃框的邊緣,分割結果並沒有受到切成小 patch 而造成分割情況 不好。
⚫ 卷積運算對邊緣區域的特徵提取不如中間區域的深,黃色預測區域需 要臉色區域的圖像資料做輸入,在大圖像分割時,需將圖像做有重疊 的分割就可以做到無縫切割平鋪。
建議參考:
⚫ https://www.gushiciku.cn/pl/p9p2/zh-tw
⚫ https://chtseng.wordpress.com/2020/07/29/%E4%BD%BF%E7%94%A8unet%E9%80%B2%E8%A1%8C%E5%BD%B1%E5%8 3%8F%E5%88%87%E5%89%B2/
2. 建立一個 Unet 模型
⚫ 這是一個標準的 Unet 模型。
⚫ 輸入一個隨機數(1, 3, 224, 224),經由 Unet 模型權重(weight)計 算,然後輸出。
⚫ 由於模型還沒有訓練,所以權重(weight)也是隨機值,所以也是輸出 隨機數,其 shape 與一樣是(1, 3, 224, 224)
程式(0):UNet 模型
⚫ 程式碼:




程式(1):檢驗範例
⚫ 觀察 UNet 模型的輸入與輸出形式。
⚫ 程式碼:


⚫ 輸出結果:

程式(2):檢驗範例
⚫ 觀察模型的輸入與輸出形式。
⚫ 程式碼:


⚫ 輸出:

程式(3):檢驗範例
⚫ 觀察模型的輸入與輸出形式。
⚫ 程式碼:


⚫ 輸出:

3. 基於 Edge2Shoes 數據集
⚫ Edge2Shoes 數據集:
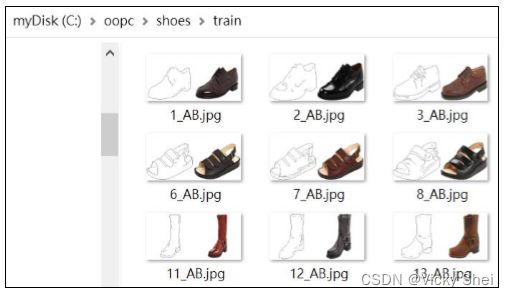
程式(4): 讀取數據集
⚫ 熟悉一下 Shoes 數據集。
⚫ 程式碼:




⚫ 輸出:

⚫ 把左邊的邊框圖,輸入給 UNet 模型,然後學習右圖的顏色。
⚫ 學習之後,自動渲染出彩色圖像。
程式(5):訓練 UNet 模型
⚫ 現在,就拿 Shoes 數據集來訓練這個 UNet 模型。
⚫ 程式碼:



訓練 10 回合。
⚫ 可以觀察到了,其誤差值逐漸下降(縮小):
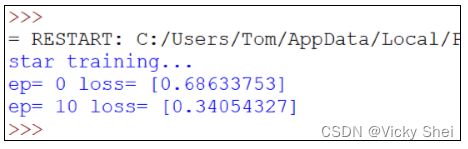
⚫ 訓練完畢之後,這 UNet 模型自動繪出:

⚫ 該才只學習一回合,所以彩繪出來的色彩(上圖左),與原圖(上圖右) 差別還蠻大的。
訓練 50 回合。
⚫ 剛才只訓練 10 回合。現在訓練更多回合(50 回合)。
⚫ 訓練完畢之後,這 UNet 模型自動繪出:

訓練 100 回合。
⚫ 剛才只訓練 50 回合。現在訓練更多回合(100 回合)。
⚫ 訓練完畢之後,這 UNet 模型自動繪出:

訓練 150 回合。
⚫ 剛才只訓練 100 回合。現在訓練更多回合(150 回合)。
⚫ 可以看到 loss 值得下降情形:
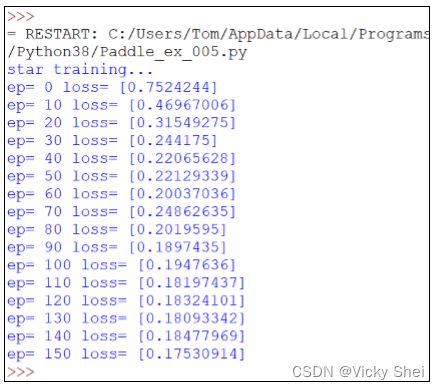
⚫ 訓練 150 回合之後,繪出:

程式(5):可以調整 UNet 模型的參數
⚫ 上一個程式裡,以 RGB 彩色讀取圖像。
⚫ 分解之後,邊框和原圖都是 256 x 256 大小,並保持 RGB 三通道。
⚫ 現在來調整一下:分解之後,邊框和原圖都縮小為是 128 x 128 大 小。
⚫ 並且將邊框圖,轉換成單通道的灰階圖像。
⚫ 這樣可以降低記憶體的用量,或可以加快訓練的速度。
⚫ 程式碼:




訓練 50 回合。
⚫ 可以觀察到了,其誤差值逐漸下降(縮小):
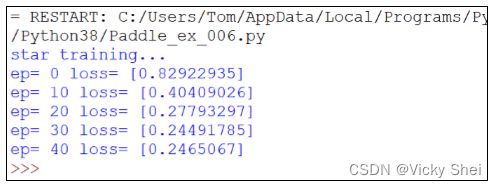
⚫ 訓練完畢之後,這 UNet 模型自動繪出:

⚫ 該才只學習 50 回合,所以彩繪出來的色彩(上圖左),與原圖(上圖右) 差別還蠻大的。
訓練 200 回合。
⚫ 剛才只訓練 50 回合。現在訓練更多回合(200 回合)。
⚫ 可以觀察到了,其誤差值逐漸下降(縮小):
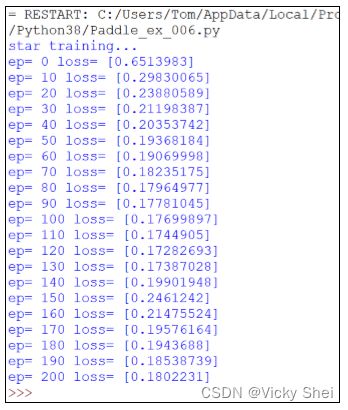
⚫ 訓練完畢之後,這 UNet 模型自動繪出:

4. 建立一個基於 Unet 的 Pix2Pix GAN 模型
⚫ 這是基於 Unet 的 Pix2Pix GAN 模型。
⚫ 以 UNet 作 為 生 成 器 (Geneerator) , 另 添 加 一 個 判 別 器 (Discriminator)。
程式(6):設計一個判別器
⚫ 首先增添一個判別器(Discriminator)。



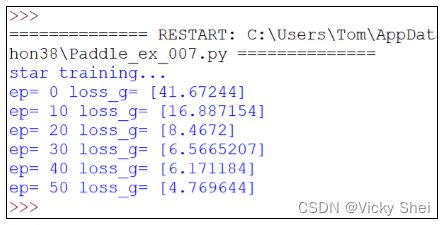
程式(7):撰寫主程式,來訓練這 GAN 模型
⚫ 將 UNet 生成器,與上述的判別器,兩個模型組合起來,就成為 GAN 模型了。
⚫ 上一個程式裡,分解之後,邊框和原圖都是 128 x 128 大小。
⚫ 現在來調整一下:分解之後,邊框和原圖都縮小為是 64 x 64 大小。
⚫ 並且將邊框圖,轉換成單通道的灰階圖像。
⚫ 這樣可以降低記憶體的用量,或可以加快訓練的速度。
⚫ 主程式的程式碼:





訓練 50 回合。
⚫ 可以觀察到了,其誤差值逐漸下降(縮小):
⚫ 訓練完畢之後,這 Pix2Pix GAN 模型自動繪出:

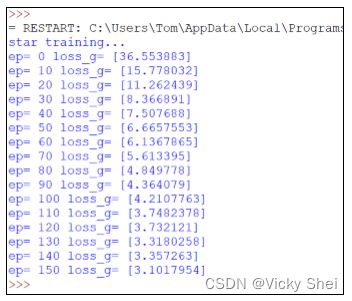
訓練 150 回合。
⚫ 剛才只訓練 50 回合。現在訓練更多回合(150 回合)。
⚫ 可以觀察到了,其誤差值逐漸下降(縮小):
⚫ 訓練完畢之後,這 Pix2Pix GAN 模型自動繪出:

5. 結語
- Unet 提出的初衷是為了解決醫學影象分割的問題;
- 一種 U 型的網路結構來獲取上下文的資訊和位置資訊;
- 在 2015 年的 ISBI cell tracking 比賽中獲得了多個第一, 一開始 這是為了解決細胞層面的分割的任務的。
⚫ 這個結構就是先對圖片進行卷積和池化,在 Unet 論文中是池化 4 次,比方說一開始的圖片是 224x224 的,那麼就會變成 112x112, 56x56,28x28,14x14 四個不同尺寸的特徵。 然後我們對 14x14 的特 徵圖做上取樣或者反捲積,得到 28x28 的特徵圖,這個 28x28 的特 徵圖與之前的 28x28 的特徵圖進行通道傷的拼接 concat,然後再對 拼接之後的特徵圖做卷積和上取樣,得到 56x56 的特徵圖,再與之 前的 56x56 的特徵拼接,卷積,再上取樣,經過四次上取樣可以得 到一個與輸入影象尺寸相同的 224x224 的預測結果。
⚫ 其實整體來看,這個也是一個 Encoder-Decoder 的結構:
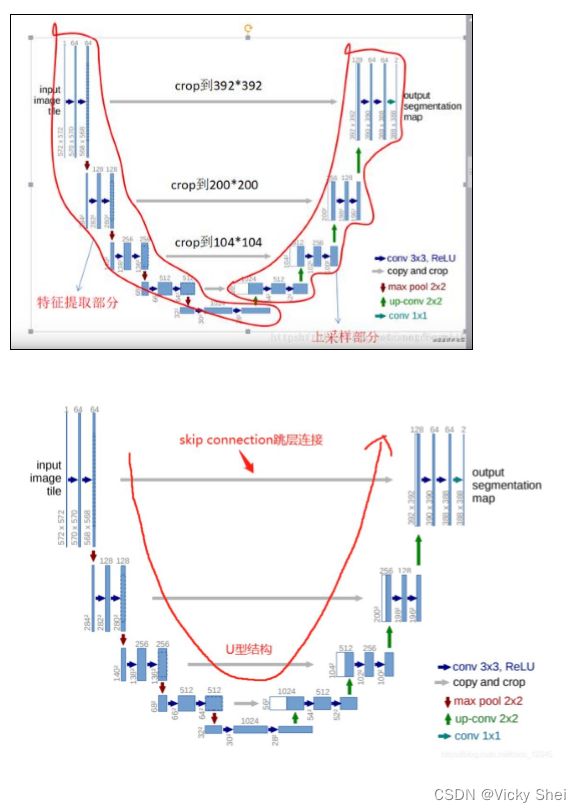
⚫ Unet 網路非常的簡單,前半部分就是特徵提取,後半部分是上取 樣。在一些文獻中把這種結構叫做 編碼器-解碼器結構 ,由於網路 的整體結構是一個大些的英文字母 U,所以叫做 U-net。
⚫ UNet 的結構,我認為有兩個最大的特點,U 型結構和 skip-connec tion。
⚫ UNet 的 encoder 下採樣 4 次,一共下採樣 16 倍,對稱地,其 dec oder 也相應上採樣 4 次,將 encoder 得到的高級語義特徵圖恢復到 原圖片的解析度。
⚫ UNet 共進行了 4 次上採樣,並在同一個 stage 使用了 skip connec tion,而不是直接在高級語義特徵上進行監督和 loss 反傳,這樣就 保證了最後恢復出來的特徵圖融合了更多的 low-level 的 feature, 也使得不同 scale 的 feature 得到了的融合,從而可以進行多尺度預 測和 DeepSupervision。4 次上採樣也使得分割圖恢復邊緣等資訊 更加精細。
⚫ Encoder:左半部分,由兩個 3x3 的卷積層(RELU)再加上一個 2x2 的 maxpooling 層組成一個下采樣的模組(後面程式碼可以看 出);
⚫ Decoder:有半部分,由一個上取樣的卷積層(去卷積層)+特徵拼 接 concat+兩個 3x3 的卷積層(ReLU)反覆構成(程式碼中可以看 出來)
⚫ U-net 通過通道數的拼接,這樣可以形成更厚的特徵。
建議參考:
⚫ https://www.gushiciku.cn/pl/p9p2/zh-tw
END
◆◆◆
尊重原创,感谢原创哦!神鹰AI团队准备了10支《彩绘GAN模型》,更多paddlepaddle的讨论与知识也可关注公众号